面试题个人汇总 - 微服务&分布式
1. 什么是服务雪崩?什么是服务限流?
- 服务雪崩 : 服务A调用服务B,服务B调用服务C,当大量请求突然请求服务A(服务A本身可以抗住这些请求),但是服务C存在请求堆积,从而会使服务B请求堆积,从而服务A不可用。
- 服务限流 : 在高并发情况下为了保护系统,可以对访问服务的请求进行数量上的限制,从而防止系统不被大量请求压垮。
2. 什么是服务降级、什么是熔断
- 服务降级 : 解决系统资源不足和海量业务请求之间的矛盾。在暴增的流量请求下,对一些非核心业务、非关键业务进行有选择性的放弃,一次来释放系统资源,保证核心业务的正常运行。服务降级不是一个常态策略,而是应对非正常情况下的应急策略。服务降级的结果,通常是对一些业务请求返回一个统一的结果,可以理解是一种快速失败FailOver的策略。一般通过配置中心配置开关实现开启降级。
- 服务熔断 : 保护的是业务系统不被外部大流量或者下游系统的异常而拖垮。如果开启了熔断,订单服务可以在下游调用出现部分异常时,调节流量请求,比如在出现了10%的失败后,减少50%的流量请求,如果继续出现50%的异常,则减少80%的流量请求。在检测到下游服务正常后,先恢复30%的流量,然后恢复50%的流量,接下来是全部流量。
3. springcloud核心组件及其作用
Eureka : 服务注册与发现
注册 : 每个服务都向Eureka登记自己提供服务的元数据,包括服务的ip地址,端口号,版本号,通信协议等。Eureka将每个服务维护在一个服务清单中(双层map,第一层key是服务名,第二层key是服务名,value是服务地址加端口)。同时对服务维持心跳,剔除不可用的服务,Eureka集群各节点相互注册,每个实例中都有一样的服务清单。
发现 : Eureka注册的服务之间调用不需要指定服务地址,而是通过服务名想注册中心咨询,并获取所有服务实例清单(缓存到本地),然后实现服务的请求访问。
Ribbon :
服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台(被调用方的服务地址有多个),Ribbon也是通过http发起请求,来进行的调用,只不过是通过调用服务名的地址来实现的。虽然Ribbon不用去具体请求服务实例的ip地址或者域名,但是每调用一个接口都还要手动发起http请求。
Feign :
基于Feign的动态代理机制,根据注解和选择的机器,拼接请求url地址,发起请求,简化服务间的调用,在Ribbon的基础上进行了进一步的封装。单独抽取成一个组件,即是Spring Cloud Feign。在引入Spring Cloud Feign后,只需要创建一个接口并用注解的方式来配置它,即可完成服务提供方的接口绑定。
Hystrix :
发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现不同服务调用的隔离,通过统计接口超时次数返回默认值,实现服务熔断和降级。
Zuul :
如果前端,移动端需要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务。通过与Eureka整合,将自身注册为Eureka下的应用,从Eureka下获取所有服务的实例,来进行服务的路由。Zuul还提供了一套关于过滤器机制,开发者可以自己指定那些规则的请求需要进行校验逻辑,只有通过校验逻辑的请求才会被路由到具体服务实例上,否则返回错误提示。
4. 什么是Hystrix?简述实现机制
分布式容错框架
- 阻止故障的连锁反应,实现熔断。
- 快速失败,实现优雅降级。
- 提供实时的监控和告警。
资源隔离 :
- 线程隔离 : Hystrix会给每一个Command分配一个单独的线程池,这样在进行单个服务调用的时候,就可以在独立的线程池里面进行,而不会对其它线程池造成影响。
- 信号量隔离 : 客户端需要依赖服务发起请求是,首先要获取一个信号量才能真正发起调用,由于信号量的数量有限,当并发请求量超过信号量个数时,后续的请求都会直接拒绝,进入fallback流程。信号量隔离主要是通过控制并发请求量,防止请求线程大面积阻塞,从而达到限制和防止服务雪崩的目的。
Hystrix流程:
- 通过HystrixCommand或者HystrixObservableCommand将所有的外部系统(或者依赖)包装起来,整个包装对象是单独运行在一个线程池之中(命令模式)
- 超时请求应该超过开发者定义的阈值
- 为每个依赖关系维护一个小的线程池(或信号量),如果它变满了,那么依赖关系的请求将被立即拒绝,而不是排队等待
- 统计成功,失败(有客户端抛出的异常),超时和线程拒绝
- 打开断路器可以在一段时间内停止对特定服务的所有请求,入股服务的错误百分比达到阈值,手动或自动的关闭断路器
- 当请求被拒绝,连接超时或者断路器打开,直接执行fallback逻辑
- 近乎实时监控指标和配置变化
5. 高并发场景下如何实现系统限流
限流一般需要结合容量规划和压测来进行,当外部请求接近或者达到系统的最大阈值时,触发限流,采取其他的手段来进行降级,保护系统不被压垮。常见的降级策略包括延迟处理,拒绝服务,随即拒绝等。
计数器法:
- 将时间划分为固定的窗口大小,例如1s
- 在窗口时间段内,每来一个请求,对计数器加1
- 当计数器达到设定限制后,该窗口时间内的之后的请求都被丢弃处理
- 该窗口时间结束后,计数器清零,从新开始计数
滑动窗口计数法 :
- 将时间划分为细粒度的区间,每个区间维持一个计数器,每进入一个请求则计数器加1
- 多个区间组成一个时间窗口,每流逝一个区间时间后,则抛弃最老的一个区间,纳入新区间
- 若当前窗口的区间计数器总和超过设定的限制数量,则本窗口内的后续请求都被丢弃
漏桶算法 : 如果外部请求超出当前阈值,则会在容器里积蓄,一直到溢出,系统不关注溢出的流量。从出口处限制请求速率,并不存在计数器法的临界问题,请求曲线始终是平滑的。无法应对突发流量,相当于一个空桶加固定处理线程。
令牌桶算法 : 假设一个大小恒定的桶,这个桶的容量和设定的阈值有关,桶里放着很多令牌,通过一个固定的速率往里边放入令牌,如果桶满了,就把令牌丢掉,最后桶里可以保存的最大令牌数永不超过桶的大小。当有请求进入时,就尝试从桶里取走一个令牌,如果桶里是空的,那么这个请求就会被拒绝。
6. SOA、分布式、微服务之间有什么关系和区别?
- 分布式 : 分布式架构是指将单体架构的各个部分拆分,然后部署不同的机器或者进程中去,SOA和微服务基本上都是分布式架构
- SOA : 一种面向服务的架构,系统上的所有服务都注册在总线上,当调用服务时,从总线上查找服务信息,然后调用
- 微服务 : 一种更彻底的面向服务的架构,将系统各个功能个体抽成一个个小的应用程序,基本保持一个应用对应一个服务的架构
7. 雪花算法原理

第一位固定为0,41位时间戳,10位workId,12位系列号,位数可以有不同实现。
优点 :
- 每个毫秒值包含的id值很多,不够可以变动位数来增加,性能好(依赖于workId的实现)
- 时间戳值在高位,中间是固定的机器码,自增的序列在低位,整个id是趋势递增的
- 能够根据业务昌吉数据库节点布置灵活调整bit位划分,灵活度高
缺点 :
- 强依赖于机器时钟,如果时钟回拨,会导致重复的id生成,所以一般基于此的算法发现时钟回拨,都会触发异常,阻止id生成,可能会导致服务不可用。
8. 为什么Zookeeper可以用来作为注册中心
可以利用Zookeeper的临时节点和watch机制来实现注册中心的自动注册和发现,另外Zookeeper中的数据都是存在内存的,并且Zookeeper底层采用了NIO,多线程模型,所以Zookeeper的性能也是比较高的,所以可以用来作为注册中心,但是如果考虑到注册中心的可用性的话,Zookeeper则不适合,因为Zookeeper是侧重CP的,注重的是一致性,所以集群数据不一致时,集群将不可用,所以用redis,eureka,nacos来作为注册中心将更合适。
9. 数据库实现分布式锁的问题及解决方案
利用唯一约束键存储key,insert成功则代表获取锁成功,失败则获取失败,操作完成需要删除锁。
问题:
- 非阻塞。锁获取失败后没有排队机制,需要自己编码实现阻塞,可以使用自旋,操作完成需要删除锁
- 不可重入。如果加锁的方法需要递归,则第二次插入会失败,可以使用记录线程标识解决重入问题
- 死锁。删除锁失败,则其他线程没有本法获取锁,可以设置超时时间,使用定时任务检查
- 数据库单点故障。数据库高可用
10. 数据一致性模型有哪些
- 强一致性:当更新操作完成后,任何多个后续进程的访问都会返回最新的更新过的值,这种是对用户体验最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据CAP理论,这种实现需要牺牲可用性。
- 弱一致性:系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会据图承诺多久之后可以读到。用户读到某一操作对系统的更新需要一段时间,即不一致性窗口。
- 最终一致性:弱一致性的特例,强调的是所有的数据副本,在经过一段时间同步之后,最终都能够达到一个一致的状态,因此,最终一致性的本质是需要系统保证数据能够达到一致,而不需要实时保证系统数据的强一致性。到达最终一致性的时间,就是不一致窗口时间,在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。
最终一致性模型根据器提供的不同保证可以划分为更多的模型,包括因果一致性和会话一致性。
因果一致性:要求有因果关系的操作顺序得到保证,非因果关系的操作顺序则无所谓。
会话一致性:将对系统数据的访问过程框定在了一个会话当中,约定了系统能够保证在同一个有效的会话中实现“读己之所写”的一致性,就是在一次访问中,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据的最新值。实际开发中有分布式的session一致性问题,可以认为是会话一致性的一个应用。
11. 什么是分布式事务?有哪些实现方案?
- 本地消息表:创建订单时,将减库存消息加入在本地事务中,一起提交到数据库存入本地消息表,然后调用库存系统,如果调用成功则修改本地消息状态为成功,如果调用库存系统失败,则由后台定时任务从本地消息表中取出未成功的消息,重试调用库存系统。
- 消息队列:目前RocketMQ支持事务消息,工作原理:
1. 生产者订单系统先发送一条half消息到Broker,half消息对消费者而言是不可见的
2. 再创建订单,根据创建订单成功与否,想Broker发送commit或者rollback
3. 并且生产者订单系统还可以提供Broker回调接口,当Broker发现一段时间half消息没有收到任何操作命令,则会主动调此接口来查询订单是否创建成功
4. 一旦half消息commit了,消费者库存系统就会来消费,如果消费成功,则消息销毁,分布式事务结束
5. 如果消费失败,则根据重试策略进行重试,最后还失败则进入死信队列,等待进一步处理 - Seata:阿里开源分布式事务框架,支持AT,TCC等多种模式,底层都是基于两阶段提交来实现的
12. 什么是ZAB协议
ZAB协议是Zookeeper用来实现一致性的原子广播协议,该协议描述了Zookeeper是如何实现一致性的,分为三个阶段:
- 领导者选举阶段:从Zookeeper集群中选出一个节点作为Leader,所有的写请求都会有Leader节点来处理
- 数据同步阶段:集群中所有节点的数据要和Leader节点保持一致,如果不一致则要进行同步
- 请求广播阶段:当Leader节点接收到写请求时,会利用两阶段提交来广播该写请求,使得该写请求像事务一样在其他节点上执行,达到节点上的数据实时一致
注意:Zookeeper只是尽量在达到强一致性,实际依然是最终一致
13. 什么是RPC
RPC,表示远程过程调用,对于java这种面向对象语言,也可以理解成远程方法调用,RPC调用和HTTP调用是有区别的,RPC表示的是一种调用远程方法的方式,可以使用HTTP协议,或者直接基于TCP协议来实现RPC。在java中,我们可以通过直接使用某个服务接口的代理对象来执行方法,而底层则通过构造HTTP请求来调用远程的方法,所以,有一种说法是RPC协议是http协议之上的一种协议。
14. 如何实现接口幂等性
- 唯一id,每次操作,都根据操作和内容生成唯一id,在执行之前先判断id是否已经存在,如果不存在则执行后续操作,并且保存到数据库或者redis等
- 服务端提供发送token的接口,业务调用接口前先获取token,然后调用业务接口请求时,把token携带过去,服务器判断token是否已经存在redis中,存在表示第一次请求,可以继续执行业务,执行业务完成后,最后需要把redis的token删除
- 建去重表,增加版本号,当版本号符合时,才能更新数据
- 状态控制,例如订单有状态,已支付,未支付,支付失败等,当处于未支付的时候才允许修改为支付成功
15. 什么是BASE理论
由于不能同时满足CAP,所以出现了BASE理论
- BA:Basically Available,表示基本可用,表示可以允许一定程度上的不可用,比如系统故障,请求时间变长,或者由于系统故障导致部分非核心功能不可用,都是允许的
- S:Soft state:表示分布式系统可以处于一种中间状态,比如数据正在同步
- E:Eventually consistent,表示最终一致性,不要求分布式系统数据实时达到一致,允许在经过一段时间后再达到一致,在达到一致的过程中,系统也是可用的
16. Dubbo的工作流程
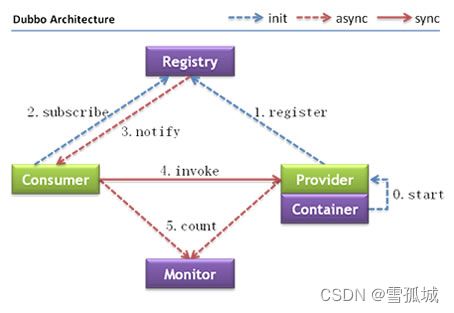
- start:启动spring容器时,自动启动dubbo的provider
- register:dubbo的provider在启动后会去注册中心注册内容,注册的内容包括:ip,端口,接口列表(接口类,方法),版本,provider的协议
- subscribe:订阅,当consumer启动时,自动去registry获取到所已注册的服务的信息
- notify:通知,当provider的信息发生变化时,自动有registry想consumer推送通知
- invoke:consumer调用provider中方法(同步请求,消耗一定性能,但是必须是同步请求,因为需要介绍调用方法后的结果)
- count:每隔2分钟,provider和consumer自动向monitor发生访问次数,monitor进行统计
17. Redis的分布式锁的实现
Redis分布式锁