对抗生成网络总结
对一些基本的对抗生成网络的总结。部分内容整理自Teeyohuang’s blog
文章目录
- GAN (NeurIPS, 2014)
- CGAN
- DCGAN
- StackGAN
- Pix2Pix (CVPR, 2017)
- CycleGAN (ICCV, 2017)
- SRGAN (CVPR, 2017)
- StyleGAN (CVPR, 2019)
GAN (NeurIPS, 2014)
Generative adversarial nets
m i n G m a x D V ( D , G ) = E x ∼ P d a t a ( x ) [ l o g D ( x ) ] + E z ∼ P z ( x ) [ l o g ( 1 − D ( G ( x ) ) ) ] min_Gmax_DV(D,G) = E_{x\sim~P_{data}(x)}[logD(x)] + E_{z\sim~P_{z}(x)}[log(1-D(G(x)))] minGmaxDV(D,G)=Ex∼ Pdata(x)[logD(x)]+Ez∼ Pz(x)[log(1−D(G(x)))].
在实际训练的过程中,可以通过maximize logD(G(x))来训练G。
CGAN
Conditional generative adversarial nets
Pytorch版本代码
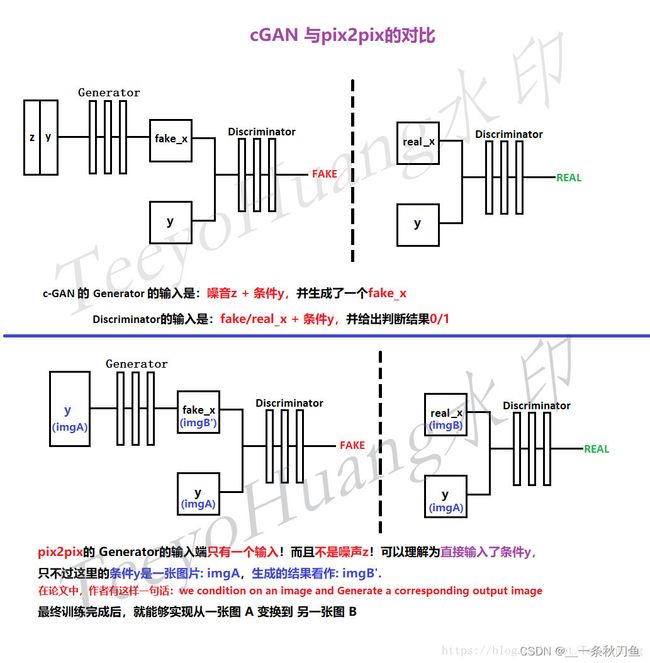
原始GAN的生成器G学到了数据的分布,生成出来的图片其实是随机的,也就是说这个G的生成过程处于一种没有指导的状态,虽然生成的图片,比如mnist数据集来说,生成的的确是数字,但是却没有具体的说是什么数字。 cGAN相当于在原始GAN的基础上加上一个条件:condition,以此来指导G的生成过程。
m i n G m a x D V ( D , G ) = E x ∼ P d a t a ( x ) [ l o g D ( x ∣ y ) ] + E z ∼ P z ( z ) [ l o g ( 1 − D ( G ( z ∣ y ) ) ) ] min_Gmax_DV(D,G) = E_{x\sim~P_{data}(x)}[logD(x|y)] + E_{z\sim~P_{z}(z)}[log(1-D(G(z|y)))] minGmaxDV(D,G)=Ex∼ Pdata(x)[logD(x∣y)]+Ez∼ Pz(z)[log(1−D(G(z∣y)))]
y作为条件,和数据x以及噪声z同时分别进入D和G中。
DCGAN
unsupervised representation learning with deep convolutional generative adversarial networks
Pytorch版本代码
该网络主要使用卷积层,之前的网络用的是全连接层。
StackGAN
**StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks**
基于对CGAN的改进,CGAN无法生成清晰大图,StackGAN希望通过一个描述C,产生一张256x256的图像。通过两个generator实现,第一个generator产生64x64的小图,然后把结果放入第二个generator中生成256x256的大图。
详细内容
Pix2Pix (CVPR, 2017)
Image-to-image translation with conditional adversarial networks
本篇论文的核心思想并不复杂,是借鉴了conditional-GAN的思想。但pix2pix的generator的输入端只有条件y作为输入而没有噪声z。最终训练完成后可以从一张图A变换到另一张图B。
We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks.
CycleGAN (ICCV, 2017)
Unpaired image-to-image translation using cycle-consistent adversarial networks
CycleGAN详细解读
创新点:源于和目标域之间,无需建立训练数据一对一映射(对比pix2pix),就可实现风格迁移。
在CycleGAN中,不仅需要生成器产生的图片y’和数据集Y中的图片画风一样,还需要y’和输入图片x的内容一样。
- Loss function: Loss GAN + Loss cycle
- Loss cycle: 将y‘放入生成器F中,产生的新图片x’与原始x尽可能相似。即F(G(x))=x。
- Loss GAN
SRGAN (CVPR, 2017)
**Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network**
首次使用生成对抗网络(GAN)应用于图像超分辨率(SR)
SRGAN论文阅读笔记
StyleGAN (CVPR, 2019)
A style-based generator architecture for generative adversarial networks
StyleGAN 用风格(style)来影响人脸的姿态、身份特征等,用噪声 ( noise ) 来影响头发丝、皱纹、肤色等细节部分。
StyleGAN论文超详细解读