三重预测指数炒股
预测指数,预测板块,预测个股,进行股票交易。
导包:
#importing required libraries 导入必要的库函数
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
import akshare as ak
import numpy as np
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import mplfinance as mpf
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为微软雅
plt.rcParams['font.sans-serif'] = ['SimHei'] # 字体设置
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False # 负号显示问题获取指数:
end =datetime.datetime.now().strftime('%Y%m%d')
#code= str(stock_pool['代码'].values[i])
code = "sh000001"
df = ak.stock_zh_index_daily(symbol="sh000001")
df.rename(columns= {'date':'Date'},inplace=True)
df['code'] = code
data = df
#creating dataframe 建立新的数据集框架,以长度为索引,取date和close这两列
new_data = data[['Date','close']]
#对于数据内容表现形式的转换,这里是转化为年-月-日的格式,同时建立以这个时间的索引
#new_data['Date'] = pd.to_datetime(new_data.Date,format='%Y-%m-%d')
new_data.index = new_data['Date']
new_data.drop('Date', axis=1, inplace=True)预测函数:
def predict(df):
#creating train and test sets 划分训练集测试集
new_data = df
num = len(new_data)
dataset = new_data.values
print(dataset)
train = dataset[0:int(num*0.4),:]
valid = dataset[int(num*0.4):,:]
#converting dataset into x_train and y_train 将两个数据集归一化处理
scaler = MinMaxScaler(feature_range=(0, 1))
#总数据集归一化
scaled_data = scaler.fit_transform(dataset)
#确定正式训练集测试集,大小是在刚刚划分的数据集合中,按60:1的比例划分,这里的划分不能算是k折交叉验证,知道的朋友麻烦留言解答一下,感谢
x_train, y_train = [], []
for i in range(60,len(train)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
#转为numpy格式
x_train, y_train = np.array(x_train), np.array(y_train)
#重新改变矩阵的大小,这里如果不理解可以参考我的传送门
x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
# create and fit the LSTM network 建立模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50))
model.add(Dense(1))
#编译模型,并给模型喂数据
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2)
#predicting 246 values, using past 60 from the train data 用测试集最后的60个数据
inputs = new_data[len(new_data) - len(valid) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
#取最终的测试集
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
#调整矩阵的规模
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
#模型预测
closing_price = model.predict(X_test)
closing_price = scaler.inverse_transform(closing_price)
#计算rms
rms=np.sqrt(np.mean(np.power((valid-closing_price),2)))
#for plotting 绘画结果
train = new_data[:int(num*0.4)]
valid = new_data[int(num*0.4):]
valid['Predictions'] = closing_price
plt.plot(train['close'])
plt.plot(valid[['close','Predictions']])
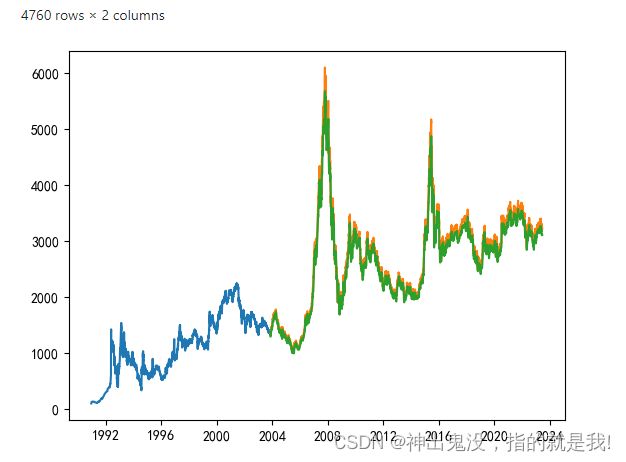
return valid预测指数:
index1 = predict(new_data)
index1
import akshare as ak
ind ="能源金属"
industry = ak.stock_board_industry_hist_em(symbol=ind, start_date="20001201", end_date=end, period="日k", adjust="")
industry .rename(columns= {'日期':'Date','开盘':'open','最高':'high','最低':'low','收盘':'close','成交量':'volume'},inplace=True)
industry['code'] = ind
industry
new_data2 = industry[['Date','close']]
#对于数据内容表现形式的转换,这里是转化为年-月-日的格式,同时建立以这个时间的索引
#new_data['Date'] = pd.to_datetime(new_data.Date,format='%Y-%m-%d')
new_data2.index = new_data2['Date']
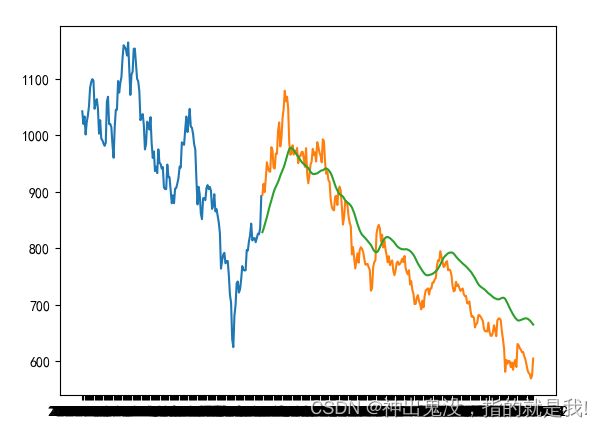
new_data2.drop('Date', axis=1, inplace=True)ind1 = predict(new_data2)
ind1
确定股票代码:”
def gp_type_szsh(gp):
if gp.find('60',0,3)==0:
gp_type='sh'+gp
elif gp.find('688',0,4)==0:
gp_type='sh'+gp
elif gp.find('900',0,4)==0:
gp_type='sh'+gp
elif gp.find('00',0,3)==0:
gp_type='sz'+gp
elif gp.find('300',0,4)==0:
gp_type='sz'+gp
elif gp.find('200',0,4)==0:
gp_type='sz'+gp
return gp_type获取股票数据:
import datetime
from_date='1990-01-01'
to_date=datetime.date.today().strftime('%Y%m%d')
codelist = ak.stock_board_industry_cons_em(symbol="能源金属")['代码']
def stock_pre(stock):
code = stock
dd = ak.stock_zh_a_daily(symbol=code ,start_date = from_date,end_date = to_date)
dd.rename(columns= {'date':'Date'},inplace=True)
data = dd
#creating dataframe 建立新的数据集框架,以长度为索引,取date和close这两列
new_data3 = data[['Date','close']]
#对于数据内容表现形式的转换,这里是转化为年-月-日的格式,同时建立以这个时间的索引
new_data3['Date'] = pd.to_datetime(new_data3.Date,format='%Y-%m-%d')
new_data3.index = new_data3['Date']
new_data3.drop('Date', axis=1, inplace=True)
return new_data3
stock_last= pd.DataFrame()
stock_last['Date'] = 0
for i in codelist[:2]:
print(i)
stock = predict(stock_pre(gp_type_szsh(i)))
stock_last = pd.merge(stock,stock_last,on='Date',how='left')
stock_last
确定信号:
index1['signal']=0
index1.loc[index1['Predictions'].shift(1)>index1['close'].shift(1),'signal']=1
ind1['signal']=0
ind1.loc[ind1['Predictions'].shift(1)>ind1['close'].shift(1),'signal']=1
stock['signal']=0
stock.loc[stock['Predictions'].shift(1)>stock['close'].shift(1),'signal']=1确定数据:
ind1 = ind1.reset_index()
stock = stock.reset_index()
ind1['Date'] = ind1['Date'].apply(lambda x : datetime.datetime.strptime(str(x),'%Y-%m-%d'))
last = pd.merge(ind1,index1,on='Date')
last = pd.merge(last,stock,on='Date')
last['signal3'] = last['signal_x']+last['signal_y']+last['signal']
last['signal4'] = 0
last.loc[last['signal3']>=2,'signal4']=1
last['pct'] = last['close'].pct_change()*last['signal4']
last['cum'] = last['pct'].cumsum()
last['cum'].plot()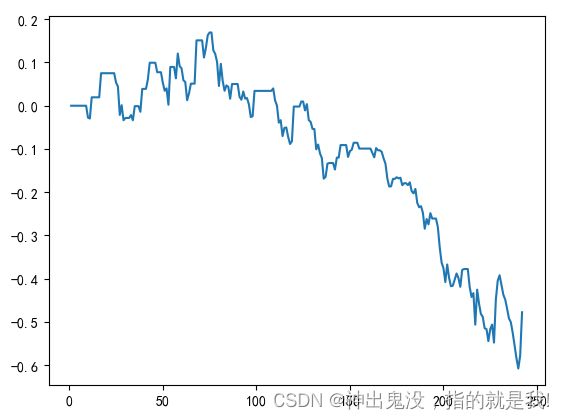
from datetime import datetime,timedelta
df = last
df = df.set_index('Date')
df['当天仓位']=df['signal4'].shift(1)
df['当天仓位'].fillna(method='ffill',inplace=True)
d=df[df['当天仓位']==1].index[0]-timedelta(days=1)
df1=df.loc[d:].copy()
df1['ret'] = df1['close'].pct_change()
df1['ret'][0]=0
df1['当天仓位'][0]=0
#当仓位为1时,买入持仓,当仓位为-1时,空仓,计算资金净值
df1['策略净值']=(df1.ret.values*df1['当天仓位'].values+1.0).cumprod()
df1['指数净值']=(df1.ret.values+1.0).cumprod()
df1['策略收益率']=df1['策略净值']/df1['策略净值'].shift(1)-1
df1['指数收益率']=df1.ret
total_ret=df1[['策略净值','指数净值']].iloc[-1]-1
annual_ret=pow(1+total_ret,250/len(df1))-1
dd=(df1[['策略净值','指数净值']].cummax()-df1[['策略净值','指数净值']])/df1[['策略净值','指数净值']].cummax()
d=dd.max()
beta=df1[['策略收益率','指数收益率']].cov().iat[0,1]/df1['指数收益率'].var()
alpha=(annual_ret['策略净值']-annual_ret['指数净值']*beta)
exReturn=df1['策略收益率']-0.03/250
sharper_atio=np.sqrt(len(exReturn))*exReturn.mean()/exReturn.std()
TA1=round(total_ret['策略净值']*100,2)
TA2=round(total_ret['指数净值']*100,2)
AR1=round(annual_ret['策略净值']*100,2)
AR2=round(annual_ret['指数净值']*100,2)
MD1=round(d['策略净值']*100,2)
MD2=round(d['指数净值']*100,2)
S=round(sharper_atio,2)
df1[['策略净值','指数净值']].plot(figsize=(15,7))
plt.title('三重交易策略简单回测',size=15)
bbox = dict(boxstyle="round", fc="w", ec="0.5", alpha=0.9)
plt.text(df1.index[int(len(df1)/5)], df1['指数净值'].max()/1.5, f'累计收益率:\
策略{TA1}%,指数{TA2}%;\n年化收益率:策略{AR1}%,指数{AR2}%;\n最大回撤: 策略{MD1}%,指数{MD2}%;\n\
策略alpha: {round(alpha,2)},策略beta:{round(beta,2)}; \n夏普比率: {S}',size=13,bbox=bbox)
plt.xlabel('')
ax=plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.show()
# 