【云原生】Kubernetes学习笔记
部署
在部署前强调几点
- 不要使用
IPv6, 很多组件都不支持IPv6 - 不要使用最新版本, 最新版本非常不稳定, 甚至可能存在无法运行的bug
- 不要版本更新, 安装后就将版本固定下来, 新的版本可能会引入新功能, 或移除旧功能, 导致Kubernetes无法运行
Kubeadm介绍
- K8s是由多个模块构成的, 而实现核心功能的组件像apiserver/etcd/scheduler本质上都是可执行文件, 因此可以采用Shell脚本等方式打包到服务器
- 但Kubernetes里,这些组件的关系非常复杂, 仅仅使用过shell部署难度很高, 需要有非常专业的运维管理知识才能配置/搭建好集群, 但即使这样, 搭建的过程也非常复杂
- 为了简化Kubernetes的部署工作, 社区里面出现了一个专门用于集群中安装Kubernetes的工具, 名字就是Kubeadm, 寓意为"Kubernetes管理员"
系统架构

使用Kubeadm安装
首先安装kubeadm, kubelet, kubectl三个组件
sudo apt update;
sudo apt install apt-transport-https;
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/kubernetes.gpg > /dev/null
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list > /dev/null
sudo apt update
sudo apt install -y kubeadm=1.23.3-00 kubelet=1.23.3-00 kubectl=1.23.3-00
运行kubeadm init初始化集群
passnight@passnight-s600:~$ sudo kubeadm init --pod-network-cidr=10.244.0.0/16 # 这个是flannel的默认ip
# ..............................................................
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.100.3:6443 --token ************* \
--discovery-token-ca-cert-hash sha256:****************
# ..............................................................
为了普通用户可以使用k8s, 因此执行以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
使用kubeadm join命令加入集群, 记住所有节点都要执行和join命令
passnight@passnight-acepc:~$ sudo kubeadm join 192.168.100.3:6443 --token ************ --discovery-token-ca-cert-hash ************
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
这样就完成安装了
# kubectl成功运行
passnight@passnight-s600:~/.kube$ kubectl version
Client Version: v1.28.1
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.28.1
# 三个节点都成功注册
passnight@passnight-s600:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
passnight-acepc NotReady <none> 18m v1.28.1
passnight-centerm NotReady <none> 14s v1.28.1
passnight-s600 NotReady control-plane 29m v1.28.1
安装helm1
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
安装dashboard2
passnight@passnight-s600:/opt/k8s$ sudo wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml -O kubernetes-dashboard.yml
访问dashboard需要通过Ingress, 并且dashboard默认配置tls, 因此需要先配置tls证书, 这里使用openssl生成一个:
passnight@passnight-s600:/opt/k8s$ sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout kube-dashboard.key -out kube-dashboard.crt -subj "/CN=dashboard.kube.com/O=cluster.passnight.local"
passnight@passnight-s600:/opt/k8s$ sudo chmod a+r kube-dashboard.crt
passnight@passnight-s600:/opt/k8s$ sudo chmod a+r kube-dashboard.key
passnight@passnight-s600:/opt/k8s$ kubectl create secret tls ingress-nginx-tls --key kube-dashboard.key --cert kube-dashboard.crt -n ingress-nginx
之后在kubernetes-dashboard中添加Ingress配置
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS" #注意这里:必须指定后端服务为HTTPS服务。
spec:
ingressClassName: nginx
tls:
- hosts:
- k8s.dashboard.local # 主机名
secretName: ingress-nginx-tls # 这里引用创建的secrets
rules:
- host: cluster.passnight.local
http:
paths:
- path: /
pathType: Prefix # 起始与根都进行代理。
backend:
service:
name: kubernetes-dashboard # service名称
port: # 后端端口
number: 443
这样就成功访问了

最后使用以下命令获取token便可成功访问
passnight@passnight-s600:/opt/k8s$ kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get sec
ret | grep admin-user | awk '{print $1}')
但是没有数据, 查看日志报错:
statefulsets.apps is forbidden: User "system:serviceaccount:kubernetes-dashboard:kubernetes-dashboard" cannot list resource "statefulsets" in API group "apps" in the namespace "default"
原因在于dashboard没有权限获取信息3, 为默认角色kubernetes-dashboard添加权限即可完成 访问
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
# Allow Metrics Scraper to get metrics from the Metrics server
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
# Other resources
- apiGroups: [""]
resources: ["nodes", "namespaces", "pods", "serviceaccounts", "services", "configmaps", "endpoints", "persistentvolumeclaims", "replicationcontrollers", "replicationcontrollers/scale", "persistentvolumeclaims", "persistentvolumes", "bindings", "events", "limitranges", "namespaces/status", "pods/log", "pods/status", "replicationcontrollers/status", "resourcequotas", "resourcequotas/status"]
verbs: ["get", "list", "watch"]
- apiGroups: ["apps"]
resources: ["daemonsets", "deployments", "deployments/scale", "replicasets", "replicasets/scale", "statefulsets"]
verbs: ["get", "list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["get", "list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["get", "list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "deployments/scale", "networkpolicies", "replicasets", "replicasets/scale", "replicationcontrollers/scale"]
verbs: ["get", "list", "watch"]
- apiGroups: ["networking.k8s.io"]
resources: ["ingresses", "networkpolicies"]
verbs: ["get", "list", "watch"]
- apiGroups: ["policy"]
resources: ["poddisruptionbudgets"]
verbs: ["get", "list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses", "volumeattachments"]
verbs: ["get", "list", "watch"]
- apiGroups: ["rbac.authorization.k8s.io"]
resources: ["clusterrolebindings", "clusterroles", "roles", "rolebindings", ]
verbs: ["get", "list", "watch"]
锁定版本
本文在章节kubelet时不时宕机介绍的问题原因就是因为使用了最新版本的Kubernetes, 为了防止每次apt update都将kubernetes更新, 所以需要使用apt-mark hold命令将所有节点的版本都固定住
passnight@passnight-s600:~$ sudo apt-mark hold kubeadm kubelet kubectl
kubeadm set on hold.
kubelet set on hold.
kubectl set on hold.
passnight@passnight-centerm:~$ sudo apt-mark hold kubeadm kubelet kubectl
kubeadm set on hold.
kubelet set on hold.
kubectl set on hold.
passnight@passnight-acepc:~$ sudo apt-mark hold kubeadm kubelet kubectl
kubeadm set on hold.
kubelet set on hold.
kubectl set on hold.
可能遇到的问题
使用apt-key add报错已废弃
阿里云默认使用apt-key add添加仓库, 但会报错已废弃,
-
原因见apt-key is deprecated. Manage keyring files in trusted.gpg.d (itsfoss.com)https://itsfoss.com/apt-key-deprecated/4
-
这里将其放于特定的文件中
-
gpg
–enarmor
–dearmrPack or unpack an arbitrary input into/from an OpenPGP ASCII armor. This is a GnuPG extension to OpenPGP and in general not very useful. The --dearmor command can also be used to dearmor PEM armors.
-
The format for two one-line-style entries using the deb and deb-src types is: deb [ option1=value1 option2=value2 ] uri suite [component1] [component2] [...] The URI for the deb type must specify the base of the Debian distribution, from which APT will find the information it needs. suite can specify an exact path, in which case the components must be omitted and suite must end with a slash (/). This is useful for the case when only a particular sub-directory of the archive denoted by the URI is of interest. If suite does not specify an exact path, at least one component must be present. suite may also contain a variable, $(ARCH) which expands to the Debian architecture (such as amd64 or armel) used on the system. This permits architecture-independent sources.list files to be used. In general this is only of interest when specifying an exact path; APT will automatically generate a URI with the current architecture otherwise. Example: "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" "deb http://us.archive.ubuntu.com/ubuntu trusty main restricted" "deb http://security.ubuntu.com/ubuntu trusty-security main restricted"
初始化集群报错容器运行时无法启动
passnight@passnight-s600:~$ sudo kubeadm init
[init] Using Kubernetes version: v1.28.1
[preflight] Running pre-flight checks
[WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2023-08-27T15:58:20+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
尝试重新安装container5
passnight@passnight-s600:~$ sudo apt remove containerd
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
Package 'containerd' is not installed, so not removed
0 upgraded, 0 newly installed, 0 to remove and 2 not upgraded.
passnight@passnight-s600:~$ sudo apt install containerd.io
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
containerd.io is already the newest version (1.6.22-1).
containerd.io set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 2 not upgraded.
passnight@passnight-s600:~$
发现已经安装最新版的container, 推测是否是因为k8s与容器运行时接口(Container Runtime Interface)通信出现问题:
passnight@passnight-s600:~$ sudo vim /etc/containerd/config.toml
# 里面有以下一行; 将这行注释掉并重启容器运行时: disabled_plugins = ["cri"]
passnight@passnight-s600:~$ sudo systemctl restart containerd.service
报错kubelet未正常运行
再次运行kubeadm init, 又报错:
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
查看kubectl的运行状态
# 查看kukbectl运行状态, 发现运行失败
passnight@passnight-s600:/opt/docker/portainer$ sudo systemctl status kubelet
#.....
Main PID: 1731962 (code=exited, status=1/FAILURE)
#......
# 查看运行日志
passnight@passnight-s600:/opt/docker/portainer$ sudo journalctl -xefu kubelet
发现有以下一行日志:
"command failed" err="failed to run Kubelet: running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false.
尝试关闭swap6
passnight@passnight-s600:/opt/docker/portainer$ sudo vim /etc/fstab
# 注释掉最后一行 /swapfile ........
# 这里要重启才能生效, 为了不重启使用以下命令关闭swap
passnight@passnight-s600:/opt/docker/portainer$ sudo swapoff -a
再次查看kubectl运行状态, 发现可以正常运行
passnight@passnight-s600:/opt/docker/portainer$ sudo systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Sun 2023-08-27 17:01:48 CST; 33s ago
上次运行的文件未被清除
尝试初始化节点
passnight@passnight-s600:/opt/docker/portainer$ sudo kubeadm init
[init] Using Kubernetes version: v1.28.1
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
发现上次失败的脏文件未被清除, 清除他们
passnight@passnight-s600:/opt/docker/portainer$ sudo kubeadm reset
[reset] Reading configuration from the cluster...
[reset] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
W0827 17:06:50.285497 1743915 reset.go:120] [reset] Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get config map: configmaps "kubeadm-config" not found
W0827 17:06:50.285549 1743915 preflight.go:56] [reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W0827 17:06:55.387873 1743915 removeetcdmember.go:106] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] Deleted contents of the etcd data directory: /var/lib/etcd
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of directories: [/etc/kubernetes/manifests /var/lib/kubelet /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
节点状态显示NOT READY
但是节点状态都显示NOT READY,
passnight@passnight-s600:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
passnight-acepc NotReady <none> 18m v1.28.1
passnight-centerm NotReady <none> 14s v1.28.1
passnight-s600 NotReady control-plane 29m v1.28.1
原因在于部分组件没有成功运行7; 这是需要安装Flannel网络插件
passnight@passnight-s600:~$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5dd5756b68-cnmbf 0/1 Pending 0 29m
coredns-5dd5756b68-wjsj4 0/1 Pending 0 29m
etcd-passnight-s600 1/1 Running 51 (98s ago) 29m
kube-apiserver-passnight-s600 1/1 Running 57 (97s ago) 30m
kube-controller-manager-passnight-s600 1/1 Running 57 (98s ago) 29m
kube-proxy-65zrs 0/1 ContainerCreating 0 40s
kube-proxy-cfhdm 0/1 ContainerCreating 0 18m
kube-proxy-kpfhr 1/1 Running 12 (53s ago) 29m
kube-scheduler-passnight-s600 1/1 Running 61 (98s ago) 29m
安装这些组件
passnight@passnight-s600:/opt/k8s$ sudo wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
依旧无法正常运行
passnight@passnight-s600:/opt/k8s$ kubectl apply -f kube-flannel.yml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
使用kubectl describe查看容器状态; 发现是cidr没有配置8
passnight@passnight-s600:/opt/k8s$ kubectl logs --namespace kube-flannel kube-flannel-ds-l7ztm
# 里面有一行:
E0828 12:45:37.868277 1 main.go:335] Error registering network: failed to acquire lease: node "passnight-s600" pod cidr not assigned


查看生效状况:
passnight@passnight-s600:/opt/k8s$ kubectl cluster-info dump | grep -m 1 cluster-cidr
"--cluster-cidr=10.244.0.0/16",
忘记了加入集群的token或证书哈希值
可以使用以下命令查询或修改token或证书哈希值
passnight@passnight-s600:~$ kubeadm token list # 列出token
passnight@passnight-s600:~$ kubeadm token create # 创建token
passnight@passnight-s600:~$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex # 查看证书hash
kubelet时不时宕机
系统会时不时宕机, 日志中有, 发现这个bug还没有修复9; 解决该问题需要换版本 这里我遇到的宕机版本为v1.28.1
8月 27 20:31:04 passnight-s600 kubelet[33961]: E0827 20:31:04.227827 33961 cri_stats_provider.go:448] "Failed to get the info of the filesystem with mountpoint" err="unable to find data in memory cache" mountpoint="/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs"
Coredns处于CrashLoopBackOff状态
查看日志
passnight@passnight-s600:/opt/k8s$ kubectl logs --namespace kube-system coredns-64897985d-sxbjv
[INFO] plugin/ready: Still waiting on: "kubernetes"
.:53
[INFO] plugin/reload: Running configuration MD5 = db32ca3650231d74073ff4cf814959a7
CoreDNS-1.8.6
linux/amd64, go1.17.1, 13a9191
[FATAL] plugin/loop: Loop (127.0.0.1:33817 -> :53) detected for zone ".", see https://coredns.io/plugins/loop#troubleshooting. Query: "HINFO 937545321553107581.6503699653106618873."
发现是存在循环, 打开配置文件将loop注释掉10

重启pod 删掉他们, deployment会自动创建, 发现可以正常运行; 顺便将两个coredns缩小到一个11
passnight@passnight-s600:/opt/k8s$ kubectl scale deployments.apps -n kube-system coredns --replicas=1
deployment.apps/coredns scaled
passnight@passnight-s600:/opt/k8s$ kubectl get pods -A | grep coredns
kube-system coredns-64897985d-zjzs2 1/1 Running 0 5m54s
passnight@passnight-s600:/opt/k8s$ kubectl scale deployments.apps -n kube-system coredns --replicas=1
主节点不被调度
主节点默认有污点12因此不被调度, 为了主节点能够被调度, 需要去除master节点上的污点, 使用以下命令13去除节点上的污点14
passnight@passnight-s600:~$ kubectl taint nodes passnight-s600 node-role.kubernetes.io/master-
node/passnight-s600 untainted
passnight@passnight-s600:~$ kubectl describe node passnight-s600 | grep Taint
Taints: <none>
这样添加一个节点就可以调度到master上了
passnight@passnight-s600:/opt/k8s/learn$ sudo vim nginx.yml
# 添加一个replica
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx.yml
deployment.apps/nginx-deployment configured
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6956dcf8c-4z259 1/1 Running 0 22h 10.244.2.5 passnight-acepc <none> <none>
nginx-deployment-6956dcf8c-5n5nf 1/1 Running 0 22h 10.244.2.6 passnight-acepc <none> <none>
nginx-deployment-6956dcf8c-5x268 1/1 Running 0 22h 10.244.1.5 passnight-centerm <none> <none>
nginx-deployment-6956dcf8c-l6ddw 1/1 Running 0 22h 10.244.1.6 passnight-centerm <none> <none>
nginx-deployment-6956dcf8c-xjq75 0/1 ContainerCreating 0 7s <none> passnight-s600 <none>
部分请求无法访问
metrics-server无法访问s600节点, 并报错:
E0902 07:51:04.058052 1 scraper.go:140] "Failed to scrape node" err="Get \"https://[fd12:4abe:6e6e::7f8]:10250/metrics/resource\": dial tcp [fd12:4abe:6e6e::7f8]:10250: connect: cannot assign requested address" node="passnight-s600"
metalLB无法ping通其他节点, 并报错:
ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > component=Memberlist ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > component=Memberlist msg=memberlist: Failed to send indirect ping: write udp 192.168.100.4:7946->[fd12:4abe:6e6e::7f8]:7946: address fd12:4abe:6e6e::7f8: non-IPv4 address from=192.168.100.5:7946 ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > component=Memberlist ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > ERR ERR net.go:640 > component=Memberlist msg=memberlist: Failed to send indirect ping: write udp 192.168.100.4:7946->[fd12:4abe:6e6e::7f8]:7946: address fd12:4abe:6e6e::7f8: non-IPv4 address from=192.168.100.5:7946 ts=2023-09-02T14:26:24Z
原因都在于s600默认使用IPv6, 因此需要改为IPv4
passnight@passnight-s600:/etc/netplan$ nslookup passnight-s600
;; communications error to 127.0.0.1#53: connection refused
;; communications error to 127.0.0.1#53: connection refused
;; communications error to 127.0.0.1#53: connection refused
Server: 192.168.100.1
Address: 192.168.100.1#53
Non-authoritative answer:
;; communications error to 127.0.0.1#53: connection refused
;; communications error to 127.0.0.1#53: connection refused
;; communications error to 127.0.0.1#53: connection refused
Name: passnight-s600.lan
Address: fd12:4abe:6e6e::7f8
passnight@passnight-s600:/etc/netplan$ ping passnight-s600
PING passnight-s600(passnight-s600.lan (fd12:4abe:6e6e::7f8)) 56 data bytes
64 bytes from passnight-s600.lan (fd12:4abe:6e6e::7f8): icmp_seq=1 ttl=64 time=0.050 ms
基本概念
Kubernetes是一个生产级别的容器编排平台和集群管理系统
Kubenetes工作机制
Kubernetes基本架构
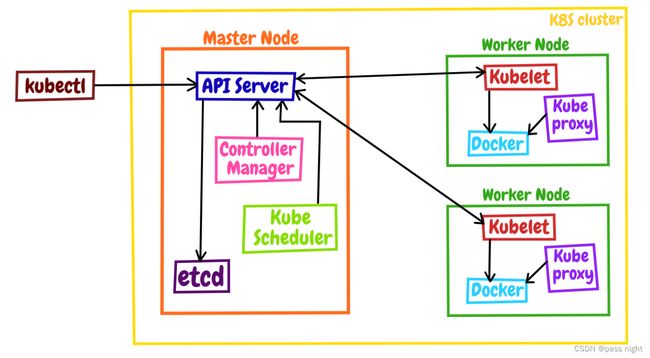
-
Kubernetes将系统分为了控制面/数据面, 集群中的计算机被称为节点 这里记住Master也可以承担Worker的工作
-
控制面节点在Kubernetes中叫做Master Node, 他是集群中控制管理其他节点的节点
-
数据面的节点叫做Worker Node, 一般简称为Worker或Node; 其职责是在Master的指挥下干活
-
kubectl时Kubernetes的客户端工具, 用于操作Kubernetes, 它位于集群之外, 理论上不属于集群
-
可以使用命令
kubectl get node查看Kubernetes的节点状态:passnight@passnight-s600:~$ kubectl get nodes NAME STATUS ROLES AGE VERSION passnight-acepc Ready <none> 22h v1.23.3 passnight-centerm Ready <none> 22h v1.23.3 passnight-s600 Ready control-plane,master 22h v1.23.3
-
-
kubernates中所有的组件都被容器化了, 运行在
kube-system名字空间下, 可以使用以下命令查看:passnight@passnight-s600:/opt/k8s$ kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE etcd-passnight-s600 1/1 Running 0 23h kube-apiserver-passnight-s600 1/1 Running 0 23h kube-controller-manager-passnight-s600 1/1 Running 0 23h kube-proxy-295v8 1/1 Running 0 23h kube-proxy-fzxpj 1/1 Running 0 23h kube-proxy-mblqb 1/1 Running 0 23h kube-scheduler-passnight-s600 1/1 Running 0 23h
核心组件

Kubernetes中Master中的apiserver/scheduler等组件需要获取节点的各种信息才能做出管理决策; 其中需要Node的三个组件: Kubelet, kube-proxy及container-runtime
- kubelet是Node的代理, 负责Node相关的绝大多数操作, 它负责与apiserver通信, 实现Master对Node的管理
- kube-proxy是Node的网络代理, 负责容器的网络通信 简单来说就是为Pod转发TCP/UDP数据包
- container-runtime: 是容器和镜像的实际使用者, 在kubelet的指挥下创建容器/管理Pod的生命周期
- scheduler通过apiserver得到当前的节点状态, 调度Pod, 然后apiserver下发命令给某个Node的kubelet
- controller-manager通过apiserver得到实时的节点状态, 监控可能得异常情况, 再使用相应的手段去恢复
可以使用docker ps查看kube-proxy等容器
passnight@passnight-s600:/opt/k8s$ docker ps | grep kube-proxy
b1f80552c637 f21c8d21558c "/usr/local/bin/kube…" 23 hours ago Up 23 hours
k8s_kube-proxy_kube-proxy-295v8_kube-system_4d9d98e6-2c39-4912-8245-75c215ce71e2_0
1d3b483e3571 k8s.gcr.io/pause:3.6 "/pause" 23 hours ago Up 23 hours
k8s_POD_kube-proxy-295v8_kube-system_4d9d98e6-2c39-4912-8245-75c215ce71e2_0
使用系统命令查看kubelet
passnight@passnight-s600:/opt/k8s$ ps -e | grep kubelet
16149 ? 02:44:00 kubelet
插件
passnight@passnight-s600:/opt/k8s$ kubectl plugin list
error: unable to find any kubectl plugins in your PATH
Pod概念
-
Pod的意义
- 例如在WordPress网站的例子中, 需要Nginx/WordPress/MariaDB三个容易一起工作
- 例如在日志代理中, 如果将日志拆分到另一个容器中, 日志模块便无法工作
- 倘若上面两个情况将多个进程都放在一个容器中便违背了容器的初衷, 因为容器的理念是对应用的独立的封装; 这样使得容器变得更加难以管理
- 为了解决这个问题, 同时不破坏容器的隔离, 就需要在容器外面再建立一个组, pod便是用于管理这个容器组的概念
-
Pod的概念:
-
Pod是对容器的打包, 里面的容器是一个整体, 他们总是能够一起调度/运行
-
Pod是容器调度的最小单位; 是Kubernetes中的原子
-
如下图所示, Kubernetes基本其他的功能都是基于Pod衍生或实现的

-
-
下面是创建一个pod的例子:
- 首先编写对应的yml配置文件
apiVersion: v1 kind: Pod metadata: # 包含一下基本数据 name: busy-pod # pod名字 labels: # 给pod贴标签, 便于pod的识别和管理 owner: passnight # owner env: demo # 系统的运行环境; 这里表示运行环境为demo, 可以根据实际情况随便填 region: north #选择数据中心区域 tier: back # 选择系统中的层次 spec: # 用于维护和管理Pod; 包含许多关键的信息 containers: - image: busybox:latest # 容器 name: busy # 容器名 imagePullPolicy: IfNotPresent # 镜像拉取策略, 人如其名表示只有本地不存在才会从网络拉取, 由Always/Never/IfNotPresent三个选项 env: # 定义Pod的环境变量, 类似于Dockerfile中的ENV指令; 但它是运行时指定的, 配置更加灵活 - name: os value: "ubuntu" - name: debug value: "on" command: # 定义启动容器所要执行的命令, 相当于Dockerfile中的ENTRYPOINT指令 - /bin/echo args: # command运行时的参数, 相当于Dockerfile的CMD指令 - "$(os), $(debug)"-
使用
kubectl apply创建或是kubectl delete删除kubectl apply -f busy-pod.yml # 根据busy-pod.yml创建pod kubectl delete -f busy-pod.yml # 根据busy-pod.yml删除pod kubectl delete pod busy-pod # 因为在yml文件中对pod命名, 所以可以直接通过名字删除pod passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f busy-pod.yml pod/busy-pod created passnight@passnight-s600:/opt/k8s/learn$ kubectl logs busy-pod ubuntu, on # 可以看到 启动后执行了command中定义的命令 passnight@passnight-s600:~$ kubectl get pods NAME READY STATUS RESTARTS AGE busy-pod 0/1 CrashLoopBackOff 277 (61s ago) 23h # 这里busy-pod一直处于CrashLoopBackOff状态是因为它执行完任务后就会退出, 而退出后k8s引擎为了可用性会自动将其重启
Job/CronJob
相比于Nginx这样长时间运行的在线业务; 还有非常多计算量很大, 但是只会运行一段时间的离线业务; 相比于在线业务, 他们的调度策略有很大的不同, 因为他们要考虑: 运行超时/状态检查/失败重试/获取计算结果等事项
这样的离线业务分为两种, 一种是跑完就完事的临时任务; 另一种是按点周期运行的定时任务; 这样的临时任务对应的就是Job, 而定时任务对应的事CronJob
Job的创建
以下是一个创建job的例子, 它创建一个job对象, 这个job会输出hello world然后退出
apiVersion: batch/v1 #job这里要填batch/v1
kind: Job # 类型为job
metadata:
name: echo-job
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
然后使用apply命令创建就可以了
# 创建job
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f busy-job.yml
job.batch/echo-job created
# 查看job, 这里只有一个作业, 而它已经被完成了
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
echo-job 1/1 1s 6s
# 可以看到, 如果设置为job模式, 就不会因为运行结束重启而报错了, 而是显示为completed状态
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
echo-job-2rfrl 0/1 Completed 0 58s
# 查看job的标准输出, 可以看到`hello world`已经被打印了
passnight@passnight-s600:/opt/k8s/learn$ kubectl logs echo-job-2rfrl
hello world
job的基本使用

相比于简单的容器, Kubernetes提供了许多重要的控制离线作业的手段, 下面以一个"sleep-job"为例, 列举几个比较重要的字段
apiVersion: batch/v1
kind: Job
metadata:
name: sleep-job
spec:
# 这里数字设置的比较大的原因是主节点性能太强, 若不设置的比较大从节点不会被分配任务
activeDeadlineSeconds: 15 # 设置运行的超时时间为15s
backoffLimit: 200 # 设置重试次数为200次
completions: 400 # 完成job需要400个pod
parallelism: 5 # 允许同时50个pod运行
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- sleep $(($RANDOM % 10 + 1)) && echo done
创建后观察运行结果:
# k8s创建了两个job并行执行
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sleep-job-2h9w6 0/1 ContainerCreating 0 6s <none> passnight-acepc <none> <none>
sleep-job-44plp 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-4mpb8 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-4vpkq 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-4xcxq 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-5dzgt 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-5fclt 0/1 ContainerCreating 0 6s <none> passnight-acepc <none> <none>
sleep-job-5k6mg 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-5n6wh 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-67rms 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-6dwdh 0/1 ContainerCreating 0 7s <none> passnight-s600 <none> <none>
sleep-job-6xtlb 0/1 ContainerCreating 0 7s <none> passnight-s600 <none> <none>
sleep-job-7pbc6 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-7qkwv 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-85xqb 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-87hfn 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-8fl59 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-8gnfd 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-95mql 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-9ck9c 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-9mnvs 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-b6489 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-bg279 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-c4hkp 0/1 ContainerCreating 0 7s <none> passnight-s600 <none> <none>
sleep-job-cb4rd 0/1 ContainerCreating 0 6s <none> passnight-centerm <none> <none>
sleep-job-cpsmq 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-dgmzb 1/1 Running 0 7s 10.244.1.11 passnight-centerm <none> <none>
sleep-job-g2lkw 1/1 Running 0 7s 10.244.1.10 passnight-centerm <none> <none>
sleep-job-k2cb4 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-krgst 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-l25cv 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-ldd2b 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-lmjtl 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-mmckm 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-mx8jc 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-n2hvm 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-nj5vn 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-ntql9 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-q87h6 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-rb59f 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-rssd9 0/1 ContainerCreating 0 7s <none> passnight-s600 <none> <none>
sleep-job-thxnd 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-ts7b9 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-v2dxj 0/1 ContainerCreating 0 7s <none> passnight-s600 <none> <none>
sleep-job-vgf5n 0/1 Pending 0 6s <none> passnight-s600 <none> <none>
sleep-job-wgpsj 0/1 ContainerCreating 0 7s <none> passnight-acepc <none> <none>
sleep-job-wnwpk 0/1 ContainerCreating 0 7s <none> passnight-s600 <none> <none>
sleep-job-xjzx5 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-zknzt 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
sleep-job-zr2st 0/1 Pending 0 7s <none> passnight-s600 <none> <none>
# 可以看到不断有任务完成
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 16/400 29s 29s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 17/400 30s 30s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 17/400 31s 31s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 17/400 31s 31s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 18/400 32s 32s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 19/400 32s 32s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
sleep-job 19/400 33s 33s
CronJob

以下是一个定期输出hello world的定时任务; 它包含了三个spec, 第一个是对CronJob自己的对象规格声明, 第二个属于jobTemplate定义了一个Job对象, 第三个属于template定义了Job里面运行的Pod
apiVersion: batch/v1
kind: CronJob
metadata:
name: echo-cj
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-cj
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
可以看到在到达时间后按创建了两个pod和两个job
passnight@passnight-s600:/opt/k8s/learn$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
echo-cj-28223421 1/1 0s 64s
echo-cj-28223422 1/1 1s 4s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
echo-cj-28223421-jd2r5 0/1 Completed 0 67s
echo-cj-28223422-rvmb6 0/1 Completed 0 7s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
echo-cj */1 * * * * False 0 14s 2m
Configmap&Secret
- 对于容器的配置文件, 由以下几种方式可以实现:
- 使用
COPY指令, 将配置文件打包到镜像中, 这样子将配置文件固定到了镜像中, 不利于配置的修改 - 使用
docker cp或docker run -v将配置文件拷入/挂载到容器中, 这种方法则有些笨拙, 在大规模集群中不利于自动化运维
- 使用
- 因此Kubernetes定义了两个API对象: ConfigMap和Secret, 一个用于保存明文配置, 另一个用于保存密文配置
ConfigMap
ConfigMap是一个用于保存明文配置的对象, 配置完成后它会被保存到etcd数据库中; 我们可以使用yml文件创建configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: info
data:
count: '10'
debug: 'on'
path: '/etc/systemd'
greeting: |
say hello to kubernetes.
在编写完配置文件后, 同job和pod一样, 使用apply命令使其生效:
# 创建configmap
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f config-map.yml
configmap/info created
# 获取configmap, 可以看到info已经创建完成
passnight@passnight-s600:/opt/k8s/learn$ kubectl get configmap
NAME DATA AGE
info 4 10s
kube-root-ca.crt 1 2d1h
# 使用describe命令查看对应的配置
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe configmap info
Name: info
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
count:
----
10
debug:
----
on
greeting:
----
say hello to kubernetes.
path:
----
/etc/systemd
BinaryData
====
Events: <none>
Secret
使用yml创建Secret
apiVersion: v1
kind: Secret
metadata:
name: user
# 以下数据使用base64进行编码
data:
name: cm9vdA== # root
pwd: MTIzNDU2 # 123456
db: bXlzcWw= # mysql
查看结果
# 创建Secret
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f secret.yml
secret/user created
# 获取Secret
passnight@passnight-s600:/opt/k8s/learn$ kubectl get secret
NAME TYPE DATA AGE
default-token-2xwzf kubernetes.io/service-account-token 3 2d1h
user Opaque 3 6s
# 查看Secret
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe secret user
Name: user
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
db: 5 bytes
name: 4 bytes
pwd: 6 bytes
以环境变量的形式使用
倘若配置是环境变量, 则可以使用configMapKeyRef来引用ConfigMap, 使用secretKeyRef来引用Secret, 下面则是一个例子:
apiVersion: v1
kind: Pod
metadata:
name: env-pod
spec:
containers:
- env:
- name: COUNT
valueFrom:
configMapKeyRef:
name: info
key: count
- name: GREETING
valueFrom:
configMapKeyRef:
name: info
key: greeting
- name: USERNAME
valueFrom:
secretKeyRef:
name: user
key: name
- name: PASSWORD
valueFrom:
secretKeyRef:
name: user
key: pwd
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
通过valueFrom定义了值的来源, 下图更加形象地阐释了pod配置和k8s管理的配置之间的关系:

passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f secret.yml
secret/user created
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f config-map.yml
configmap/info created
passnight@passnight-s600:/opt/k8s/learn$ sudo vim env-config.yml
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods | grep env
env-pod 1/1 Running 0 8s
passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it env-pod sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ #
/ # echo $COUNT
10
/ # echo $USERNAME
root
/ # echo $PASSWORD
123456
/ #
可以看到环境变量成功从ConfigMap/Secret中获取了
以配置文件的形式使用
k8s的Volume可以直接使用ConfigMap和Secret创建, 如下面的配置文件, 定义了两个volume, 分别由ConfigMap和Secret创建
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user
在有了volume之后, 就可以通过volumeMounts命令将他们挂载到容器里面了
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
同样的, 可以使用一张图来表示他们之间的关系:

apiVersion: v1
kind: Pod
metadata:
name: vol-pod
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
根据上述配置文件创建pod, 并进入容器, 可以看到对应的配置文件得以创建
passnight@passnight-s600:/opt/k8s/learn$ sudo vim file-config.yml
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f file-config.yml
pod/vol-pod created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods | grep vol
vol-pod 1/1 Running 0 13s
passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it vol-pod sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ #
/ # cd /tmp
/tmp # ls
cm-items sec-items
/tmp # cd cm-items/
/tmp/cm-items # ls
count debug greeting path
/tmp/cm-items # cat greeting
say hello to kubernetes.
/tmp/cm-items # cd ../sec-items/
/tmp/sec-items # ls
db name pwd
/tmp/sec-items # cat pwd
123456/tmp/sec-items # cat db
mysql/tmp/sec-items #
可以看到, 每个key都作为一个文件被创建了
Deployment


-
Deployment:
-
意义
- 尽除了离线业务, k8s中还有一大类业务是在线业务, 他们需要某些统一的管理
- 在pod中有一个
restartPolicy字段可以控制容器在异常的时候重启, 但当集群故障或是不小心使用了kubectl delete导致pod消失, 此时restartPolicy就不再能够保证容器的可用性 - 除了重启以外, 还有多实例/高可用/版本更新等复杂操作都是仅仅有pod无法支持的, 为了能够对pod有自动化的管理, kubernetes引入了Deployment的概念
-
查看
Deployment基本信息:# 使用api-resources命令查看deployments的基本信息 passnight@passnight-s600:/opt/k8s/learn$ kubectl api-resources | grep deployment deployments deploy apps/v1 true Deployment
-
使用yml描述Deployment
下面是一个通过Kubernetes创建Nginx集群的配置文件
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
spec:
replicas: 2 # 相比于pod多的新字段, 可以用于描述副本数; 表示集群中的pod实例数量
selector:
matchLabels:
app: ngx-dep # 创建带有ngx-dep标签的模板的容器
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:alpine
name: nginx
-
运行结果:
# deployments被成功创建; 且根据下面多次查看, 可以看到deployments中的avaiables与pods之间的关系 passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE ngx-dep 0/2 2 0 4s passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods NAME READY STATUS RESTARTS AGE ngx-dep-bfbb5f64b-5jcdv 0/1 ContainerCreating 0 9s ngx-dep-bfbb5f64b-g68gj 0/1 ContainerCreating 0 9s passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE ngx-dep 1/2 2 1 19s passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods NAME READY STATUS RESTARTS AGE ngx-dep-bfbb5f64b-5jcdv 0/1 ContainerCreating 0 21s ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 21s passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE ngx-dep 1/2 2 1 26s passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE ngx-dep 2/2 2 2 31s passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods NAME READY STATUS RESTARTS AGE ngx-dep-bfbb5f64b-5jcdv 1/1 Running 0 33s ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 33s-
如上图所示,
READY表示运行的pod的数量, 可以看到随着时间推移两个pod被逐渐创建 -
UP-TO-DATE表示更新到最新状态的pod的数量, 倘若有多个pod需要部署, 而pod的启动速度比较慢, 就需要等待一段时间使Deployment完全生效 -
AVAIABLE比READY和UP-TO-DATE更进一步, 其不仅要求容器已经运行, 而且能够正常对外提供服务 -
AGE表示容器从创建开始到现在所经过的时间, 即运行时间 -
这里我们删除一个pod, 发现Deployment立即又创建一个pod, 做到永不宕机的效果:
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods NAME READY STATUS RESTARTS AGE ngx-dep-bfbb5f64b-5jcdv 1/1 Running 0 4m53s ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 4m53s passnight@passnight-s600:/opt/k8s/learn$ kubectl delete pod ngx-dep-bfbb5f64b-5jcdv pod "ngx-dep-bfbb5f64b-5jcdv" deleted # 在上一个pod被删除后, kubernetes又为我们创建了一个新的pod, 注意age较小的名字和被删除的不一样 passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods NAME READY STATUS RESTARTS AGE ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 5m6s ngx-dep-bfbb5f64b-xgm7s 1/1 Running 0 2s
-
自动扩缩容
除了自动维持pod的数量外, 还可以通过scale命令进行扩容/缩容
# 扩容到5个
passnight@passnight-s600:/opt/k8s/learn$ kubectl scale --replicas=5 deploy ngx-dep
deployment.apps/ngx-dep scaled
# 可以看到在集群的不同节点扩容到5个
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ngx-dep-bfbb5f64b-d47kr 1/1 Running 0 26s 10.244.2.14 passnight-acepc <none> <none>
ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 7m45s 10.244.1.16 passnight-centerm <none> <none>
ngx-dep-bfbb5f64b-nfhjk 1/1 Running 0 26s 10.244.0.165 passnight-s600 <none> <none>
ngx-dep-bfbb5f64b-v94db 1/1 Running 0 26s 10.244.1.17 passnight-centerm <none> <none>
ngx-dep-bfbb5f64b-xgm7s 1/1 Running 0 2m41s 10.244.0.164 passnight-s600 <none> <none>
# 然后再缩容到3个
passnight@passnight-s600:/opt/k8s/learn$ kubectl scale --replicas=3 deploy ngx-dep
deployment.apps/ngx-dep scaled
# 可以看到在集群中的不同节点中被缩容到3个
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ngx-dep-bfbb5f64b-d47kr 1/1 Running 0 38s 10.244.2.14 passnight-acepc <none> <none>
ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 7m57s 10.244.1.16 passnight-centerm <none> <none>
ngx-dep-bfbb5f64b-xgm7s 1/1 Running 0 2m53s 10.244.0.164 passnight-s600 <none> <none>
标签使用
对于标签的使用, 我们可以很容易地使用-l参数来查看各种被贴了标签的参数
# 查看app标签是nginx的所有pod
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod -l app=nginx
No resources found in default namespace.
# 查看app标签在 (ngx, nginx, ngx-dep)中的所有pod
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod -l 'app in (ngx, nginx, ngx-dep)'
NAME READY STATUS RESTARTS AGE
ngx-dep-bfbb5f64b-d47kr 1/1 Running 0 2m36s
ngx-dep-bfbb5f64b-g68gj 1/1 Running 0 9m55s
ngx-dep-bfbb5f64b-xgm7s 1/1 Running 0 4m51s
- 功能:
replicas字段用于描述副本数量; 可以根据定义的期望状态来动态的调整集群中的副本数量selector: 用于筛选出别管理的Pod对象, 下属字段matchLabels定义了Pod对象应该携带的label, 其与template里Pod定义的labels完全相同- kubernetes通过贴标签的方式, 在API对象的
metadata元信息里加各种标签, 这样解除了Deployment模板和pod的强绑定, 将关系变成了弱引用 这么做的原因是在线上服务中, pod还可能被其他api对象管理, 因此不能作为强引用与Deployment绑定在一起, 如pod除了由Deployment管理, 还要由Service负载均衡
Service
- Service:
- 由于每个pod都有唯一的ip地址等信息, 因此需要一个概念将其抽象, 以便于对于无服务的pod进行扩容和缩容
- Service提供了这样一个抽象层, 它为具备某些特征的pod定义了一个访问方式
- 创建Service的时候, 可以通过
spec.type字段的值, 配置向外暴露应用程序的方式 - Service通过Labels和LabelSelector匹配一组Pod 尽管Nginx/LVS也提供了类似的功能, 但未能和k8s紧密结合
- 实现原理
-
其实现原理也很简单: 就是为pod分配一个静态的ip地址, 然后去自动管理, 维护后面动态变化的pod集合
-
如上图所示, Service使用了iptables技术, 每个节点上的
kube-proxy组件自动维护iptables规则, 客户不需要关系具体Pod的地址, 只需要访问Service的固定的IP地址, Service就会根据iptables规则转发请求给她管理的多个pod Service除了使用iptables还可以使用性能更差的userspace和性能更好地ipvs
-
使用YAML描述Service

-
除了使用
yml创建Service, 还可以通过expose命令直接暴露服务地址 -
如上面创建的nginx集群就可以通过
kubectl expose暴露:passnight@passnight-s600:/opt/k8s/learn$ kubectl expose deploy ngx-dep --port=30080 --target-port=80 # 这样就可以创建service了 passnight@passnight-s600:/opt/k8s/learn$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d2h -
当然, 更正式地我们应该使用yml创建service
apiVersion: v1 kind: Service metadata: name: ngx-svc spec: selector: app: ngx-dep ports: - port: 30080 targetPort: 80 protocol: TCP -
这样就可以完成创建了
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx-service-simply.yml service/ngx-svc created # 创建了一个service, 类型为ClusterIP passnight@passnight-s600:/opt/k8s/learn$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d2h ngx-svc ClusterIP 10.99.215.93 <none> 30080/TCP 4s -
我们还可以通过
describe查看被代理的地址passnight@passnight-s600:/opt/k8s/learn$ kubectl describe svc ngx-svc Name: ngx-svc Namespace: default Labels: <none> Annotations: <none> Selector: app=ngx-dep Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.99.215.93 IPs: 10.99.215.93 Port: <unset> 30080/TCP TargetPort: 80/TCP Endpoints: 10.244.0.167:80,10.244.1.19:80 Session Affinity: None Events: <none> # 可以看到endpoints和pods的ip相同 passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ngx-dep-bfbb5f64b-4w9fq 1/1 Running 0 6m1s 10.244.1.19 passnight-centerm <none> <none> ngx-dep-bfbb5f64b-zcpqm 1/1 Running 0 6m1s 10.244.0.167 passnight-s600 <none> <none> # 这样我们就可以通过代理ip访问 passnight@passnight-s600:/opt/k8s/learn$ curl 10.99.215.93:30080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> # 等等等等 # 或是通过集群ip访问 passnight@passnight-s600:/opt/k8s/learn$ curl 10.244.1.19:80 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> # 等等等等 # 进入容器内部, 发现容器被赋予的外部访问ip就是对应的endpoints passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it ngx-dep-bfbb5f64b-4w9fq sh kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. / # ifconfig eth0 Link encap:Ethernet HWaddr AA:56:4A:25:A2:47 inet addr:10.244.1.19 Bcast:10.244.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1 RX packets:15 errors:0 dropped:0 overruns:0 frame:0 TX packets:9 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1149 (1.1 KiB) TX bytes:1371 (1.3 KiB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:20 errors:0 dropped:0 overruns:0 frame:0 TX packets:20 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:2240 (2.1 KiB) TX bytes:2240 (2.1 KiB) / # # 删除pod后Deployment立马创建了一个新的pod, 并赋予了一个新的ip passnight@passnight-s600:/opt/k8s/learn$ kubectl delete pod ngx-dep-bfbb5f64b-4w9fq pod "ngx-dep-bfbb5f64b-4w9fq" deleted passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ngx-dep-bfbb5f64b-qpwg5 1/1 Running 0 6s 10.244.2.16 passnight-acepc <none> <none> ngx-dep-bfbb5f64b-zcpqm 1/1 Running 0 14m 10.244.0.167 passnight-s600 <none> <none>
使用域名访问Service
-
尽管
Service对象的ip是静态的, 但是使用数字形式的IP地址还是不方便, Kubernetes为此提供了DNS插件使我们可以通过域名访问Service -
在介绍域名之前, 还需要了解名字空间(namespace):
-
可以通过
get命令查看所有namespace:passnight@passnight-s600:/opt/k8s/learn$ kubectl get namespaces NAME STATUS AGE default Active 2d2h kube-flannel Active 25h kube-node-lease Active 2d2h kube-public Active 2d2h kube-system Active 2d2h kubernetes-dashboard Active 2d1h # 可以看到我的集群中有这些namespace; 其中默认的名字空间是default, 若不显示制定, API对象都会在这个名字空间里面
-
-
这样我们就可以通过
对象.名字空间.svc.cluster访问, 甚至可以通过对象.名字空间访问; 倘若是默认的名字空间, 还可以直接使用对象名访问:passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it ngx-dep-bfbb5f64b-qpwg5 sh kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. / # ping ngx-dep-bfbb5f64b-qpwg5 PING ngx-dep-bfbb5f64b-qpwg5 (10.244.2.16): 56 data bytes 64 bytes from 10.244.2.16: seq=0 ttl=64 time=0.165 ms ^C --- ngx-dep-bfbb5f64b-qpwg5 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.165/0.165/0.165 ms / # ping ngx-dep-bfbb5f64b-qpwg5.default PING ngx-dep-bfbb5f64b-qpwg5.default (198.18.29.3): 56 data bytes 64 bytes from 198.18.29.3: seq=0 ttl=60 time=1.127 ms ^C --- ngx-dep-bfbb5f64b-qpwg5.default ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 1.127/1.127/1.127 ms / # ping ngx-dep-bfbb5f64b-qpwg5.default.svc.cluster PING ngx-dep-bfbb5f64b-qpwg5.default.svc.cluster (198.18.29.4): 56 data bytes 64 bytes from 198.18.29.4: seq=0 ttl=60 time=1.270 ms ^C --- ngx-dep-bfbb5f64b-qpwg5.default.svc.cluster ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 1.270/1.270/1.270 ms -
顺便一提, Kubernetes还为每个pod分配了域名, 可以将ip中的
.改为-后访问:/ # ping 10-244-2-16.default.pod PING 10-244-2-16.default.pod (10.244.2.16): 56 data bytes 64 bytes from 10.244.2.16: seq=0 ttl=64 time=0.118 ms / # ping 10-244-2-16.default PING 10-244-2-16.default (198.18.29.5): 56 data bytes 64 bytes from 198.18.29.5: seq=0 ttl=60 time=1.354 ms / # ping 10-244-2-16.pod PING 10-244-2-16.pod (198.18.29.6): 56 data bytes 64 bytes from 198.18.29.6: seq=0 ttl=60 time=0.951 ms
让Service对外暴露服务
Service对象有一个关键字段**type**; 用于表示其是那种类型的负载均衡, 其特征如下:
| type | 功能 |
|---|---|
| ClusterIP(默认) | ClusterIP(默认): 在集群内部IP上公布服务, 这种方式只能在集群内部访问到 |
| ExternalName | 接受域名, 集群DNS返回CNAME记录, 转发到对应的pod中 |
| LoadBalancer | 在云环境中, 创建一个集群外部的负载均衡器, 并使用该负载均衡器的IP地址作为服务的访问地址 此时ClusterIP和NodePort依旧可以使用 |
| NodePort | NodePort: 使用NAT在集群中每个的同一端口上公布服务, 这种方式下, 可以通过任意节点+端口号访问服务, 其格式为NodeIP:NodePort 此时ClusterIP依然可以使用 |
尽管NodePort好像功能最全面, 但也有一下缺点:
- 为了避免冲突, 默认只能在300000~32767之间分配, 都不是标准端口号, 也不够用
- 然后使用 kube-proxy 路由到真正的后端 Service,这对于有很多计算节点的大集群来说就带来了一些网络通信成本
- 它要求向外界暴露节点的 IP 地址,这在很多时候是不可行的,为了安全还需要在集群外再搭一个反向代理,增加了方案的复杂度。
DaemonSet
- Deployment 不关心pod在哪些节点上运行, 它运行的大多数都是与环境无关的应用, 如Nginx/MySQL等; 只要配置好环境变量和存储卷, 在哪里跑都一样
- 但是有一些应用比较特殊, 它并不是完全独立于系统运行的, 而是与主机存在"绑定关系", 需要依附于某个节点才能产生价值, 如:
- 网络应用(如kube-porxy): 每个节点必须运行一个pod, 否则节点无法加入kubernetes网络
- 监控应用(如Prometheus): 每个节点必须有一个pod来监控节点的状态
- 日志应用(Fluentd): 每个节点上运行一个pod, 才能够手机容器运行时产生的日志
- 安全应用: 每个节点都要有一个pod来执行安全审计/入侵检查/漏洞扫描
- 这样如果使用Deployment就不合适了, 因为其数量可能会在集群中"漂移", 而实际的需求是每个Node一个这样的Pod
- 为了解决这个问题, Kubernetes定义了API对象DaemenSet; 它形式上和Deployment类似, 都是用于管理控制Pod的对象, 但调度策略不同, DaemenSet的目标是在集群的每个节点上进运行一个Pod, 就好像一个守护神"守护"这节点, 这就是DaemonSet名字的由来
Yaml描述DaemeonSet
我们通过以下命令在每个节点上创建一个Redis
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: redis-ds
labels:
app: redis-ds
spec:
selector:
matchLabels:
name: redis-ds
template:
metadata:
labels:
name: redis-ds
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379

DaemonSet的配置文件几乎和Deployment一模一样, 唯一的区别就是spec中没有replicas字段, 因为它的目标是在每个节点上创建一个pod实例, 而不是在集群中创建多个副本
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f daemon-set.yml
daemonset.apps/redis-ds created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get daemonsets
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
redis-ds 3 3 0 3 0 <none> 7s
# 可以看到, DaemonSet在每个Node上都创建了一个pod
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-ds-76lnv 0/1 ContainerCreating 0 13s <none> passnight-acepc <none> <none>
redis-ds-7j4m6 0/1 ContainerCreating 0 13s <none> passnight-s600 <none> <none>
redis-ds-zwljl 0/1 ContainerCreating 0 13s <none> passnight-centerm <none> <none>
静态pod
- DaemonSet是在Kubernetes中运行节点转数Pod最常用的方式, 但他并不是唯一的方式, 还有一种方式叫做静态Pod
- 静态Pod非常特殊, 它不受Kubernetes的管控, 不与apiserver和scheduler发生关系, 所以是静态的
- 它是存在于
/etc/kubernetes/manifests目录下, 这是Kubernetes的专用目录 - 由下面代码框可以看到, Kubernetes的4个核心组件
apiserver/etcd/scheduler和controller-manager都是以静态pod的形式启动, 这也是他们为什么能够先于Kubernetes集群启动的原因
passnight@passnight-s600:/opt/k8s/learn$ ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
Ingress

- 尽管Service提供了对pod的暴露和访问机制, 但也只能算是基础设施; Kubernetes在此基础之上提出了一个新的概念Ingress
- 在应用层协议上, 还有例如主机名/URL/请求头/证书等更加高级的路由条件, 这些条件也是Service在网络层无法管理的
- 除了七层负载均衡, 这个对象还应该承担更多的职责, 也就是作为流量的总入口; 统管集群的进出口数据
Ingress 实现
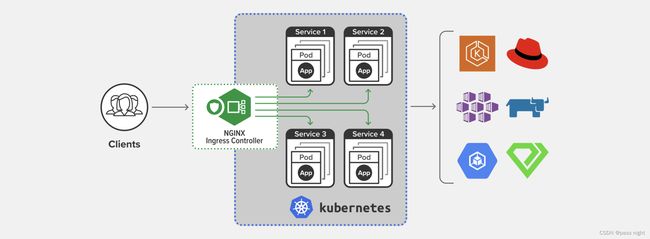
-
Ingress Controller
- 在Kubernetes中, Service只是一些iptables规则, 真正配置/应用这些规则的实际上是kube-porxy组件
- 同样的, Ingress是一些HTTP路由规则的集合, 真正管理的事Ingress Controller; 它相当于Service 的kube-proxy
- Ingress Controller是一个协议, 其实现是由社区完成的, 最著名/常用的就是老牌反向代理/负载均衡软件Nginx了
-
IngressClass
- 对于不同应用, 需要引入不同的Ingress Controller; 但Kubernetes不允许这么做
- Ingress规则太多, 都交给一个Ingress Controller会让他不堪重负
- 多个Ingress对象没有很好的逻辑分组方式, 管理和维护成本很高
- 进群里面有不同租户, 他们呢对Ingress的需求差异很大甚至有冲突, 无法部署在同一个Ingress Controller上
- 为此, Kubernetes提出了一个Ingress Class的概念, 让它在Ingress和Ingress Controller之间做协调人
Ingress Class使用
同Deployment和Service一样, 可以使用api-resources查看ingress资源
passnight@passnight-s600:~$ kubectl api-resources | grep ingress
ingressclasses networking.k8s.io/v1 false IngressClass
ingresses ing networking.k8s.io/v1 true Ingress
同样地, 可以使用yml来创建ingress
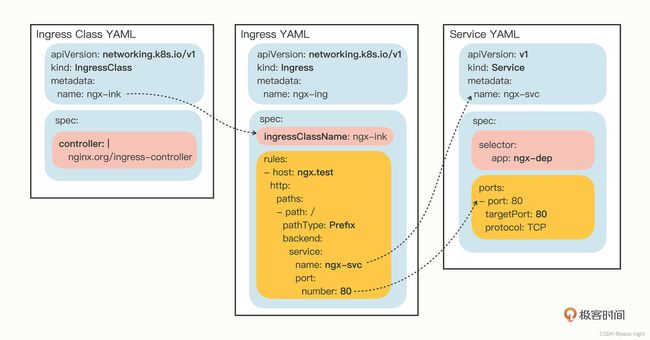
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ngx-ing
spec:
ingressClassName: ngx-ink
rules:
- host: ngx.test
http:
paths:
- path: /
pathType: Exact
backend:
service:
name: ngx-svc
port:
number: 80
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: ngx-ink
spec:
controller: nginx.org/ingress-controller
使用apply命令创建
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f ingress.yml
ingress.networking.k8s.io/ngx-ing created
ingressclass.networking.k8s.io/ngx-ink created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get ingressclass
NAME CONTROLLER PARAMETERS AGE
nginx k8s.io/ingress-nginx <none> 52m
ngx-ink nginx.org/ingress-controller <none> 27s
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe ingress ngx-ing
Name: ngx-ing
Labels: <none>
Namespace: default
Address:
Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>)
Rules:
Host Path Backends
---- ---- --------
ngx.test
/ ngx-svc:80 (<error: endpoints "ngx-svc" not found>)
Annotations: <none>
Events: <none>
Ingress Controller使用15

在有了ingress和ingress class之后, 我们还要部署真正处理路由规则的Ingress Controller来处理请求
首先安装ingress-nginx; 它是Ingress Controller的最常用的实现
passnight@passnight-s600:/opt/k8s$ sudo wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.1/deploy/static/provider/cloud/deploy.yaml -O ingress-nginx.yml
passnight@passnight-s600:/opt/k8s$ kubectl apply -f ingress-nginx.yml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
serviceaccount/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
configmap/ingress-nginx-controller created
service/ingress-nginx-controller created
service/ingress-nginx-controller-admission created
deployment.apps/ingress-nginx-controller created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
ingressclass.networking.k8s.io/nginx created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
passnight@passnight-s600:/opt/k8s$ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-65hzk 0/1 Completed 0 39s
ingress-nginx-admission-patch-7n587 0/1 Completed 1 39s
ingress-nginx-controller-64c9b9485b-5wnr7 1/1 Running 0 39s
passnight@passnight-s600:/opt/k8s$ kubectl get deployment -n ingress-nginx
NAME READY UP-TO-DATE AVAILABLE AGE
ingress-nginx-controller 1/1 1 1 88s
passnight@passnight-s600:/opt/k8s$ kubectl get service -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.111.166.195 <pending> 80:30522/TCP,443:31193/TCP 119s
ingress-nginx-controller-admission ClusterIP 10.102.198.114 <none> 443/TCP 119s
# 将ingress class注册到Controller中
passnight@passnight-s600:/opt/k8s$ sudo vim ingress-nginx.yml
# 添加spec.template.spec.containers[image=nginx-ingress].args[-1] = -ingress-class=ngx-ink
# 将容器的80端口转发到本地8080端口
passnight@passnight-s600:/opt/k8s$ kubectl port-forward -n ingress-nginx ingress-nginx-controller-64c9b9485b-5wnr7 8080:80
# 之后可以通过请求本地8080端口, 来请求远程80端口
passnight@passnight-s600:/opt/k8s$ curl --resolve ngx.test:8080:127.0.0.1 http://ngx.test:8080
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
在完成章节2.8.4 安装LoadBalancer后, 就可以通过LoadBalancer分配的IP地址进行访问
passnight@passnight-s600:/opt/k8s$ kubectl get svc -A | grep ingress-nginx
ingress-nginx ingress-nginx-controller LoadBalancer 10.101.130.117 192.168.100.70 80:31438/TCP,443:30099/TCP 15m
ingress-nginx ingress-nginx-controller-admission ClusterIP 10.108.111.248 <none> 443/TCP 15m
passnight@passnight-s600:/opt/k8s$ curl 192.168.100.70:80
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
在完成Ingress Controller的部署之后, 就要完成服务的部署
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:alpine
name: nginx
---
apiVersion: v1
kind: Service
metadata:
name: ngx-svc
spec:
selector:
app: ngx-dep
ports:
- port: 80
targetPort: 80
protocol: TCP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ngx-ing
spec:
ingressClassName: nginx # 通过这个关联到下载的nginx controller
rules:
- host: ngx.test
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: ngx-svc
port:
number: 80
之后我们分别通过域名和ip访问, 发现通过ip访问会直接404, 而只能通过域名访问
passnight@passnight-s600:/opt/k8s/learn$ kubectl get svc -n ingress-nginx | grep nginx
ingress-nginx-controller LoadBalancer 10.101.130.117 192.168.100.70 80:31438/TCP,443:30099/TCP 57m
ingress-nginx-controller-admission ClusterIP 10.108.111.248 <none> 443/TCP 57m
passnight@passnight-s600:/opt/k8s/learn$ curl 192.168.100.70
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
# 注意: 需要添加`ngx.test`到/etc/hosts; 这里我就略过了
passnight@passnight-s600:/opt/k8s/learn$ curl ngx.test
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
安装LoadBalancer
因为没有安装LoadBalancer的缘故, LoadBalance的ExternalIP为空, 依旧没有办法直接访问,
passnight@passnight-s600:/opt/k8s$ kubectl get svc -n ingress-nginx | grep nginx
ingress-nginx-controller LoadBalancer 10.111.166.195 <pending> 80:30522/TCP,443:31193/TCP 33m
ingress-nginx-controller-admission ClusterIP 10.102.198.114 <none> 443/TCP 33m
因此安装mtalLB16; metaLB是基于ARP协议路由17的, 因此可以设置成和子网一样的ip网段, 本机的子网网段可以在/etc/config中的config dhcp lan中看到18 我的局域网是使用Openwrt做路由的
root@PassnightRouter:/etc/config# cat dhcp | grep "config dhcp 'lan'" -A 10
config dhcp 'lan'
option interface 'lan'
option start '100'
option limit '150'
option leasetime '12h'
option dhcpv4 'server'
option dhcpv6 'server'
option ra 'server'
option ra_slaac '1'
list ra_flags 'managed-config'
list ra_flags 'other-config'
可以看到, dhcp服务器分配的地址范围为100以后, 因此将70-99作为metaLB的ip; 我们需要在下面添加ConfigMap19; 使用-表示ip范围20
passnight@passnight-s600:/opt/k8s$ sudo wget https://raw.githubusercontent.com/metallb/metallb/v0.13.10/config/manifests/metallb-native.yaml
在下面添加ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.100.70/24-192.168.100.99/24
然后执行
passnight@passnight-s600:/opt/k8s$ kubectl apply -f metallb-native.yaml
namespace/metallb-system created
customresourcedefinition.apiextensions.k8s.io/addresspools.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bfdprofiles.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bgpadvertisements.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bgppeers.metallb.io created
customresourcedefinition.apiextensions.k8s.io/communities.metallb.io created
customresourcedefinition.apiextensions.k8s.io/ipaddresspools.metallb.io created
customresourcedefinition.apiextensions.k8s.io/l2advertisements.metallb.io created
serviceaccount/controller created
serviceaccount/speaker created
role.rbac.authorization.k8s.io/controller created
role.rbac.authorization.k8s.io/pod-lister created
clusterrole.rbac.authorization.k8s.io/metallb-system:controller created
clusterrole.rbac.authorization.k8s.io/metallb-system:speaker created
rolebinding.rbac.authorization.k8s.io/controller created
rolebinding.rbac.authorization.k8s.io/pod-lister created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:controller created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:speaker created
configmap/metallb-excludel2 created
secret/webhook-server-cert created
service/webhook-service created
deployment.apps/controller created
daemonset.apps/speaker created
validatingwebhookconfiguration.admissionregistration.k8s.io/metallb-webhook-configuration created
configmap/config created
passnight@passnight-s600:/opt/k8s$ kubectl get pods -n metallb-system
NAME READY STATUS RESTARTS AGE
controller-6f5c46d94b-hlm7v 1/1 Running 0 63s
speaker-8t9p2 1/1 Running 0 63s
speaker-pkz2g 1/1 Running 0 63s
speaker-tvvz4 1/1 Running 0 63s
在完成IPv4的配置之后, 三个pod都可以正常运行, 但依旧无法为LoadBalancer分配IP, 报错如下:
passnight@passnight-s600:/opt/k8s$ kubectl describe svc ingress-nginx-controller -n ingress-nginx
Name: ingress-nginx-controller
Namespace: ingress-nginx
Labels: app.kubernetes.io/component=controller
app.kubernetes.io/instance=ingress-nginx
app.kubernetes.io/name=ingress-nginx
app.kubernetes.io/part-of=ingress-nginx
app.kubernetes.io/version=1.8.1
Annotations: <none>
Selector: app.kubernetes.io/component=controller,app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx
Type: LoadBalancer
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.101.130.117
IPs: 10.101.130.117
Port: http 80/TCP
TargetPort: http/TCP
NodePort: http 31438/TCP
Endpoints: 10.244.0.222:80
Port: https 443/TCP
TargetPort: https/TCP
NodePort: https 30099/TCP
Endpoints: 10.244.0.222:443
Session Affinity: None
External Traffic Policy: Local
HealthCheck NodePort: 31859
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning AllocationFailed 23s metallb-controller Failed to allocate IP for "ingress-nginx/ingress-nginx-controller": no available IPs
metaLB日志中报错:
2023-09-02T15:07:00.725342803Z W0902 15:07:00.725104 1 warnings.go:70] metallb.io v1beta1 AddressPool is deprecated, consider using IPAddressPool
这可能会导致arp成环, 最终无法分配ip地址21; 因此需要使用CRD方式进行部署2223; 因此需要将上面的ConfigMap改为CRD:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: primary-pool
namespace: metallb-system
spec:
addresses:
- 192.168.100.70-192.168.100.99
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: l2adv
namespace: metallb-system
spec:
ipAddressPools:
- primary-pool
这样ingress-nginx就可以分配到LoadBalancer的IP了
passnight@passnight-s600:/opt/k8s$ kubectl get svc -A | grep ingress-nginx
ingress-nginx ingress-nginx-controller LoadBalancer 10.101.130.117 192.168.100.70 80:31438/TCP,443:30099/TCP 15m
ingress-nginx ingress-nginx-controller-admission ClusterIP 10.108.111.248 <none> 443/TCP 15m
passnight@passnight-s600:/opt/k8s$
基本使用
使用Kubernetes部署Nginx
API对象
kubernetes是通过声明一个yaml文件对容器进行管理; 而其中YAML语言仅仅是语法, Kubernetes还通过语义来解释该yaml文件; 这个概念被称为API对象
apiserver是Kubernetes系统的唯一入口, 外部用户和内部组件都必须和它通信, 而它采用了HTTP协议的URL资源概念, API风格也是RESTful的风格, 因此这些对象很容易被称为API对象, 其中可以通过kubectl api-resources来查看当前Kubernetes版本所支持的所有对象
# 查看Kubernetes所支持的所有资源
passnight@passnight-s600:/opt/k8s/learn$ kubectl api-resources
# name表示对象的名字; shortnames表示缩写(缩写可以在调用命令的时候简化操作)
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
persistentvolumeclaims pvc v1 true PersistentVolumeClaim
# 等等等等
其中可以通过参数--v9来显示详细的命令执行过程, 如下面可以清楚地看到HTTP请求过程
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod --v=9
I0829 21:53:57.540144 3944055 loader.go:372] Config loaded from file: /home/passnight/.kube/config
# 这里可以看到get pod命令其实是通过访问主节点的/api/v1/namespaces/default/pods路径获得
I0829 21:53:57.542613 3944055 round_trippers.go:466] curl -v -XGET -H "Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json" -H "User-Agent: kubectl/v1.23.3 (linux/amd64) kubernetes/816c97a" 'https://192.168.100.3:6443/api/v1/namespaces/default/pods?limit=500'
# 等等等等
使用run命令直接部署nginx
passnight@passnight-s600:/opt/k8s/learn$ kubectl run ngx --image=nginx:alpine
pod/ngx created
# 通过get pods 命令可以看到已经创建成功了
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods | grep ngx
ngx 0/1 ContainerCreating 0 53s
直接使用Deployment部署Nginx
编写配置文件:
apiVersion: apps/v1 #与k8s集群版本有关,使用 kubectl api-versions 即可查看当前集群支持的版本
kind: Deployment #该配置的类型,我们使用的是 Deployment
metadata: #译名为元数据,即 Deployment 的一些基本属性和信息
name: nginx-deployment #Deployment 的名称
labels: #标签,可以灵活定位一个或多个资源,其中key和value均可自定义,可以定义多组,目前不需要理解
app: nginx #为该Deployment设置key为app,value为nginx的标签
spec: #这是关于该Deployment的描述,可以理解为你期待该Deployment在k8s中如何使用
replicas: 1 #使用该Deployment创建一个应用程序实例
selector: #标签选择器,与上面的标签共同作用,目前不需要理解
matchLabels: #选择包含标签app:nginx的资源
app: nginx
template: #这是选择或创建的Pod的模板
metadata: #Pod的元数据
labels: #Pod的标签,上面的selector即选择包含标签app:nginx的Pod
app: nginx
spec: #期望Pod实现的功能(即在pod中部署)
containers: #生成container,与docker中的container是同一种
- name: nginx #container的名称
image: nginx:1.7.9 #使用镜像nginx:1.7.9创建container,该container默认80端口可访问
执行并查看结果:
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx.yml
passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 2m48s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-85658cc69f-fzwns 1/1 Running 0 2m26s
发现Nginx的deployment及pod都创建好了
使用Service部署
apiVersion: apps/v1 #与k8s集群版本有关,使用 kubectl api-versions 即可查看当前集群支持的版本
kind: Deployment #该配置的类型,我们使用的是 Deployment
metadata: #译名为元数据,即 Deployment 的一些基本属性和信息
name: nginx-deployment #Deployment 的名称
labels: #标签,可以灵活定位一个或多个资源,其中key和value均可自定义,可以定义多组,目前不需要理解
app: nginx #为该Deployment设置key为app,value为nginx的标签
spec: #这是关于该Deployment的描述,可以理解为你期待该Deployment在k8s中如何使用
replicas: 1 #使用该Deployment创建一个应用程序实例
selector: #标签选择器,与上面的标签共同作用,目前不需要理解
matchLabels: #选择包含标签app:nginx的资源
app: nginx
template: #这是选择或创建的Pod的模板
metadata: #Pod的元数据
labels: #Pod的标签,上面的selector即选择包含标签app:nginx的Pod
app: nginx
spec: #期望Pod实现的功能(即在pod中部署)
containers: #生成container,与docker中的container是同一种
- name: nginx #container的名称
image: nginx:1.7.9 #使用镜像nginx:1.7.9创建container,该container默认80端口可访问
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service #Service 的名称
labels: #Service 自己的标签
app: nginx #为该 Service 设置 key 为 app,value 为 nginx 的标签
spec: #这是关于该 Service 的定义,描述了 Service 如何选择 Pod,如何被访问
selector: #标签选择器
app: nginx #选择包含标签 app:nginx 的 Pod
ports:
- name: nginx-port #端口的名字
protocol: TCP #协议类型 TCP/UDP
port: 80 #集群内的其他容器组可通过 80 端口访问 Service
nodePort: 32600 #通过任意节点的 32600 端口访问 Service
targetPort: 80 #将请求转发到匹配 Pod 的 80 端口
type: NodePort #Serive的类型,ClusterIP/NodePort/LoaderBalancer
可以通过kubectl get services命令查看service部署情况
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx-service.yml
deployment.apps/nginx-deployment unchanged
service/nginx-service created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get service -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 85m <none>
nginx-service NodePort 10.102.250.141 <none> 80:32600/TCP 15s app=nginx
可见已经通过Service完成了部署, 并且将容器的80端口映射到了32600端口; 尝试使用curl访问, 发现所有ip都可以正常访问
# 使用localhost访问
passnight@passnight-s600:/opt/k8s/learn$ curl localhost:32600
<!DOCTYPE html>
# ..................
# 使用本机域名访问
passnight@passnight-s600:/opt/k8s/learn$ curl server.passnight.local:32600
<!DOCTYPE html>
# ..................
# 使用节点1域名访问
passnight@passnight-s600:/opt/k8s/learn$ curl replica.passnight.local:32600
<!DOCTYPE html>
# ..................
# 使用节点2域名访问
passnight@passnight-s600:/opt/k8s/learn$ curl follower.passnight.local:32600
<!DOCTYPE html>
# ..................
常用命令
#####################################查询命令####################################
# 获取类型为Deployment的资源列表; 看到有一个名为Nginx-deployment的Deployment
passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 12m
# 获取类型为Pod的资源列表; 可以看到有一个nginx pod
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-85658cc69f-fzwns 1/1 Running 0 12m
# 获取类型为Node的资源列表, 可以看到集群中有三台服节点
passnight@passnight-s600:/opt/k8s/learn$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
passnight-acepc Ready <none> 64m v1.23.3
passnight-centerm Ready <none> 64m v1.23.3
passnight-s600 Ready control-plane,master 68m v1.23.3
# 名字空间,使用-n可以指定名字空间, 使用-A 或 --all-namespaces指定所有名字空间
# 查看所有名字空间的Deployment
passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
default nginx-deployment 1/1 1 1 15m
kube-system coredns 1/1 1 1 70m
passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments --all-namespaces
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
default nginx-deployment 1/1 1 1 15m
kube-system coredns 1/1 1 1 70m
# 查看名字空间为kube-system的Deployment
passnight@passnight-s600:/opt/k8s/learn$ kubectl get deployments -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 1/1 1 1 70m
# describe: 显示有关资源的详细信息
# 查看名称为nginx-deployment-85658cc69f-fzwns的Pod的信息
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe pod nginx-deployment-85658cc69f-fzwns
Name: nginx-deployment-85658cc69f-fzwns
Namespace: default
# ...................
# 查看名称为nginx的Deployment的信息
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe deployment nginx
Name: nginx-deployment
Namespace: default
# ...................
# 查看日志
# 查看名称为nginx-deployment-85658cc69f-fzwns的Pod内的容器打印的日志
# 本案例中的 nginx-pod 没有输出日志,所以您看到的结果是空的
passnight@passnight-s600:/opt/k8s/learn$ kubectl logs nginx-deployment-85658cc69f-fzwns
# 进入容器, 类似于docker exec
# 在名称为nginx-pod-xxxxxx的Pod中运行bash
passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it nginx-deployment-85658cc69f-fzwns bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-deployment-85658cc69f-fzwns:/#
应用程序伸缩
修改niginx.yml中的spec.replicas参数将容器扩容到4个
#.............
spec:
replicas: 4 # 将副本数量修改为4个
#.............
使用kubectl apply命令使其生效
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx.yml
deployment.apps/nginx-deployment configured
# 查看部署情况, 发现四个副本已经在两个node上完成部署
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-85658cc69f-4q2qj 1/1 Running 0 2m9s 10.244.1.4 passnight-centerm <none> <none>
nginx-deployment-85658cc69f-d9zxz 1/1 Running 0 2m9s 10.244.2.3 passnight-acepc <none> <none>
nginx-deployment-85658cc69f-fzwns 1/1 Running 0 38m 10.244.1.3 passnight-centerm <none> <none>
nginx-deployment-85658cc69f-lqkqh 1/1 Running 0 2m9s 10.244.2.4 passnight-acepc <none> <none>
滚动更新
k8s会逐个使用新版本pod替换旧版本; 我们将spec.containers[0].image从nginx:1.7.9替换为nginx:1.8, 并使用Watch命令查看滚动更新过程
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.8 # 修改点, 将版本改为1.8
使用apply命令, 并观察现象
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx.yml
deployment.apps/nginx-deployment configured
passnight@passnight-s600:/opt/k8s/learn$ watch kubectl get pods -l app=nginx
有两个节点进入创建容器状态

一段时间后, 容器完成更新

节点管理
节点状态
节点状态可以使用kubectl describe node 进行查看, 其规则如下:
# 使用kubectl查看主节点的详细信息
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe node passnight-s600
Name: passnight-s600 # 节点名
Roles: control-plane,master # 节点role, 是主节点, 同时还是控制面
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=passnight-s600
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node-role.kubernetes.io/master=
node.kubernetes.io/exclude-from-external-load-balancers=
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"2e:b1:e5:f6:ad:dd"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 192.168.100.3
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Mon, 28 Aug 2023 21:10:34 +0800
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: passnight-s600
AcquireTime: <unset>
RenewTime: Tue, 29 Aug 2023 21:34:11 +0800
# Condition 描述了节点状态
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason
Message
---- ------ ----------------- ------------------ ------
-------
NetworkUnavailable False Mon, 28 Aug 2023 21:18:07 +0800 Mon, 28 Aug 2023 21:18:07 +0800 FlannelIsUp
Flannel is running on this node
MemoryPressure False Tue, 29 Aug 2023 21:31:58 +0800 Mon, 28 Aug 2023 21:10:33 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Tue, 29 Aug 2023 21:31:58 +0800 Mon, 28 Aug 2023 21:10:33 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Tue, 29 Aug 2023 21:31:58 +0800 Mon, 28 Aug 2023 21:10:33 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Tue, 29 Aug 2023 21:31:58 +0800 Mon, 28 Aug 2023 21:10:47 +0800 KubeletReady
kubelet is posting ready status. AppArmor enabled
# 节点部署方式
Addresses:
# 从节点内部可以访问的IP
InternalIP: fd12:4abe:6e6e::7f8
# 域名
Hostname: passnight-s600
# 还可能有ExternalIP; 但这里没有, 这通常表示节点的外部IP, 即可以从集群外使用该IP访问该节点
# Capacity 和 Allocatable描述了节点上可用资源的情况
# Capacity表示节点上的资源总数
Capacity:
cpu: 20
ephemeral-storage: 982862268Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 65576904Ki
pods: 110
# Allocatable表示可以分配给普通Pod的资源总数
Allocatable:
cpu: 20
ephemeral-storage: 905805864690
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 65474504Ki
pods: 110
# 这部分内容描述了节点的基本信息, 如Linux内核版本/Kubernetes版本/Docker版本/操作系统名称等
System Info:
Machine ID: 408899535caf46a789ca9fd22781863f
System UUID: 03000200-0400-0500-0006-000700080009
Boot ID: 300be485-e79a-4172-894b-ec97ad78c57d
Kernel Version: 6.2.0-26-generic
OS Image: Ubuntu 22.04.3 LTS
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://24.0.5
Kubelet Version: v1.23.3
Kube-Proxy Version: v1.23.3
PodCIDR: 10.244.0.0/24
PodCIDRs: 10.244.0.0/24
Non-terminated Pods: (7 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-deployment-6956dcf8c-xjq75 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2m8s
kube-flannel kube-flannel-ds-89qq4 100m (0%) 0 (0%) 50Mi (0%) 0 (0%) 24h
kube-system etcd-passnight-s600 100m (0%) 0 (0%) 100Mi (0%) 0 (0%) 24h
kube-system kube-apiserver-passnight-s600 250m (1%) 0 (0%) 0 (0%) 0 (0%) 24h
kube-system kube-controller-manager-passnight-s600 200m (1%) 0 (0%) 0 (0%) 0 (0%) 24h
kube-system kube-proxy-cfmjb 0 (0%) 0 (0%) 0 (0%) 0 (0%) 24h
kube-system kube-scheduler-passnight-s600 100m (0%) 0 (0%) 0 (0%) 0 (0%) 24h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 750m (3%) 0 (0%)
memory 150Mi (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>
上面例子介绍了describe的基本使用, 其中Condition可能存在多种情况, 具体如下表所示:
| Node Condition | 描述 |
|---|---|
| OutOfDisk | 如果节点上的空白磁盘空间不够,不能够再添加新的节点时,该字段为 True,其他情况为 False |
| Ready | 如果节点是健康的且已经就绪可以接受新的 Pod。则节点Ready字段为 True。False表明了该节点不健康,不能够接受新的 Pod。 |
| MemoryPressure | 如果节点内存紧张,则该字段为 True,否则为False |
| PIDPressure | 如果节点上进程过多,则该字段为 True,否则为 False |
| DiskPressure | 如果节点磁盘空间紧张,则该字段为 True,否则为 False |
| NetworkUnvailable | 如果节点的网络配置有问题,则该字段为 True,否则为 False |
进阶使用
数据持久化
- PersistentVolume
- pod里的容器是由镜像产生的, 而镜像文件本身是制度的, 进程要读写磁盘只能使用一个临时的存储空间, 一旦pod销毁, 临时存储也会立即回收释放, 这样数据就丢失了
- 为了保证数据能够持久化保存, Kubernetes已经提供了一个
Volume的概念, 顺着这个概念, 延伸除了PersistentVolume; 它可以用于表示持久存储的实现 PersistentVolumn简称PV - 作为存储的抽象, PV实际上就是一些存储设备/文件系统, 它可以是Ceph/ClusterFS甚至是本地磁盘
- PV属于集群的系统资源, 是和Node平级的一种对象, Pod对它没有管理权, 只有使用权
- PersistentVolumeClaim/StorageClass
- 由于存储设备的差异十分巨大, 有的可以共享读写/有的只能独占读写; 有的容量只有几百MB/有的容量达到TB/PB级别
- 为了管理这么多种存储设备, Kubernetes又新增了两个新对象: PersistentVolumeClaim和StorageClass, 将存储卷的分配和管理过程再次细化
- PVC是给pod使用的对象, 它相当于是Pod的代理, 代表Pod想系统申请PV; 一旦申请成功, Kubernetes就会把PV和PVC关联在一起, 这个过程叫做绑定
- StorageClass类似于IngressClass, 它抽象了特定类型的存储系统, 在PVC和PV之间充当协调人的角色, 帮助PVC找到合适的PV

PersistentVolume的使用
首先是使用yml创建一个PersistentVolume
apiVersion: v1
kind: PersistentVolume
metadata:
name: host-10m-pv
spec:
storageClassName: host-test # 这个表示存储PV的名字
accessModes:
- ReadWriteOnce # 可读可写, 但只能被一个节点挂载; 同样的还有ReadOnlyMany/ReadWriteMany; 很显然本地目录只能在本机只用, 因此只能选择ReadWriteOnce
capacity:
storage: 10Mi # 大小, Mi/Ki/Gi进制是1000; GB/MB/KB进制是1040
hostPath:
path: /tmp/host-10m-pv/ # 本地卷的路径
在有了一个PersistentVolumn之后, 就可以通过PersistentVolumeClaim, 下面是一个通过PVC申请PV的例子
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: host-5m-pvc # 名字
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce # 访问模式是ReadWriteOnce
resources:
requests:
storage: 5Mi # 申请5Mi
这样我们就可以实现pod的持久化存储了
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f persistent-volume.yml
persistentvolume/host-10m-pv created
persistentvolumeclaim/host-5m-pvc created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get persistentvolumes
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
host-10m-pv 10Mi RWO Retain Bound default/host-5m-pvc host-test 6s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get persistentvolumeclaims
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
host-5m-pvc Bound host-10m-pv 10Mi RWO host-test 15s
这之后我们就可以将pv绑定到pod里面了; 如以下例子就将Nginx容器中的/tmp目录挂载到了host-5m-pvc中

apiVersion: v1
kind: Pod
metadata:
name: host-pvc-pod
spec:
volumes:
- name: host-pvc-vol
persistentVolumeClaim:
claimName: host-5m-pvc
containers:
- name: ngx-pvc-pod
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: host-pvc-vol
mountPath: /tmp
但这里要注意: 倘若pod被调度到了其他的node上, 即使挂载了本地目录, 也是无法引用到之前的存储为止, 这样持久化功能就失效了
k8s网络存储
- 在Kubernetes中, pod在集群中经常会漂移, 因此使用本地卷的方式并不实用
- 因此可以使用网络存储
使用nfs进行网络存储
以下是一个nfs的例子; 它首先通过PersistentVolume创建一个持久卷, 然后通过PersistentVolumeClaim声明一个持久卷, 最后通过claimName与pod绑定; 因为使用的是nfs存储, 所以可以使用ReadWriteMany模式; 这里将/etc/nginx/conf.d绑定到/opt/nfs/1g-pv下, 方便我们对nginx容器进行配置
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-1g-pv
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
capacity:
storage: 1Gi
nfs:
path: /opt/nfs/1g-pv
server: 192.168.100.3 # 通过ip访问
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-static-pvc
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: nfs-static-pod
spec:
volumes:
- name: nfs-pvc-vol
persistentVolumeClaim:
claimName: nfs-static-pvc
containers:
- name: nfs-pvc-test
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: nfs-pvc-vol
mountPath: /etc/nginx/conf.d

使用apply命令就可以完成创建, 这里记住要手动创建挂载点, 否则会一直处于ContainerCreating并报错No such file or directory; 以及创建后的容器卷要赋予777访问权限 24 倘若想自动创建, 需要使用provisioner
passnight@passnight-s600:/opt/k8s/learn$ kubectl get persistentvolume
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfs-1g-pv 1Gi RWX Retain Bound default/nfs-static-pvc nfs 10s
passnight@passnight-s600:/opt/k8s/learn$ kubectl get persistentvolumeclaim
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nfs-static-pvc Bound nfs-1g-pv 1Gi RWX nfs 17s
# 观察pod, 及打印的日志, 发现已经成功挂载了
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nfs-static-pod 1/1 Running 0 20s
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe pod nfs-static-pod
Name: nfs-static-pod
Namespace: default
# ...............省略一些日志...........................
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 31s default-scheduler 0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims.
Normal Scheduled 29s default-scheduler Successfully assigned default/nfs-static-pod to passnight-s600
Normal Pulled 28s kubelet Container image "nginx:alpine" already present on machine
Normal Created 28s kubelet Created container nfs-pvc-test
Normal Started 28s kubelet Started container nfs-pvc-test
进入容器创建文件, 查看挂载状态
passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it nfs-static-pod sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ # cd /etc/nginx/conf.d/
/etc/nginx/conf.d # echo "hello from container" > hello
/etc/nginx/conf.d #
passnight@passnight-s600:/opt/k8s/learn$ ll /opt/nfs/1g-pv/
total 12
drwxrwxrwx 2 passnight passnight 4096 9月 2 14:32 ./
drwxrwxrwx 3 root root 4096 9月 2 14:25 ../
-rw-r--r-- 1 nobody nogroup 21 9月 2 14:32 hello
动态存储卷

- 尽管nfs网络卷挂载似乎解决了持久化的问题, 但是对于大规模集群, 仍然有成百上千的应用需要PV存储, 如果仍然使用人力的方式管理, 可能会造成大量不必要的重复工作
- 为此, Kubernetes提出了动态存储卷的概念, 它可以使用StorageClass绑定一个Provisioner对象, 而这个Provisioner对象是一个可以自动管理/创建PV的应用
要想配置StorageClass并通过provisioner自动分配存储卷, 首先需要部署provisioner; 然后再在yml中进行相关配置
部署provisioner 25
# nfs通过RBAC进行权限管理, 因此需要先配置角色, 为nfs-provisioner赋予权限
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: storage # 替换成你要部署的 Namespace
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: storage
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: storage
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: storage
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: storage
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
# 之后便可以配置nfs-provisioner
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
namespace: storage
labels:
app: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate ## 设置升级策略为删除再创建(默认为滚动更新)
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME ## Provisioner的名称,以后设置的storageclass要和这个保持一致
value: nfs-client
- name: NFS_SERVER ## NFS服务器地址,需和valumes参数中配置的保持一致
value: 192.168.100.3
- name: NFS_PATH ## NFS服务器数据存储目录,需和valumes参数中配置的保持一致
value: /opt/nfs/provisioner
volumes:
- name: nfs-client-root
nfs:
server: 192.168.100.3 ## NFS服务器地址
path: /opt/nfs/provisioner ## NFS服务器数据存储目录
这样provisioner就完成安装了
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod -n storage
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-78c69bf96b-hsw49 1/1 Running 0 3m57s
配置StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: nfs-client # 动态卷分配者名称,必须和上面创建的"PROVISIONER_NAME"变量中设置的Name一致
parameters:
archiveOnDelete: "true" # 删除时保留数据
mountOptions:
- hard ## 指定为硬挂载方式
- nfsvers=4 ## 指定NFS版本,这个需要根据NFS Server版本号设置
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-dyn-10m-pvc
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Mi
---
apiVersion: v1
kind: Pod
metadata:
name: nfs-dyn-pod
spec:
volumes:
- name: nfs-dyn-10m-vol
persistentVolumeClaim:
claimName: nfs-dyn-10m-pvc
containers:
- name: nfs-dyn-test
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: nfs-dyn-10m-vol
mountPath: /tmp
之后我们创建对应的pod, 就可以发现mountPath被自动创建了
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f provisioner.yml
storageclass.storage.k8s.io/nfs-client created
persistentvolumeclaim/nfs-dyn-10m-pvc created
pod/nfs-dyn-pod created
# 在nfs路径下查看, 可以看到卷已经被创建了
passnight@passnight-s600:/opt/nfs/provisioner$ ll
total 12
drwxrwxrwx 3 root root 4096 9月 9 16:06 ./
drwxrwxrwx 4 root root 4096 9月 9 15:56 ../
drwxrwxrwx 2 nobody nogroup 4096 9月 9 16:06 default-nfs-dyn-10m-pvc-pvc-a215fd7a-d9b1-4151-87b3-4233ff38584b/
有状态应用
- 尽管有了
PersistentVolume等对象, 在管理有状态应用的过程依旧会遇到很多困难 - 如在运行时, 将一些关键的运行时数据落盘, 若pod发生了以外崩溃, 可以回复原来的状态运行
- 倘若一个应用的运行信息很重要, 其重启后丢失状态是无法接受的, 这样的应用就是有状态应用
- 对于有状态应用, 可能多个实例间存在依赖关系, 如master/slave, active/passive; 他们需要依次启动才能保证应用的正常运行
- Kubernetes因此在Deployment上定义了一个新的api对象: StatefulSet
StatefulSet的使用
# statefulset 相比于 deployment, 除了kind是StatefulSet以外, 就是多了一个serviceName字段; 因为对于StatefulSet, 它是有状态的, 也不能再是随机名字了
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-sts
spec:
serviceName: redis-svc
replicas: 2
selector:
matchLabels:
app: redis-sts
template:
metadata:
labels:
app: redis-sts
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379
同样使用apply命令创建StatefulSet:
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f stateful-set.yml
statefulset.apps/redis-sts created
# 这里我们可以看到, pod的名字不再是随机的了, 而是根据时间排序的; 这样我们就可以令0号pod为主实例, 1号为从实例
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
redis-sts-0 1/1 Running 0 5s
redis-sts-1 1/1 Running 0 5s
# 进入容器查看域名, 发现域名与pod的名字相同
passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it redis-sts-0 sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/data # echo $HOSTNAME
redis-sts-0
之后我们就可以创建Service使用他们了
apiVersion: v1
kind: Service
metadata:
name: redis-svc
spec:
selector:
app: redis-sts
ports:
- port: 6379
protocol: TCP
targetPort: 6379
相比于Deployment, 他们的域名是固定的: pod名.服务名.名字空间.svc.cluster或简写为pod名.服务名
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f stateful-set-service.yml
service/redis-svc created
passnight@passnight-s600:/opt/k8s/learn$ kubectl exec -it redis-sts-0 sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/data # ping redis-sts-0.redis-svc
PING redis-sts-0.redis-svc (10.244.0.168): 56 data bytes
64 bytes from 10.244.0.168: seq=0 ttl=64 time=0.057 ms
64 bytes from 10.244.0.168: seq=1 ttl=64 time=0.084 ms
^C
--- redis-sts-0.redis-svc ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.057/0.070/0.084 ms
/data # ping redis-sts-1.redis-svc
PING redis-sts-1.redis-svc (10.244.1.20): 56 data bytes
64 bytes from 10.244.1.20: seq=0 ttl=62 time=0.750 ms
64 bytes from 10.244.1.20: seq=1 ttl=62 time=0.474 ms
^C
--- redis-sts-1.redis-svc ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.474/0.612/0.750 ms
这里注意, Service适用于负载均衡转发pod流量的, 但是对于StatefulSet来说, 他们的pod拥有稳定的域名, 因此外界访问无需通过Service这一层; 我们可以在Service中添加clusterIP:None来告诉Kubernetes无需为这个对象分配ip地址

StatefulSet数据持久化

- StatefulSet可以使用同Deployment一样的持久卷
- 但为了能够保证StatefulSet与持久卷一对一的绑定关系, StatefulSet有一个字段volumeClaimTemplates可以直接把PVC定义嵌入到StatefulSet的YAML文件中
如下面在redis集群定义时, 添加一个专属持久卷
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-pv-sts
spec:
serviceName: redis-pv-svc
volumeClaimTemplates: # 其里面的内容同PVC中类似, 都是生命storageClassName等信息
- metadata:
name: redis-100m-pvc
spec:
storageClassName: nfs-client # 使用上面创建的provisioner
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Mi
replicas: 2
selector:
matchLabels:
app: redis-pv-sts
template:
metadata:
labels:
app: redis-pv-sts
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379
volumeMounts:
- name: redis-100m-pvc
mountPath: /data
之后创建的pod就会自动挂载卷到nfs服务器上
passnight@passnight-s600:/opt/k8s/learn$ sudo vim stateful-set-persistent-volume.yml
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f stateful-set-persistent-volume.yml
statefulset.apps/redis-pv-sts created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
redis-pv-sts-0 1/1 Running 0 5m9s
redis-pv-sts-1 1/1 Running 0 5m7s
# 在nfs服务器上可以看到对应的持久化卷
passnight@passnight-s600:/opt/nfs/provisioner$ ll | grep redis
drwxrwxrwx 2 systemd-coredump root 4096 9月 9 17:27 default-redis-100m-pvc-redis-pv-sts-0-pvc-3e31ec3a-f4b4-4d35-8dae-1e84af1012c6/
drwxrwxrwx 2 systemd-coredump root 4096 9月 9 17:27 default-redis-100m-pvc-redis-pv-sts-1-pvc-1900ddd8-839d-4f04-bff5-e81b711e1813/
滚动更新
在实际的运维工作中, 除了应用伸缩, 应用更新/版本回退等工作也是非常常见的问题, Kubernetes提供了rollout命令实现用户无感知的应用升级和降级
Kubernetes定义应用版本
在Kubernetes中, 版本的控制其实是对Kubernetes所管理的最小单元:pod进行管理的, 而pod的版本由pod对应的yml文件所控制, 因此Kubernetes通过摘要计算算法计算yml的hash值作为版本号, 表示pod的版本
如下面代码框中的bfbb5f64b就表示版本
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ngx-dep-bfbb5f64b-kdrqc 1/1 Running 0 4s
ngx-dep-bfbb5f64b-q7p2h 1/1 Running 0 4s
将Nginx的版本从alpine改为1.24.0后, 其中一个pod的名字变成了``ngx-dep-5bd855f78b-zttc4, 版本号也从bfbb5f64b变为了5bd855f78b`
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ngx-dep-5bd855f78b-8l4pl 1/1 Running 0 73s
ngx-dep-5bd855f78b-zttc4 1/1 Running 0 2m59s
在更新过程中, 可以使用rollout status来查看更新的状态, 这里将版本从1.24.0改回airpine 因为在镜像已经存在的前提下, 更新速度很快, 为了能够观察到应用更新的过程, 可以使用minReadySeconds命令让pod等待一段时间再就绪
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout status deployment ngx-dep
Waiting for deployment "ngx-dep" rollout to finish: 1 out of 2 new replicas have been updated...
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe deploy ngx-dep
Name: ngx-dep
Namespace: default
CreationTimestamp: Fri, 01 Sep 2023 22:03:08 +0800
Labels: app=ngx-dep
Annotations: deployment.kubernetes.io/revision: 5
Selector: app=ngx-dep
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=ngx-dep
Containers:
nginx:
Image: nginx:1.24.0
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: ngx-dep-5bd855f78b (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set ngx-dep-bfbb5f64b to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set ngx-dep-6f86f86875 to 1
Normal ScalingReplicaSet 9m25s deployment-controller Scaled down replica set ngx-dep-6f86f86875 to 0
Normal ScalingReplicaSet 9m25s deployment-controller Scaled up replica set ngx-dep-7fc9fd6b45 to 1
Normal ScalingReplicaSet 8m29s deployment-controller Scaled down replica set ngx-dep-7fc9fd6b45 to 0
Normal ScalingReplicaSet 8m29s deployment-controller Scaled up replica set ngx-dep-68cb84c7c to 1
Normal ScalingReplicaSet 8m10s deployment-controller Scaled down replica set ngx-dep-68cb84c7c to 0
Normal ScalingReplicaSet 8m10s deployment-controller Scaled up replica set ngx-dep-5bd855f78b to 1
Normal ScalingReplicaSet 6m24s deployment-controller Scaled down replica set ngx-dep-bfbb5f64b to 1
Normal ScalingReplicaSet 5m26s (x2 over 6m24s) deployment-controller (combined from similar events): Scaled down replica set ngx-dep-bfbb5f64b to 0
可以用rollout status看到nginx更新的过程, 而从describe命令打印的日志中可以看到, 更新是一个滚动更新的过程; 可以用下图表示

Kubernetes管理应用更新
除了使用status命令查看更新的状态外; rollout还提供了一些其他的命令对更新过程进行管理:
- 当更新过程中, 发现错误可以使用
rollout pause暂停更新 - 当更新确定没有问题后, 可以使用
rollout resume来继续更新 - 可以使用
rollout history来查看更新记录 - 还可以使用为
rollout history添加参数--revision来查看每个版本的详细信息 - 当想要回滚, 可以使用
rollout undo来回滚到上一个版本, 也可以添加参数--to-revision制定回退版本
# 查看更新历史
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout history deploy ngx-dep
deployment.apps/ngx-dep
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
5 <none>
6 <none>
7 <none>
# 查看revision为2的更新历史的详细记录
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout history deploy ngx-dep --revision=2
deployment.apps/ngx-dep with revision #2
Pod Template:
Labels: app=ngx-dep
pod-template-hash=6f86f86875
Containers:
nginx:
Image: nginx:1.7.0
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
# 回滚到上一次更新
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout undo deploy ngx-dep
deployment.apps/ngx-dep rolled back
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout history deploy ngx-dep
deployment.apps/ngx-dep
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
5 <none>
7 <none>
8 <none>
# 回滚到revision为5的更新
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout undo deploy ngx-dep --to-revision=5
deployment.apps/ngx-dep rolled back
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout history deploy ngx-dep
deployment.apps/ngx-dep
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
7 <none>
8 <none>
9 <none>
这里CHANGE-CAUSE是用于描述更新记录的文本, 可以在yml中国通过metadata.annotations来表示; 当我们添加了该字段后, 就可以看到更新记录了
passnight@passnight-s600:/opt/k8s/learn$ sudo vim nginx-deployment.yml
修改以下内容
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
annotations:
update to 1.24.0 # 添加更新注释
spec:
replicas: 2
minReadySeconds: 15
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:1.24.0 # 将版本更新到1.24.0
name: nginx
应用修改, 便可以观察到更新注释:
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx-deployment.yml
deployment.apps/ngx-dep configured
passnight@passnight-s600:/opt/k8s/learn$ kubectl rollout history deploy ngx-dep
deployment.apps/ngx-dep
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
7 <none>
8 <none>
9 update to 1.24.0 # 这就是在metadata中添加的change-cause
容器状态管理
Kubernetes里面对Pod的管理主要有两种方法:
- 资源配额(resources)
- 状态探针(Probe)
他们能够给Pod添加各种运行保障, 让应用运行的更加健康
容器的资源配额
创建容器使用了Linux中的三大隔离技术: namespace实现了独立的进程空间, chroot实现了独立的文件系统; 而cgroup实现了对CPU/内存的管控, 以保证容器不会无节制地占用系统基础资源进而影响到系统里的其他应用
对资源的申请类似于队存储卷的申请, 它使用的字段名为resources; 下面是在创建nginx pod的过程中添加资源限制的一个例子
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod-resources
spec:
containers:
- image: nginx:alpine
name: ngx
resources: # 倘若resources为空, 表示不对资源做任何限制, 容器可以任意使用系统资源
requests: # 表示系统申请的资源, 若未达到要求时, 容器无法运行
cpu: 10m # Kubernetes允许容器对CPU精细化地风格, 最小的使用单位是0.001个CPU时间片; 为了表示方便, 使用了m代表0.001; 如10m表示可以使用1%的CPU时间
memory: 100Mi
limits: # 这表示容器使用的资源上限, 若超过规定的资源, 容器可能会被强制停止运行
cpu: 20m
memory: 200Mi
上面的配置文件很容易就可以完成对pod的创建
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx-resources.yml
pod/ngx-pod-resources created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ngx-pod-resources 1/1 Running 0 12s
为了体现资源不足的情况, 这里将CPU改为30 我的性能最好的服务器有20个核心, 因此k8s无法申请到足够的资源
passnight@passnight-s600:/opt/k8s/learn$ sudo vim nginx-
# ................................
spec:
containers:
- image: nginx:alpine
name: ngx
resources: # 倘若resources为空, 表示不对资源做任何限制, 容器可以任意使用系统资源
requests: # 表示系统申请的资源, 若未达到要求时, 容器无法运行
cpu: 30 # Kubernetes允许容器对CPU精细化地风格, 最小的使用单位是0.001个CPU时间片; 为了表示方便, 使用了m代表0.001; 如10m表示可以使用1%的CPU时间
memory: 100Mi
limits: # 这表示容器使用的资源上限, 若超过规定的资源, 容器可能会被强制停止运行
cpu: 50
memory: 200Mi
resources.ymlpassnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f nginx-resources.yml
pod/ngx-pod-resources created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods
NAME READY STATUS RESTARTS AGE
ngx-pod-resources 0/1 Pending 0 6s
可以看到创建容器一直处于Pending状态, 使用describe命令查看原因, 可以看到是因为CPU不足
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe pod ngx-pod-resources
Name: ngx-pod-resources
Namespace: default
# 省略部分信息......................................
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 11s default-scheduler 0/3 nodes are available: 3 Insufficient cpu.
容器探针
仅仅限制容器的资源使用量还远远不够, 倘若容器因为某些异常无法对外提供服务, 而容器正常运行, 我们便无法得知其原因, 为了能够检测容器的运行状态, Kubernetes提供了探针(Probe)在应用的检查口提取数据, 检查容器的运行状态
Kubernetes定义了三种探针:
- Startup: 启动探针, 用来检查应用是否已经启动完成, 适合那些有大量初始化工作要做, 启动很慢的应用; 若启动探针失败, Kubernetes会认为容器没有正常启动, 后面的两个探针也不会启动
- Liveness: 存活探针, 用于检查应用是否正常运行, 是否存在死锁/死循环; 若存活探针失败, Kubernetes就会认为容器发生了异常, 就会重启容器
- readiness: 就绪探针, 用来检查应用是否可以接受流量, 是否能够对外提供服务, 当就绪探针失败, Kubernetes就会认为容器虽然在运行, 但不能正常提供服务, Kubernetes就会将其从Service对象的负载均衡中剔除, 不再给它分配流量
他们的状态可以简单地用下图表示:

探针的使用
为了使用这些探针, 我们还要对应用预留检查口, 以下以一个Nginx应用的状态检测为例:
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod-probe
spec:
volumes:
- name: ngx-conf-vol
configMap:
name: ngx-conf
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx/conf.d
name: ngx-conf-vol
startupProbe:
periodSeconds: 1 # 执行探测动作的时间间隔, 默认为10s一次, 这里设置为1s
exec: # 通过判断/var/run/nginx.pid是否存在nginx的进程id文件
command: ["cat", "/var/run/nginx.pid"]
livenessProbe: # 通过判断TCP端口80是否正常运行
periodSeconds: 10
tcpSocket:
port: 80
readinessProbe:
periodSeconds: 5
httpGet: # 通过http访问80端口/ready路径, 以判断是否正常运行
path: /ready
port: 80
---
# 添加/ready配置
apiVersion: v1
kind: ConfigMap
metadata:
name: ngx-conf
data:
default.conf: |
server {
listen 80;
location = /ready {
return 200 'I am ready';
}
}
倘若startup检测失败, nginx容器会处于Running但不Ready的状态, 此时无法提供服务; 我们使用logs命令查看请求, 可以发现探针访问/ready路径不断探测容器是否能够正常提供服务
passnight@passnight-s600:/opt/k8s/learn$ kubectl logs ngx-pod-probe
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: can not modify /etc/nginx/conf.d/default.conf (read-only file system?)
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2023/09/02 06:52:22 [notice] 1#1: using the "epoll" event method
2023/09/02 06:52:22 [notice] 1#1: nginx/1.21.5
2023/09/02 06:52:22 [notice] 1#1: built by gcc 10.3.1 20211027 (Alpine 10.3.1_git20211027)
2023/09/02 06:52:22 [notice] 1#1: OS: Linux 6.2.0-26-generic
2023/09/02 06:52:22 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2023/09/02 06:52:22 [notice] 1#1: start worker processes
2023/09/02 06:52:22 [notice] 1#1: start worker process 23
2023/09/02 06:52:22 [notice] 1#1: start worker process 24
2023/09/02 06:52:22 [notice] 1#1: start worker process 25
2023/09/02 06:52:22 [notice] 1#1: start worker process 26
2023/09/02 06:52:22 [notice] 1#1: start worker process 27
2023/09/02 06:52:22 [notice] 1#1: start worker process 28
2023/09/02 06:52:22 [notice] 1#1: start worker process 29
2023/09/02 06:52:22 [notice] 1#1: start worker process 30
2023/09/02 06:52:22 [notice] 1#1: start worker process 31
2023/09/02 06:52:22 [notice] 1#1: start worker process 32
2023/09/02 06:52:22 [notice] 1#1: start worker process 33
2023/09/02 06:52:22 [notice] 1#1: start worker process 34
2023/09/02 06:52:22 [notice] 1#1: start worker process 35
2023/09/02 06:52:22 [notice] 1#1: start worker process 36
2023/09/02 06:52:22 [notice] 1#1: start worker process 37
2023/09/02 06:52:22 [notice] 1#1: start worker process 38
2023/09/02 06:52:22 [notice] 1#1: start worker process 39
2023/09/02 06:52:22 [notice] 1#1: start worker process 40
2023/09/02 06:52:22 [notice] 1#1: start worker process 41
2023/09/02 06:52:22 [notice] 1#1: start worker process 42
10.244.0.1 - - [02/Sep/2023:06:52:24 +0000] "GET /ready HTTP/1.1" 200 10 "-" "kube-probe/1.23" "-"
10.244.0.1 - - [02/Sep/2023:06:52:27 +0000] "GET /ready HTTP/1.1" 200 10 "-" "kube-probe/1.23" "-"
10.244.0.1 - - [02/Sep/2023:06:52:32 +0000] "GET /ready HTTP/1.1" 200 10 "-" "kube-probe/1.23" "-"
10.244.0.1 - - [02/Sep/2023:06:52:37 +0000] "GET /ready HTTP/1.1" 200 10 "-" "kube-probe/1.23" "-"
10.244.0.1 - - [02/Sep/2023:06:52:42 +0000] "GET /ready HTTP/1.1" 200 10 "-" "kube-probe/1.23" "-"
倘若我们将探测目录改为错误的文件, 使探针无法探测到pid及端口号, 观察他的状态:
startupProbe:
periodSeconds: 1
exec:
command: ["cat", "/var/run/noexists/nginx.pid"]
livenessProbe:
periodSeconds: 10
tcpSocket:
port: 8080
readinessProbe:
periodSeconds: 5
httpGet:
path: /ready
port: 8080
重新创建后, 可以看到容器处于RUNNING但是不READY的状态
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f probe.yml
pod/ngx-pod-probe created
configmap/ngx-conf created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod
NAME READY STATUS RESTARTS AGE
ngx-pod-probe 0/1 Running 1 (3s ago) 7s
集群管理
- Kubernetes的名字空间并不是一个实体的对象, 而是一个逻辑上的概念; 它将集群切分成一个个独立的区域, 使他们只能够在自己的名字空间里分配资源和运行而不干扰到其他名字空间里的应用
- 例如前端/后端/测试都要在集群中创建一些列相同的系统, 这样就可以用名字空间将他们隔离
- 之后我们可以针对各个名字空间进行集群管理
名字空间的使用
创建名字空间非常简单, 甚至不需要使用yml配置文件, 可以直接使用命令kubectl create namespace 来创建名字空间 这里注意, 系统已经默认有default/kube-public/system/kube-node-lease四个名字空间, 当不指定时默认为*default***
passnight@passnight-s600:/opt/k8s/learn$ kubectl create namespace test
namespace/test created
passnight@passnight-s600:/opt/k8s/learn$ sudo vim namespace.yml
apiVersion: v1
kind: Pod
metadata:
name: ngx
namespace: test
spec:
containers:
- image: nginx:alpine
name: ngx
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f namespace.yml
pod/ngx created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod
No resources found in default namespace.
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
ngx 1/1 Running 0 6s
我们可以看到kubectl get获得的时默认名字空间内的pod; 若想要操作其他名字空间里的对象, 必须使用-n参数致命名字空间
若我们删除名字空间, 我们可以看到名字空间内的所有资源都被删除了
passnight@passnight-s600:/opt/k8s/learn$ kubectl delete namespace test
namespace "test" deleted
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pod -n test
No resources found in test namespace.
passnight@passnight-s600:/opt/k8s/learn$ kubectl get namespace | grep test
资源配额
我们可以像管理容器一样, 给容器空间分配资源配额, 把集群的计算资源/存储资源等分割成不同大小, 按需分配给团队使用; 管理该资源的API对象为ResourceQuota
passnight@passnight-s600:/opt/k8s/learn$ kubectl api-resources |grep resourcequotas
resourcequotas quota v1 true ResourceQuota
在ResourcesQuota中, 我们可以限制许多资源26, 其中最常用的有:
- CPU和内存配额: 可以使用
request.*和limits.*进行限制 使用同对容器的限制一样 - 对存储容量的配额: 使用
requests.storage来限制PVC存储的总量, 也可以用persistentVolumeClaims来限制PVC的个数 - 核心对象配额: 可以使用对象的名字(复数形式), 如
pods/configmaps等来限制核心对象的使用 - 其他 API对象的使用: 使用
count/name.group的形式, 如count/jobs.batsh/count/deployments.apps等
下面就是一个比较完整的ResourcesQuota对象:
apiVersion: v1
kind: ResourceQuota
metadata:
name: dev-qt
namespace: dev-ns # 对namespace dev-ns进行限制
spec:
hard:
# 最多只能分配10个CPU和10Gi内存
requests.cpu: 10
requests.memory: 10Gi
limits.cpu: 10
limits.memory: 20Gi
# 限制持久化空间大小为100Gi, 数量为100个(PVC)
requests.storage: 100Gi
persistentvolumeclaims: 100
# 只能创建100个pods/configmaps.....
pods: 100
configmaps: 100
secrets: 100
services: 10
# 只能创建一个job/cronjob/deployment
count/jobs.batch: 1
count/cronjobs.batch: 1
count/deployments.apps: 1
创建并查看限额
passnight@passnight-s600:/opt/k8s/learn$ kubectl create namespace dev-ns
namespace/dev-ns created
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f quota-ns.yml
resourcequota/dev-qt created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get resourcequotas -n dev-ns
NAME AGE REQUEST
LIMIT
dev-qt 34s configmaps: 1/100, count/cronjobs.batch: 0/1, count/deployments.apps: 0/1, count/jobs.batch: 0/1, persistentvolumeclaims: 0/100, pods: 0/100, requests.cpu: 0/10, requests.memory: 0/10Gi, requests.storage: 0/100Gi, secrets: 1/100, services: 0/10 limits.cpu: 0/10, limits.memory: 0/20Gi
LimitRange
- ResourceQuota对于管理namespace的资源很有帮助, 但倘若有大量临时pod需要管理, 使用
ResourceQuota就非常麻烦了 - Kubernetes提供了
LimitRange可以为每个API对象添加默认的资源限制, 这样就不用每次声明都配置了
下面是一个LimitRange例子:
apiVersion: v1
kind: LimitRange
metadata:
name: dev-limits
namespace: dev-ns
spec:
limits:
- type: Container # 每个容器默认限制资源
defaultRequest:
cpu: 200m
memory: 50Mi
default:
cpu: 500m
memory: 100Mi
- type: Pod # 每个pod默认限制资源
max:
cpu: 800m
memory: 200Mi
这样我们在创建容器后就可以看到他们默认都有资源配额
passnight@passnight-s600:/opt/k8s/learn$ sudo vim limit-range.yml
passnight@passnight-s600:/opt/k8s/learn$ kubectl apply -f limit-range.yml
limitrange/dev-limits created
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe limitranges -n dev-ns
Name: dev-limits
Namespace: dev-ns
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu - - 200m 500m -
Container memory - - 50Mi 100Mi -
Pod cpu - 800m - - -
Pod memory - 200Mi - - -
passnight@passnight-s600:/opt/k8s/learn$ kubectl run ngx --image=nginx:alpine -n dev-ns
pod/ngx created
passnight@passnight-s600:/opt/k8s/learn$ kubectl get pods -n dev-ns
NAME READY STATUS RESTARTS AGE
ngx 1/1 Running 0 42s
passnight@passnight-s600:/opt/k8s/learn$ kubectl describe pod ngx -n dev-ns
Name: ngx
Namespace: dev-ns
Priority: 0
Node: passnight-s600/fd12:4abe:6e6e::7f8
Start Time: Sat, 02 Sep 2023 15:25:12 +0800
Labels: run=ngx
Annotations: kubernetes.io/limit-ranger: LimitRanger plugin set: cpu, memory request for container ngx; cpu, memory limit for container ngx
Status: Running
IP: 10.244.0.185
IPs:
IP: 10.244.0.185
Containers:
ngx:
Container ID: docker://9bf36dbd1520536d6d194cc9d4c466304d0af2ebdceb0ddadccfd2ae199be050
Image: nginx:alpine
Image ID: docker-pullable://nginx@sha256:eb05700fe7baa6890b74278e39b66b2ed1326831f9ec3ed4bdc6361a4ac2f333
Port: <none>
Host Port: <none>
State: Running
Started: Sat, 02 Sep 2023 15:25:13 +0800
Ready: True
Restart Count: 0
Limits: # 可以看到容器已经被添加了默认的资源配额
cpu: 500m
memory: 100Mi
Requests:
cpu: 200m
memory: 50Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-2x6q8 (ro)
系统监控
Kubernetes除了探针以外还提供了两种系统级别的监控: Metrices Server以及基于他们的HorizontalPodAutoscaler
Metrics Server
同Linux主机和Docker一样, 我们可以使用top命令查看pod/node等对象的状态; 但这需要安装Metrics Server
passnight@passnight-s600:/opt/k8s/learn$ kubectl top node
error: Metrics API not available
我们直接安装最新版的metrices server27; 直接安装会报错500, 原因是没有配置tls证书, 为了方便, 我们直接将该功能给关掉28; metrics server暂时还无法访问ipv6, 因此s600暂时无法访问, 以下是报错
E0902 07:51:04.058052 1 scraper.go:140] "Failed to scrape node" err="Get \"https://[fd12:4abe:6e6e::7f8]:10250/metrics/resource\": dial tcp [fd12:4abe:6e6e::7f8]:10250: connect: cannot assign requested address" node="passnight-s600"
以下是实现过程:
passnight@passnight-s600:/opt/k8s$ sudo wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.4/components.yaml -O metrics-server.yml
passnight@passnight-s600:/opt/k8s$ sudo vim metrics-server.yml
# 在Deployment中添加spec.template.spec.containers[0].artgs[0] = --kubelet-insecure-tls
# 在Deployment中添加spec.template.spec.containers[0].artgs[1] = --kubelet-preferred-address-types=InternalIP
passnight@passnight-s600:/opt/k8s$ kubectl apply -f metrics-server.yml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
之后就可以通过top命令查看各种资源的使用量
passnight@passnight-s600:~$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
passnight-acepc 295m 7% 2266Mi 60%
passnight-centerm 93m 2% 2294Mi 61%
passnight-s600 <unknown> <unknown> <unknown> <unknown>
passnight@passnight-s600:~$ kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-64897985d-zjzs2 12m 12Mi
kube-proxy-glbjp 1m 10Mi
kube-proxy-h957l 3m 10Mi
根据章节1.7.10 部分请求无法返回中的修复方法将域名解析到IPv4上面, 便可正常监控所有节点
passnight@passnight-s600:/etc/netplan$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
passnight-acepc 432m 10% 2246Mi 60%
passnight-centerm 102m 2% 2408Mi 65%
passnight-s600 402m 2% 16266Mi 25%
HorizontalPodAutoscaler
- 有了
Metrics server就可以查看集群资源使用情况了, 在此基础之上, 它可以实现一个更重要的功能: 水平自动伸缩 - 因此, Kubernetes定义了一个新的API对象: HorizontalPodAutoscaler, 他可以用于自动管理Pod数量
我们首先创建一个Nginx应用, 并将资源限额配置得较小, 以便于观察扩容
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-hpa-dep
spec:
replicas: 1
selector:
matchLabels:
app: ngx-hpa-dep
template:
metadata:
labels:
app: ngx-hpa-dep
spec:
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 100m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: ngx-hpa-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: ngx-hpa-dep
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: ngx-hpa
spec:
maxReplicas: 10 # 最多10个
minReplicas: 2 # 最少2个
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ngx-hpa-dep
targetCPUUtilizationPercentage: 5 # 当CPU使用率超过5%则开始扩容
创建, 并压测该容器
passnight@passnight-s600:/opt/k8s/learn$ sudo vim auto-scale.yml
一段时间后就可以看到新的容器被创建了
Every 2.0s: kubectl get pods -o wide passnight-s600: Sat Sep 2 16:37:58 2023
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ngx-hpa-dep-86f66c75f5-b6hn4 1/1 Running 0 10m 10.244.0.193 passnight-s600 <none> <none>ngx-hpa-dep-86f66c75f5-flwkl 1/1 Running 0 5s 10.244.0.194 passnight-s600 <none> <none>ngx-hpa-dep-86f66c75f5-frcz6 1/1 Running 0 10m 10.244.1.23 passnight-centerm <none> <none>ngx-hpa-dep-86f66c75f5-kg5xh 1/1 Running 0 5s 10.244.2.19 passnight-acepc <none> <none>
网络模型
下图描述的事docker的bridge网络模型, Docker创建一个名字叫docker0的网桥, 每个容器创建一个虚拟网卡对并连接在docker所创建的虚拟网桥上:
Docker这样的工作模式在单机模式下可以很好的工作, 但在急群众工作非常困难, 因为要做端口映射和网络地址转换.
为了解决Docker的网络缺陷, Kubernetes提出了自己的网络模型: IP-per-pod, 它有四个基本假设:
- 集群中每个Pod都会有一个唯一的IP地址
- Pod里的所有容器都共享这个ip地址
- 集群里的所有pod都属于同一个网段
- Pod可以直接基于IP地址访问另一个pod, 不需要做网络地址转换
如下图所示:

CNI
- Kubernetes定义了上述的网络模型, 而CNI(Container Network Interface)就是Kubernetes为了实现它所制定的标准
- CNI为网络插件定义了一系列接口, 只要开发者遵循这个规范就可以接入Kubernetes, 为pod创建虚拟网卡/分配IP地址/设置路由规则, 进而实现IP-per-pod
- CNI大致可以分为以下三类:
- Overlay: Overlay的意思是覆盖, 它构建了一个工作在真是底层网络之上的逻辑网络, 把原始的Pod网络数据封包拆包, 因为这个特点, 它对底层网络的要求低, 适应性强; 缺点就是有额外的传输成本, 性能较差
- Route: Route也是建立在底层网络上的, 但是没有封包和拆包, 而是基于系统内置的路由功能实现, 它的好处就是性能较高, 但对底层网络的依赖较强
- Underlay: 就是直接使用底层网络实现CNI, 也就是说Pod和宿主机在一个网络中, pod和宿主机是平等的, 它对底层的硬件和网络的依赖性最强, 因此不够灵活, 但性能最高
- CNI因为接口定义宽松, 有很大自由发挥的空间, 因此社区中有大量的网络插件:
- Flannel: 最早是一种Overlay模式的网络插件, 后来又实用Host-Gateway支持了Route模式, 它简单易用, 是Kubernetes中最流行的CNI插件, 但性能较差
- Calico: 是一种Route模式的网络插件, 使用BGP协议维护路由信息, 性能交Flannel好, 且支持多种网络策略, 如数据加密/安全隔离/流量整形等功能
- Cilium: 是一个比较新的网络插件, 同时支持Overlay和Route模式, 它使用了Linux 额BPF技术, 因此性能很高
CNI的工作原理
Flannel工作原理

上图从单机角度来看, 几乎和Docker一样, 但添加了flannel, 它将pod内部地址虚拟化, 并桥接到宿主机的路由表上, 使得我们可以通过ip路由到其他节点
Calico工作原理

Calico使用的是Route模式, 它直接修改了路由表, 使得我们可以直接通过宿主机上的规则直接路由到目标节点上
引用
Helm | 安装Helm ↩︎
kubernetes之Ingress发布Dashboard(二) - 梨花海棠 - 博客园 (cnblogs.com) ↩︎
Permission errors with dashboard v2.0.0-beta3 · Issue #4179 · kubernetes/dashboard (github.com) ↩︎
apt-key is deprecated. Manage keyring files in trusted.gpg.d (itsfoss.com) ↩︎
kubeadm init error: CRI v1 runtime API is not implemented — Linux Foundation Forums ↩︎
Ubuntu 20.04 LTS 关闭 Swap 分区_ubuntu 关闭swap_极客点儿的博客-CSDN博客 ↩︎
初始化集群coredns容器一直处于pending状态_coredns pending_不忘初心fight的博客-CSDN博客 ↩︎
[ k8s实践]集群初始化后修改 pod cidr 支持 CNI 组件 - 掘金 (juejin.cn) ↩︎
CRI getFsInfo logs errors for valid filesystems mounted after kubelet start · Issue #94825 · kubernetes/kubernetes (github.com) ↩︎
[coredns不断重启,CrashLoopBackOff, FATAL] plugin loop_多网卡 k8s coredns 一直重启_半生不随的博客-CSDN博客 ↩︎
为什么 kubernetes 需要有 2 个 coredns pod_kubernetes_K8SOQ-K8S/Kubernetes (csdn.net) ↩︎
Why There is No Kubernetes Pod on the Master Node | by Gaurav Gupta | Medium ↩︎
利用taint机制让master上也能部署pod - 简书 (jianshu.com) ↩︎
污点和容忍度 | Kubernetes ↩︎
Installation Guide - Ingress-Nginx Controller (kubernetes.github.io) ↩︎
MetalLB, bare metal load-balancer for Kubernetes (universe.tf) ↩︎
MetalLB, bare metal load-balancer for Kubernetes (universe.tf) ↩︎
openwrt-DHCP池地址范围怎么设置-OPENWRT专版-恩山无线论坛 - Powered by Discuz! (right.com.cn) ↩︎
本地 k8s 集群也可以有 LoadBalancer | k8s 折腾笔记 (todoit.tech) ↩︎
MetalLB, bare metal load-balancer for Kubernetes (universe.tf) ↩︎
MetalLB provides Services with IP Addresses but doesn’t ARP for the address · Issue #1154 · metallb/metallb (github.com) ↩︎
Custom Resources | Kubernetes ↩︎
MetalLB, bare metal load-balancer for Kubernetes (universe.tf) ↩︎
How to fix kubernetes nfs mount error no such file or directory - Stack Overflow ↩︎
Kubernetes 如何安装 NFS-Subdir-External-Provisioner存储插件?_wx6086232c36932的技术博客_51CTO博客 ↩︎
Resource Quotas | Kubernetes ↩︎
Releases · kubernetes-sigs/metrics-server (github.com) ↩︎
Kubernetes Metric Server - cannot validate certificate because it doesn’t contain any IP SANs (veducate.co.uk) ↩︎