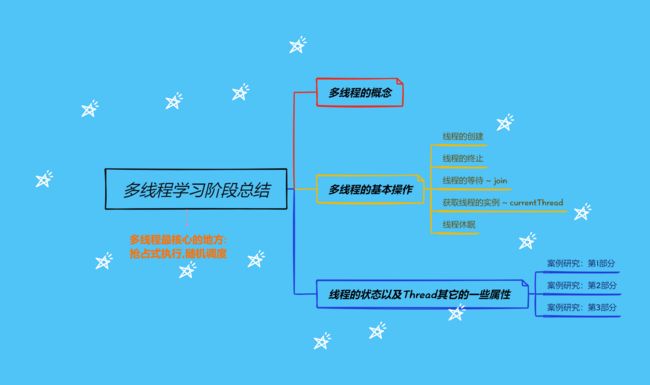
多线程的学习中篇上
获取当前线程引用
| 方法 | 说明 |
|---|---|
| public static Thread currentThread(); | 返回当前线程对象的引用 |
currentThread() => 在那个线程中, 就能获取到那个线程的实例.
static关键字
static修饰的方法~~字面的直译 ~~静态方法(不好的翻译) => 类方法(更好的说法)
调用这个方法,不需要实例,直接通过类名来调用.
Thread t = new Thread;
调用这个上述这个方法的时候,直接Thread.currentThread();
不一定非要t.currrentThread;
从字面上看,static这个词,和类方法/类属性之间,没什么联系.
static ~~ 历史遗留问题
Java这么设计,是因为C++也是这么设计的. ~~ Java很多语法都是借鉴C++的
而C++又是从C语言演化来的,在C语言中,static可以修饰全局/变量变量,修饰函数.
~~ 在早期的操作系统中,内存划分的区域,是存在一个“静态内存区”.
static最初的作用就是被static修饰的变量就在“静态内存区”.
但是后来“静态内存区”没有了,但是static关键字被保留下来了,并重新赋予了新的功能.
C++中引入了类和对象,就急需有一种途径来表示"类属性"“类方法”.
就直接把之前的 static关键字给拿过来,不管它字面含义如何,直接赋予它新的历史使命了.
新的问题来了,为什么不创建一个新的关键字来表示“类属性,类方法”,比如Python中的classmethod?
原因就是关键字有特殊的含义不能作为变量名,不能作为函数名,不能作为类名……
一旦引入了新的关键字,此时原有写的千千万万写的代码里面一旦使用了这个关键字的单词作为
变量名,代码就无法通过编译器的编译了.
但是,这对于程序猿来说是无法接受的,那么多编译不过的代码是不可能重写的.
这个事情主要体现的就是“代码的兼容性”.
注:我们现在学的C语言的功能已经是变了之后的.
冷知识:C语言这近二十年,都没有太大的变化.C标准委员会大佬们已经在摆烂了,
包括C语言之父,肯汤姆逊,已经去全身心投身于Go语言了(不在更新,就是消亡的前兆).
休眠当前线程
~~ 本质上就是让这个线程不参与调度了(不去CPU上执行了)
| 方法 | 说明 |
|---|---|
| public static void sleep(long millis) throws InterruptedException | 休眠当前线程 millis 毫秒 |
| public static void sleep(long millis, int nanos) throws InterruptedException | 可以更高精度的休眠 |
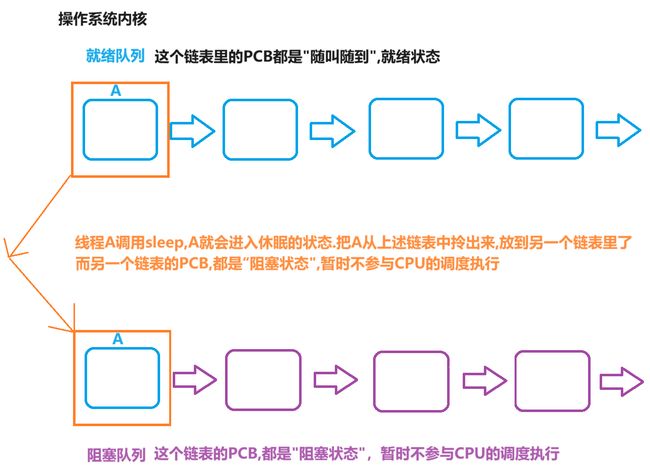
注:
(1)PCB 是使用链表来组织的.(并不具体)实际的情况并不是一个简单的链表,其实这是一系列以链表为核心的数据结构.
(2)操作系统每次需要调度一个线程去执行,就从就绪队列中选一个就好了
(3)一旦线程进入阻塞状态,对应PCB就进入阻塞队列了,此时就暂时无法参与调度了.
(4)这个方法只能保证实际休眠时间是大于等于参数设置的休眠时间的。
比如调用sleep(1000),对应的线程PCB就要再阻塞队列中待1000ms这么久
当这个PCB回到了就绪队列,会被立即调度嘛?
虽然是 sleep (1000),但是实际上考虑到调度的开销,对应的线程是无法在唤醒之后立即就执行的.实际上的时间间隔大概率要大于1000ms.
~~ 挂起(hung up)就是阻塞(block),一个意思,学校操作系统的课一般使用“挂起”这个术语较多.
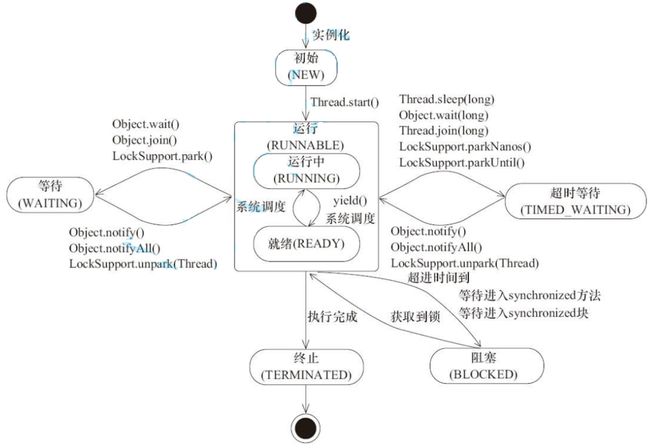
线程的状态
状态是针对当前的线程调度的情况来描述的.
由于线程是调度的基本单位,状态就是线程的属性
| 属性 | 说明 | 个人理解 |
|---|---|---|
| 1.NEW | 安排了工作, 还未开始行动 | 创建了Thread 对象,但是还没调用start(内核里还没创建对应PCB) |
| 2.TERMINATED | 工作完成了 | 表示内核中的PCB已经执行完毕了,但是Thread对象还在 |
| 3.RUNNABLE | 可工作的. 又可以分成正在工作中和即将开始工作 | 可运行的(叫做RUNNABLE,而是RUNNING) (1)正在CPU上执行的 (2)在就绪队列里,随时可以去CPU上执行 |
| 4,5,6都是表示线程PCB正在阻塞队列中 | 4,5,6这三个状态是不同原因的阻塞 | 4,5,6这三个都表示排队等着其他事情 |
| 4.WAITING | 表示排队等着其他事情 | |
| 5.TIMED_WAITING | 表示排队等着其他事情 | |
| 6.BLOCKED | 表示排队等着其他事情 |
注:线程的状态是一个枚举类型 Thread.State, 可通过
for (Thread.State state : Thread.State.values()) { System.out.println(state); } 这段代码将线程的属性都打印出来.
线程状态和状态转移的意义
图示详解
博主所做的简化图
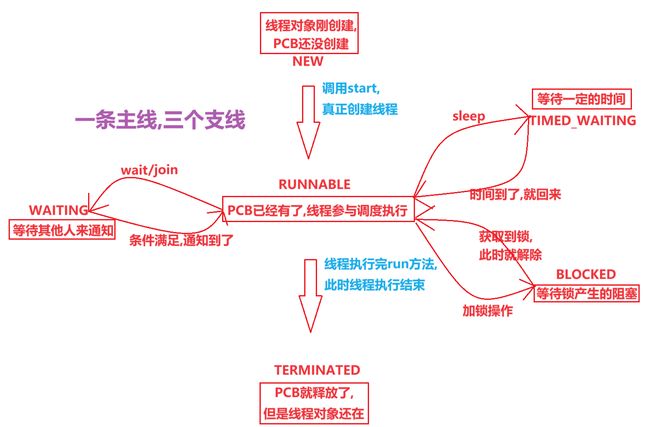
TERMINATED:
一旦内核里的线程PCB 消亡了,此时代码中t对象也就没啥用了
Java中的对象的生命周期和系统内核里的线程并非完全一致
内核的线程释放的时候,无法保证Java代码中t对象也立即释放
因此,势必就会存在,内核的PCB没了,但是代码中的t还在这样的情况
此时就需要通过特定的状态,来把t对象标识成“无效".
也是不能重新start 的,一个线程,只能start一次!!
~~ 一个变量/一个对象,一般只有一个用途(约定俗成的规矩)
示范代码:
public class ThreadDemo11 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i < 1000000; i++) {
// 这个循环体什么都不做
}
});
// 启动之前, 获取 t 的状态, 就是 NEW 状态
System.out.println("start 之前: "+t.getState());
t.start();
System.out.println("线程 t 执行中的状态: "+ t.getState());
t.join();
// 线程执行完毕之后, 就是 TERMINATED 状态
System.out.println("线程 t 结束之后: "+ t.getState());
}
}
运行结果:
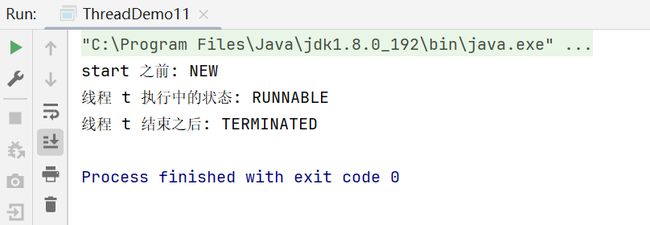
之所以,此处能看到RUNNABLE,主要就是因为当前线程run里面,没写任何 sleep之类的方法.
当前获取到的状态,到底是什么,完全取决于系统的调度操作.
多线程的意义到底是什么?

多线程,在这种CPU密集型的任务中,有非常大的作用,可以充分利用CPU的多核资源
从而加快程序的运行效率.
多线程在IO密集型的任务中,也是很有作用的.
~~ 我们用智能手机的时候,有时候会遇到“程序未响应”的界面提示(比如打开QQ音乐的时候),
程序进行了一些耗时的IO操作(比如QQ音乐启动要加载数据文件,就涉及到大量的读硬盘操作),阻塞了界面的响应.这种情况下使用多线程也是可以有效改善的(一个线程负责IO,另一个线程用来响应用户的操作).
单线程写法:
public class ThreadDemo12 {
public static void main(String[] args) {
// 假设当前有两个变量, 需要把两个变量各自自增 100亿次. => 典型的 CPU 密集型的场景
// 可以一个线程, 先针对 a 自增, 然后再针对 b 自增
// 还可以两个线程, 分别是 a 和 b 自增
serial();
}
// serial (串行) ~~ 串行执行, 一个线程完成
public static void serial() {
// 为了衡量代码的执行速度, 加上个计时的操作
// currentTimeMillis 获取到当前系统的 ms 级时间戳
long beg = System.currentTimeMillis();
long a = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
a++;
}
long b = 0;
for (long j = 0; j < 100_0000_0000L; j++) {
b++;
}
long end = System.currentTimeMillis();
System.out.println("执行时间: " + (end - beg) + " ms");
}
}
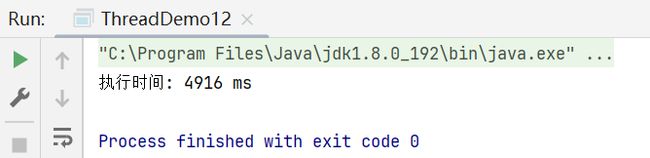
单线程写法的运行结果:
注: 就像这种衡量执行时间的代码,让他运行的久一点,不是坏事,运行的久,误差就小.
(线程调度自身也是有时间开销的)运算的任务量越大,线程调度的开销相比之下就特别不明显了,从而就可以忽略不计.
多线程写法:
package thread;
/**
* Created with IntelliJ IDEA.
* Description:
* User: fly(逐梦者)
* Date: 2023-09-22
* Time: 11:45
*/
// 通过这个线程来演示, 多线程和单线程相比, 效率的提升
public class ThreadDemo12 {
public static void main(String[] args) {
// 假设当前有两个变量, 需要把两个变量各自自增 100亿次. => 典型的 CPU 密集型的场景
// 可以一个线程, 先针对 a 自增, 然后再针对 b 自增
// 还可以两个线程, 分别是 a 和 b 自增
//serial();
concurrency();
}
// concurrency(并发性)
public static void concurrency() {
// 使用两个线程分别完成自增.
Thread t1 = new Thread(() -> {
long a = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
a++;
}
});
Thread t2 = new Thread(()->{
long b = 0;
for (long j = 0; j<100_0000_0000L;j++){
b++;
}
});
// 开始计时
long beg = System.currentTimeMillis();
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 结束计时
long end = System.currentTimeMillis();
System.out.println("执行时间: " + (end - beg) + " ms");
}
}
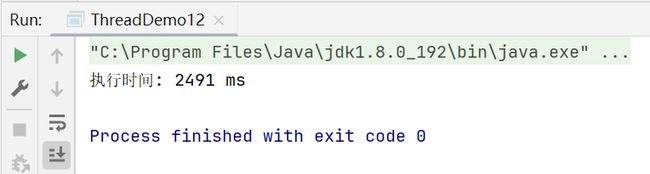
多线程写法的运行结果:
代码执行顺序:
main线程先调用t1.start.
启动t1开始计算t1的同时,main再调用t2.start,
启动t2的同时,t1仍然再继续计算.同时main线程进入就t1.join,
此时main阻塞等待了,t1和t2还是再继续执行的.
等到t1执行完了, main线程从t1.join返回,再进入t2.join,再来等待,
等到 t2执行完了,main 从t2.join返回,继续执行计时操作并打印执行时间.
~~ t2 是有可能比 t1 先结束的, 但是对程序结果没有任何影响.
t1.join 还是正常等,执行到 t2.join 的时候,就立即返回,不在等了.
此处使用两个线程并发执行,时间确实缩短的很明显(4916ms -> 2491ms)
为什么使用多线程更快?
多线程可以更充分的利用到多核心cpu的资源~~
但是为啥不是正好缩短一半??
(1)t1和t2,不一定是分布在两个CPU上执行,
它俩既有可能是并行执行,也有可能是并发执行.
实际上, t1和t2在执行过程中,会经历很多次的调度.
这些调度,有些是并发执行的(在一个核心上),有些是并行执行的(正好在两个核心上).
(2)线程调度自身也是有时间消耗的.
虽然虽然缩短的不是50%,但是仍然很明显,仍然很有意义!!
学习多线程推荐看的书:
<
常见的开发方向:
1.后端开发
2.前端开发
3.客户端开发
4.测试开发
5.运维开发
6.算法工程师(策略开发)
7.游戏开发
……
多线程当前学习阶段的小结