AI AIgents时代 - (四.) HuggingGPT & MetaGPT
HuggingGPT
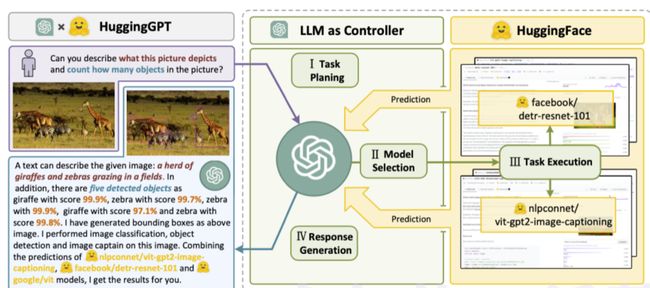
HuggingGPT是一个多模型调用的 Agent 框架,利用 ChatGPT 作为任务规划器,根据每个模型的描述来选择 HuggingFace 平台上可用的模型,最后根据模型的执行结果生成总结性的响应。
这个项目目前已在 Github 上开源,并且有一个非常酷的名字叫做 JARVIS(钢铁侠的助手)。这项研究主要涉及到两个主体,一个是众所周知的 ChatGPT,另一个是 AI 社区中的 Hugging Face。
Hugging Face是什么?
简单来说,Hugging Face是一个专注于人工智能的开源社区平台,用户可以在该平台上发布和共享预训练模型、数据集和展示文件等。目前在Hugging Face上已经共享了超过10万个预训练模型和1万多个数据集。包括微软、谷歌、彭博社、英特尔等众多行业的1万家机构都在使用Hugging Face的产品。

在HuggingGPT中,ChatGPT充当了”操作大脑”的角色,能够自动解析用户提出的需求,并在Hugging Face的AI模型库中进行自动模型选择、执行和报告,为我们开发更复杂的人工智能程序提供了极大的便利。
HuggingGPT 工作原理
这个系统包含四个阶段:
1. 任务规划
使用LLM作为大脑,将用户的请求解析为多个任务。每个任务都有任务类型、ID、依赖关系和参数四个属性。系统会使用一些示例来指导LLM进行任务解析和规划。
具体指令如下:
[{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]
-
"dep"字段表示前一个任务的ID,该任务生成了当前任务所依赖的新资源。
-
“-task_id”字段指的是具有任务ID为task_id的依赖任务中生成的文本图像、音频和视频。
2. 模型选择
LLM将任务分配给专门的模型,这些请求被构建成了一道多项选择题。LLM为用户提供了一个模型列表供选择。由于上下文长度的限制,需要根据任务类型进行过滤。
具体指令如下:
根据用户请求和调用命令,Agent 帮助用户从模型列表中选择一个合适的模型来处理用户请求。Agent 仅输出最合适模型的模型ID。输出必须采用严格的JSON格式:{“id”: “模型ID”, “reason”: “您选择该模型的详细原因”}。
之后,HuggingGPT根据下载次数对模型进行排名,因为下载次数被认为是反映模型质量的可靠指标。选择的模型是根据这个排名中的“Top-K”模型来进行的。K在这里只是一个表示模型数量的常数,例如,如果设置为3,那么它将选择下载次数最多的3个模型。
3. 任务执行
专家模型在特定任务上执行并记录结果。
根据输入和推理结果,Agent 需要描述过程和结果。前面的阶段可以形成下方的输入
用户输入:{{用户输入}},任务规划:{{任务}},模型选择:{{模型分配}},任务执行:{{预测结果}}。
为了提高此过程的效率,HuggingGPT 可以同时运行不同的模型,只要它们不需要相同的资源。例如,如果我提示生成猫和狗的图片,那么单独的模型可以并行运行来执行此任务。
但是,有时模型可能需要相同的资源,这就是为什么HuggingGPT维护一个属性来跟踪资源的原因。它确保资源得到有效利用。
4. 响应生成
LLM 接收执行结果,并向用户提供总结结果。
然而,要将HuggingGPT应用于实际场景中,我们需要应对一些挑战:
-
提高效率:因为LLM的推理轮次和与其他模型的交互都会减缓处理速度
-
依赖长上下文窗口:LLM需要使用长篇的上下文信息来传递复杂的任务内容
-
提高稳定性:需要改进LLM的输出质量以及外部模型服务的稳定性。
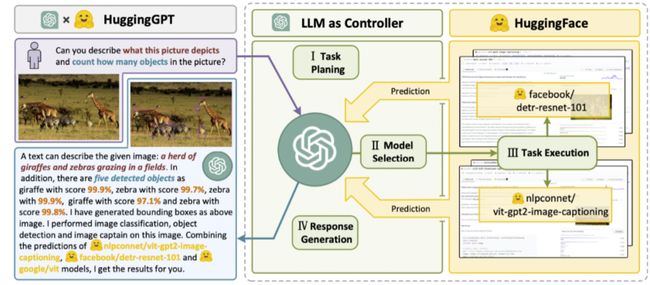
现在,让我们假设您希望模型根据图像生成一个音频。HuggingGPT会以最适合的方式连续执行这个任务。您可以在下面的图中查看更详细的响应信息

快速体验
体验HuggingGPT非常简单,只需要输入 openai apikey 和HuggingGPT token 即可:
访问地址:
https://huggingface.co/spaces/microsoft/HuggingGPT
了解了AutoGPT、AgentGPT和HuggingGPT的工作原理后,我相信大家对Agents的能力已有了一定认识。那么 MetaGPT 作为它们之后诞生的项目,是如何成为又一个引起轰动的 Agents 项目呢?我们下面就来拆解 MetaGPT。
MetaGPT
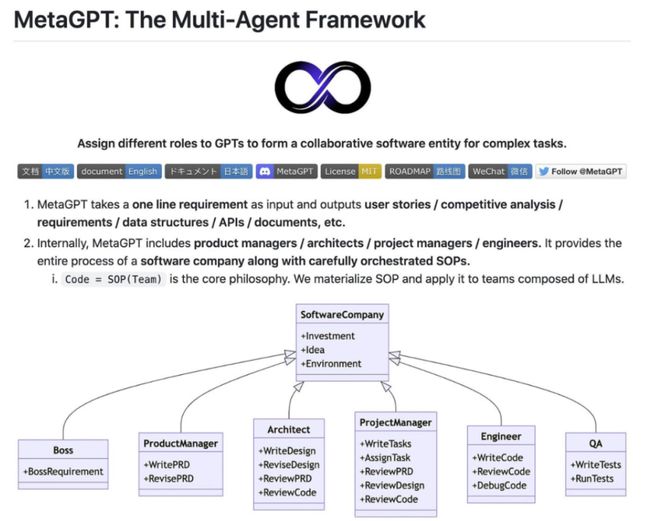
MetaGPT引入了一个将人工工作流程与多智能体协作无缝集成的框架。通过将标准化操作(SOP) 程序编码为提示,MetaGPT确保解决问题时采用结构化方法,从而减少出错的可能性。
当前 Agent 的解决方案存在一个问题:尽管这些语言模型驱动的 Agent 在简单的对话任务上取得了显著进展,但在面对复杂任务时,LLM 会陷入困境,仿佛看到了并不存在的事物(幻觉)。当将这些 Agent 串联起来时,就会引发混乱的连锁反应。
现在 MetaGPT 引入了标准化操作程序。这些操作程序就像作弊码一样,用于顺利协调工作。它们告诉代理们发生了什么事,以有条不紊的方式指导他们。
借助这些操作程序,代理几乎可以像领域专家一样熟悉他们的工作,并验证输出以避免错误。就像高科技流水线一样,每个代理都扮演着独特的角色,共同理解复杂的团队合作。
为什么 MetaGPT 很重要
MetaGPT 提供了一个全新的视角。这就是它掀起波澜的原因:
-
稳定的解决方案:借助SOP,与其他 Agents 相比,MetaGPT 已被证明可以生成更一致和正确的解决方案。
-
多样化的角色分配:为LLM分配不同角色的能力确保了解决问题的全面性。
MetaGPT 软件开发过程
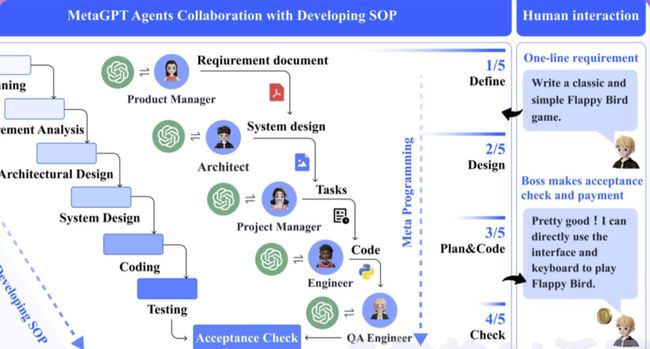
需求分析:收到需求后,该过程开始。这一阶段致力于明确软件所需的功能和要求。
-
扮演产品经理:产品经理以需求和可行性分析为基础,开启整个流程。他们负责理解需求,并为项目制定明确的方向。
-
扮演架构师:一旦需求明确,架构师将为项目创建技术设计方案。他们负责构建系统接口设计,确保技术实现符合需求。在MetaGPT中,架构 Agent 可以自动生成系统界面设计,如内容推荐引擎的开发。
-
扮演项目经理:项目经理使用序列流程图来满足每个需求。他们确保项目按计划前行,每个阶段都得到适时执行。
-
扮演工程师:工程师负责实际的代码开发。他们使用设计和流程图,将其转化为功能完备的代码。
-
扮演质量保证(QA)工程师:在开发阶段结束后,QA工程师进行全面的测试。他们确保软件符合所需标准,不存在任何错误或问题。
实例
举个例子,当你输入
python startup.py “Design a RecSys like Toutiao”,
MetaGPT会为你提供多个输出,其中之一是有关数据和API设计的指导。
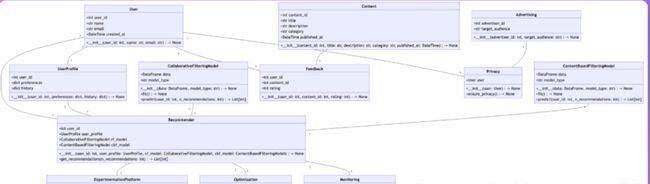
生成一个包含分析和设计示例的成本大约为0.2美元(使用GPT-4 API),而完整项目的成本约为2.0美元。通过这种方式,MetaGPT提供了低廉的解决方案,让你能够快速获取所需的信息和指导。
快速体验
目前MetaGPT暂无在线体验版本。这里我会列出docker的安装方法,最大程度减少大家安装面对的环境难度:
# Step 1: Download metagpt official image and prepare config.yaml docker pull metagpt/metagpt:v0.3.1 mkdir -p /opt/metagpt/{config,workspace} docker run --rm metagpt/metagpt:v0.3.1 cat /app/metagpt/config/config.yaml > /opt/metagpt/config/key.yaml vim /opt/metagpt/config/key.yaml # Change the config
# Step 2: Run metagpt demo with container docker run --rm \ --privileged \ -v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \ -v /opt/metagpt/workspace:/app/metagpt/workspace \ metagpt/metagpt:v0.3.1 \ python startup.py "Write a cli snake game" # You can also start a container and execute commands in it docker run --name metagpt -d \ --privileged \ -v /opt/metagpt/config/key.yaml:/app/metagpt/config/key.yaml \ -v /opt/metagpt/workspace:/app/metagpt/workspace \ metagpt/metagpt:v0.3.1 docker exec -it metagpt /bin/bash $ python startup.py "Write a cli snake game"
将"Write a cli snake game"更换成你喜欢的命令试试吧!
更多安装的教程建议看官方指南。