深度学习自学笔记六:深层神经网络
一、深层神经网络概述
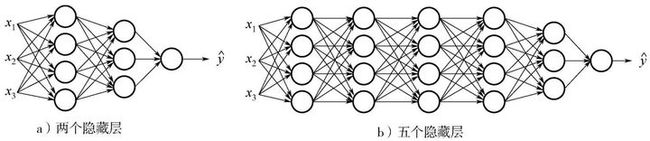
深层神经网络(Deep Neural Networks,DNN)是一种机器学习模型,由多个神经网络层组成。与传统的浅层神经网络相比,深层神经网络具有更多的隐藏层,使其能够进行更复杂、更抽象的特征学习和表示。
添加图片注释,不超过 140 字(可选)
深层神经网络的核心思想是通过反向传播算法来优化网络参数,以最小化预测输出与真实值之间的误差。每个隐藏层接收前一层的输出,并使用非线性激活函数对输入进行变换。这允许网络学习非线性关系,并捕捉输入数据中的高级特征。
深层神经网络的结构可以分为三个主要部分:
1. 输入层(Input Layer):接收原始输入数据,并将其传递给下一层。
2. 隐藏层(Hidden Layers):通常包括多个层,每一层都从前一层接收输入,并将经过非线性变换后的结果传递给下一层。这些层逐渐提取输入数据的更高级特征。
3. 输出层(Output Layer):最后一层将隐藏层的输出映射到所需的输出格式,例如分类问题中的不同类别或回归问题中的数值。
深层神经网络的训练通常使用梯度下降优化算法,通过反向传播来计算参数的梯度并更新它们。深层神经网络的一个重要挑战是梯度消失或梯度爆炸问题,这会导致较深层的参数更新变得困难。为了应对这个问题,可以采用一些技巧,如使用适当的激活函数(如ReLU、Leaky ReLU)、批标准化和残差连接等。
深层神经网络在许多领域取得了显著的成功,特别是在计算机视觉、自然语言处理和语音识别等任务中。它们能够从大量的数据中学习复杂的模式,并提供高性能的预测和分类能力。
二、前向传播和反向传播

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
三、深层网络中的维数
深层神经网络中的各个层可以具有不同的维度。下面是一些常见的维度:
1. 输入数据:输入数据的维度取决于具体问题。例如,在图像分类任务中,输入可以是一个三维张量,表示为(宽度,高度,通道数)。在自然语言处理任务中,输入可以是一个二维张量,表示为(序列长度,词嵌入维度)。
2. 权重和偏置:每个网络层都有对应的权重矩阵和偏置向量。其维度由当前层的单元数量和前一层的单元数量决定。
3. 加权输入和激活值:对于隐藏层和输出层,每个单元都会计算加权输入和激活值。加权输入的维度与当前层的单元数量相同,而激活值的维度也与当前层的单元数量相同。
4. 梯度:在反向传播过程中,计算梯度用于更新网络中的权重和偏置。梯度的维度与相应的权重矩阵和偏置向量的维度相同。
四、超参数
超参数(Hyperparameters)是在建立深度学习模型时需要预先设置的参数,它们不是通过训练数据来学习得到的,而是由人工选择或通过试错方法来确定。超参数的选择可以影响模型的性能和训练过程的效果。
以下是一些常见的深度学习中的超参数:
1. 学习率(Learning Rate):学习率决定了每次参数更新的步长大小。较大的学习率可以加快收敛速度,但可能导致不稳定的训练过程;较小的学习率通常更稳定,但收敛速度较慢。
2. 批量大小(Batch Size):批量大小指的是每次迭代训练时使用的样本数量。较大的批量大小可以提高训练速度,但可能占用更多的内存;较小的批量大小可以使模型更好地适应数据,但训练过程可能更慢。
3. 迭代次数(Epochs):迭代次数表示整个训练集被遍历的次数。增加迭代次数可以提高模型的性能,但如果设置得太大,可能会导致过拟合。
4. 网络结构相关的超参数:例如,隐藏层数量、每个隐藏层的单元数量、激活函数的选择等。这些超参数直接影响着模型的容量和表示能力。
5. 正则化参数(Regularization):用于控制模型的复杂度,避免过拟合。常见的正则化方法包括L1正则化和L2正则化,它们的超参数分别是正则化强度和正则化系数。
6. 优化器相关的超参数:例如,动量(Momentum)、权重衰减(Weight Decay)和自适应学习率算法(如Adam、RMSprop)。这些超参数影响着参数更新的方式和速度。
7. 初始化参数(Initialization):神经网络的初始权重和偏置设置也是超参数。合适的初始化可以有助于模型更快地收敛。
8. Dropout参数:Dropout是一种正则化技术,用于随机丢弃一部分神经元。Dropout的超参数是丢弃比例,即丢弃的神经元占总数的比例。
选择合适的超参数对于深度学习模型的性能至关重要。通常,人们可以通过一系列实验和交叉验证来确定最佳的超参数组合。此外,还有一些自动调参的方法,如网格搜索、随机搜索和贝叶斯优化,可以帮助寻找最优的超参数组合。