Flink intervalJoin 使用和原理分析
1.前言
Flink中基于DataStream的join,只能实现在同一个窗口的两个数据流进行join,但是在实际中常常会存在数据乱序或者延时的情况,导致两个流的数据进度不一致,就会出现数据跨窗口的情况,那么数据就无法在同一个窗口内join。
Flink基于KeyedStream提供的interval join机制,intervaljoin 连接两个keyedStream, 按照相同的key在一个相对数据时间的时间段内进行连接。
2.代码示例
将订单流与订单品流通过订单id进行关联,获得订单流中的会员id。
其中ds1就是订单品流,ds2就是订单流,分别对ds1和ds2通过订单id进行keyBy操作,得到两个KeyedStream,再进行intervalJoin操作;
between方法传递的两个参数lowerBound和upperBound,用来控制右边的流可以与哪个时间范围内的左边的流进行关联,即:
leftElement.timestamp + lowerBound <= rightElement.timestamp <= leftElement.timestamp + upperBound
相当于左边的流可以晚到lowerBound(lowerBound为负的话)时间,也可以早到upperBound(upperBound为正的话)时间。
DataStream ds = ds1.keyBy(jo -> jo.getString("fk_tgou_order_id"))
.intervalJoin(ds2.keyBy(jo -> jo.getString("id")))
.between(Time.milliseconds(-5), Time.milliseconds(5))
.process(new ProcessJoinFunction() {
@Override
public void processElement(JSONObject joItem, JSONObject joOrder, Context context, Collector collector) throws Exception {
String order_id = joItem.getString("fk_tgou_order_id");
String item_id = joItem.getString("activity_to_product_id");
String create_time = df.format(joItem.getLong("create_time"));
String member_id = joOrder.getString("fk_member_id");
Double price = joItem.getDouble("price");
Integer quantity = joItem.getInteger("quantity");
collector.collect(new OrderItemBean(order_id, item_id, create_time, member_id, price, quantity));
}
});
ds.map(JSON::toJSONString).addSink(new FlinkKafkaProducer010("berkeley-order-item", schema, produceConfig)); 3.Interval Join源码
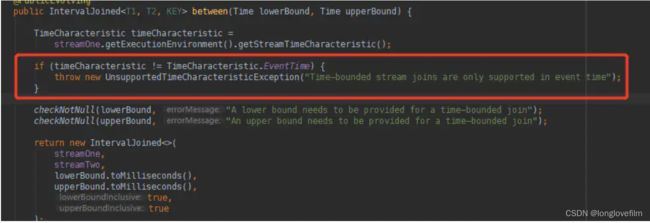
<1> 使用Interval Join时,必须要指定的时间类型为EventTime
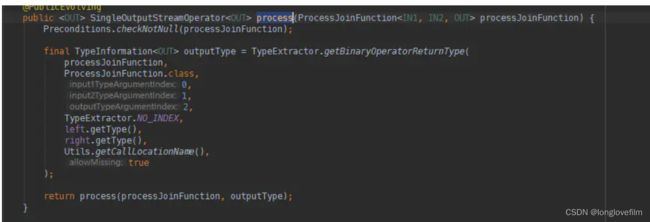
<2>两个KeyedStream在进行intervalJoin并调用between方法后,跟着使用process方法;
process方法传递一个自定义的 ProcessJoinFunction 作为参数,ProcessJoinFunction的三个参数就是左边流的元素类型,右边流的元素类型,输出流的元素类型。
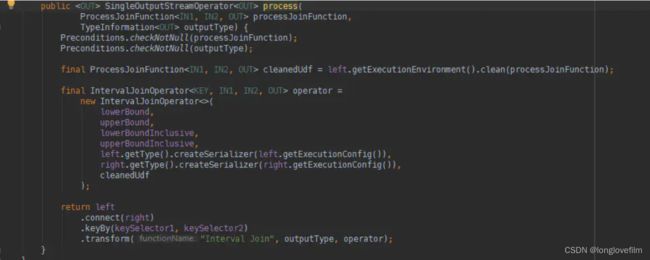
<3>intervalJoin,底层是将两个KeyedStream进行connect操作,得到ConnectedStreams,这样的两个数据流之间就可以实现状态共享,对于intervalJoin来说就是两个流相同key的数据可以相互访问。
ConnectedStreams的keyby????
<4> 在ConnectedStreams之上执行的操作就是IntervalJoinOperator
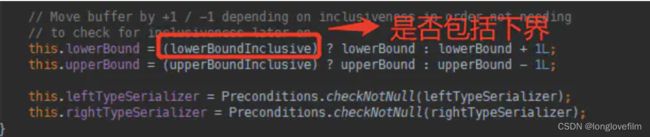
这里有两个参数控制是否包括上下界,默认都是包括的。
a.initializeState()方法
这里面初始化了两个状态对象,

分别用来存储两个流的数据,其中Long对应数据的时间戳,List
b.processElement1和processElement2方法
方法描述的是,当两个流达到之后,比如左边的流有数据到达之后,就去右边的流去查找对应上下界范围内的数据。这两个方法调用的都是processElement方法。
private void processElement(
final StreamRecord record,
final MapState>> ourBuffer,
final MapState>> otherBuffer,
final long relativeLowerBound,
final long relativeUpperBound,
final boolean isLeft) throws Exception {
final THIS ourValue = record.getValue();
final long ourTimestamp = record.getTimestamp();
if (ourTimestamp == Long.MIN_VALUE) {
throw new FlinkException("Long.MIN_VALUE timestamp: Elements used in " +
"interval stream joins need to have timestamps meaningful timestamps.");
}
if (isLate(ourTimestamp)) {
return;
}
addToBuffer(ourBuffer, ourValue, ourTimestamp);
for (Map.Entry>> bucket: otherBuffer.entries()) {
final long timestamp = bucket.getKey();
if (timestamp < ourTimestamp + relativeLowerBound ||
timestamp > ourTimestamp + relativeUpperBound) {
continue;
}
for (BufferEntry entry: bucket.getValue()) {
if (isLeft) {
collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);
} else {
collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);
}
}
}
long cleanupTime = (relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;
if (isLeft) {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);
} else {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);
}
} (1)获取记录的值和时间戳,判断是否延时,当到达的记录的时间戳小于水位线时,说明该数据延时,不去处理,不去关联另一条流的数据。
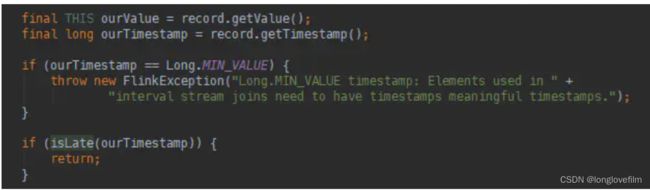
private boolean isLate(long timestamp) {
long currentWatermark = internalTimerService.currentWatermark();
return currentWatermark != Long.MIN_VALUE && timestamp < currentWatermark;
}(2)将数据添加到对应自己流的MapState缓存状态中,key为数据的时间。addToBuffer(ourBuffer, ourValue, ourTimestamp);
private static void addToBuffer(
final MapState>> buffer,
final T value,
final long timestamp) throws Exception {
List> elemsInBucket = buffer.get(timestamp);
if (elemsInBucket == null) {
elemsInBucket = new ArrayList<>();
}
elemsInBucket.add(new BufferEntry<>(value, false));
buffer.put(timestamp, elemsInBucket);
} (3)去遍历另一条流的MapState,如果ourTimestamp + relativeLowerBound <=timestamp<= ourTimestamp + relativeUpperBound ,则将数据输出给ProcessJoinFunction调用,ourTimestamp表示流入的数据时间,timestamp表示对应join的数据时间
for (Map.Entry>> bucket: otherBuffer.entries()) {
final long timestamp = bucket.getKey();
if (timestamp < ourTimestamp + relativeLowerBound ||
timestamp > ourTimestamp + relativeUpperBound) {
continue;
}
for (BufferEntry entry: bucket.getValue()) {
if (isLeft) {
collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);
} else {
collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);
}
}
}
对应的collect方法:
private void collect(T1 left, T2 right, long leftTimestamp, long rightTimestamp) throws Exception {
final long resultTimestamp = Math.max(leftTimestamp, rightTimestamp);
collector.setAbsoluteTimestamp(resultTimestamp);
context.updateTimestamps(leftTimestamp, rightTimestamp, resultTimestamp);
userFunction.processElement(left, right, context, collector);
}设置结果的Timestamp为两边流中最大的,之后执行processElement方法

 (4)注册定时清理时间
(4)注册定时清理时间
long cleanupTime = (relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;
if (isLeft) {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);
} else {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);
}定时的清理时间,就是当下流入的数据的时间+relativeUpperBound,当watermark大于该时间就需要清理。
public void onEventTime(InternalTimer timer) throws Exception {
long timerTimestamp = timer.getTimestamp();
String namespace = timer.getNamespace();
logger.trace("onEventTime @ {}", timerTimestamp);
switch (namespace) {
case CLEANUP_NAMESPACE_LEFT: {
long timestamp = (upperBound <= 0L) ? timerTimestamp : timerTimestamp - upperBound;
logger.trace("Removing from left buffer @ {}", timestamp);
leftBuffer.remove(timestamp);
break;
}
case CLEANUP_NAMESPACE_RIGHT: {
long timestamp = (lowerBound <= 0L) ? timerTimestamp + lowerBound : timerTimestamp;
logger.trace("Removing from right buffer @ {}", timestamp);
rightBuffer.remove(timestamp);
break;
}
default:
throw new RuntimeException("Invalid namespace " + namespace);
}
} 清理时间逻辑:
假设目前流到达的数据的时间戳为10s,between传进去的时间分别为1s,5s,
upperBound为5s,lowerBound为1s
根据 左边流时间戳+1s<=右边时间戳<=左边流时间戳+5s ;右边时间戳-5s<=左边流时间戳<=右边时间戳-1s
a。如果为左边流数据到达,调用processElement1方法
此时relativeUpperBound为5,relativeLowerBound为1,relativeUpperBound>0,所以定时清理时间为10+5即15s
当时间达到15s时,清除左边流数据,即看右边流在15s时,需要查找的左边流时间范围
10s<=左边流时间戳<=14s,所以watermark>15s时可清除10s的数据。

b。如果为右边流数据到达,调用processElement2方法
此时relativeUpperBound为-1,relativeLowerBound为-5,relativeUpperBound<0,所以定时清理时间为10s
当时间达到10s时,清除右边流数据,即看左边流在10s时,需要查找的右边流时间范围
11s<=右边流时间戳<=15s,所以可以清除10s的数据。
