最全Kettle详解
文章目录
-
-
- 第一章 Kettle概述
-
- 1.1 Kettle发展历程
- 1.2 Kettle简介
- 1.3 Kettle相关俗语
- 1.4 Kettle设计与组成
- 1.5 Kettle功能模块
- 1.6 Kettle的执行
- Transformation(转换)
- 1.7 Kettle商业和社区版区别
- 1.8 数据集成与ETL
- 1.9 ETL工具比较
-
第一章 Kettle概述
1.1 Kettle发展历程
Kettle 是 PDI 以前的名称,PDI 的全称是Pentaho Data Integeration-Pentaho数据集成,Kettle 本意是水壶的意思,表达了数据流的含义。
在 2003 年,Kettle 的主作者 Matt就开始了这个项目,在 PDI 的代码里就可以看到最早的日期大概在2003年4月。 从版本2.2开始, Kettle 项目进入了开源领域,并遵守 LGPL 协议。
在 2006年 ,Pentaho公司收购了Kettle项目,原Kettle项目发起人Matt Casters加入了Pentaho团队,成为Pentaho套件数据集成架构师。从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle 正式被命名为PDI,加入Pentaho 后Kettle 的发展越来越快了,并有越来越多的人开始关注它了。
在2015年,Pentaho公司被Hitachi Data Systems收购。
在2017年,Hitachi Data Systems更名为Hitachi Vantara,官网地址为:https://www.hitachivantara.com
历史主要版本记录如下:
| 时间 | 主版本号 | 主要变化 |
|---|---|---|
| 2006年4月 | Ketlle 2.2 | Kettle从该版本开始开源 |
| 2006年6月 | PDI 2.3 | Kettle被Pentaho收购后第一个版本 |
| 2007年11月 | PDI 3.0 | 产品整体重新设计,性能提升 |
| 2009年4月 | PDI 3.2 | 加入新功能、可视化与性能优化 |
| 2010年6月 | PDI 4.0 | 加入企业级功能,例如:版本管理 |
| 2013年11月 | PDI 5.0 | 优化大数据支持、转换步骤负载均衡、作业事务性支持、作业断点重启 |
| 2015年12月 | PDI 6.0 | Pentaho Data Service,元数据注入(Metadata Injection),数据血缘追踪 |
| 2016年11月 | PDI 7.0 | 数据管道可视化、Hadoop安全性支持、Spark支持优化、资源库功能完善、元数据注入功能优化 |
| 2017年4月 | PDI 7.1 | 任务下压至Spark集群运行(Adaptive Execution Layer) |
| 2017年11月 | PDI 8.0 | 实时数据对接、AEL优化、大数据格式支持优化 |
| 2018年6月 | PDI 8.3 | 数据源支持优化:Snowflake, RedShift, Kinesis, HCP等 |
| 2020年1月 | PDI 9.0 | 多Hadoop集群支持、大型机(Mainframe)数据对接支持、S3支持优化 |
| 2020年10月 | PDI 9.1 | Google Dataproc支持、数据目录Lumada Data Catalog对接 |
| 2022年5月 | PDI 9.3 | 支持多种云 |
1.2 Kettle简介
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,其中transformation完成针对数据的基础转换,job则完成整个工作流的控制。
1.3 Kettle相关俗语
Job:一个作业,由不同逻辑功能的entry组件构成,数据从一个entry组件传递到另一个entry组件,并在entry组件中进行相应的处理。Transformation:完成针对数据的基础转换,即一个数据转换过程。Entry:实体,即job型组件。用来完成特定功能应用,是job的组成单元、执行单元。Step:步骤,是Transformation的功能单元,用来完成整个转换过程的一个特定步骤。Hop:工作流或转换过程的流向指示,从一个组件指向另一个组件,在kettle源工程中有三种hop,无条件流向、判断为真时流向、判断为假时流向。数据类型:一行数据是零到多个类型的数据组成,具体Ketlle支持的数据类型如下:
①String字符型
②Number双精度浮点数
③Integer带符号整型64
④BigNumber任意精度数据
⑤Date带毫秒精度的日期时间值
⑥Boolean布尔值true false
⑦Binary二进制数据
1.4 Kettle设计与组成
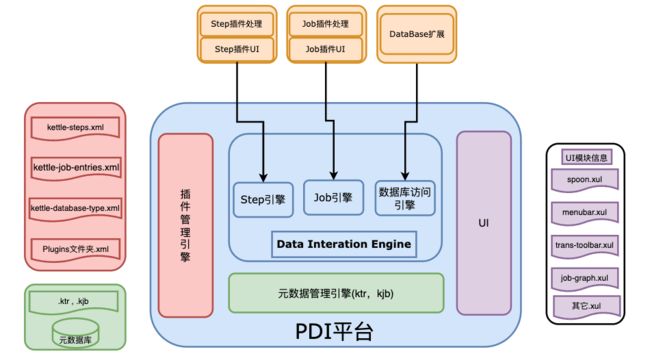
PDI平台是整个Kettle系统的核心,包括插件管理引擎、元数据管理引擎、数据集成引擎和UI模块。
-
插件管理引擎
Kettle是众多“可供插入的地方”(扩展点)和“可以插入的东西”(扩展)共同组成的集合体。在我们的生活中,电源接线板就是一种“扩展点”,很多“扩展”(也就是电线插头)可以插在它上面。
插件管理引擎主要负责插件的注册,在Kettle中不管是以后的扩展还是系统集成的功能,本质上来讲都是插件,管理方式和运行机制是一致的。系统集成的功能点也均实现了对应的扩展接口,只是在插接的说明上略有不同。
Kettle的扩展点包括step插件、job entry插件、Database插件、Partioner插件和debugging插件等。 -
元数据管理引擎
元数据管理引擎管理ktr、kjb或者元数据库,插件通过该引擎获取基本信息,主要包括TransMeta、JobMeta和StepMeta三个类。
- TransMeta类,定义了一个转换(对应一个.ktr文件),提供了保存和加载该文件的方法;
- JobMeta类,同样对应于一个工作(对应一个.kjb文件),提供保存和加载方法;
- StepMeta类,保存的是Step的一些公共信息的类,每个类的具体的元数据将保存在显示了StepMetaInterface的类里面。
-
数据集成引擎
数据集成引擎包括Step引擎、Job引擎和数据库访问引擎三大部分,主要负责调用插件,并返回相应信息。
-
UI模块
UI显示Spoon这个核心组件的界面,通过xul实现菜单栏、工具栏的定制化,显示插件界面接口元素,其中的TransGraph类和JobGraph类是用于显示转换和Job的类。
1.5 Kettle功能模块
Kettle的功能模块很多,其核心主要有:Pan、Spoon、Kitchen和Chef等。

-
Spoon—转换过程设计器
GUI工作,用来设计数据转换过程,创建的转换可以由Pan来执行,也可以被Chef所包含,作为作业中的一个作业项。
- Input-Steps:输入步骤
- Text file input:文本文件输入
可以支持多文件合并,有不少参数,基本一看参数名就能明白其意图。 - Table input:数据表输入
实际上是视图方式输入,因为输入的是sql语句。当然,需要指定数据源(数据源的定制方式在后面讲一下) - Get system info:取系统信息
就是取一些固定的系统环境值,如本月最后一天的时间,本机的IP地址之类。 - Generate Rows:生成多行。
这个需要匹配使用,主要用于生成多行的数据输入,比如配合Add sequence可以生成一个指定序号的数据列。 - XBase Input
- Excel Input
- XML Input
- Text file input:文本文件输入
- Output-Steps: 输出步聚
- Text file output:文本文件输出。这个用来作测试蛮好,呵呵。很方便的看到转换的输出。
- Table output:输出到目的表。
- Insert/Update:目的表和输入数据行进行比较,然后有选择的执行增加,更新操作。
- Update:同上,只是不支持增加操作。
- XML Output:XML输出。
- Look-up:查找操作
- Data Base
- Stream
- Procedure
- Database join
- Transform 转换
- Select values
对输入的行记录数据的字段进行更改 (更改数据类型,更改字段名或删除) 数据类型变更时,数据的转换有固定规则,可简单定制参数。可用来进行数据表的改装。 - Filter rows
对输入的行记录进行指定复杂条件的过滤。用途可扩充sql语句现有的过滤功能。但现有提供逻辑功能超出标准sql的不多。
- Select values
- Sort rows
对指定的列以升序或降序排序,当排序的行数超过5000时需要临时表。 - Add sequence
为数据流增加一个序列,这个配合其它Step(Generate rows, rows join),可以生成序列表,如日期维度表(年、月、日)。 - Dummy
不做任何处理,主要用来作为分支节点。 - Join Rows
对所有输入流做笛卡儿乘积。 - Aggregate
聚合,分组处理 - Group by
分组,用途可扩充sql语句现有的分组,聚合函数。但我想可能会有其它方式的sql语句能实现。 - Java Script value
使用mozilla的rhino作为脚本语言,并提供了很多函数,用户可以在脚本中使用这些函数。 - Row Normaliser
该步骤可以从透视表中还原数据到事实表,通过指定维度字段及其分类值,度量字段,最终还原出事实表数据。 - Unique rows
去掉输入流中的重复行,在使用该节点前要先排序,否则只能删除连续的重复行。 - Calculator
提供了一组函数对列值进行运算,用该方式比用户自定义JAVA SCRIPT脚本速度更快。 - Merge Rows
用于比较两组输入数据,一般用于更新后的数据重新导入到数据仓库中。 - Add constants:
增加常量值。 - Row denormaliser
同Normaliser过程相反。 - Row flattener
表扁平化处理,指定需处理的字段和扃平化后的新字段,将其它字段做为组合Key进行扃平化处理。
除了上述基本节点类型外还定义了扩展节点类型 - SPLIT FIELDS:按指定分隔符拆分字段;
- EXECUTE SQL SCRIPT:执行SQL语句;
- CUBE INPUT:CUBE输入;
- CUBE OUTPUT:CUBE输出。
- Input-Steps:输入步骤
-
Pan—转换的执行工具
命令行执行方式,可以执行由Spoon生成的转换任务,不支持调度。
-
Chef—工作(job)设计器
这是一个GUI工具,操作方式主要通过拖拽。
何谓工作?多个作业项,按特定的工作流串联起来,形成一项工作。正如:我的工作是软件开发。我的作业项是:设计、编码、测试!先设计,如果成功,则编码,否则继续设计,编码完成则开始设计,周而复始,作业完成。-
Chef中的作业项
- 转换:指定更细的转换任务,通过Spoon生成,通过Field来输入参数;
- SQL:sql语句执行;
- FTP:下载ftp文件;
- 邮件:发送邮件;
- 检查表是否存在;
- 检查文件是否存在;
- 执行shell脚本:如dos命令。
- 批处理:(注意:windows批处理不能有输出到控制台)。
- Job包:作为嵌套作业使用。
- JavaScript执行:如果有自已的Script引擎,可以很方便的替换成自定义Script,来扩充其功能;
- SFTP:安全的Ftp协议传输;
- HTTP方式的上传/下载。
-
工作流
工作流是作业项的连接方式,分为三种:无条件,成功,失败。
为了方便工作流使用,KETTLE提供了几个辅助结点单元(也可将其作为简单的作业项):
- Start单元:任务必须由此开始。设计作业时,以此为起点。
- OK单元:可以编制做为中间任务单元,且进行脚本编制,用来控制流程。
- ERROR单元:用途同上。
- DUMMY单元:什么都不做,主要是用来支持多分支的情况。
-
存储方式
支持XML存储,或存储到指定数据库中。
一些默认的配置(如数据库存储位置……),在系统的用户目录下,单独建立了一个.Kettle目录,用来保存用户的这些设置。 -
LogView
可查看执行日志。
-
-
Kitchen—作业执行器
是一个作业执行引擎,用来执行作业。这是一个命令行执行工具,参数如下:
-
rep : Repository name 任务包所在存储名
-
user : Repository username 执行人
-
pass : Repository password 执行人密码
-
job : The name of the job to launch 任务包名称
-
dir : The directory (don’t forget the leading / or /)
-
file : The filename (Job XML) to launch
-
level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 指定日志级别
-
log : The logging file to write to 指定日志文件
-
listdir : List the directories in the repository 列出指定存储中的目录结构。
-
listjobs : List the jobs in the specified directory 列出指定目录下的所有任务
-
listrep : List the defined repositories 列出所有的存储
-
norep : Don’t log into the repository 不写日志
-
-
其它
Connection:可以配置多个数据源,在Job或是Trans中使用,这意味着可以实现跨数据库的任务。支持大多数市面上流行的数据库。
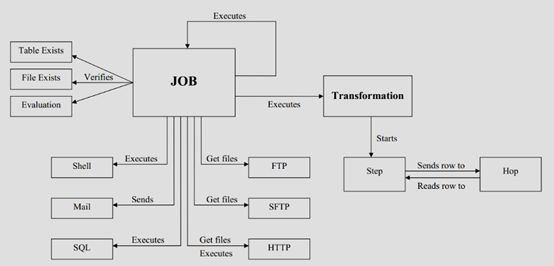
1.6 Kettle的执行
Kettle的执行分为两个层次:Transformation和Job。两个层次的最主要区别在于数据传递和运行方式。
-
Transformation(转换)
Transformation(转换)是由一系列被称之为step(步骤)的逻辑工作的网络。转换本质上是数据流。
下图是一个转换的例子,这个转换从数据输入中读取数据,然后数据过滤,然后数据排序和脏数据记录,最后将数据加载到数据库。本质上,转换是一组图形化的数据转换配置的逻辑结构。

上图中,蓝色的地方就是Setp(步骤),橙色箭头就是Hop。它们也是转换的两个相关的主要组成部分:
step(步骤)和hops(节点连接)。-
转换特征
- 转换文件的扩展名是.ktr。
- 每个转换步骤都是ETL数据流里面的一个任务。
- 转换步骤包括输入、处理和输出。
- 输入步骤从外部数据源获取数据,例如文件或者数据库;
- 处理步骤处理数据流,字段计算,流处理等,例如整合或者过滤。
- 输出步骤将数据写回到存储系统里面,例如文件或者数据库。
-
Steps(步骤)
Steps(步骤)是转换的建筑模块,比如一个文本文件输入或者一个表输出就是一个步骤。每个步骤用于完成某种特定的功能,通过配置一系列的步骤就可以完成你所需要完成的任务。 -
Hops(节点连接)
Hops(节点连接)是数据的通道,用于连接两个步骤,使得元数据从一个步骤传递到另一个步骤。节点连接决定了贯穿在步骤之间的数据流,步骤之间的顺序不是转换执行的顺序。当执行一个转换时,每个步骤都以自己的线程启动,并不断的接受和推送数据。
注意
- 所有的步骤是同步开启和运行的,所以步骤的初始化的顺序是不可知的。因为我们不能在第一个步骤中设置一个变量,然后在接下来的步骤中使用它。
- 在一个转换中,一个步骤可以有多个连接,数据流可以从一个步骤流到多个步骤。在Spoon中,hops就想是箭,它不仅允许数据从一个步骤流向另一个步骤,也决定了数据流的方向和所经步骤。如果一个步骤的数据输出到了多个步骤,那么数据既可以是复制的,也可以是分发的。
-
-
Jobs(工作)
Jobs(工作)是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动流程。作业包括一个或多个作业项,作业项以某种顺序来执行。
Jobs(工作)将功能性和实体过程聚合在了一起,由工作节点连接、工作实体和工作设置组成,工作文件的扩展名是.kjb。
下图是一个工作的例子。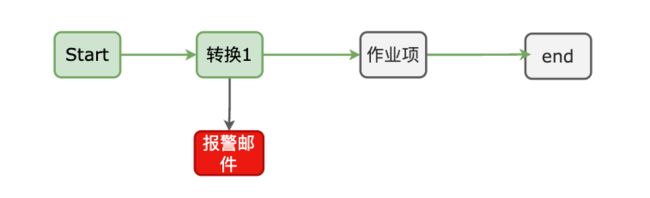
-
作业项。作业项是作业的基本构成部分。如同转换的步骤,作业项也可以使用图标的方式图形化展示。作业项的注意点。新步骤的名字应该是唯一的,但是作业项可以有影子拷贝。这样可以把一个作业项放在不同的位置。这些影子拷贝里的信息都是相同的,编辑一份拷贝,其他拷贝也会随之修改。在作业项之间可以传递一个结果对象(result object)。这个结果对象里包含了数据行,它们不是以流的方式来传递的。而是等一个作业项执行完了,再传递给下一个作业项。默认情况下,所有的作业项都是以串行方式执行的,只是在特殊情况下,以并行方式执行。
-
作业跳:作业之间的连线称为作业跳。作业里每个作业项的不同运行结果决定了作业的不同执行路径。对作业项的运行结果判断如下:
-
无条件执行:不论上一个作业项执行成功与否,下一个作业项都会执行。标识为,黑色的连线,上面有一个锁的图标

-
当运行结果为真时执行:标识为,绿色的连线,上面有一个钩号

-
当运行结果为假时执行:标识为,红色的连线,上面有一个红色的停止图标

-
-
1.7 Kettle商业和社区版区别
Pentaho Data Integration分为商业版与开源版。在中国,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。


1.8 数据集成与ETL
数据集成是指将来自不同来源、不同格式和不同结构的数据整合到一个统一的数据存储库中,以实现数据的一致性、可访问性和可用性。它的目标是消除数据孤岛,使企业能够更好地利用数据进行分析、决策和业务创新。
ETL(Extract-Transform-Load的缩写,即**抽取(Extract)、转换(Transform)、装载(Load)**的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少,这里我要学习的ETL工具是Kettle!
ETL是数据集成常用方法之一,当然还有很多集成平台服务方法做数据集成等。
1.9 ETL工具比较
市面上常用的ETL工具有很多,比如Sqoop,DataX, Kettle, Talend 等,作为一个大数据工程师,掌握其中的两三种即可,原理都很相似,其他的学习成本就相对很低。
| 比较项/ETL产品 | DataPipeline | kettle | Oracle Goldengate | informatica | talend | DataX | Sqoop | 备注 |
|---|---|---|---|---|---|---|---|---|
| 使用场景 | 主要用于各类数据融合、数据交换场景,专为超大数据量、高度复杂的数据链路设计的灵活、可扩展的数据交换平台 | 面向数据仓库建模传统ETL工具 | 主要用于数据备份、容灾 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 | 面向数据仓库的ETL建模工具 | Sqoop已停止更新 |
| 使用方式 | 全流程图形化界面,应用端采用B/S架构,Cloud Native为云而生,所有操作在浏览器内就可以完成,不需要额外的开发和生产发布 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境,线上生产环境没有界面,需要通过日志来调试、debug,效率低,费时费力 | 没有图形化的界面,操作皆为命令行方式,可配置能力差 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境;学习成本较高,一般需要受过专业培训的工程师才能使用; | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境; | DataX是以Json格式脚本的方式执行任务的,其中子项目DataX-Web基于浏览器开发、上线、调度和运维。 | Sqoop基于命令行方式执行,本身没有相关BS或CS的架构,需要依赖别的来调度,几乎仅用于数据库。 | |
| 底层架构 | 分布式集群高可用架构,可以水平扩展到多节点支持超大数据量,架构容错性高,可以自动调节任务在节点之间分配,适用于大数据场景 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 | 可做集群部署,规避单点故障,依赖于外部环境,如Oracle RAC等 | schema mapping非自动;可复制性比较差;更新换代不是很强 | 支持分布式部署 | 支持单机部署和集群部署两种方式,底层是多线程 | 支持单机或类集群部署,底层依赖MapReduce执行 | |
| 功能 | CDC机制基于日志、基于时间戳和自增序列等多种方式可选 | 基于时间戳、触发器等 | 主要是基于日志 | 基于日志、基于时间戳和自增序列等多种方式可选 | 基于触发器、基于时间戳和自增序列等多种方式可选 | 离线批处理 | 离线批处理 | |
| 对数据库的影响 | 基于日志的采集方式对数据库无侵入性 | 对数据库表结构有要求,存在一定侵入性 | 源端数据库需要预留额外的缓存空间 | 基于日志的采集方式对数据库无侵入性 | 有侵入性 | 通过sql select 采集数据,对数据源没有侵入性 | 通过sql select 采集数据,对数据源没有侵入性 |