3D目标检测实战 | 图解KITTI数据集与数据格式
目录
- 1 数据集简介
- 2 传感器坐标系
- 3 数据集下载与组织
- 4 数据内容说明
-
- 4.1 矫正文件calib
- 4.2 图像文件image
- 4.3 点云文件velodyne
- 4.4 标签文件label
- 4.5 平面文件plane
1 数据集简介
KITTI数据集是一个广泛应用于自动驾驶和计算机视觉领域的公开数据集。该数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院共同创建,旨在提供丰富的场景和多种类型的传感器数据,包括立体摄像头、激光雷达和GPS/IMU定位。该数据集用于评测
- 立体图像(stereo)
- 光流(optical flow)
- 视觉测距(visual odometry)
- 3D物体检测(object detection)
- 3D跟踪(tracking)
- …
等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据
3D目标检测旨在从传感器数据中准确地定位和识别三维空间中的物体。KITTI数据集针对3D目标检测任务提供了14999张图像以及对应的点云,其中7481组用于训练,7518组用于测试,针对场景中的汽车、行人、自行车三类物体进行标注,共计80256个标记对象。
KITTI数据集的广泛使用推动了3D目标检测算法的发展,为自动驾驶技术的进步做出了重要贡献。同时,这个数据集也成为了研究人员之间共享和比较算法性能的标准基准,促进了该领域的研究和创新。
2 传感器坐标系
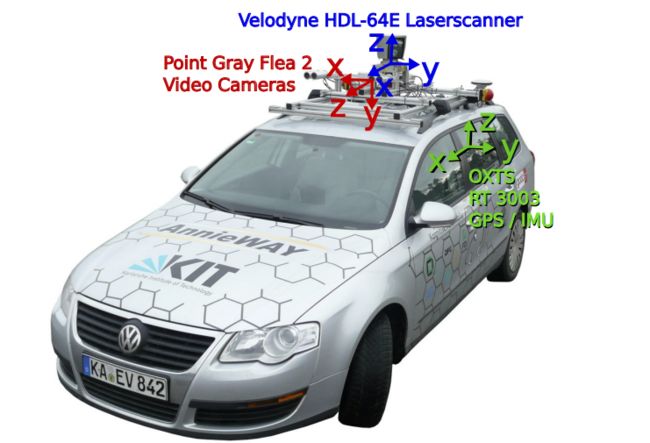
KITTI数据集使用的数据采集车如下所示,该图展示了传感器、传感器之间的变换,以及车体在地面上方的高度

其中的传感器配置为
- 2个一百四十万像素的PointGray Flea2灰度相机
- 2个一百四十万像素的PointGray Flea2彩色相机
- 1个64线的Velodyne激光雷达,10Hz,角分辨率为0.09度,每秒约一百三十万个点,水平视场360°,垂直视场26.8°,至多120米的距离范围
- 4个Edmund的光学镜片,水平视角约为90°,垂直视角约为35°
- 1个OXTS RT 3003的惯性导航系统(GPS/IMU),6轴,100Hz,分别率为0.02米,0.1°
主要传感器的坐标系定义如下所示,后续进行数据可视化时,需要根据车体信息和坐标系定义进行数据转换
3 数据集下载与组织
主要下载资源如下
- KITTI官网:3D目标检测
- AVOD:道路平面信息

下载完成主要的数据集后,可以按训练集和测试集组织为如下格式
.data
└── kitti
├── test
│ ├── calib
│ ├── image_2
│ └── velodyne
└── train
├── calib
├── image_2
├── label_2
├── planes
└── velodyne
4 数据内容说明
4.1 矫正文件calib
calib是相机、雷达、惯导等传感器的矫正数据或变换关系,以train/calib/000000.txt文件为例
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
其中数据的含义是:
- P 0 P_0 P0- P 4 P_4 P4:相机内参矩阵 R 3 × 4 \mathbb{R} ^{3\times 4} R3×4
P i = [ f u i 0 c u i − f u i b i 0 f v i c v i 0 0 0 1 0 ] P_i=\left[ \begin{matrix} f_{u}^{i}& 0& c_{u}^{i}& -f_{u}^{i}b_i\\ 0& f_{v}^{i}& c_{v}^{i}& 0\\ 0& 0& 1& 0\\ \end{matrix} \right] Pi= fui000fvi0cuicvi1−fuibi00
其中参数 c u c_u cu、 c v c_v cv用于中心映射——将光轴与归一化成像面的交点,即成像面中心点映射到像素平面中心,其取决于拜耳阵列与光轴如何对齐。参数 f u f_u fu、 f v f_v fv用于归一化——将矩形的传感器阵列映射为正方形, b i b_i bi是第 i i i个相机沿 x x x方向距离0号相机的位移。序号含义如下
| 序号 | 相机 |
|---|---|
| 0 | 左边灰度相机 |
| 1 | 右边灰度相机 |
| 2 | 左边彩色相机 |
| 3 | 右边彩色相机 |
- R 0 r e c t R^{rect}_0 R0rect:立体矫正矩阵 R 3 × 3 \mathbb{R} ^{3\times 3} R3×3,在实际计算时在第四行和第四列添加全为0的向量,扩展为4x4的矩阵。 R 0 r e c t R^{rect}_0 R0rect用于立体视觉中使相机图像共面,详见计算机视觉教程6-1:图解双目视觉系统与立体校正原理
- T r v e l o _ t o _ c a m Tr_{\mathrm{velo\_to\_cam}} Trvelo_to_cam:从雷达到0号相机的旋转平移矩阵 R 3 × 4 \mathbb{R} ^{3\times 4} R3×4,在实际计算时,需要添加一行 [ 0 , 0 , 0 , 1 ] [0,0,0,1] [0,0,0,1]齐次化为 R 4 × 4 \mathbb{R} ^{4\times 4} R4×4的矩阵
- T r i m u _ t o _ v e l o Tr_{\mathrm{imu\_to\_velo}} Trimu_to_velo:从惯导或GPS装置到0号相机的旋转平移矩阵 R 3 × 4 \mathbb{R} ^{3\times 4} R3×4,在实际计算时,需要添加一行 [ 0 , 0 , 0 , 1 ] [0,0,0,1] [0,0,0,1]齐次化为 R 4 × 4 \mathbb{R} ^{4\times 4} R4×4的矩阵
利用上述矩阵可以将不同坐标系的数据相互转换,例如将雷达坐标系的点 x x x映射到左侧彩色相机可以使用
y = P 2 ⋅ R 0 r e c t ⋅ T r v e l o _ t o _ c a m ⋅ x y=P_2\cdot R^{rect}_0 \cdot Tr_{\mathrm{velo\_to\_cam}} \cdot x y=P2⋅R0rect⋅Trvelo_to_cam⋅x
即先将 x x x转换到0号相机,再进行0号相机立体矫正,最后投影到2号相机,即左侧彩色相机
4.2 图像文件image
image是以8位PNG格式存储的图像文件,以train/image_2/000000.png为例

4.3 点云文件velodyne
velodyne是以浮点二进制格式存储的激光雷达点云文件,每行包含8个浮点数数据,其中每个浮点数数据由四位十六进制数表示且通过空格隔开。一个点云数据由4个浮点数数据构成,分别表示点云的 x x x、 y y y、 z z z、 r r r(其中 x x x、 y y y、 z z z表示点云的三维坐标, r r r表示反射强度),以train/velodyne/000000.bin为例
8D97 9241 39B4 483D | 5839 543F 0000 0000
83C0 9241 8716 D93D | 5839 543F 0000 0000
2D32 4D42 AE47 013F | FED4 F83F 0000 0000
3789 9241 D34D 623E | 5839 543F 0000 0000
E5D0 9241 1283 803E | E17A 543F EC51 B83D
...
4.4 标签文件label
label是标签文件,以train/label_2/000000.txt为例
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
训练数据共15列,每列的含义如下
- 第1列 字符串:代表物体类别,总共有9类,分别是
Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc和DontCare。其中DontCare表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算精确度precision),将本来是目标物体但因某些原因而没有标注的区域统计为假阳性,评估脚本会自动忽略DontCare区域的预测结果 - 第2列 浮点数:代表物体是否被截断(truncated),数值在0(非截断)到1(截断)间浮动,数字表示指离开图像边界的程度
- 第3列 整数:代表物体是否被遮挡(occluded),离散值0、1、2、3分别表示被遮挡的程度
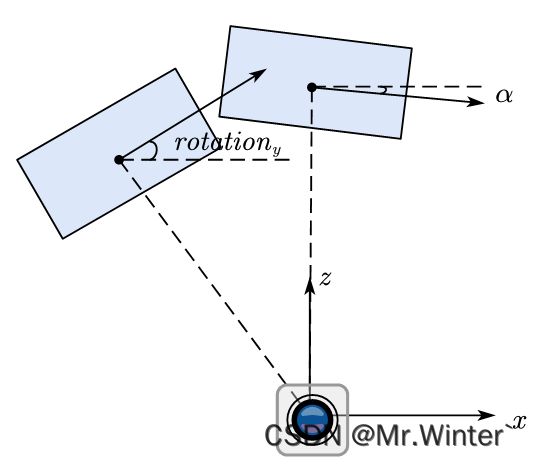
- 第4列 弧度:物体的观察角度(alpha),取值范围为 [ − π , π ] [-\pi, \pi ] [−π,π],它表示在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机 y y y轴旋转至相机 z z z轴,此时物体方向与相机 x x x轴的夹角
- 第5~8列 浮点数:物体的2D边界框大小(bbox),四个数分别是xmin、ymin、xmax、ymax(单位:pixel),表示2D边界框的左上角和右下角的坐标
- 第9~11列 浮点数: 3D物体的尺寸(dimensions),三个数分别是高、宽、长(单位:米)
- 第12-14列 浮点数: 3D物体在相机坐标系下的位置(location),三个数分别是 x x x、 y y y、 z z z(单位:米),特别注意的是,这里的xyz是在相机坐标系下3D物体的中心点位置,这里中心点位于底面中心
- 第15列 弧度:3D物体的方向角(rotation_y),取值范围为 [ − π , π ] [-\pi, \pi ] [−π,π],它表示在相机坐标系下,物体的全局方向角,也就是物体前进方向与相机坐标系x轴的夹角
- 第16列 浮点数:目标检测的置信度(score),只在测试集中有
4.5 平面文件plane
planes是由AVOD生成的道路平面信息,其在训练过程中作为一个可选项,用来提高模型的性能,例如限制物体在道路平面上。以train/planes/000000.txt文件为例
# Matrix
WIDTH 4
HEIGHT 1
-7.051729e-03 -9.997791e-01 -1.980151e-02 1.680367e+00
四个系数代表了平面方程系数 A A A、 B B B、 C C C、 D D D,即
A x + B y + C z + D = 0 Ax+By+Cz+D=0 Ax+By+Cz+D=0
更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《运动规划实战精讲》
- …