多目标跟踪MOT论文阅读记录1
以下内容都是个人理解,有不当的地方烦请批评指正。
后续论文阅读见 多目标跟踪MOT论文阅读记录2
多目标跟踪MOT论文阅读记录2(持续更新中...)_阿珩#的博客-CSDN博客
1 综述
1) 2022年 Multiple Object Tracking in Recent Times: A Literature Review
论文地址:https://arxiv.org/pdf/2209.04796.pdf
2 检测后跟踪 (tracking by detection)
2.1 Separate Detection and Embedding (SDE)
1) 2021年 TPAMI TransCenter: Transformers With Dense Representations for Multiple-Object Tracking
网络结构:

论文地址:TransCenter: Transformers With Dense Representations for Multiple-Object Tracking | IEEE Journals & Magazine | IEEE Xplore
代码地址:https://github.com/yihongXU/TransCenter
创新点:(1)提出了TransCenter,一种基于transformer的,具有密集表示的MOT结构,并分别提出了适用于拥挤环境和高效环境的两种变体(Dual、Lite);(2)证明跟踪查询可以是稀疏的,并带来了效率的提高;检测查询使用多尺度密集表示,改善漏检、误检;(3)QLN转换器(将密集特征M转换为解码器输入)、两个编码器(分别处理TQ和DQ)的设计。
为什么:直接应用具有二次复杂度和噪声初始化稀疏查询不足的Transformer架构对于 MOT 而言并不是最佳选择。
怎么做:由当前帧和上一帧生成图像经由编码器和QLN生成跟踪查询TQ,经过解码器产生跟踪位移T;由当前帧图像经由编码器和QLN生成多尺度密集查询DQ,经过解码器产生中心点C和框S,形成检测集D,再使用匈牙利算法进行轨迹关联。
总结:使用中心热图而非bounding box表示目标,对遮挡效果好;密集的检测查询提高了检测效果;Lite版本FPS达到19.4,实时性不高;主要是针对检测进行的改进。(作者提出的)改进方向:多帧输入以得到长时间关联信息。
2) 2022年 ECCV ByteTrack: Multi-Object Tracking by Associating Every Detection Box
关联过程伪代码:

论文地址:https://arxiv.org/abs/2110.06864
代码地址:GitHub - ifzhang/ByteTrack: [ECCV 2022] ByteTrack: Multi-Object Tracking by Associating Every Detection Box
创新点:提出了一个二次匹配过程,能够与其他检测器、跟踪器结合,大幅度提高检测精度。
为什么:大多数方法通过关联分数高于阈值的检测框来获得身份。检测分数低的对象,例如被遮挡的物体,被简单地扔掉,这带来了不可忽略的真实物体丢失和支离破碎的轨迹。
怎么做:第一次匹配:高置信度检测框和轨迹;第二次匹配:低置信度框和未匹配的轨迹。
总结:使用YOLOX进行检测;FPS达到29.6;主要是针对跟踪(匹配策略)进行的改进。
3) 2022年 BoT-SORT: Robust Associations Multi-Pedestrian Tracking
网络结构:

关联过程伪代码:

论文地址:https://arxiv.org/abs/2206.14651
代码地址:https://github.com/NirAharon/BoT-SORT
创新点:(1)增加相机运动补偿CMC模块;(2)改进卡尔曼状态向量的表示;(3)提出IOU+ReID的更稳定的特征关联
为什么:相机运动,预测边界框的正确位置可能会失败;经实验验证,卡尔曼状态向量直接估计边界框的高和宽更好。
怎么做:(1)CMC:将预测框在k-1下的坐标经过仿射变换矩阵变换到k帧;(2)Kalman: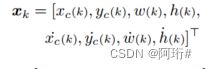 ,其中w、h分别表示预测框的宽和高;(3)IOU+ReID:IOU距离近、IOU距离不远且外观相似(ReID),取两者中代价低的做第一次关联,然后将未匹配的轨迹与低置信度预测框做第二次关联(同bytetrack)。
,其中w、h分别表示预测框的宽和高;(3)IOU+ReID:IOU距离近、IOU距离不远且外观相似(ReID),取两者中代价低的做第一次关联,然后将未匹配的轨迹与低置信度预测框做第二次关联(同bytetrack)。
总结:使用YOLOX进行检测;FPS达到6.6,实时性不高;主要是针对跟踪进行的改进(基于bytetrack)。
4) 2022年 Online relational tracking with camera motion suppression(FOR_Tracking)
网络结构:
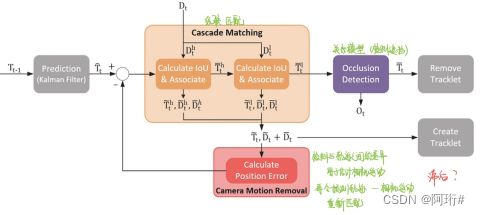
论文地址:Online relational tracking with camera motion suppression - ScienceDirect
代码地址:GitHub - mhnasseri/for_tracking: Fast Online and Relational Tracking
创新点:(1)估计相机运动;(2)给级联匹配设定两个相关度阈值;(3)关系模型用于检测遮挡
为什么:相机运动可能会严重到足以误导跟踪算法并导致某些轨迹完全匹配失败或其他轨迹匹配不正确;使用图神经网络或变压器来提取交互特征会导致高计算成本。
怎么做:(1)将检测与预测之间的差异用于估计相机运动,再令“预测-相机运动”,再重新匹配(这样不会滞后调节吗);(2)第一次高置信度的匹配设置一个接近于0的值(称为匹配相似度),高于该值的进行关联;第二次针对低置信度检测同样设定一个匹配相似度(数值大于上一个),高于该值的进行关联;(3)根据轨迹覆盖率和轨迹置信度检测遮挡,即覆盖率高且置信度高的轨迹,判断其发生了遮挡。
总结:使用YOLOX进行检测;FPS达到60.7(怎么做到的?);主要是针对跟踪进行的改进。
问题:由于检测和预测本身的不确定性,使用两者进行的相机运动估计的不确定性不会更大吗?论文中并没有提到轨迹覆盖率、置信度这些超参数该如何设定?检测遮挡的实际意义在于?(使其轨迹保留时间延长,短时间内不进行删除)
5) 2022年 ECCV MOTR: End-to-End Multiple-Object Tracking with Transformer
网络结构:
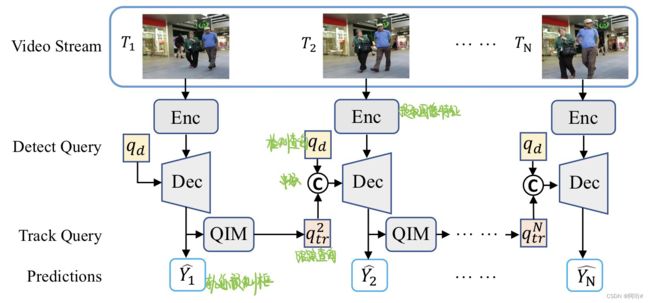
更新检测查询的过程:

QIM结构:

论文地址:[2105.03247] MOTR: End-to-End Multiple-Object Tracking with Transformer (arxiv.org)
代码地址:GitHub - megvii-research/MOTR: [ECCV2022] MOTR: End-to-End Multiple-Object Tracking with TRansformer
创新点:(1)一个端到端的框架,MOTR,以联合方式隐式学习外观和位置差异;(2)为了增强时间建模,提出了QIM模块,包括集体平均损失CAL,时间聚合网络TAN
为什么:关联的后处理性质阻止了视频序列中时间变化的端到端利用。(我的理解是为了更充分利用长时间跨度的上下文信息)
怎么做:(1)检测查询qd仅检测新出现的目标,解码器通过之前的跟踪查询、当前的图像特征、检测查询,生成跟踪预测(及下一帧会用到的跟踪查询);(2)CAL,计算整个序列的损失,而非逐帧计算损失
总结:FPS达到7.5
问题:(文章提出的limitation)(1)检测新目标的效果不好;(2)训练效率不高。
(这个Transformer的结构我没怎么看懂,等需要的时候再重新看看)
6) 2022年 Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
想法说明:
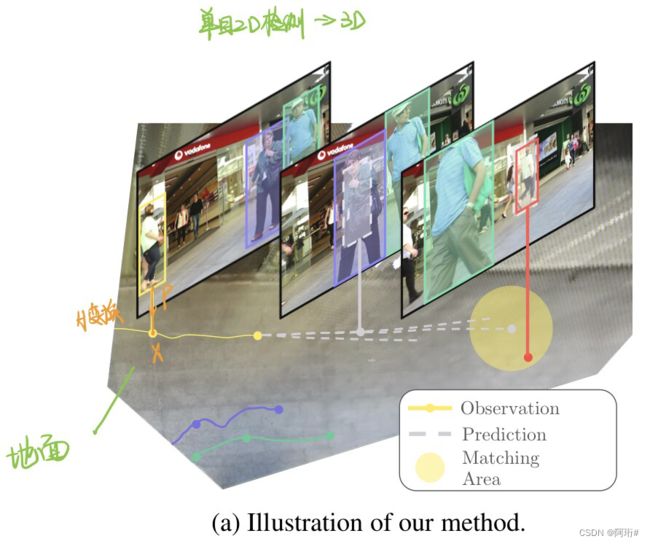
网络流程:
网络结构:

论文地址:[2210.07681] Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking? (arxiv.org)
代码地址:GitHub - dendorferpatrick/QuoVadis: [NeurIPS 2022] Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
创新点:通过估计的单应性变换在 BEV (鸟瞰图)中定位对象轨迹,并考虑不确定性,预测遮挡对象的长期轨迹
为什么:现有方法难以处理长时间(3s以上)遮挡后的轨迹关联问题,遮挡时间延长意味着目标的搜索范围变大,关键在于预测更长的轨迹,缩小搜索空间
怎么做:(1)上图3,估计:使用深度估计器重建3D点云,以估计序列的单应性变换H,使用语义分割模型获得地面图像到点云的对应关系,再对应到BEV中的2D位置。使用变换H,将边界框底边中心点转换为2D的BEV坐标。(2)预测:使用LSTM encoder-decoder的预测模型结构,使用卡尔曼滤波器平滑观测结果以解决定位噪声,线性外推到过去,以获得固定长度的输入轨迹。解码器为多生成器GAN网络,能够从不同生成器中获得多个预测。(3)跟踪:将轨迹分为active和inactive,针对inactive的轨迹,使用预测模型预测BEV中时间长度为τmax的k个轨迹(k对应生成器数量),沿着预测轨迹移动,同时确定可见空间,过滤掉不可能的预测,使用IOU和外观特征匹配预测框和新的检测框,匹配成功则变为active,删除轨迹的情况:a.所有预测都被删除;b.假设目标将在τvis(超参数)帧内可见,超过τvis帧未见的轨迹会被删除。
总结:(文章提出的limitation)(1)效率低;(2)依赖于深度估计器的质量;(3)BEV定位的不确定性。
能够与其他检测器、跟踪器结合;部件很多,实时性估计不高;是针对跟踪进行的改进。
问题:相机平移运动在变换H中如何实现?关联成本c的范围?
7) 2022年 StrongSORT: Make DeepSORT Great Again
与deepsort的对比:

网络结构:

论文地址:[2202.13514] StrongSORT: Make DeepSORT Great Again (arxiv.org)
代码地址:GitHub - dyhBUPT/StrongSORT: StrongSORT: Make DeepSORT Great Again
创新点:(1)给deepsort更换一些新组件,称为strongsort;(2)用于遮挡后重关联的无外观连接模型AFlink;(3)用于轨迹后处理的高斯平滑插值GSI
为什么:DeepSORT 的表现不佳是因为其技术过时,而不是其跟踪范式不好
怎么做:(1)a.检测器由FasterRCNN换为YOLOX;b.ReID特征提取网络由CNN换为BOT;c.deepsort的特征更新是保存最近的k帧,本文换为EMA,以指数移动平均更新外观特征;d.添加相机运动补偿ECC:参数化图像对齐,估计全局平移和旋转,然后利用前向加性迭代算法或逆向合成迭代算法,变为最小化问题;e.将kalman滤波换为NSA Kalman,即自适应计算噪声协方差;f.deepsort在第一次关联仅使用外观特征,本文的代价矩阵为外观和运动代价的权重和;g.作者认为deepsort的级联匹配会限制优秀跟踪器的效果,故换为全局线性匹配;(2)如上图2,仅使用运动信息,通过特征提取和融合将两个轨迹特征拼接,然后使用MLP预测两个轨迹相关联的置信度分数,计算速度快;(3)对于遮挡后重新关联的目标,使用高斯核函数拟合其路线,并在其中添加了一个自适应平滑因子
总结:(文章提到的局限性)1.速度慢,因为deepsort需要额外的检测器和ReID特征提取器;2.AFlink只能处理遮挡后的重新关联,不能针对错误关联进行重新分割关联。
检测器使用YOLOX;AFlink、GSI及其他推理技巧同样适用于其他方法;是针对跟踪进行的改进。
2.2 Joint Detection and Embedding (JDE)
1)2021年 IJCV FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
网络结构:

论文地址:https://arxiv.org/pdf/2004.01888.pdf
代码地址:GitHub - ifzhang/FairMOT: [IJCV-2021] FairMOT: On the Fairness of Detection and Re-Identification in Multi-Object Tracking
创新点:基于CenterNet提出了FairMOT,同时进行检测和ReID特征提取
为什么:分析JDE效果差的原因:(1)anchor-based不适于ReID特征提取;(2)网络不公平对待两个检测和ReID任务
怎么做:使用CenterNet,以实现在ReID中提取目标中心的特征;在ResNet34中应用DLA以聚合多层特征;上采样使用可变形卷积应对目标尺度变化;使用不确定性损失自动平衡多任务学习;使用单图像训练提高性能
总结:FPS达到30;主要是针对检测进行的改进。
2) 2020年 ECCV Towards Real-Time Multi-Object Tracking(JDE)
网络结构:

论文地址:https://arxiv.org/pdf/1909.12605.pdf
代码地址:GitHub - Zhongdao/Towards-Realtime-MOT: Joint Detection and Embedding for fast multi-object tracking
创新点:将检测任务和REID任务融合到一个网络中
为什么:track by detection方法先检测,再数据关联,速度慢
怎么做:(1)基于FPN特征金字塔的结构,在每个尺度连接预测头,每个预测头分别进行分类、框回归、特征嵌入任务;并使用任务无关不确定的损失自动调整损失权重;(2)使用一种综合考虑外观和运动特征的简单关联策略(FairMOT与此相同),和特征更新策略(StrongSORT与此相同)
总结:anchor-based、实际上是主检测副嵌入,因此FairMOT对此提出改进。FPS=22-40
问题:为什么分类的输出维度是2A*H*W?文章提到的矢量化卡尔曼滤波器是什么?
2.3 其他方法
1) 2022年 Decode-MOT: How Can We Hurdle Frames to Go Beyond Tracking-by-Detection?
网络结构:
自监督跟踪上下文学习流程:

论文地址:Decode-MOT: How Can We Hurdle Frames to Go Beyond Tracking-by-Detection? | IEEE Journals & Magazine | IEEE Xplore
代码地址:https://github.com/reussite-cv/Decode-MOT
创新点:在线MOT期间自动选择使用TBD还是TBM(tracking by motion)的决策器Decode-MOT
为什么:TBM速度快,TBD精度高,为了平衡精度,交替使用TBM和TBD
怎么做:1)场景上下文学习的长期注意力:使用长短期注意力的场景上下文学习,以在连续帧之间生成更具辨别力的特征;2)决策器Decode-MOT:使用最近一次TBD帧和当前帧的不相似性及注意力机制,决策出当前帧是使用TBM还是TBD;3)分层置信度关联策略:(在bytetrack的基础上)添加了轨迹置信度的二次关联,一共三层:D(high)+T(high),D(high)+T(high+low),D(high+low)+T(high+low);4)自监督学习:基于跟踪基数和运动上下文相似性(IOU),相似性低,则生成TBD伪标签,相似性高则TBM伪标签。
总结:TBM的方法适合固定相机场景,因此TBM+TBD的也比较适合相机运动不大的场景。可以和知识蒸馏、多孔金字塔池化、多头注意力模块结合。
4 其他
MOT challenge:
MOT Challenge
HiEve数据集:
Human in Events
格式参考:
gsg多目标跟踪MOT技术总结(持续更新) - 小智博客 (imyhq.com)