NLP中embedding
NLP中embedding
https://mp.weixin.qq.com/s/5ttCIFPVA0_7O67DvI6HKA
https://www.zhihu.com/question/510987022
一、获取目标对象表征
如果有人问我,“你认为**预训练模型是干什么的**”,我可能会不加思考地随口说出,“获取编码”,或者“获取目标对象的表征”,因为不管是什么样的任务,都在获取表征的基础上,去设计具体的下游任务。
在token-level embedding的基础上,接一个Dense,可以做序列标注,可以做MLM;接一个pooler,再接一个Dense,可以做sentence-level的任务,可以做sequence classification,亦或是regression,可以做检索、召回;两个sequence拼一起,可以做sequence-pair类的任务,例如一直被吐槽的NSP;接一个decoder,可以做生成类任务。
当然上面所举的这些例子中,相互之间存在内容上的交叉,但不管是怎样的任务范式,似乎都绕不开一个话题——我们总是需要**获取对目标对象的表征**。
再把时间放的久一点,回顾技术的发展,似乎可以发现,整个机器学习的发展,好像一直都在围绕着“表征”进行的。
早在预训练模型兴起之前,甚至是深度学习兴起之前,TF-IDF其实是在获取“表征”,BM25是在获取“表征”,fasttext,word2vec,glove等一众方法亦是如此;再把目光跳出NLP领域,CNN对图像的编码,GCN对图的编码,也都是在做同样的事情,甚至是数据建模中,人工特征工程的构建,也是为了寻求一众更合理的特征表示方法。这并不是一个发现,而是天然的,应该出现的。
正是由于这种固有的特性,好多人,包括我自己在内,在提到BERT之类的模型时,总是给它加上一个后缀“编码器”,因为心里已经习惯了这样的思想,BERT在整个模型中,是用来做编码的。这种称呼很直观,这没什么问题。
可是,为什么,【为什么经过BERT编码之后的结果,可以用来代表这句话的特征,以及这个表征,表征了什么东西】。
二、备受嫌弃的NSP,为什么效果不佳★★★★★
在我印象里,好像自从NSP被设计出以来,它都都备受嫌弃。作为一项预训练任务,NSP无疑是失败的,并且从名字开始就是失败的。
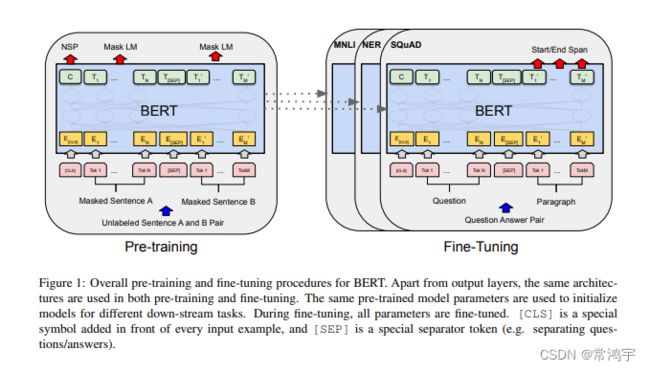
Next sentence prediction,它并不是一个生成式任务(实现输入一句话,预测它下一句话的内容),结果是判断两句话的关系。
从效果来看,它也是失败的,以至于后来的预训练模型纷纷对这项任务进行修改,或者是干脆舍弃了这项任务。甚至某乎上出现了这样的问题:
为什么用bert计算出的CLS,用来计算文本相似度的效果很差?★★
【为什么用bert计算出的CLS,用来计算文本相似度的效果很差?】 其中,苏神的回答很有趣,大概意思是说,你为什么会对它抱有期待呢?
其实是我们没有深入的考虑文本表征的问题,习惯性地觉得,只要是得到了编码,就可以利用编码来计算相似度了,这个问题我也遇到过,例如在NER任务中,拿到两个实体的编码,就利用这两个实体的编码来计算两个实体的相似度。
稍微想想不难理解,CLS的编码,是通过NSP预训练得到的,并没有对它进行fine-tune。【那为什么觉得它可以很好地适配另一个任务呢?】讲道理,文本相似度计算应该是一个回归任务,至少应该是文本蕴含任务,NSP作为一个简单的二分类任务,怎么能指望它产生的结果能够适配到相似性计算呢?更不用说,它的样本产生的如此随意了(其实NSP训练出来的结果似乎更像是判断两句话是否属于同一主题)。
所以NSP是一项失败的预训练任务。但是,如果说其获得的CLS表征,是一种失败的表征,我认为就有点冤枉它了。在我看来,它是一个“很好的”表征,可以很好的用来描述两句话之间是否存在上下文的关系,但是也仅仅在这个场景下好。
举个例子,你教一个人做凶柿炒蛋,他学的很好,可是如果你忽然要求他去做一道松鼠桂鱼,那似乎是有点为难他了,或许他会先把火打开,然后倒油,然后呢?NSP的预训练也是类似的道理吧,不能说毫无用处,至少他学会打火倒油了呢。
可以说,NSP设计的出发点是好的,它是想增强模型对于sequence pair的表示能力,以扩展出更多的下游任务功能,只是任务设计的有点问题。
苏神介绍一篇文章:《曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果》,介绍的这个工作是叫NSP-BERT,其中提到了prompt。从NSP-BERT这个例子,我们也可以得到这样一个启发:
决定表征结果的,一是模型结构,二是任务范式。 同样的模型结构,换一种方式去描述这个任务,这种范式迁移的做法,便是prompt的思想了。
小结一下就是,NSP任务可以对整个句子的信息起到表征的作用,但是对于很多下游任务的应用场景,效果并不理想。
那么,讲道理,可不可以设计一个token,像[CLS]一样,用来表示整句话的特征,达到我们所期望的效果呢?
个人浅见,可以。但是需要好好设计训练目标,并且,仅仅利用一个token,似乎并不充分。
三、 bert获取sentence-embedding的正确方式
你有尝试从 BERT 提取编码后的 sentence embedding 吗?很多⼩伙伴的第⼀反应是:不就是直接取 顶层的[CLS] token的embedding作为句⼦表示嘛,难道还有其他套路不成? no no no,你知道这样得到的句⼦表示捕捉到的语义信息其实很弱吗?甚至连将token embedding取平均的效果都比取CLS层效果要好!
⾃2018年BERT惊艳众⼈之后,基于预训练模型对下游任务进⾏微调已成为炼丹的标配。然⽽近两年的 研究却发现,没有经过微调,直接由BERT得到的句⼦表示在语义⽂本相似性⽅⾯明显薄弱,甚⾄会弱于GloVe得到的表示。BERT-Flow论⽂中⾸先从理论上探索了masked language model 跟语义相似性任务上的联系,并通过实验分析了BERT的句⼦表示,最后提出了BERT-Flow来解决上述问题。
四、风光无限的prompt,到底提示了什么
prompt的有效性,似乎并不是主要来自于模板近似自然语言这一特点,而是因为模板中的token与原文中的token产生了交互,可以有效地对原文中的信息进行表征。
具体内容可参考《P-tuning:自动构建模版,释放语言模型潜能》、《Query and Extract: Refining Event Extraction as Type-oriented Binary Decoding》。
所以,prompt真的是在“提示”吗?我认为并不尽然,换个角度理解,它有效的原因在于**prompt模板提供了若干额外的token作为“锚点”,使得“锚点”token可以与原文中的token进行有效地交互,并表征一定的信息**。
五、重识transformer,也只是加权平均
既然问题是从预训练模型提出的,那最后肯定还是要回归transformer,本文的最开始我们提出这样的问题,我们利用预训练模型拿到的表征,为什么可以表征整个句子的信息,它又表征了什么东西,不妨跟随直观感受,定性的分析一下。
从结构上讲,预训练模型的核心无疑就是Transformer结构,而transformer主要又可以分为SA(self-attention)和FFN(feed forward network)。
后者比较容易理解,叠加一层的话,就是以前面的节点,加权平均来表示后边的节点,如果两层的话,那无非就是在加权平均的基础上,再做一次加权平均,其间再穿插一下增强非线性表征能力的激活函数。
那么self-attn又是在做什么呢?
在切入SA之前,先来看这样一段代码,这是sentence-transformer模块中对余弦相似度计算的实现,为了更好地扩展,它没有采用F.cos_similarity,而是采用了torch.mm,也就是矩阵乘法。
def pytorch_cos_sim(a: Tensor, b: Tensor):
"""
Computes the cosine similarity cos_sim(a[i], b[j]) for all i and j.
:return: Matrix with res[i][j] = cos_sim(a[i], b[j])
"""
return cos_sim(a, b)
def cos_sim(a: Tensor, b: Tensor):
"""
Computes the cosine similarity cos_sim(a[i], b[j]) for all i and j.
:return: Matrix with res[i][j] = cos_sim(a[i], b[j])
"""
if not isinstance(a, torch.Tensor):
a = torch.tensor(a)
if not isinstance(b, torch.Tensor):
b = torch.tensor(b)
if len(a.shape) == 1:
a = a.unsqueeze(0)
if len(b.shape) == 1:
b = b.unsqueeze(0)
a_norm = torch.nn.functional.normalize(a, p=2, dim=1)
b_norm = torch.nn.functional.normalize(b, p=2, dim=1)
return torch.mm(a_norm, b_norm.transpose(0, 1))
流程很简单,unsqueeze,norm,然后矩阵乘法。
看最后一行:将norm之后的tensor_a 与norm之后的并且转置的tensor_b,做了矩阵乘法。假设tensor有h个特征,那么这个矩阵乘法就是(1∗h)乘以(h∗1),就变成了一个标量,也就是相似度。
那假如a和b中,都有两个元素,乘法是(2∗h)乘以(h∗2)呢?那就得到了一个2∗2的矩阵,矩阵中的元素,代表a_1与 b_1,a_1与b_2,a_2 与b_1,a_2与b_2之间的相似度。
那如果不是2个,而是seq_len个呢?那是不是就得到了一个seq_len*seq_len的矩阵,矩阵中的每一个元素,代表 a中的每一个元素和 b中每一个元素两两之间的相似度。
再如果, **a和b压根就是同一个呢?**如果这h个特征,可以分成若干个(比如12个)桶呢?想到什么没有,SA的核心,就快要显现了
SA的公式,想必很多同学都已经熟记于心了:
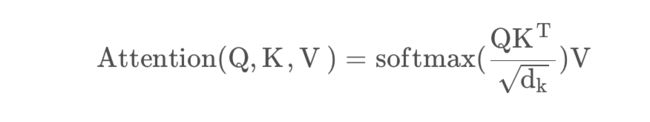
这个式子可以拆解成几个步骤,Q与K(的转置)相乘,除以sqrt{d_k},取softmax,以及乘以 V,如果让我从中选择最核心的一步,我会选择第一步,也就是Q与K的转置)相乘。
SA的核心,就是计算了序列中的每个token,与其自身中的所有token之间的相似度而已。
至于sqrt{d_k} ,是为了防止方差偏移,将方差拉回1,在实际操作中,其实也可以省略这一步,例如大名鼎鼎的T5。
softmax就更容易理解了,是把相似度变成“概率”。
既然相似度矩阵都已经算出来了,那最后怎么又乘了一个 V呢?
也不难理解,从变量维度的角度考虑,相似度矩阵是的维度是(seq_len, seq_len) ,而你接下来希望输出的特征的尺寸是(seq_len, hidden_size) 呀,当然需要一个额外的操作把其中的一个seq_-len变成hidden_size。
从实际意义的角度理解,我们刚刚说SA的核心是计算相似度,可没有说SA就是仅仅计算相似度,它**【计算相似度的目的,是以相似度为权重,将每个token的每个特征,表示为其它token的对应特征的加权平均】**。
前面的部分是计算权重,即attention score,而V就是被加权的对象。简单画一个矩阵相乘的图帮助大家理解一下,最后乘以 V的加权平均的过程:
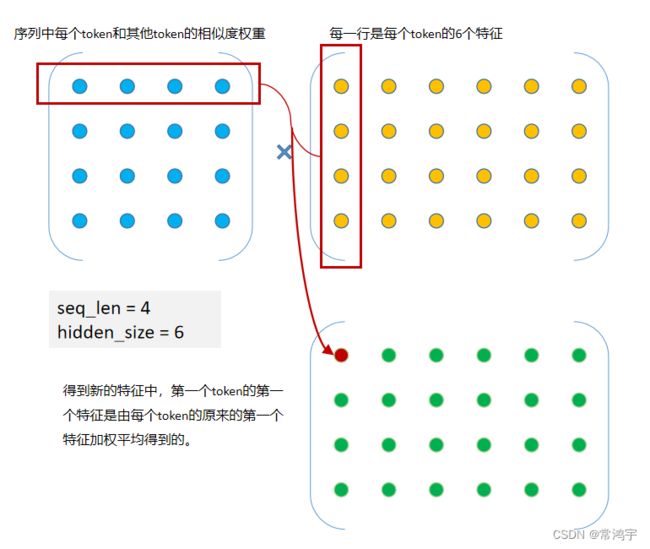
除此之外,SA还对Q,K,V做了一个linear变换,以增强其表示能力。而在多层SA之间穿插FFN,更进一步增强了模型的能力。所以说,FFN是加权平均,SA也是加权平均,这就代表着,我们的整个模型就是在利用每个token的特征,通过加权平均的方式,来表示其他token的特征,【所以理论上,一个token当然可以用来涵盖其他token的总和信息了,只不过权重有大有小罢了】。
当一个token的权重全部集中在其自身上时,其他位置的权重为0,那,它就不足以用来表征整个句子,所以,如果我们想要获得一个可以用来代表整个句子信息的token,那就是要通过设计一个合理的训练任务,使得这个token的注意力权重,可以落在句子中最重要的那些token上。
再回想一下在学校里学过的一点关于神经网络的知识,不仅是transformer在做加权平均,所有的神经网络,不都是在做这件事吗,只是我们这一通分析下来,使得这个认知更加清晰明确了一点。
所以说,从来就没有什么prompt,有的只是加权平均。
六、Self-Attention详解
了解了模型大致原理,我们可以详细的看一下究竟Self-Attention结构是怎样的。其基本结构如下
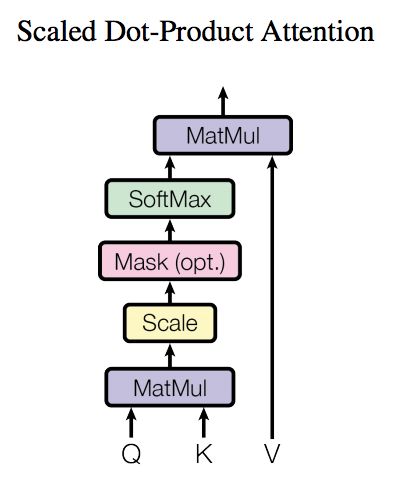

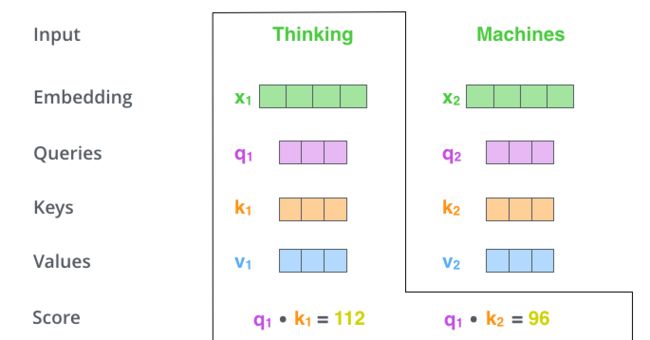
这里可能比较抽象,我们来看一个具体的例子(图片来源于https://jalammar.github.io/illustrated-transformer/,该博客讲解的极其清晰,强烈推荐),假如我们要翻译一个词组Thinking Machines,其中Thinking的输入的embedding vector用 x1 表示,Machines的embedding vector用 x2 表示。
-
当我们处理Thinking这个词时,我们需要计算句子中所有词与它的Attention Score,
- 这就像将当前词作为搜索的query,去和句子中所有词(包含该词本身)的key去匹配,看看相关度有多高。
- 我们用 q1 代表Thinking对应的query vector, k1 及 k2 分别代表Thinking以及Machines对应的key vector,则计算Thinking的attention score的时候我们**需要计算 q1 与 k1,k2 的点乘**
-
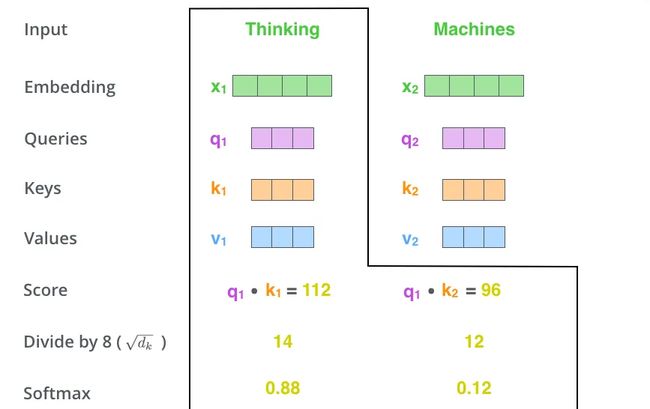
然后我们进行尺度缩放与softmax归一化,如下图所示:
-
-
显然,当前单词与其自身的attention score一般最大,其他单词根据与当前单词重要程度有相应的score。然后我们在用这些attention score与value vector相乘,得到**==加权[由k得到]==的向量**。
-

- Z1= 0.88V1+0.12V2[加权和]
-
-
如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示
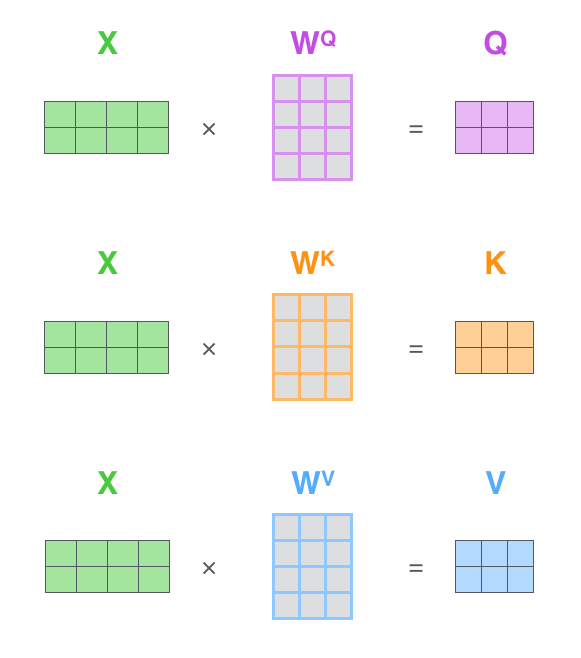
- 其中 WQ,WK,WV 是我们模型训练过程学习到的合适的参数【我们输入的文字通过embeding操作(one-hot、word2word)得到的向量,再通过这三组参数矩阵就可以得到对应的Q K V】。上述操作即可简化为矩阵形式
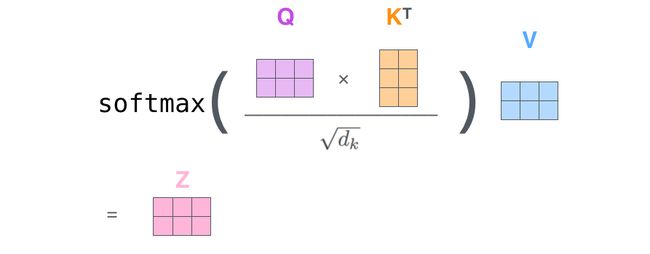
单头注意力和多头注意力
多头注意力就是对输入的向量在空间上进行降维均分为多个低纬度的向量。然后每个低纬度的向量进行注意力机制操作时学习的QKV参数不同。
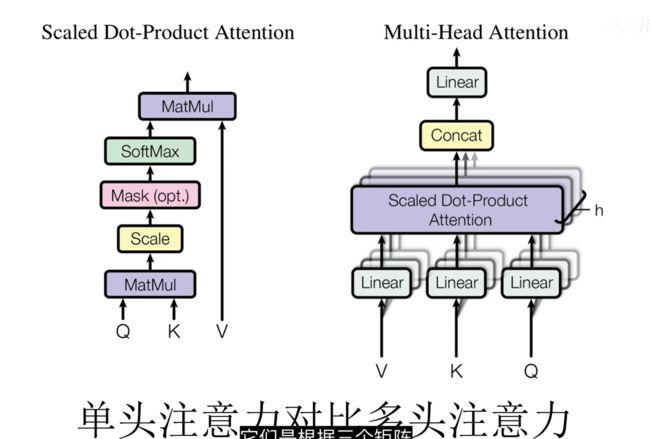
在单头注意力机制中,QKV向量的得到是根据一组参数矩阵WQ,WK,WV。
而multihead就是我们可以有不同的Q,K,V表示(eg: W1…Wn),最后再将其结果结合起来,如下图所示:
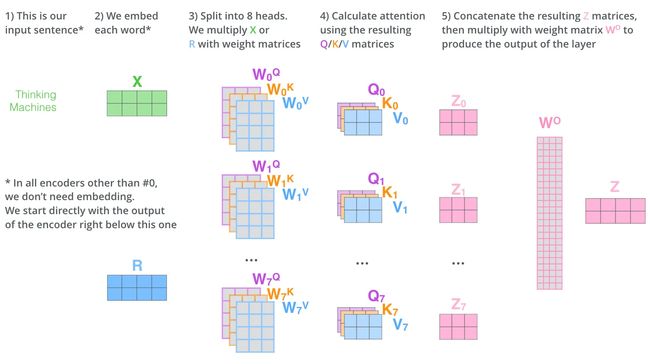
这就是基本的Multihead Attention单元
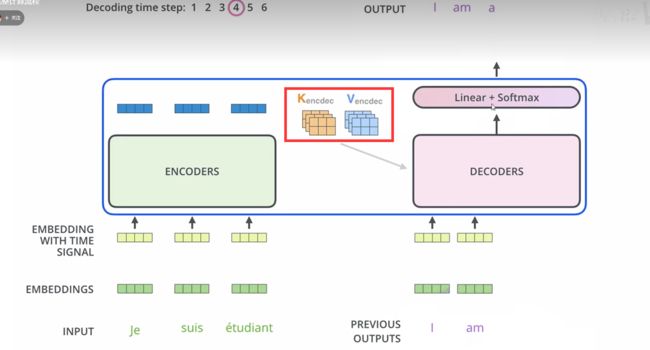
- 对于encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层encoder的输出,即encoder的每个位置都可以注意到之前一层encoder的所有位置【看Transformer模型就知道了】。
- 对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出,下面分别解释一下是什么原理。
-

- 第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的【不能预测未来】。
- 而第二级decoder也被称作encoder-decoder attention layer,即它的query来自于之前一级的decoder层的输出,但**其key和value来自于encoder的输出**,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。
-
- 总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
-