Go 并发编程之 MapReduce
为什么需要 MapReduce?
在实际的业务开发场景中,我们常常需要从不同的 rpc 服务或者不同的调用函数中获取相应属性来组装成复杂对象。例如查询商品详情:
商品服务–查询商品属性
库存服务–查询库存属性
价格服务–查询价格属性
营销服务–查询营销属性
如果是串行调用的话响应时间会随着 rpc 服务调用次数呈线性增长,所以我们要优化性能一般会将串行改为并行。
简单场景下使用 WaitGroup 就能够满足需求,但是如果我们需要对 rpc 调用返回的数据进行校验、数据加工转换、数据汇总等,使用 WaitGroup 就有点力不从心了。MapReduce 实现了进程内的数据批处理。
在实际开发中,基本都是对输入数据进行处理最后输出清洗后的数据,针对数据处理的大致流程可以分为以下三个步骤:
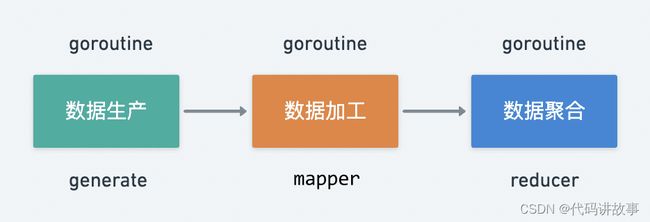
数据生产 generate
数据加工 mapper
数据聚合 reducer
其中数据生产是不可或缺的阶段,数据加工、数据聚合是可选阶段,数据生产与加工支持并发调用,数据聚合基本属于纯内存操作单协程即可。不同阶段可以由 goroutine 并发调度,那么其阶段产生的数据自然可以采用 channel 来实现 goroutine 之间的通信。

MapReduce 的基本使用
由 go-zero 框架封装的 MapReduce,其地址如下:
import "github.com/zeromicro/go-zero/core/mr"
方法定义如下(1.5.0支持泛型):
func MapReduce[T any, U any, V any](generate GenerateFunc[T], mapper MapperFunc[T, U], reducer ReducerFunc[U, V], opts ...Option) (V, error)
下面以一个并行求平方和的例子,看看 MapReduce 如何使用:
package main
import (
"fmt"
"log"
"github.com/zeromicro/go-zero/core/mr"
)
func main() {
val, err := mr.MapReduce(func(source chan<- int) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(i int, writer mr.Writer[int], cancel func(error)) {
// mapper
fmt.Println(i)
writer.Write(i * i)
}, func(pipe <-chan int, writer mr.Writer[int], cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
MapReduce 需要传入三个必填参数,分别是:generate、mapper、reducer,都是自定义的 func 类型,依次对应数据生产、数据加工、数据聚合。可选参数支持 context 上下文 和 workers 启动并发协程数。
MapReduce 的实现原理
MapReduce 定义的数据结构如下,依次用到了 Go 并发原语的 WaitGroup、Once、Channel、Context、atomic。
const (
defaultWorkers = 16
minWorkers = 1
)
var (
// ErrCancelWithNil is an error that mapreduce was cancelled with nil.
ErrCancelWithNil = errors.New("mapreduce cancelled with nil")
// ErrReduceNoOutput is an error that reduce did not output a value.
ErrReduceNoOutput = errors.New("reduce not writing value")
)
type (
// GenerateFunc is used to let callers send elements into source.
GenerateFunc[T any] func(source chan<- T)
// MapperFunc is used to do element processing and write the output to writer,
// use cancel func to cancel the processing.
MapperFunc[T, U any] func(item T, writer Writer[U], cancel func(error))
// ReducerFunc is used to reduce all the mapping output and write to writer,
// use cancel func to cancel the processing.
ReducerFunc[U, V any] func(pipe <-chan U, writer Writer[V], cancel func(error))
// MapFunc is used to do element processing and write the output to writer.
MapFunc[T, U any] func(item T, writer Writer[U])
// Option defines the method to customize the mapreduce.
Option func(opts *mapReduceOptions)
mapperContext[T, U any] struct {
ctx context.Context
mapper MapFunc[T, U]
source <-chan T
panicChan *onceChan
collector chan<- U
doneChan <-chan struct{}
workers int
}
mapReduceOptions struct {
ctx context.Context
workers int
}
// Writer interface wraps Write method.
Writer[T any] interface {
Write(v T)
}
)
defaultWorkers:默认配置启动 16 个协程同时执行,允许自定义配置。
GenerateFunc[T any] func(source chan<- T):数据生产,传入的参数是 channel,用于将数据传给 Mapper。
MapperFunc[T, U any] func(item T, writer Writer[U], cancel func(error)):数据加工,将获取到的 item 进一步处理,并将结果写入到 writer 中,如出现错误可调用 cancel 中断后续请求。
ReducerFunc[U, V any] func(pipe <-chan U, writer Writer[V], cancel func(error)):数据聚合,依从从管道中取出 Mapper 加工后的值,并加结果汇总到 writer 中返回。
MapFunc[T, U any] func(item T, writer Writer[U]):用于 Mapper 的具体过程调用。
Option func(opts *mapReduceOptions):可选参数配置
mapperContext[T, U any] struct {} :定义一个在 Mapper 处理过程中封装元数据的结构体。
Writer[T any] interface {}:定义一个接口,用于在协程流转时写入数据。
其他辅助结构如下:
// WithContext customizes a mapreduce processing accepts a given ctx.
func WithContext(ctx context.Context) Option {
return func(opts *mapReduceOptions) {
opts.ctx = ctx
}
}
// WithWorkers customizes a mapreduce processing with given workers.
func WithWorkers(workers int) Option {
return func(opts *mapReduceOptions) {
if workers < minWorkers {
opts.workers = minWorkers
} else {
opts.workers = workers
}
}
}
func buildOptions(opts ...Option) *mapReduceOptions {
options := newOptions()
for _, opt := range opts {
opt(options)
}
return options
}
func newOptions() *mapReduceOptions {
return &mapReduceOptions{
ctx: context.Background(),
workers: defaultWorkers,
}
}
func once(fn func(error)) func(error) {
once := new(sync.Once)
return func(err error) {
once.Do(func() {
fn(err)
})
}
}
type guardedWriter[T any] struct {
ctx context.Context
channel chan<- T
done <-chan struct{}
}
func newGuardedWriter[T any](ctx context.Context, channel chan<- T, done <-chan struct{}) guardedWriter[T] {
return guardedWriter[T]{
ctx: ctx,
channel: channel,
done: done,
}
}
func (gw guardedWriter[T]) Write(v T) {
select {
case <-gw.ctx.Done():
return
case <-gw.done:
return
default:
gw.channel <- v
}
}
type onceChan struct {
channel chan any
wrote int32
}
func (oc *onceChan) write(val any) {
if atomic.CompareAndSwapInt32(&oc.wrote, 0, 1) {
oc.channel <- val
}
}
下面,我们来看看 MapReduce 如何实现:
// MapReduce maps all elements generated from given generate func,
// and reduces the output elements with given reducer.
func MapReduce[T, U, V any](generate GenerateFunc[T], mapper MapperFunc[T, U], reducer ReducerFunc[U, V],
opts ...Option) (V, error) {
panicChan := &onceChan{channel: make(chan any)}
source := buildSource(generate, panicChan)
return mapReduceWithPanicChan(source, panicChan, mapper, reducer, opts...)
}
首先,来看看数据生产的过程,其封装了 buildSource 方法,启动一个协程去执行,并将结果写入到 source 中。
func buildSource[T any](generate GenerateFunc[T], panicChan *onceChan) chan T {
source := make(chan T)
go func() {
defer func() {
if r := recover(); r != nil {
panicChan.write(r)
}
close(source)
}()
generate(source)
}()
return source
}
其次,我们来看看数据加工的过程,其封装的方法在 mapReduceWithPanicChan 中。mapReduceWithPanicChan 比较长,但可以总结为以下3个步骤:
参数定义
output:最终返回结果,由 reducer 写入,只允许写入一次。
collector:有缓冲的chan,将 mapper 执行的结果放到 collector 中,同时限制并发个数。
writer:实例化一个 writer 用于写入数据到 channel 中。
开启一个新协程,执行 reducer 。
// mapReduceWithPanicChan maps all elements from source, and reduce the output elements with given reducer.
func mapReduceWithPanicChan[T, U, V any](source <-chan T, panicChan *onceChan, mapper MapperFunc[T, U],
reducer ReducerFunc[U, V], opts ...Option) (val V, err error) {
options := buildOptions(opts...)
// output is used to write the final result
output := make(chan V)
defer func() {
// reducer can only write once, if more, panic
for range output {
panic("more than one element written in reducer")
}
}()
// collector is used to collect data from mapper, and consume in reducer
collector := make(chan U, options.workers)
// if done is closed, all mappers and reducer should stop processing
done := make(chan struct{})
writer := newGuardedWriter(options.ctx, output, done)
var closeOnce sync.Once
// use atomic type to avoid data race
var retErr errorx.AtomicError
finish := func() {
closeOnce.Do(func() {
close(done)
close(output)
})
}
cancel := once(func(err error) {
if err != nil {
retErr.Set(err)
} else {
retErr.Set(ErrCancelWithNil)
}
drain(source)
finish()
})
go func() {
defer func() {
drain(collector)
if r := recover(); r != nil {
panicChan.write(r)
}
finish()
}()
reducer(collector, writer, cancel)
}()
go executeMappers(mapperContext[T, U]{
ctx: options.ctx,
mapper: func(item T, w Writer[U]) {
mapper(item, w, cancel)
},
source: source,
panicChan: panicChan,
collector: collector,
doneChan: done,
workers: options.workers,
})
select {
case <-options.ctx.Done():
cancel(context.DeadlineExceeded)
err = context.DeadlineExceeded
case v := <-panicChan.channel:
// drain output here, otherwise for loop panic in defer
drain(output)
panic(v)
case v, ok := <-output:
if e := retErr.Load(); e != nil {
err = e
} else if ok {
val = v
} else {
err = ErrReduceNoOutput
}
}
return
}
下面看看 mapper 的具体执行方法 executeMappers:
func executeMappers[T, U any](mCtx mapperContext[T, U]) {
var wg sync.WaitGroup
defer func() {
wg.Wait()
close(mCtx.collector)
drain(mCtx.source)
}()
var failed int32
pool := make(chan struct{}, mCtx.workers)
writer := newGuardedWriter(mCtx.ctx, mCtx.collector, mCtx.doneChan)
for atomic.LoadInt32(&failed) == 0 {
select {
case <-mCtx.ctx.Done():
return
case <-mCtx.doneChan:
return
case pool <- struct{}{}:
item, ok := <-mCtx.source
if !ok {
<-pool
return
}
wg.Add(1)
go func() {
defer func() {
if r := recover(); r != nil {
atomic.AddInt32(&failed, 1)
mCtx.panicChan.write(r)
}
wg.Done()
<-pool
}()
mCtx.mapper(item, writer)
}()
}
}
}
基于 WaitGroup 和 Channel 启动协程并发执行,并将结果写入到 writer 中,且优雅处理 panic 异常。
总结
MapReduce 基于数据处理使用场景封装了 Go 语言自带的并发原语,实现了数据生产–数据加工–数据聚合整个流程,在我实际开发中用到还是蛮多的。除了介绍到的 MapReduce,此包中还包含了其他几个实现,但大同小异,感觉的读者朋友可以自行阅读源码,加深对 MapReduce 的理解以及 前面介绍过的并发原语的回顾。