链表相关知识总结
链表相关知识
目录
- 前言
- 链表的定义
- 链表的分类
- 单链表的相关操作
- 链表的优缺点
前言
我们之前使用数组来存放数据,但使用数组时,要先指定数组中包含元素的个数,即数组长度。如果向数组中加入的元素个数超过了数组长度,便不能正确保存其中内容。且这种方式特别浪费空间。这时就希望有一种存储方式,其存储元素的个数是不受限制的,当要添加更多元素时,存储的个数会随之增加,这种方式被称为链表。链表是一种常见的数据结构。
数据的存储结构有两种:
- 连续存储【数组】
数组是由固定数目的同类型的元素按顺序排列而构成的数据结构,其中的元素被存储在一段连续的内存空间中
优点:存取速度很快
缺点:插入删除元素很慢,空间通常是有限制的,事使用前声明数组长度,需要大块连续的内存块 - 离散存储【链表】
链表是一种非连续的数据结构,链表在内存中不连续存储
优点:空间没有限制 插入删除元素很快
缺点:存取速度很慢
链表的定义
- n个结点离散分配
- 彼此通过指针相连
- 每个结点只有一个前驱结点,每个节点只有一个后续结点
- 首节点没有前驱结点,尾节点没有后续结点
专业术语:
首结点:第一个有效节点
尾节点:最后一个有效结点
头节点:第一个有效结点之前的结点,头结点不存放有效数据,且头结点主要为了方便对链表的操作
头指针:指向头结点的指针变量,且存放头结点的地址
尾指针:指向尾节点的指针变量
链表图解如下:

每一个结点都有两部分组成。左边的部分用来存放具体的数值,右边的部分需要存储下一个结点的地址,可以用指针实现(称为后继指针)
定义一个简单的结构体存储节点:
struct node
{
int data;//数据域
struct node * next;//指针域
};
上面的代码中,我们定义了一个叫做node的结构体类型,这个结构体类型有两个成员,第一个成员是整形data,用来存储具体的数值;第二个成员是指针,用来存储下一个结点的地址,因为下一个结点的类型也是struct node ,所以这个指针的类型也必须是struct node *类型的指针。
注:确定一个数组,需要三个参数:元素个数,首地址,长度
如若通过一个函数对链表进行处理,至少需要几个参数?
只需要一个参数:头指针
通过头指针可以推算出链表的其他所有参数(头指针存放头结点的地址,而头结点和其后结点数据类型相同)
链表的分类
- 单链表
- 双链表
- 循环链表
- 非循环链表
单链表:每个结点只有一个指针,每个结点的指针都指向下一结点,所有结点单线联系
双链表:添加了一个指针域,通过两个指针域,分别指向节点的前结点和后节点
循环链表:最后一个结点的指针指向链表头结点,头尾相连,形成一个环形的数据链;
单链表的创建
单链表的建立就是在程序运行的过程中,从无到有的建立一个链表,即一个一个分配结点的内存空间,输入结点的数据,建立结点间的相连关系
头插法:始终让每个新结点放在链表中第一个位置,即对链表进行遍历时先遍历的是最后加入链表的结点
尾插法:每次把新结点放在链表的最后一个位置
如何建立链表呢?
- 首先我们需要一个头指针head指向链表的最开始。当链表还没有建立的时候头指针head为空(也可以理解为空结点)
struct node *head;
head=NULL;//头指针为空
- 现在我们来创建一个第一个结点,并用临时指针p指向这个结点
struct node *p;
//动态申请一个内存的空间,用来存放一个结点,并用临时指针p指向这个结点
p=(struct node *)malloc(sizeof(struct node));
- 接下来分别设置新创建的这个结点的左半部分和右半部分
scanf("%d",&a);
p->data=a;//将数据存储到当前结点的data域中
p->next=NULL;//设置当前结点的后继指针为空,也就是当前结点的下一个结点为空
注:上面的代码中,我们发现了一个符号->,它叫做结构体运算符,用来访问结构体成员。因为此处p是一个指针,所以不能使用.号访问内部成员,而要使用->。
- 下面来设置头指针并设置新创建的结点的*next指向为空,头指针的作用方便以后从头遍历整个链表
if(head=NULL)
head=p;//如果这是新创建的结点,则将头指针指向这个结点
else
q->next=p;// 如果不是第一个创建的结点,则将上一个结点的后继指针指向当前结点
-
如果这是新创建的结点,则将头指针指向这个结点
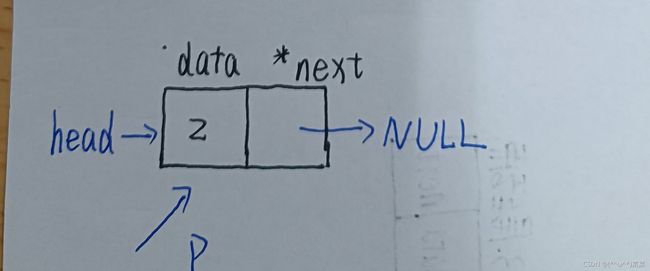
如果不是第一个创建的结点,则将上一个结点的后继指针指向当前结点
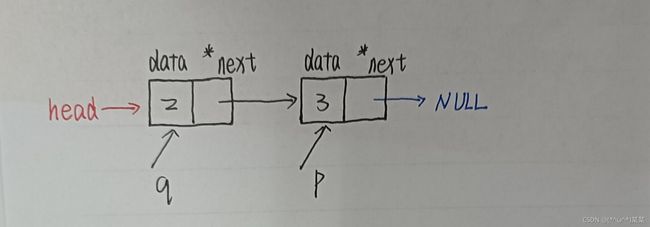
-
最后要将q也指向当前结点,因为接下来临时指针p会指向新创建的结点
q=p;//指针q也指向当前结点
完整的创建链表的代码:
#include 单链表的遍历
将链表创建好后,对链表中的数据进行遍历并进行输出
//输出链表中的所有数
t=head;
while(t!=NULL)
{
printf("%d",t->data);
t=t->next;//继续下一个结点
}
free(p);
单链表的插入

在1位置插入结点的具体步骤:
- 定义一个临时指针t从链表的头部开始遍历
t=head;//从链表头部开始遍历
- 等到指针t的下一个结点的值比6大的时候,将6插入到中间。即t->next->data大于6时进行插入
- 新增结点的后继指针指向当前结点的后继指针所指向的结点
- 当前结点的后继指针指向新增结点
scanf("%d",&a);//读入待插入的数
while(t!=NULL) //当没有达到链表尾部的时候进行循环
{
if(t->next->data>a)//如果当前结点下一个结点的值大于待插入数,将数插入到中间
{
p=(struct node *)malloc(sizeof(struct node));// 当前结点的后继指针指向新增结点
p->data=a;
p->next=t->next;// 新增结点的后继指针指向当前结点的后继指针所指向的结点
t->next=p;// 当前结点的后继指针指向新增结点
break;
}
t=t->next;//继续下一个结点
}
完整的单链表的插入代码:
注:将上文的创建,插入,遍历合起来即为一个完整的单链表的插入代码
#include 单链表的删除

删除普通结点的步骤:
- 首结点的指针域指向普通节点,普通结点的指针域指向尾节点
- 将首节点的指针域指向尾节点,相当于删除普通结点
- 释放普通节点的内存
正确写法:
r=p->pnext;//指向p后面的结点
p->pnext=r->pnext;//指向p后面的后面的结点
free( r );//释放r的内存
void delete(struct node * phead,int n)//phead为头结点,n为要删除的结点序号
{
int i;
struct node *r;//定义一个临时指针
struct node *p;
r=pHead;
p=r;
printf("删除第%d个学生 \n",n);
for(i=1;i<n;i++)//通过for循环使r指向要删除的结点
{
p=r;
r=r->next;
}
p->next=r->next;//连接删除结点两边的结点
free();//释放要删除结点的内存空间
}
链表的优缺点
-
优点:空间没有限制
-
优点: 插入删除元素很快
-
缺点:存取速度很慢
对链表的分享就到这啦,如果有错误,欢迎大家矫正
