Java POI导出word文件及生成表格
HWPF是处理 Microsoft Word 97(-2007) .doc文件格式,它还为较旧的Word 6和Word 95文件格式提供了有限的只读支持。包含在poi-scratchpad-XXX.jar中。
XWPF是处理 Word 2007 .docx文件格式,包含在poi-ooxml-XXX.jar中。
虽然HWPF和XWPF提供类似的功能,但目前两者之间没有公共接口。
这里POI使用 4.1.2版本,处理 .docx文件格式,word文件中只包含普通数据和表格数据。在Java POI通用导入导出Excel 的项目基础上简单实现的
一、新建word模板文件(.docx)
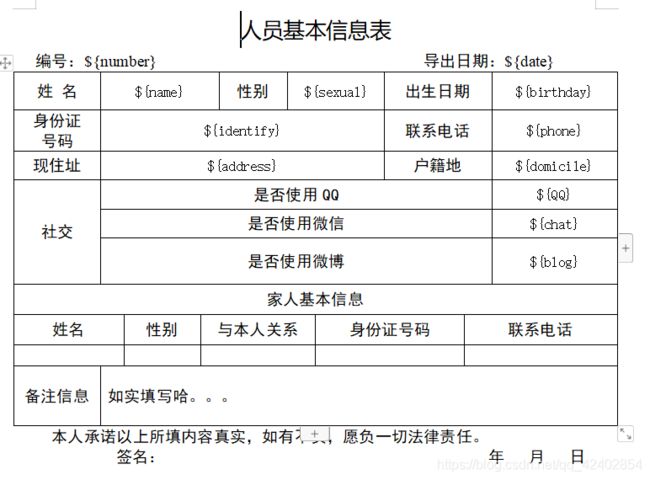
1、新建word模板文件,并在word文件中设置模板标签(这里自定义使用 ${变量名})。
普通数据:一般标签以 ${变量名} 的格式命名,其中 $ 和 {} 一定是英文符号,如 ${project} , ${time}。注意标签名不要重复
表格数据:由于表格数据是由多组相同格式的数据组成,所以无需设置标签,只需要在word文件中新建空白表格,并设置表头即可,系统可以根据相应单元格的位置对表格数据进行设置(这就是表格的操作了)。
word模板文件定义好放在项目的资源路径下。在代码中使用资源路径来获取对应的模板文件。
注意:如果遇到poi读取如${name}不能识别为一个整体时,可以使用
1)使用word的域操作。
2)在text文档中写好,如${name},然后再复制到word中,不要在word中一个一个敲,不然可能不会被poi识别为一个整体。
2、常用类说明
XWPFDocument:用于处理.docx文件。
XWPFParagraph:保存文本的段落 。在文档、表格、标题、页眉或页脚等都可存在段落。一个段落有很多样式化信息,但是实际的文本(可能还有更多的样式化)保存在子XWPFRuns上。
XWPFRun:XWPFRun对象用一组公共属性定义一个文本区域。对文本的内容,字体,颜色,大小,样式等操作。
XWPFTable:指定文档中出现的表的内容。表是一组按行和列排列的段落(和其他块级内容)。
XWPFTableRow:表示XWPFTable中的一行。行大多只有大小和样式,更多的内容存在于子XWPFTableCells中。
XWPFTableCell:表示XWPFTable中的单元格。单元格是存放实际内容(段落等)的东西。
具体的说明和操作方法查看官方API:https://poi.apache.org/apidocs/index.html
1)获取文件中文档的文本内容
public static void main(String[] args) throws Exception {
StringBuffer tableText = new StringBuffer();
String templatePath = PoiSerivce.class.getResource("/static/template/person.docx").getPath();
//解析docx模板并获取document对象
XWPFDocument document = new XWPFDocument(new FileInputStream(templatePath));
//获取整个文本对象
List paragraphs = document.getParagraphs();
//获取XWPFRun对象输出整个文档中的文本内容
paragraphs.forEach(xwpfParagraph -> {
List runs = xwpfParagraph.getRuns();
for (XWPFRun run : runs) {
tableText.append(run.toString());
}
});
System.out.println(tableText.toString());
} ![]()
2)获取文件中表格的文本内容
public static void main(String[] args) throws Exception {
StringBuffer tableText = new StringBuffer();
String templatePath = PoiSerivce.class.getResource("/static/template/person.docx").getPath();
//解析docx模板并获取document对象
XWPFDocument document = new XWPFDocument(new FileInputStream(templatePath));
//获取全部表格对象
List tables = document.getTables();
//获取表格中的文本内容
tables.forEach(xwpfTable -> {
//获取表格行数据
List rows = xwpfTable.getRows();
for (XWPFTableRow row : rows) {
//获取表格单元格数据
List tableCells = row.getTableCells();
for (XWPFTableCell tableCell : tableCells) {
List paragraphs = tableCell.getParagraphs();
paragraphs.forEach(xwpfParagraph -> {
List runs = xwpfParagraph.getRuns();
for (XWPFRun run : runs) {
tableText.append(run.toString());
}
});
}
}
});
System.out.println(tableText.toString());
} ![]()
二、导出.docx文件:使用XWPFDocument
1、controller
@RequestMapping(value="/exportWord")
public ResponseEntity exportWord() throws Exception{
String fileName = "导出docx数据.docx";
HttpHeaders headers = new HttpHeaders();
//下载显示的文件名,并解决中文名称乱码问题
String downloadFileName = new String(fileName.getBytes(StandardCharsets.UTF_8.name()),StandardCharsets.ISO_8859_1.name());
//通知浏览器以attachment(下载方式)打开
headers.setContentDispositionFormData("attachment", downloadFileName);
//applicatin/octet-stream: 二进制流数据(最常见的文件下载)
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
byte[] byteArr = poiSerivce.exportWord();
return new ResponseEntity(byteArr, headers, HttpStatus.CREATED);
} 2、service
public byte[] exportWord() {
// 模拟点数据
Map paragraphMap = new HashMap<>();
Map tableMap = new HashMap<>();
List familyList = new ArrayList<>();
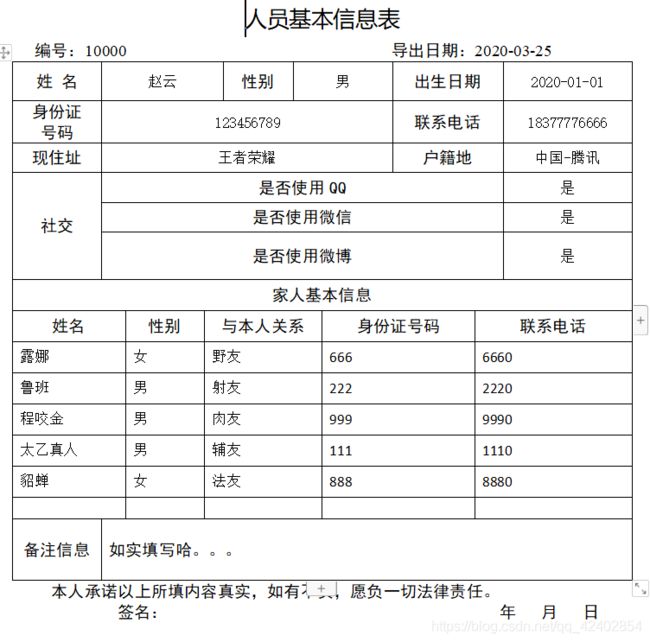
paragraphMap.put("number", "10000");
paragraphMap.put("date", "2020-03-25");
tableMap.put("name", "赵云");
tableMap.put("sexual", "男");
tableMap.put("birthday", "2020-01-01");
tableMap.put("identify", "123456789");
tableMap.put("phone", "18377776666");
tableMap.put("address", "王者荣耀");
tableMap.put("domicile", "中国-腾讯");
tableMap.put("QQ", "是");
tableMap.put("chat", "是");
tableMap.put("blog", "是");
familyList.add(new String[]{"露娜", "女", "野友", "666", "6660"});
familyList.add(new String[]{"鲁班", "男", "射友", "222", "2220"});
familyList.add(new String[]{"程咬金", "男", "肉友", "999", "9990"});
familyList.add(new String[]{"太乙真人", "男", "辅友", "111", "1110"});
familyList.add(new String[]{"貂蝉", "女", "法友", "888", "8880"});
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
String templatePath = this.getClass().getClassLoader().getResource("static/template/person.docx").getPath();
XWPFDocument document = null;
try {
//解析docx模板并获取document对象
document = new XWPFDocument(new FileInputStream(templatePath));
ExportWordUtil.changeParagraphText(document,paragraphMap);
ExportWordUtil.changeTableText(document, tableMap);
ExportWordUtil.copyHeaderInsertText(document, familyList , 7);
document.write(byteOut);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (document != null) {
try {
document.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return byteOut.toByteArray();
} 3、工具类
import org.apache.poi.xwpf.usermodel.*;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* @Description:
* @Auther: leijq
* @Date: 2020-03-25 14:59
* @Version: V1.0
*/
public class ExportWordUtil {
private ExportWordUtil() {
}
/**
* 替换文档中段落文本
*
* @param document docx解析对象
* @param textMap 需要替换的信息集合
*/
public static void changeParagraphText(XWPFDocument document, Map textMap) {
//获取段落集合
List paragraphs = document.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
//判断此段落时候需要进行替换
String text = paragraph.getText();
if (checkText(text)) {
List runs = paragraph.getRuns();
for (XWPFRun run : runs) {
//替换模板原来位置
run.setText(changeValue(run.toString(), textMap), 0);
}
}
}
}
/**
* 复制表头 插入行数据,这里样式和表头一样
* @param document docx解析对象
* @param tableList 需要插入数据集合
* @param headerIndex 表头的行索引,从0开始
*/
public static void copyHeaderInsertText(XWPFDocument document, List tableList, int headerIndex){
if(null == tableList){
return;
}
//获取表格对象集合
List tables = document.getTables();
for (XWPFTable table : tables) {
XWPFTableRow copyRow = table.getRow(headerIndex);
List cellList = copyRow.getTableCells();
if (null == cellList) {
break;
}
//遍历要添加的数据的list
for (int i = 0; i < tableList.size(); i++) {
//插入一行
XWPFTableRow targetRow = table.insertNewTableRow(headerIndex + 1 + i);
//复制行属性
targetRow.getCtRow().setTrPr(copyRow.getCtRow().getTrPr());
String[] strings = tableList.get(i);
for (int j = 0; j < strings.length; j++) {
XWPFTableCell sourceCell = cellList.get(j);
//插入一个单元格
XWPFTableCell targetCell = targetRow.addNewTableCell();
//复制列属性
targetCell.getCTTc().setTcPr(sourceCell.getCTTc().getTcPr());
targetCell.setText(strings[j]);
}
}
}
}
/**
* 替换表格对象方法
*
* @param document docx解析对象
* @param textMap 需要替换的信息集合
*/
public static void changeTableText(XWPFDocument document, Map textMap) {
//获取表格对象集合
List tables = document.getTables();
for (int i = 0; i < tables.size(); i++) {
//只处理行数大于等于2的表格
XWPFTable table = tables.get(i);
if (table.getRows().size() > 1) {
//判断表格是需要替换还是需要插入,判断逻辑有$为替换,表格无$为插入
if (checkText(table.getText())) {
List rows = table.getRows();
//遍历表格,并替换模板
eachTable(rows, textMap);
}
}
}
}
/**
* 遍历表格,并替换模板
*
* @param rows 表格行对象
* @param textMap 需要替换的信息集合
*/
public static void eachTable(List rows, Map textMap) {
for (XWPFTableRow row : rows) {
List cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
//判断单元格是否需要替换
if (checkText(cell.getText())) {
List paragraphs = cell.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
List runs = paragraph.getRuns();
for (XWPFRun run : runs) {
run.setText(changeValue(run.toString(), textMap), 0);
}
}
}
}
}
}
/**
* 匹配传入信息集合与模板
*
* @param value 模板需要替换的区域
* @param textMap 传入信息集合
* @return 模板需要替换区域信息集合对应值
*/
public static String changeValue(String value, Map textMap) {
Set> textSets = textMap.entrySet();
for (Map.Entry textSet : textSets) {
//匹配模板与替换值 格式${key}
String key = "${" + textSet.getKey() + "}";
if (value.indexOf(key) != -1) {
value = textSet.getValue();
}
}
//模板未匹配到区域替换为空
if (checkText(value)) {
value = "";
}
return value;
}
/**
* 判断文本中时候包含$
*
* @param text 文本
* @return 包含返回true, 不包含返回false
*/
public static boolean checkText(String text) {
boolean check = false;
if (text.indexOf("$") != -1) {
check = true;
}
return check;
}
}
这里简单做了工具类处理。
参考文章:
POI操作word模板并生成新的word
POI操作WORD表格系列--复制表格,填充数据
ends~