YOLOv3模型训练、检测流程梳理(含代码部分)
目录
一、YOLOv3简介
二、YOLOv3网络结构
(一)骨干网络——darknet53结构
(二)侦测网络部分
三、数据获取及预处理(数据标注+读取)
(一)标注
(二)读取voc或xml文件 -----抽样检查标注是否有误,再
(三)将确认标注好的xml文件转为yolo使用的标签格式(txt--cls cx cy w h)格式,图片、视频尺寸进行缩放处理,这里缩放为416
四、获取建议框并写入配置文件
(一)使用k-means算法对标签进行聚类,获取自定义的建议框
1.k-means算法原理和关键点
2.代码
(二)将自定义的建议框加入到cfg配置文件中
五、数据处理:封装dataset
六、开启训练
七、测试检测效果
一、YOLOv3简介
2018年,作者 Redmon 又在 YOLOv2 的基础上做了一些改进。特征提取部分采用darknet-53网络结构代替原来的darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。
用途:多类别多目标检测
学习yolo的前提:熟悉MTCNN的目标检测原理以及流程
二、YOLOv3网络结构

分为骨干网络和侦测网络
(一)骨干网络——darknet53结构
结构图:

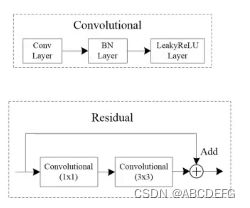
代码:
class Darknet53(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Sequential(
Convolutional(3, 32, 3, 1, 1),
DownSampling(32, 64),
Residual(64, 32),
DownSampling(64, 128),
Residual(128, 64),
Residual(128, 64),
DownSampling(128, 256)
)
self.layer_52 = nn.Sequential(
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128)
)
self.layer_26 = nn.Sequential(
DownSampling(256, 512),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256)
)
self.layer_13 = nn.Sequential(
DownSampling(512, 1024),
Residual(1024, 512),
Residual(1024, 512),
Residual(1024, 512),
Residual(1024, 512),
)
def forward(self, x):
tmp = self.layer(x)
# return tmp
layer_52_out = self.layer_52(tmp)
# return layer_52_out
layer_26_out = self.layer_26(layer_52_out)
# return layer_26_out
layer_13_out = self.layer_13(layer_26_out)
# return layer_13_out
return layer_52_out, layer_26_out, layer_13_out(二)侦测网络部分
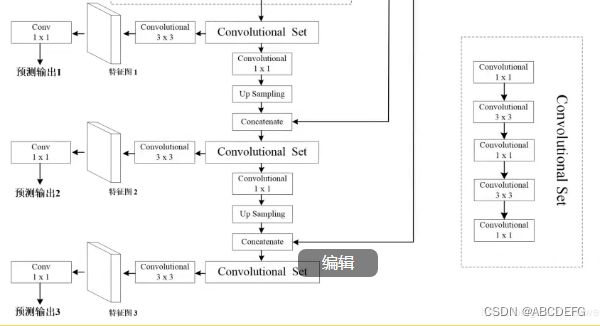
代码:
class YOLOv3(nn.Module):
def __init__(self):
super().__init__()
self.darknet53 = Darknet53()
self._out_13 = nn.Sequential(
ConvolutionalSet(1024, 512)
)
self.out_layer_13 = nn.Sequential(
Convolutional(512, 1024, 3, 1, 1),
nn.Conv2d(1024, 27, 1, 1, 0)
)
self.cat_layer_13 = nn.Sequential(
Convolutional(512, 256, 3, 1, 1),
UpSampling()
)
self._out_26 = nn.Sequential(
ConvolutionalSet(768, 256)
)
self.out_layer_26 = nn.Sequential(
Convolutional(256, 512, 3, 1, 1),
nn.Conv2d(512, 27, 1, 1, 0)
)
self.cat_layer_26 = nn.Sequential(
Convolutional(256, 128, 3, 1, 1),
UpSampling()
)
self._out_52 = nn.Sequential(
ConvolutionalSet(384, 128),
)
self.out_layer_52 = nn.Sequential(
Convolutional(128, 256, 3, 1, 1),
nn.Conv2d(256, 27, 1, 1, 0)
)
def forward(self, x):
tmp_52_out, tmp_26_out, tmp_13_out = self.darknet53(x)
_out_13 = self._out_13(tmp_13_out)
out_13 = self.out_layer_13(_out_13)
# return out_13
# cat_out_13 = self.cat_layer_13(tmp_13_out)
# return cat_out_13
cat_out_13_26 = torch.cat((self.cat_layer_13(_out_13), tmp_26_out), dim=1)
_out_26 = self._out_26(cat_out_13_26)
out_26 = self.out_layer_26(_out_26)
# return out_26
# cat_out_26 = self.cat_layer_26(cat_out_13_26)
# return cat_out_26
cat_out_26_52 = torch.cat((self.cat_layer_26(_out_26), tmp_52_out), dim=1)
_out_52 = self._out_52(cat_out_26_52)
out_52 = self.out_layer_52(_out_52)
# return out_52
return out_13, out_26, out_52整体结构(转载自参考6)以及整体代码(已经封装好的一些网络层)
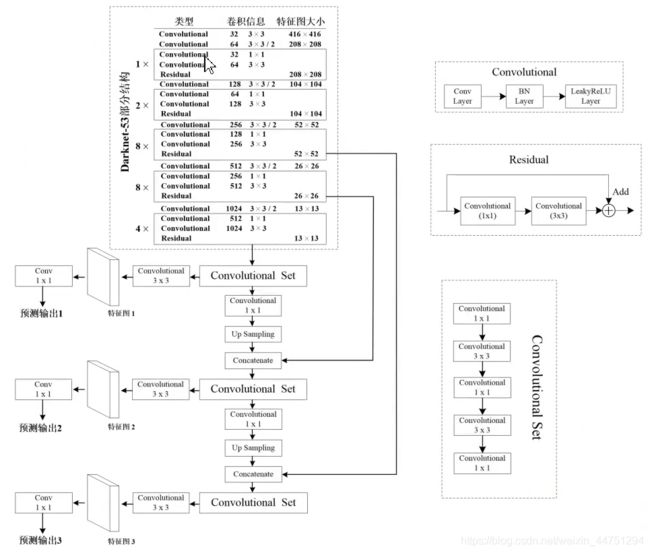
"""
定义YOLOv3网络
"""
import torch
import torch.nn as nn
class YOLOv3(nn.Module):
def __init__(self):
super().__init__()
self.darknet53 = Darknet53()
self._out_13 = nn.Sequential(
ConvolutionalSet(1024, 512)
)
self.out_layer_13 = nn.Sequential(
Convolutional(512, 1024, 3, 1, 1),
nn.Conv2d(1024, 27, 1, 1, 0)
)
self.cat_layer_13 = nn.Sequential(
Convolutional(512, 256, 3, 1, 1),
UpSampling()
)
self._out_26 = nn.Sequential(
ConvolutionalSet(768, 256)
)
self.out_layer_26 = nn.Sequential(
Convolutional(256, 512, 3, 1, 1),
nn.Conv2d(512, 27, 1, 1, 0)
)
self.cat_layer_26 = nn.Sequential(
Convolutional(256, 128, 3, 1, 1),
UpSampling()
)
self._out_52 = nn.Sequential(
ConvolutionalSet(384, 128),
)
self.out_layer_52 = nn.Sequential(
Convolutional(128, 256, 3, 1, 1),
nn.Conv2d(256, 27, 1, 1, 0)
)
def forward(self, x):
tmp_52_out, tmp_26_out, tmp_13_out = self.darknet53(x)
_out_13 = self._out_13(tmp_13_out)
out_13 = self.out_layer_13(_out_13)
# return out_13
# cat_out_13 = self.cat_layer_13(tmp_13_out)
# return cat_out_13
cat_out_13_26 = torch.cat((self.cat_layer_13(_out_13), tmp_26_out), dim=1)
_out_26 = self._out_26(cat_out_13_26)
out_26 = self.out_layer_26(_out_26)
# return out_26
# cat_out_26 = self.cat_layer_26(cat_out_13_26)
# return cat_out_26
cat_out_26_52 = torch.cat((self.cat_layer_26(_out_26), tmp_52_out), dim=1)
_out_52 = self._out_52(cat_out_26_52)
out_52 = self.out_layer_52(_out_52)
# return out_52
return out_13, out_26, out_52
class Darknet53(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Sequential(
Convolutional(3, 32, 3, 1, 1),
DownSampling(32, 64),
Residual(64, 32),
DownSampling(64, 128),
Residual(128, 64),
Residual(128, 64),
DownSampling(128, 256)
)
self.layer_52 = nn.Sequential(
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128),
Residual(256, 128)
)
self.layer_26 = nn.Sequential(
DownSampling(256, 512),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256),
Residual(512, 256)
)
self.layer_13 = nn.Sequential(
DownSampling(512, 1024),
Residual(1024, 512),
Residual(1024, 512),
Residual(1024, 512),
Residual(1024, 512),
# Residual(1024, 512),
# Residual(1024, 512),
# Residual(1024, 512),
# Residual(1024, 512)
)
def forward(self, x):
tmp = self.layer(x)
# return tmp
layer_52_out = self.layer_52(tmp)
# return layer_52_out
layer_26_out = self.layer_26(layer_52_out)
# return layer_26_out
layer_13_out = self.layer_13(layer_26_out)
# return layer_13_out
return layer_52_out, layer_26_out, layer_13_out
class Convolutional(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False):
super().__init__()
self.sub_module = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, bias=bias),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU()
)
def forward(self, x):
return self.sub_module(x)
class DownSampling(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.sub_module = nn.Sequential(
Convolutional(in_channels, out_channels=out_channels, kernel_size=3, stride=2, padding=1)
)
def forward(self, x):
return self.sub_module(x)
class Residual(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.sub_module = nn.Sequential(
Convolutional(in_channels, out_channels, 1, 1, 0),
Convolutional(out_channels, in_channels, 3, 1, 1)
)
def forward(self, x):
return x + self.sub_module(x)
pass
class ConvolutionalSet(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.sub_module = nn.Sequential(
Convolutional(in_channels, out_channels, 1, 1, 0),
Convolutional(out_channels, in_channels, 3, 1, 1),
Convolutional(in_channels, out_channels, 1, 1, 0),
Convolutional(out_channels, in_channels, 3, 1, 1),
Convolutional(in_channels, out_channels, 1, 1, 0),
)
def forward(self, x):
return self.sub_module(x)
class UpSampling(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return nn.functional.interpolate(x, scale_factor=2)
if __name__ == '__main__':
up = UpSampling()
data = torch.randn(1, 3, 416, 416)
y = up(data)
print(y.shape)
net = YOLOv3()
num_params = sum(p.numel() for p in net.parameters() if p.requires_grad)
print("权重数量:", num_params)
data = torch.randn(1, 3, 416, 416)
out13, out26, out52 = net(data)
print(out13.shape, out26.shape, out52.shape)
三、数据获取及预处理(数据标注+读取)
(一)标注
使用精灵标注助手或者labelme之类的标注工具,标注为pascal-voc
(二)读取voc或xml文件 -----抽样检查标注是否有误,再

import cv2
img_path = r"201.jpg"
img = cv2.imread(img_path)
# cv2.rectangle(img, (133-42//2, 176-33//2), (133+42//2, 176+33//2), color=(200, 100, 100), thickness=1)
# cv2.rectangle(img, (99-27//2, 204-31//2), (99+27//2, 204+31//2), color=(200, 100, 100), thickness=1)
cv2.rectangle(img, (160-50//2, 92-22//2), (160+50//2, 92+22//2), color=(200, 100, 100), thickness=1)
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
(三)将确认标注好的xml文件转为yolo使用的标签格式(txt--cls cx cy w h)格式,图片、视频尺寸进行缩放处理,这里缩放为416
"""
xml2txt_and_resize
"""
import os
import xml.etree.ElementTree as ET
# import io
from PIL import Image
find_path = 'yolov3训练数据/YOLO_v3_fish/outputs' # xml所在的文件夹路径
img_root_path = r"yolov3训练数据/YOLO_v3_fish/img" # 未缩放图片所在文件夹路径
label_save_path = 'yolov3训练数据/labels/labels.txt' # 保存标签文件的文件夹路径
img_save_path = r"yolov3训练数据/img_resize" # 保存缩放后的图片的文件夹路径
class YoloLabelHandle(object):
def __init__(self):
self.find_path = find_path
self.label_outfile = open(label_save_path, 'w')
print("创建成功:{}".format(label_save_path))
# def Make_txt(self, outfile):
# out = open(outfile, 'w')
# print("创建成功:{}".format(outfile))
# return out
def Work(self, count):
# 新建txt文件,确保文件正常保存
out = self.label_outfile
bg_img = Image.new("RGB", size=(416, 416), color=(0, 0, 0))
# 找到文件路径
cls_error_list = []
for root, dirs, files in os.walk(self.find_path):
# 找到文件目录中每一个xml文件
for file in files:
# print(file)
# # 250.xml
# exit()
# 记录处理过的文件
count += 1
# 输入、输出文件定义
# input_file = find_path + file
input_file = os.path.join(find_path, file)
# outfile = label_save_path + file[:-4] + '.txt'
# outfile = os.path.join(label_save_path, f"{file[:-4]}.txt")
# 分析xml树
tree = ET.parse(input_file)
root = tree.getroot()
# 取出图片名称
img_name = root.find("filename").text
img_path = os.path.join(img_root_path, img_name)
img = Image.open(img_path)
# img.show()
# exit()
# print(img_name)
# # 250.jpg
# exit()
# 取出整体图像w_image、h_image,将图片缩放至416,并保留缩放比例用于后续坐标计算
bg_img_copy = bg_img.copy()
size = root.find('size')
w_image = float(size.find('width').text)
h_image = float(size.find('height').text)
if w_image == 416:
ratio = min(img.size[0], img.size[1]) / max(img.size[0], img.size[1])
else:
ratio = min(w_image, h_image) / max(w_image, h_image)
if w_image == max(w_image, h_image):
src_w = 416
src_h = int(src_w * ratio)
else:
src_h = 416
src_w = int(src_h * ratio)
size_box = (src_w, src_h)
src_w_ratio = min(src_w, int(w_image)) / max(src_w, int(w_image))
src_h_ratio = min(src_h, int(h_image)) / max(src_h, int(h_image))
src_img = img.resize(size_box)
bg_img_copy.paste(src_img, (0, 0))
bg_img_copy.save(os.path.join(img_save_path, img_name))
print(f"{img_name}已resize完毕")
# 继续提取有效信息来计算txt中的四个数据
out.write(str(img_name) + " ")
for obj in root.iter('object'):
# 将类型提取出来,不同目标类型不同,本文仅有一个类别->0
classname = obj.find('name').text
cls_id = None
# print(type(classname))
# print(classname)
# exit()
if classname == "白胖鱼":
cls_id = 0
elif classname == "黑胖鱼":
cls_id = 1
elif classname == "金胖鱼":
cls_id = 2
# elif classname == "细长鱼":
elif classname == "细长鱼" or "黑长鱼" or "长条鱼":
cls_id = 3
else:
cls_error_list.append(f"{img_name}+{cls_id}")
# cls_id = classname
xmlbox = obj.find('bndbox')
x_min = float(xmlbox.find('xmin').text)
x_max = float(xmlbox.find('xmax').text)
y_min = float(xmlbox.find('ymin').text)
y_max = float(xmlbox.find('ymax').text)
# 计算公式
# x_center = ((x_min + x_max) / 2 - 1) / w_image
# y_center = ((y_min + y_max) / 2 - 1) / h_image
# w = (x_max - x_min) / w_image
# h = (y_max - y_min) / h_image
x_center = ((x_min + x_max) / 2 - 1) * src_w_ratio
y_center = ((y_min + y_max) / 2 - 1) * src_h_ratio
w = (x_max - x_min) * src_w_ratio
h = (y_max - y_min) * src_h_ratio
# 文件写入
out.write(
str(cls_id) + " " + str(int(x_center)) + " " + str(int(y_center)) + " " +
str(int(w)) + " " + str(int(h)) + '\t')
out.write("\n")
out.close()
print(cls_error_list)
return count
if __name__ == "__main__":
data = YoloLabelHandle()
number = data.Work(count=0)
print(number)
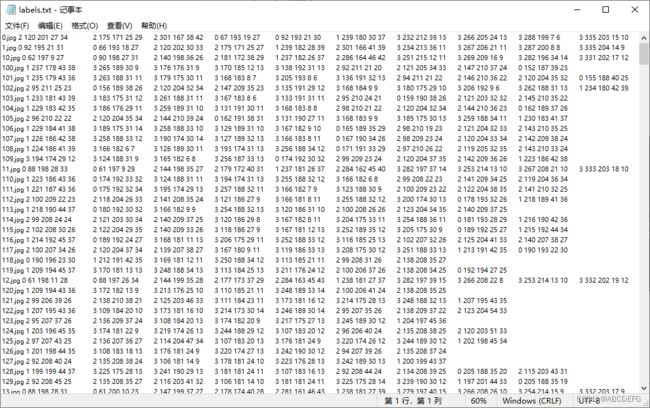
四、获取建议框并写入配置文件
(一)使用k-means算法对标签进行聚类,获取自定义的建议框
1.k-means算法原理和关键点
kmeans算法又名k均值算法,K-means算法中的k表示的是聚类为k个簇,means代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心,即用每一个的类的质心对该簇进行描述。
相当于将一堆的点,先按照类别数(k值)随机的生成不同的几个中心点(空簇),在yolo中 ,一共有9个建议框,则随机的取9个中心点,将样本中的每一个数据与9个中心点做对比,距离更近或者更相似的就分到一堆,分成9堆,再对每一堆数据求新的中心点,不断循环,更新中心点,直到新的中心点与上一个中心点相比不再改变或该表很小的时候停止,也可以人为设置循环的次数。
本文更新中心点的过程是是求均值、期望,因为大框的欧氏距离误差一定大于小框的,所以本文用的是(1-iou),iou(交并比)越大,则相似度(或者说重叠率)越高,在其他情况下也可以用欧氏距离、余弦相似度、或者曼哈顿距离来度量与中心的相似度。


该算法的优点是比较简单、容易实现,缺点是可能收敛到局部最小值,而且在数据量很大的时候效率低、速度慢
2.代码
"""
yolov3 -- kmeans
"""
import numpy as np
def iou(box, clusters):
"""
Calculates the Intersection over Union (IoU) between a box and k clusters.
:param box: tuple or array, shifted to the origin (i. e. width and height)
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: numpy array of shape (k, 0) where k is the number of clusters
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area")
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = intersection / (box_area + cluster_area - intersection)
return iou_
#做测试
def avg_iou(boxes, clusters):
"""
Calculates the average Intersection over Union (IoU) between a numpy array of boxes and k clusters.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param clusters: numpy array of shape (k, 2) where k is the number of clusters
:return: average IoU as a single float
"""
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])])
#把x1,y1,x2,y2 ----> cx,cy,w,h
def translate_boxes(boxes):
"""
Translates all the boxes to the origin.
:param boxes: numpy array of shape (r, 4)
:return: numpy array of shape (r, 2)
"""
new_boxes = boxes.copy()
for row in range(new_boxes.shape[0]):
new_boxes[row][2] = np.abs(new_boxes[row][2] - new_boxes[row][0])
new_boxes[row][3] = np.abs(new_boxes[row][3] - new_boxes[row][1])
return np.delete(new_boxes, [0, 1], axis=1)
def kmeans(boxes, k, dist=np.median):
"""
Calculates k-means clustering with the Intersection over Union (IoU) metric.
:param boxes: numpy array of shape (r, 2), where r is the number of rows
:param k: number of clusters
:param dist: distance function
:return: numpy array of shape (k, 2)
"""
rows = boxes.shape[0]
distances = np.empty((rows, k))
last_clusters = np.zeros((rows,))
np.random.seed()
# the Forgy method will fail if the whole array contains the same rows
clusters = boxes[np.random.choice(rows, k, replace=False)]
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters)
nearest_clusters = np.argmin(distances, axis=1)
if (last_clusters == nearest_clusters).all():
break
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters
return clusters
a = np.array([[1,2,3,4],[5,7,6,8]])"""
GetBoundingBox
"""
from test_yolo_anchor.kmeans import kmeans, avg_iou
import glob
import xml.etree.cElementTree as ET
import numpy as np
ANNOTATIONS_PATH = "yolov3训练数据/YOLO_v3_fish/outputs"
CLUSTERS = 9
def load_dataset(path):
dataset = []
for xml_file in glob.glob("{}/*xml".format(path)):
tree = ET.parse(xml_file)
# height = int(tree.findtext("./size/height"))
# width = int(tree.findtext("./size/width"))
size = tree.find('size')
width = float(size.find('width').text)
height = float(size.find('height').text)
ratio = min(width, height) / max(width, height)
if width == max(width, height):
src_w = 416
src_h = int(src_w * ratio)
else:
src_h = 416
src_w = int(src_h * ratio)
src_w_ratio = min(src_w, int(width)) / max(src_w, int(width))
# print(src_w_ratio)
src_h_ratio = min(src_h, int(height)) / max(src_h, int(height))
# print(src_h_ratio)
# exit()
try:
for obj in tree.iter("object"):
# 2023-5-21 乘上缩放的系数
# xmin = int(obj.findtext("bndbox/xmin")) / width * src_w_ratio # 简单做归一化
# ymin = int(obj.findtext("bndbox/ymin")) / height * src_h_ratio
# xmax = int(obj.findtext("bndbox/xmax")) / width * src_w_ratio
# ymax = int(obj.findtext("bndbox/ymax")) / height * src_h_ratio
xmin = int(obj.findtext("bndbox/xmin")) / width # 简单做归一化
ymin = int(obj.findtext("bndbox/ymin")) / height
xmax = int(obj.findtext("bndbox/xmax")) / width
ymax = int(obj.findtext("bndbox/ymax")) / height
xmin = np.float64(xmin)
ymin = np.float64(ymin)
xmax = np.float64(xmax)
ymax = np.float64(ymax)
if xmax == xmin or ymax == ymin:
print(xml_file)
dataset.append([xmax - xmin, ymax - ymin])
except:
print(xml_file)
return np.array(dataset)
if __name__ == '__main__':
# print(__file__)
data = load_dataset(ANNOTATIONS_PATH)
out = kmeans(data, k=CLUSTERS)
# clusters = [[10,13],[16,30],[33,23],[30,61],[62,45],[59,119],[116,90],[156,198],[373,326]]
# out= np.array(clusters)/416.0
print(out)
print(type(out))
print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100)) # 求平均iou, 越高说明选出来的框越好
print("Boxes:\n {}---{}".format(out[:, 0] * 416, out[:, 1] * 416)) # 得到w * 416, h * 416,因为yolo输入是416
# 9个框选出来后,要按照面积从小到大进行排序
print(np.sort(out * 416.))
int_out = (out * 416.).astype(int)
print(f"按照面积从小到大排序,并转为int:\n{int_out[np.argsort(out[:, 0] * out[:, 1] * 416.)]}")
# [[10 16]
# [13 30]
# [22 21]
# [32 22]
# [19 47]
# [23 64]
# [31 53]
# [43 44]
# [45 65]]
print(sorted((out * 416).tolist()))
# [[8.449999999999982, 15.022222222222215],
# [12.13333333333329, 20.80000000000002],
# [13.866666666666674, 33.12592592592596],
# [21.666666666666682, 25.03703703703701],
# [24.266666666666673, 16.94814814814815],
# [24.266666666666673, 53.92592592592594],
# [31.633333333333336, 21.185185185185187],
# [38.566666666666656, 26.192592592592607],
# [44.2, 61.629629629629626]]
ratios = np.around(out[:, 0] / out[:, 1], decimals=2).tolist()
print("Ratios:\n {}".format(sorted(ratios))) # 宽高比不应过大
(二)将自定义的建议框加入到cfg配置文件中
"""
cfg配置文件:建议框
"""
'建议框和图片尺寸'
IMG_HEIGHT = 416
IMG_WIDTH = 416
CLASS_NUM = 4
"anchor box是对coco数据集聚类获得的建议框"
ANCHORS_GROUP_KMEANS = {
52: [[10,13], [16,30], [33,23]],
26: [[30,61], [62,45], [59,119]],
13: [[116,90], [156,198], [373,326]]}
'自定义的建议框'
ANCHORS_GROUP = {
# 13: [[360, 360], [360, 180], [180, 360]],
# 26: [[180, 180], [180, 90], [90, 180]],
# 52: [[90, 90], [90, 45], [45, 90]]
13: [[31, 53], [43, 44], [45, 65]],
26: [[32, 22], [19, 47], [23, 64]],
52: [[10, 16], [13, 30], [22, 21]]
}
#计算建议框的面积
ANCHORS_GROUP_AREA = {
13: [x * y for x, y in ANCHORS_GROUP[13]],
26: [x * y for x, y in ANCHORS_GROUP[26]],
52: [x * y for x, y in ANCHORS_GROUP[52]],
}
if __name__ == '__main__':
for feature_size, anchors in ANCHORS_GROUP.items():#循环字典里面的键值对,并将键和值分别赋值给两个参数
print(feature_size)
print(anchors)
for feature_size, anchor_area in ANCHORS_GROUP_AREA.items():
print(feature_size)
print(anchor_area)五、数据处理:封装dataset
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision
import numpy as np
import cfg
import os
from PIL import Image
import math
import torch.nn.functional as F
LABEL_FILE_PATH = "yolov3训练数据/labels/labels.txt" # 标签数据地址
IMG_BASE_DIR = "yolov3训练数据/img_resize" # 数据总地址
transforms = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) # 对数据进行处理
# # one_hot分类函数,也可以直接使用nn包中的
# def one_hot(cls_num, i):
# b = np.zeros(cls_num)
# b[i] = 1.
# return b
class MyDataset(Dataset): # 封装数据集
def __init__(self):
with open(LABEL_FILE_PATH) as f:
self.dataset = f.readlines() # 读取标签文件中的所有数据
def __len__(self):
return len(self.dataset) # 获取数据长度
def __getitem__(self, index): # 用__getitem__方法一个一个的取出数据
labels = {} # 创建一个空的字典
line = self.dataset[index]
# print(line)
strs = line.split() # 将数据分割为字符串
# print(strs)
_img_data = Image.open(os.path.join(IMG_BASE_DIR, strs[0]))
img_data = transforms(_img_data) # 对数据进行处理,Totensor
_boxes = np.array(list(map(float, strs[1:]))) # map()函数可以将一个函数应用于一个可迭代对象的所有元素,并返回一个新的可迭代对象,其中包含了所有经过该函数处理后的元素
# 每个框有五个标签cls cx cy w h,因此可以将_boxes中的元素五等分,并赋值给boxes
boxes = np.split(_boxes, len(_boxes) // 5)
# print(boxes)
# 制作标签框
for feature_size, anchors in cfg.ANCHORS_GROUP.items(): # 循环建议框
# 每种输出的框分别赋值给两个变量,循环的目的是因为输出有3种特征图,因此也需要三种标签框
# print(feature_size, anchors)
labels[feature_size] = np.zeros(shape=(feature_size, feature_size, 3, 5 + cfg.CLASS_NUM), dtype=np.float32)
# shape 13 13 3 15
# 将feature_size作为键,形状为(feature_size, feature_size, 3, 5 + cfg.CLASS_NUM)的0举证作为值 传入空字典中
# feature_size为输出特征图的尺寸大小,
# 3为3个建议框,
# 5 + cfg.CLASS_NUM 为 1个置信度cls + 2个中心点坐标cx、cy + 2个偏移量offset_w,offset_h + 类别数class
for box in boxes: # 循环标签框中的5个值
cls, cx, cy, w, h = box # 将每个框的数据组成的列表解包赋值给对应变量
# 中心点x的坐标乘以特征图的大小再除以原图大小,整数部分作为索引,小数部分作为偏移量
# 原本是cx/(图片总的大小/特征图大小), (图片总的大小/特征图大小)即缩放比例
cx_offset, cx_index = math.modf(cx * feature_size / cfg.IMG_WIDTH) # 计算中心点在每个格子x方向的偏移量和索引
cy_offset, cy_index = math.modf(cy * feature_size / cfg.IMG_HEIGHT) # 计算中心点在每个格子y方向的偏移量和索引
for i, anchor in enumerate(anchors): # 循环三种建议框, 并带索引分别赋值给i和anchor
anchor_area = cfg.ANCHORS_GROUP_AREA[feature_size][i] # 每个建议框的面积,面积计算在cfg模块中
p_w, p_h = w / anchor[0], h / anchor[1]
# anchor[0]和anchor[1]为建议框的宽和高, w / anchor[0], h / anchor[1]代表建议框和实际框在w和h方向的偏移量
p_area = w * h # 实际标签框的面积
iou = min(p_area, anchor_area) / max(p_area, anchor_area) # 计算建议框和实际框的iou,默认同中心点,用最小面积除以最大面积
labels[feature_size][int(cy_index), int(cx_index), i] = np.array(
[iou, cx_offset, cy_offset, np.log(p_w), np.log(p_h),
*F.one_hot(torch.tensor(int(cls)), num_classes=cfg.CLASS_NUM)]
# 根据索引将上述值填入对应区域作为标签,表面该区域有目标物体, 其他地方没有就为0,
)
return labels[13], labels[26], labels[52], img_data # 将三种标签和数据返回
if __name__ == '__main__':
data = MyDataset()
dataloader = DataLoader(data, 3, shuffle=True)
for i, (target_13, target_26, target_52, img_data) in enumerate(dataloader):
print(target_13)
print("--------------------------------")
print(target_13.shape)
print(target_26.shape)
print(target_52.shape)
print(img_data.shape)
exit()
六、开启训练
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from yolov3_dataset import MyDataset
from yolov3_net import YOLOv3
from tqdm import tqdm
module_save_path = r"module_save/YOLOv3_fish03.pth"
batch_size = 8
str_epoch = 755
num_workers = 0
logs_name = "log_YOLOv3_fish03"
class Trainer: # 定义训练器
def __init__(self):
self.save_path = module_save_path
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.net = YOLOv3().to(self.device)
if os.path.exists(self.save_path):
self.net.load_state_dict(torch.load(self.save_path))
self.train_data = MyDataset()
self.train_loader = DataLoader(self.train_data, batch_size=batch_size, num_workers=num_workers, shuffle=True)
self.conf_loss_fn = nn.BCEWithLogitsLoss() # 置信度的损失函数,自带sigmoid
self.offset_loss_fn = nn.MSELoss() # 偏移量的损失函数
self.cls_loss_fn = nn.CrossEntropyLoss() # 多分类的交叉熵损失函数
self.optimzer = optim.Adam(self.net.parameters()) # 定义优化器
def loss_fn(self, output, target, alpha): # 定义损失计算方法,传入三个参数:网络输出的数据、标签、权重(用于平衡正负样本损失侧重)
# 网络输出的数据形状[N, C, H, W] --》 标签形状[N, H, W, C]
output = output.permute(0, 2, 3, 1)
# 通过reshape变换形状 将 N H W 45 --> N H W 3 15,即分成三个建议框,每个框有15个值
output = output.reshape(output.size(0), output.size(1), output.size(2), 3, -1)
# 计算正样本损失
mask_obj = target[..., 0] > 0 # 获取正样本,拿到置信度大于0的掩码值,返回其索引,省略号代表前面不变,在最后的15个值中取第0个,第0个为置信度
output_obj = output[mask_obj] # 获取输出的正样本
target_obj = target[mask_obj] # 获取标签的正样本
loss_obj_conf = self.conf_loss_fn(output_obj[:, 0], target_obj[:, 0]) # 计算置信度损失
loss_obj_offset = self.offset_loss_fn(output_obj[:, 1:5], target_obj[:, 1:5]) # 计算偏移量的损失
loss_obj_cls_ = self.cls_loss_fn(output_obj[:, 5:], torch.argmax(target_obj[:, 5:], dim=1)) # 计算多分类的损失
# 上述因输出是标量,需对标签取最大值,此处也可使用 loss_obj_cls_ = self.conf_loss_fn(output_obj[:, 5:], target_obj[:, 5:])
loss_obj = loss_obj_conf + loss_obj_offset + loss_obj_cls_ # 正样本的总损失
# 计算负样本损失
mask_not_obj = target[..., 0] == 0 # 获取负样本的掩码
output_not_obj = output[mask_not_obj] # 获取输出的负样本
target_not_obj = target[mask_not_obj] # 获取标签的负样本
loss_not_obj = self.conf_loss_fn(output_not_obj[:, 0], target_not_obj[:, 0]) # 计算负样本损失,负样本置信度为0,此处即差不多与0做损失
# 负样本无需做偏移量和分类损失,因为都是0
# 总损失为正样本损失与负样本损失乘以各自权重后的和
loss = alpha * loss_obj + (1 - alpha) * loss_not_obj
return loss
def train(self):
self.net.train() # 表示训练模式,可用可不用,若设计BN层和dropout,则测试时必须开启测试模式self.net.eval()
epochs = str_epoch
avg_loss_list = [1000, ]
summerWriter = SummaryWriter(logs_name)
# for _ in range(str_epoch):
# avg_loss_list.append(1000) # 给定一个初始损失值
while True:
sum_loss = 0
sum_loss_13 = 0
sum_loss_26 = 0
sum_loss_52 = 0
# avg_loss = 0
# print(f"开始第{epochs}轮训练")
loop = tqdm(enumerate(self.train_loader), total=len(self.train_loader))
for i, (target_13, target_26, target_52, img_data) in loop:
target_13, target_26, target_52, img_data = target_13.to(self.device), target_26.to(
self.device), target_52.to(self.device), img_data.to(self.device)
output_13, output_26, output_52 = self.net(img_data)
loss_13 = self.loss_fn(output_13, target_13, 0.9) # 尺寸13的总损失(置信度、偏移量、分类)
loss_26 = self.loss_fn(output_26, target_26, 0.9) # 尺寸26的总损失
loss_52 = self.loss_fn(output_52, target_52, 0.9) # 尺寸52的总损失
loss = loss_13 + loss_26 + loss_52 # 三个尺寸总损失
sum_loss_13 += loss_13.item()
sum_loss_26 += loss_26.item()
sum_loss_52 += loss_52.item()
sum_loss += loss.item()
self.optimzer.zero_grad()
loss.backward()
self.optimzer.step()
# if epochs % 10 == 0:
# torch.save(self.net.state_dict(), self.save_path.format(epochs)) # 保存网络参数
# print(f"第{epochs}轮权重文件保存成功,损失为{loss.item()}")
avg_loss_13 = sum_loss_13 / len(self.train_loader)
avg_loss_26 = sum_loss_26 / len(self.train_loader)
avg_loss_52 = sum_loss_52 / len(self.train_loader)
avg_loss = sum_loss / len(self.train_loader)
summerWriter.add_scalar(f"总损失", avg_loss, epochs)
summerWriter.add_scalar(f"loss_13", avg_loss_13, epochs)
summerWriter.add_scalar(f"loss_26", avg_loss_26, epochs)
summerWriter.add_scalar(f"loss_52", avg_loss_52, epochs)
print(f"第{epochs}轮平均损失为{avg_loss},之前平均损失最小值为{min(avg_loss_list)}")
# print(avg_loss_list)
# if avg_loss < avg_loss_list[epochs - 1]:
if avg_loss < min(avg_loss_list): # 与之前的损失中的最小值相比,若降低才保存
torch.save(self.net.state_dict(), self.save_path) # state_dic保存网络参数,save_path为参数保存路径
print(f"本轮损失下降{min(avg_loss_list) - avg_loss},"
f"本轮权重文件保存成功")
else:
print("损失未下降,未保存权重文件,继续训练")
avg_loss_list.append(avg_loss)
epochs += 1
if __name__ == '__main__':
train = Trainer()
train.train()
七、测试检测效果
获取输出框、去重、过滤、坐标反算、绘制
detect
from torchvision import transforms
from yolov3_net import YOLOv3
import cfg
import torch
import numpy as np
import PIL.ImageDraw as draw
import tool1
import os
import matplotlib.pyplot as plt
from PIL import Image, ImageFont, ImageDraw
import cv2
device = "cuda" if torch.cuda.is_available() else "cpu"
class Detector(torch.nn.Module): # 定义侦测模块
def __init__(self, sace_path):
super().__init__()
self.net = YOLOv3().to(device) # 实例化网络
self.net.load_state_dict(torch.load(sace_path, map_location=device)) # 加载权重文件
self.net.eval() # 开启测试模式:抑制BN层和dropout单元
def forward(self, input_data, thresh, anchors):
"""
前向计算
:param input_data:输入网络的数据
:param thresh: 置信度阈值---过滤掉置信度低的预测框
:param anchors: 建议框 传入的应当是一个字典
:return: 返回经过滤的预测框
"""
out_13, out_26, out_52 = self.net(input_data) # 将数据传入网络并获得输出,网络输出shape为N C H W
idx_13, vecs_13 = self._filter(out_13, thresh) # 经过筛选函数获取13*13特征图中置信度合格的置信度索引以及9个值
boxes_13 = self._parse(idx_13, vecs_13, 416 / 13, anchors[13]) # 对上面输出的两个值进行解析,获得最终的输出框
idx_26, vecs_26 = self._filter(out_26, thresh)
boxes_26 = self._parse(idx_26, vecs_26, 416 / 26, anchors[26])
idx_52, vecs_52 = self._filter(out_52, thresh)
boxes_52 = self._parse(idx_52, vecs_52, 416 / 52, anchors[52])
# 将三种框在第0维度拼接在一起返回
return torch.cat([boxes_13, boxes_26, boxes_52], dim=0)
def _filter(self, output_data, thresh):
"""
过滤函数
:param output_data:
:param thresh: 过滤的置信度阈值
:return: 筛选好的置信度索引数组以及 对应置信度的1+4+num_class个数值
"""
# 首先通过permute换轴,将网络输出的数据形状[N,C,H,W]转变成与标签一致的形状[N,H,W,C]
output = output_data.permute(0, 2, 3, 1)
# 输出的数据格式为 N H W C(27)--->N H W 3 * (1+4+num_class), 3是三种建议框,1是置信度,4是中心点和宽高的偏移量,这里是4分类,即num_class=4
# 通过reshape将各个建议框的数据分开 即从四维数据N H W 27 --->五维数据N H W 3 9
output = output.reshape(output.size(0), output.size(1), output.size(2), 3, -1)
# 再获取置信度大于阈值(自己可以根据目标情况设定)的目标值的掩码(为布尔型,True、False)
# mask = output[..., 0] > thresh # 9个通道为1+4+4,直接索引出第一个通道(置信度所在通道)
mask = torch.sigmoid(output[..., 0]) > thresh # 9个通道为1+4+4,直接索引出第一个通道(置信度所在通道)
# 取出掩码中的所有非0值的索引数组(非False)
# idx形状为(num_out, 4) ---> (目标数量,[N, H, W, 3个建议框之一的索引0,1,2]):
# 如[[0, 5, 7, 0], [0, 5, 9, 2]]
idx = mask.nonzero()
# 利用掩码获取符合置信度阈值的对应数据
vecs = output[mask]
return idx, vecs
def _parse(self, idx, vecs, t, anchors):
"""
解析函数
:param idx: 筛选合格框的索引
:param vecs: 9个值--> 1+4+num_class个数值
:param t: 每个格子的大小 = 总图大小 / 特征图大小,如13*13的输出,格子大小为416/13 = 32
:param anchors: 建议框
:return: 返回最终的输出框
"""
anchors = torch.tensor(anchors).to(device) # 将建议框转为tensor类型,并将其与输出数据放在同一设备
# idx形状为(num_out, 4)
# 拿到索引所对应的建议框类型之索引anchors_idx(0, 1, 2)
anchors_idx = idx[:, 3]
# 从vecs中获取置信度的值confidence,前述已说过,第一个通道就是置信度,所以取索引0
# 另外,因为网络输出的值可能会大于1,需通过sigmoid将其压缩至0-1之间
confidence = torch.sigmoid(vecs[:, 0])
# 从vecs中获取分类的值(是one_hot形式,有多少个分类就应该有多少位0/1数)
_classify = vecs[:, 5:]
# 判断类别长度是否为0,若为0则返回空,避免代码报错
if len(_classify) == 0:
classify = torch.tensor([]).to(device)
# 若不为0, 则返回类别最大值的索引,该索引就代表类别
else:
classify = torch.argmax(_classify, dim=1).float()
# idx形状(n,h,w,3), vecs(iou,p_x,p_y,p_w,p_h,类别)这里p_x,p_y代表中心点偏移量,p_w,p_h框偏移量
# | |
# | n h w anchors_idx iou,p_x,p_y,p_w,p_h,类别 |
# 对应索引 0 1 2 3 0 1 2 3 4 5:
# 坐标反算 (索引 + 偏移量)* 缩放系数
# 计算中心点cy(h+p_y)
cy = (idx[:, 1].float() + vecs[:, 2]) * t
# 计算中心点cx(w+p_x)
cx = (idx[:, 2].float() + vecs[:, 1]) * t
# 计算实际框的宽为w, w=建议框的宽*框的偏移量p_w 但需以e为底数
w = anchors[anchors_idx, 0] * torch.exp(vecs[:, 3])
# 计算实际框的高为h, h=建议框的高*框的偏移量p_h
h = anchors[anchors_idx, 1] * torch.exp(vecs[:, 4])
# 计算框左上角x的坐标
x1 = cx - w / 2
# 计算框左上角y的坐标
y1 = cy - h / 2
# 计算框右下角x的坐标
x2 = x1 + w
# 计算框右下角y的坐标
y2 = y1 + h
# 将置信度、坐标和类别按照一轴(即列)的方向重组堆叠在一起
out = torch.stack([confidence, x1, y1, x2, y2, classify], dim=1)
return out
def read_img(img_path, font=None):
img_name_list = os.listdir(img_path)
for image_file in img_name_list:
im = Image.open(os.path.join(img_path, image_file))
# y = detector(torch.randn(3, 3, 416, 416), 0.3, cfg.ANCHORS_GROUP)
# print(y.shape)
# img1 = pimg.open(r'data\imageS\06.jpg')#打开图片
img = im.convert('RGB') # 将类型转成rgb
# img = im
img = np.array(img) / 255 # 归一化
img = torch.Tensor(img) # 将数据转成Tensor
img = img.unsqueeze(0) # 图片的形状为(h,w,c)在0维度加一个轴变成(1,h,w,c)即(n,h,w,c)的形状
img = img.permute(0, 3, 1, 2) # 换轴将nhwc变成nchw
img = img.to(device)
out_value = detector(img, 0.4, cfg.ANCHORS_GROUP) # 调用侦测函数并将数据,自信度阀值和建议框传入
boxes = [] # 定义空列表用来装框
for j in range(4): # 循环判断类别数
classify_mask = (out_value[..., -1] == j) # 输出的类别如果和类别相同就做nms删掉iou的的框留下iou小的表示这不是同一个物体
# ,如果不用这个可能会将不同类别因iou大于目标值而不被删除,因此这里做个判断,只在同一类别中做nms,这里是获取同个类别的掩码
_boxes = out_value[classify_mask] # 更具掩码索引对应的输出作为框
boxes.append(tool1.nms(_boxes).to(device)) # 对同一类别做nms删掉不合格的框,并将框添加进列表
for box in boxes: # 3种特征图的框循环框torch.cat([boxes_13, boxes_26, boxes_52], dim=0),循环3次
# print(i)
try:
# print(box.shape)
img_draw = draw.ImageDraw(im) # 制作画笔
# cls=int(box[5])
for i in range(len(box)): # 循环单个特征图的框,循环框的个数次
c, x1, y1, x2, y2, cls = box[i, :] # 将自信度和坐标及类别分别解包出来
# print(c,x1, y1, x2, y2)
# print(int(cls.item()))
# print(round(c.item(),4))#取值并保留小数点后4位
img_draw.rectangle((x1, y1, x2, y2), outline=color[int(cls.item())], width=2) # 画框
img_draw.text((max(x1, 0) + 3, max(y1, 0) + 3), fill=color[int(cls.item())],
text=str(int(cls.item())), font=font, width=2)
img_draw.text((max(x1, 0) + 15, max(y1, 0) + 3), fill=color[int(cls.item())],
text=name[int(cls.item())], font=font, width=2)
img_draw.text((max(x1, 0) + 3, max(y1, 0) + 20), fill=color[int(cls.item())],
text=str(round(c.item(), 4)), font=font, width=2)
except:
continue
# im.save(os.path.join('Detector_results/results1_img/',image_file))
plt.clf()
plt.ion()
plt.axis('off')
plt.imshow(im)
plt.show()
plt.pause(10)
plt.close()
# im.show()
def read_video(video_path=""):
cap = cv2.VideoCapture(video_path)
while True:
retval, image = cap.read()
if not retval:
print("无法读取")
break
# print(image.shape)
# exit()
# plt_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
ratio = min(image.shape[0], image.shape[1]) / max(image.shape[0], image.shape[1])
bg_img = np.zeros((416, 416, 3), np.uint8)
src_img = cv2.resize(image, dsize=(int(416), int(416 * ratio)))
bg_img[:src_img.shape[0], :src_img.shape[1], :] = src_img
print(src_img.shape)
# cv2.imshow("11", bg_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# exit()
img = cv2.cvtColor(bg_img, cv2.COLOR_BGR2RGB)
# img.show()
# exit()
img = np.array(img) / 255 # 归一化
img = torch.Tensor(img) # 将数据转成Tensor
img = img.unsqueeze(0) # 图片的形状为(h,w,c)在0维度加一个轴变成(1,h,w,c)即(n,h,w,c)的形状
img = img.permute(0, 3, 1, 2) # 换轴将nhwc变成nchw
img = img.to(device)
out_value = detector(img, 0.3, cfg.ANCHORS_GROUP) # 调用侦测函数并将数据,自信度阀值和建议框传入
boxes = [] # 定义空列表用来装框
draw_img = bg_img.copy()
for j in range(4): # 循环判断类别数
classify_mask = (out_value[..., -1] == j) # 输出的类别如果和类别相同就做nms删掉iou的的框留下iou小的表示这不是同一个物体
# ,如果不用这个可能会将不同类别因iou大于目标值而不被删除,因此这里做个判断,只在同一类别中做nms,这里是获取同个类别的掩码
_boxes = out_value[classify_mask] # 更具掩码索引对应的输出作为框
boxes.append(tool1.nms(_boxes).to(device)) # 对同一类别做nms删掉不合格的框,并将框添加进列表
for box in boxes: # 3种特征图的框循环框torch.cat([boxes_13, boxes_26, boxes_52], dim=0),循环3次
# print(i)
for i in range(len(box)): # 循环单个特征图的框,循环框的个数次
c, x1, y1, x2, y2, cls = box[i, :] # 将自信度和坐标及类别分别解包出来
# print(c, x1, y1, x2, y2)
# print(int(cls.item()))
# print(round(c.item(),4))#取值并保留小数点后4位
cv2.rectangle(draw_img, (int(x1.item()), int(y1.item())), (int(x2.item()), int(y2.item())),
color=color[int(cls.item())], thickness=1)
# 分类的提示词
cv2.putText(draw_img, text=str(int(cls.item())),
org=(max(int(x1.item()), 0) + 3, max(int(y1.item()), 0) - 3),
fontScale=0.3,
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
color=color[int(cls.item())],
thickness=1)
# 分类名的提示词
cv2.putText(draw_img, text=name[int(cls.item())],
org=(max(int(x1.item()), 0) + 15, max(int(y1.item()), 0) - 3),
fontScale=0.3,
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
color=color[int(cls.item())],
thickness=1)
# 置信度
cv2.putText(draw_img, text=str(round(c.item(), 3)),
org=(max(int(x1.item()), 0) + 3, max(int(y1.item()), 0) + 6),
fontScale=0.2,
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
color=color[int(cls.item())],
thickness=1)
key = cv2.waitKey(24)
cv2.imshow("11", draw_img)
if key == ord('q'):
print("已中断读取")
break
cap.release()
cv2.destroyAllWindows()
def read_video02(video_path=""):
cap = cv2.VideoCapture(video_path)
print("开始读取视频")
while True:
retval, image = cap.read()
if not retval:
print("无法读取 或 读取完毕")
break
ratio = min(image.shape[0], image.shape[1]) / max(image.shape[0], image.shape[1])
bg_img = np.zeros((416, 416, 3), np.uint8)
src_img = cv2.resize(image, dsize=(int(416), int(416 * ratio)))
bg_img[:src_img.shape[0], :src_img.shape[1], :] = src_img
# print(src_img.shape)
img = cv2.cvtColor(bg_img, cv2.COLOR_BGR2RGB)
img = transforms.ToTensor()(img) # 将图片数据转为tensor并做归一化处理,与以下代码处理结果一致
# img = np.array(img) / 255 # 归一化
# img = torch.Tensor(img) # 将数据转成Tensor
img = img.unsqueeze(0) # 图片的形状为(h,w,c)在0维度加一个轴变成(1,h,w,c)即(n,h,w,c)的形状
# img = img.permute(0, 3, 1, 2) # 换轴将nhwc变成nchw
img = img.to(device) # 处理好的图片放入当前模型运作的设备
# 调用外部实例化的侦测模块, 传入图片数据、置信度阈值和建议框
out_value = detector(img, 0.3, cfg.ANCHORS_GROUP) # 输出为torch.cat([boxes_13, boxes_26, boxes_52], dim=0)
boxes = [] # 定义空列表来装侦测模块输出的框
# 复制cv2读取的原图像,便于后续在其上绘制目标框,也可在原图上直接绘制
draw_img = image.copy()
# 循环判别类别数,对同一类别做nms去除不合格的框,并将合格的框添加进列表
num_class = 4
for cls in range(num_class):
# out_value中索引-1的值为类别classify,做判断,取出同一类别框的掩码
classify_mask = (out_value[..., -1] == cls)
# 利用同一类别的掩码取出同一类别对应的框
_boxes = out_value[classify_mask]
# 对同一类别的框做nms去重,并将合格的框添加进列表,这里nms中的阈值设置为0.5,可更改
boxes.append(tool1.nms(_boxes).to(device))
# boxes的值
# [
# tensor([[ 0.9050, 57.6095, 179.3693, 76.3731, 206.2609, 0.0000],
# [ 0.8396, 83.3689, 178.7032, 103.7408, 206.4875, 0.0000]],
# device='cuda:0', grad_fn=),
# tensor([[ 0.7971, 223.8035, 160.7513, 254.1639, 198.1649, 1.0000]],
# device='cuda:0', grad_fn=),
# tensor([[ 0.9672, 280.6839, 146.0457, 320.0644, 187.8054, 2.0000],
# [ 0.9670, 162.7285, 156.7965, 187.8526, 184.9636, 2.0000],
# [ 0.9506, 104.0863, 184.9869, 131.7624, 217.8111, 2.0000]],
# device='cuda:0', grad_fn=),
# tensor([[ 0.9242, 209.3827, 204.1662, 245.6761, 216.5983, 3.0000],
# [ 0.8669, 327.5566, 197.9757, 341.4358, 209.1632, 3.0000],
# [ 0.8030, 252.9902, 198.7334, 277.7639, 211.0476, 3.0000]],
# device='cuda:0', grad_fn=)
# ]
# 通过循环分别将各个类别对应的框取出
for box in boxes:
# 将各个类别中的框循环取出,循环次数即为框的个数
for i in range(len(box)):
# 将置信度、坐标、类别分别解包出来
c, x1, y1, x2, y2, cls = box[i, :]
# 将坐标反算至原图或原视频大小,便于后续在原图中显示
x1, x2 = (x1 * image.shape[1] / 416, x2 * image.shape[1] / 416)
y1, y2 = (y1 * image.shape[0] / (416 * ratio), y2 * image.shape[0] / (416 * ratio))
# OpenCV画框
cv2.rectangle(draw_img, (int(x1.item()), int(y1.item())), (int(x2.item()), int(y2.item())),
color=color[int(cls.item())], thickness=2)
# 分类的提示词
cv2.putText(draw_img, text=str(int(cls.item())),
org=(max(int(x1.item()), 0) + 3 * 3, max(int(y1.item()), 0) - 3 * 4),
fontScale=0.7,
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
color=color[int(cls.item())],
thickness=2)
# 分类名的提示词
cv2.putText(draw_img, text=name[int(cls.item())],
org=(max(int(x1.item()), 0) + 10 * 3, max(int(y1.item()), 0) - 3 * 4),
fontScale=0.7,
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
color=color[int(cls.item())],
thickness=2)
# 置信度
cv2.putText(draw_img, text=str(round(c.item(), 3)),
org=(max(int(x1.item()), 0) + 3 * 3, max(int(y1.item()), 0) + 6 * 3),
fontScale=0.6,
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
color=color[int(cls.item())],
thickness=2)
key = cv2.waitKey(24)
cv2.imshow("11", draw_img)
if key == ord('q'):
print("已中断读取")
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
print(device)
save_path = "module_save/YOLOv3_fish03.pth"
detector = Detector(save_path) # 实例化侦测模块
# 测试读取图片
# name = {0: '白胖鱼', 1: '黑胖鱼', 2: '金胖鱼', 3: '细长鱼'}
# color = {0: "red", 1: "blueviolet", 2: "blue", 3: "green"}
# font = ImageFont.truetype("simsun.ttc", 10, encoding="unic") # 设置字体
# img_path = 'img_test'
# read_img(img_path, font)
# 测试读取视频(压缩后)
# name = {0: 'white_fish', 1: 'black_fish', 2: 'gold_fish', 3: 'other_fish'}
# color = {0: (0, 0, 255), 1: (0, 0, 0), 2: (0, 255, 0), 3: (255, 0, 0)}
# video_path = r"yolov3训练数据/20221111_150325.mp4"
# read_video(video_path)
# 测试读取视频(在原视频中标注)
name = {0: 'white_fish', 1: 'black_fish', 2: 'gold_fish', 3: 'other_fish'}
color = {0: (0, 0, 255), 1: (0, 0, 0), 2: (0, 255, 0), 3: (255, 0, 0)}
# video_path = r"yolov3训练数据/20221111_150115.mp4"
video_path = r"yolov3训练数据/20221111_150325.mp4" # 本组视频
read_video02(video_path)
'============================================================================================================='
'''
nonzero(a)
nonzero函数是numpy中用于得到数组array中非零元素的位置(数组索引)的函数。它的返回值是一个长度为a.ndim(数组a的轴数)的元组,元组的每个元素都是一个整数数组,其值为非零元素的下标在对应轴上的值。
(1)只有a中非零元素才会有索引值,那些零值元素没有索引值;
(2)返回的索引值数组是一个2维tuple数组,该tuple数组中包含一维的array数组。其中,一维array向量的个数与a的维数是一致的。
(3)索引值数组的每一个array均是从一个维度上来描述其索引值。比如,如果a是一个二维数组,则索引值数组有两个array,第一个array从行维度来描述索引值;第二个array从列维度来描述索引值。
(4)transpose(np.nonzero(x))函数能够描述出每一个非零元素在不同维度的索引值。
(5)通过a[nonzero(a)]得到所有a中的非零值
'''
tool(nms去重)
import numpy as np
import torch
def ious(box, boxes, isMin=False): # 定义iou函数
box_area = (box[3] - box[1]) * (box[4] - box[2]) # 计算置信度最大框的面积
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 4] - boxes[:, 2]) # 计算其他所有框的面积
xx1 = torch.max(box[1], boxes[:, 1]) # 计算交集左上角x的坐标其他同理
yy1 = torch.max(box[2], boxes[:, 2])
xx2 = torch.min(box[3], boxes[:, 3])
yy2 = torch.min(box[4], boxes[:, 4])
# w = torch.max(0, xx2 - xx1)
# h = torch.max(0, yy2 - yy1)#获取最大值也可以用下面这种方法
w = torch.clamp(xx2 - xx1, min=0) # 获取最大值
h = torch.clamp(yy2 - yy1, min=0)
inter = w * h # 计算交集面积
# ovr1 = inter/torch.min(box_area, area)
ovr2 = inter / (box_area + area - inter) # 交集面积/并集面积
# ovr = torch.max(ovr2,ovr1)
# if isMin:#用于判断是交集/并集,还是交集/最小面积(用于处理大框套小框的情况)
#
# ovr = inter / torch.min(box_area, area)
# else:
# ovr = inter / (box_area + area - inter)
return ovr2
def nms(boxes, thresh=0.5, isMin=True): # 定义nms函数并传3个参数,分别是框,自信度阀值,是否最小面积
if boxes.shape[0] == 0: # 获取框的个是看是否为0,为0没框就返回一个空的数组防止代码报错
return torch.Tensor([])
_boxes = boxes[(-boxes[:, 0]).argsort()] # 对框进行排序按自信度从大到小的顺序
r_boxes = [] # 定义一个空的列表用来装合格的框
while _boxes.shape[0] > 1: # 循环框的个数
a_box = _boxes[0] # 取出第一个(自信度最大的框)框最为目标框与 其他框做iou
b_boxes = _boxes[1:] # 取出剩下的所有框
r_boxes.append(a_box) # 将第一个框添加到列表
# print(iou(a_box, b_boxes))
index = torch.where(ious(a_box, b_boxes, isMin) < thresh) # 对框做iou将满足iou阀值条件的框留下并反回其索引
_boxes = b_boxes[index] # 根据索引取框并赋值给_boxes,使其覆盖原来的_boxes
if _boxes.shape[0] > 0: # 判断是否剩下最后一个框
r_boxes.append(_boxes[0]) # 将最后一个框,说明这是不同物体,并将其放进列表
return torch.stack(r_boxes)
if __name__ == '__main__':
# a = np.array([1,1,11,11])
# bs = np.array([[1,1,10,10],[11,11,20,20]])
# print(iou(a,bs))
bs = torch.tensor([[1, 1, 10, 10, 40, 8], [1, 1, 9, 9, 10, 9], [9, 8, 13, 20, 15, 3], [6, 11, 18, 17, 13, 2]])
# print(bs[:,3].argsort())
print(nms(bs))
参考资料:
1.https://blog.csdn.net/wjinjie/article/details/107509243
2.https://blog.csdn.net/qq_37541097/article/details/81214953
3.https://www.bilibili.com/video/BV1yi4y1g7ro?t=381&p=3
4.https://blog.csdn.net/weixin_44751294/article/details/117851548
5.https://blog.csdn.net/weixin_44751294/article/details/117844557
6.https://blog.csdn.net/weixin_44751294/article/details/117882906
7.YOLOv3目标检测算法——通俗易懂的解析_yolov3检测头_I松风水月的博客-CSDN博客