Baichuan2大模型本地部署
作为今年九月份开源的一个中午大语言模型,Baichuan2已经在各个维度上取得了亮眼的结果,效果已经超过了当前火热的ChatGLM2-6B,可以通过自然语言交互的方式为你提供以下服务:
- 提供知识:我可以回答各领域的问题,并提供准确的信息和知识,帮你解决问题或获取所需要的信息
- 文本生成:我可以创作不同体裁的内容,激发你的灵感
- 语言翻译:如果需要将一种语言翻译成另外一种语言,我可以为你提供翻译服务
- 语言理解:我可以用于语言理解相关的任务,例如文本分析、情感分析、摘要抽取、分类、聚类等
- 代码编写和解释:我还可以生成相关问题的代码或者解释相关代码的问题 请问你需要什么帮助吗?
目录
一、模型介绍
二、模型结果
通用领域
7B 模型结果
13B 模型结果
三、推理和部署
安装依赖
Python 代码方式
Chat 模型推理方法示范
Base 模型推理方法示范
命令行工具方式
网页 demo 方式
四、接入 LangChain-Chatchat
五、项目地址
一、模型介绍
- Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
- Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。
- 本次发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
- 所有版本对学术研究完全开放。同时,开发者通过邮件申请并获得官方商用许可后,即可免费商用,请参考协议章节。
- 欢迎阅读我们的技术报告 Baichuan 2: Open Large-scale Language Models 获取更多信息。
本次发布版本和下载链接见下表:
| 基座模型 | 对齐模型 | 对齐模型 4bits 量化 | |
|---|---|---|---|
| 7B | Baichuan2-7B-Base | Baichuan2-7B-Chat | Baichuan2-7B-Chat-4bits |
| 13B | Baichuan2-13B-Base | Baichuan2-13B-Chat | Baichuan2-13B-Chat-4bits |
二、模型结果
我们在通用、法律、医疗、数学、代码和多语言翻译六个领域的中英文和多语言权威数据集上对模型进行了广泛测试。
通用领域
在通用领域我们在以下数据集上进行了 5-shot 测试。
- C-Eval 是一个全面的中文基础模型评测数据集,涵盖了 52 个学科和四个难度的级别。我们使用该数据集的 dev 集作为 few-shot 的来源,在 test 集上进行测试。我们采用了 Baichuan-7B 的评测方案。
- MMLU 是包含 57 个任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的 LLM 评测数据集。我们采用了开源的评测方案。
- CMMLU 是一个包含 67 个主题的综合性性中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的评测方案。
- Gaokao 是一个以中国高考题作为评测大语言模型能力的数据集,用以评估模型的语言能力和逻辑推理能力。 我们只保留了其中的单项选择题,并进行了随机划分。我们采用了与 C-Eval 类似的评测方案。
- AGIEval 旨在评估模型的认知和解决问题相关的任务中的一般能力。 我们只保留了其中的四选一单项选择题,并进行了随机划分。我们采用了与 C-Eval 类似的评测方案。
- BBH 是一个挑战性任务 Big-Bench 的子集。Big-Bench 目前包括 204 项任务。任务主题涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面。BBH 是从 204 项 Big-Bench 评测基准任务中大模型表现不好的任务单独拿出来形成的评测基准。
7B 模型结果
| C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| LLaMA-7B | 27.10 | 35.10 | 26.75 | 27.81 | 28.17 | 32.38 |
| LLaMA2-7B | 28.90 | 45.73 | 31.38 | 25.97 | 26.53 | 39.16 |
| MPT-7B | 27.15 | 27.93 | 26.00 | 26.54 | 24.83 | 35.20 |
| Falcon-7B | 24.23 | 26.03 | 25.66 | 24.24 | 24.10 | 28.77 |
| ChatGLM2-6B | 50.20 | 45.90 | 49.00 | 49.44 | 45.28 | 31.65 |
| Baichuan-7B | 42.80 | 42.30 | 44.02 | 36.34 | 34.44 | 32.48 |
| Baichuan2-7B-Base | 54.00 | 54.16 | 57.07 | 47.47 | 42.73 | 41.56 |
13B 模型结果
| C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| LLaMA-13B | 28.50 | 46.30 | 31.15 | 28.23 | 28.22 | 37.89 |
| LLaMA2-13B | 35.80 | 55.09 | 37.99 | 30.83 | 32.29 | 46.98 |
| Vicuna-13B | 32.80 | 52.00 | 36.28 | 30.11 | 31.55 | 43.04 |
| Chinese-Alpaca-Plus-13B | 38.80 | 43.90 | 33.43 | 34.78 | 35.46 | 28.94 |
| XVERSE-13B | 53.70 | 55.21 | 58.44 | 44.69 | 42.54 | 38.06 |
| Baichuan-13B-Base | 52.40 | 51.60 | 55.30 | 49.69 | 43.20 | 43.01 |
| Baichuan2-13B-Base | 58.10 | 59.17 | 61.97 | 54.33 | 48.17 | 48.78 |
三、推理和部署
推理所需的模型权重、源码、配置已发布在 Hugging Face,下载链接见本文档最开始的表格。我们在此示范多种推理方式。程序会自动从 Hugging Face 下载所需资源。
安装依赖
pip install -r requirements.txt
Python 代码方式
Chat 模型推理方法示范
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "解释一下“温故而知新”"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。
Base 模型推理方法示范
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Base", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Base", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
>>> inputs = inputs.to('cuda:0')
>>> pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
登鹳雀楼->王之涣
夜雨寄北->李商隐
在上述两段代码中,模型加载指定
device_map='auto',会使用所有可用显卡。如需指定使用的设备,可以使用类似export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制。
命令行工具方式
python cli_demo.py
本命令行工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
网页 demo 方式
依靠 streamlit 运行以下命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。本网页 demo 工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
streamlit run web_demo.py
运行效果

注意事项:
Baichuan2部署使用的 Pytorch 版本是2.0
四、接入 LangChain-Chatchat
接入 LangChain-Chatchat (原 Langchain-ChatGLM): 基于 Langchain 与 ChatGLM 等大语言模型的本地知识库问答应用实现。只需在项目model_config.py 中修改 llm_model_dict 中代码,加入:
"Baichuan2": {
"local_model_path": "E:\\baichuan-incBaichuan2-13B-Chat", # "THUDM/chatglm2-6b-32k",
"api_base_url": "http://localhost:8888/v1", # "URL需要与运行fastchat服务端的server_config.FSCHAT_OPENAI_API一致
"api_key": "EMPTY"
},并且修改:
# LLM 名称
LLM_MODEL = "Baichuan2"实现效果如下:
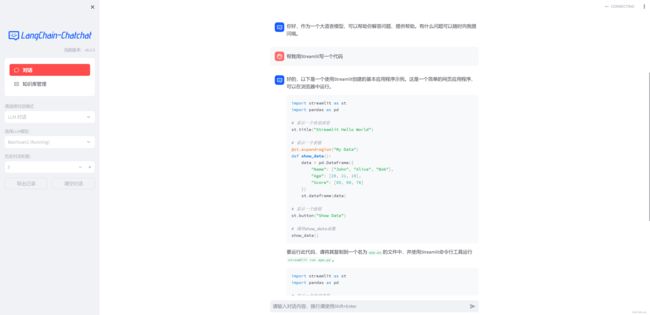
五、项目地址
Baichuan2:
GitHub - baichuan-inc/Baichuan2: A series of large language models developed by Baichuan Intelligent Technology
LangChain-Chatchat :
GitHub - chatchat-space/Langchain-Chatchat: Langchain-Chatchat(原Langchain-ChatGLM)基于 Langchain 与 ChatGLM 等语言模型的本地知识库问答 | Langchain-Chatchat (formerly langchain-ChatGLM), local knowledge based LLM (like ChatGLM) QA app with langchain