【深度学习实验】卷积神经网络(三):自定义二维卷积神经网络:步长和填充、输入输出通道
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. 步长、填充
a. 二维互相关运算(corr2d)
b. 二维卷积层类(Conv2D)
c. 模型测试
d. 代码整合
2. 输入输出通道
a. corr2d_multi_in
b. corr2d_multi_in_out
c. Conv2D
d. 模型测试
e. 代码整合
一、实验介绍
本实验实现了二维卷积神经网络的步长和填充、输入输出通道等功能。
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
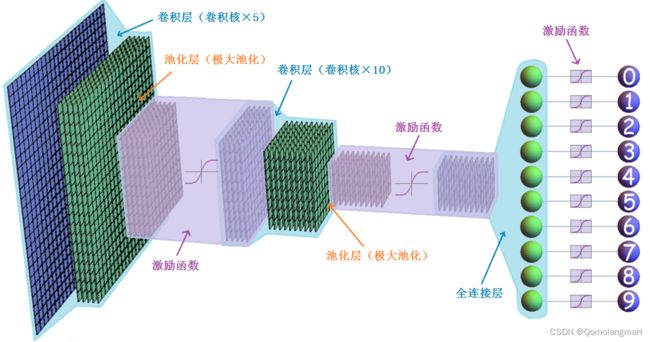
卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,广泛应用于图像识别、计算机视觉和模式识别等领域。它的设计灵感来自于生物学中视觉皮层的工作原理。
卷积神经网络通过多个卷积层、池化层和全连接层组成。
- 卷积层主要用于提取图像的局部特征,通过卷积操作和激活函数的处理,可以学习到图像的特征表示。
- 池化层则用于降低特征图的维度,减少参数数量,同时保留主要的特征信息。
- 全连接层则用于将提取到的特征映射到不同类别的概率上,进行分类或回归任务。
卷积神经网络在图像处理方面具有很强的优势,它能够自动学习到具有层次结构的特征表示,并且对平移、缩放和旋转等图像变换具有一定的不变性。这些特点使得卷积神经网络成为图像分类、目标检测、语义分割等任务的首选模型。除了图像处理,卷积神经网络也可以应用于其他领域,如自然语言处理和时间序列分析。通过将文本或时间序列数据转换成二维形式,可以利用卷积神经网络进行相关任务的处理。
0. 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F1. 步长、填充
承接上文:
【深度学习实验】卷积神经网络(二):自定义简单的二维卷积神经网络_QomolangmaH的博客-CSDN博客 https://blog.csdn.net/m0_63834988/article/details/133278280?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133278280?spm=1001.2014.3001.5501
- 卷积算子增加步长和零填充
-
改进了互相关函数
corr2d, -
改进了卷积算子
Conv2D, -
在
forward方法中,对输入x进行了填充操作,通过在输入的边缘周围添加零值像素来处理填充。这样做可以确保卷积核在输入的边缘位置也能进行有效的卷积操作,从而保持输出尺寸与输入尺寸的一致性。 -
在使用
Conv2D类创建对象时,可以通过传递不同的参数来对步长和填充进行灵活的设置。这样可以根据具体任务的需求来调整卷积操作的步长和填充方式,以获得更好的性能和适应性。
a. 二维互相关运算(corr2d)
修改为:
def corr2d(X, K, s):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - h + 1)//s , (X.shape[1] - w + 1)//s))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i*s:i*s + h, j*s:j*s + w] * K).sum()
return Y 添加了一个步长参数 s。通过指定步长,可以控制卷积操作在输入上的滑动步长,从而实现对输出大小的调整。在原始代码中,步长相当于固定为1,而修改后的代码可以通过调整 s 的值来改变步长。
b. 二维卷积层类(Conv2D)
修改为:
class Conv2D(nn.Module):
def __init__(self, kernel_size, stride=1, padding=0, weight=None):
super().__init__()
if weight is not None:
self.weight = weight
else:
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0] + 2*self.padding, x.shape[1] + 2*self.padding))
new_x[self.padding:x.shape[0] + self.padding,self.padding:x.shape[1] + self.padding] = x
return corr2d(new_x, self.weight, self.stride) + self.bias- 添加了步长和填充参数:
- 步长参数
stride控制卷积核在输入上的滑动步长 - 填充参数
padding在输入的边缘周围添加零值像素,以控制输出尺寸。- 在
forward方法中,对输入x进行了填充操作,通过在输入的边缘周围添加零值像素来处理填充。(这样做可以确保卷积核在输入的边缘位置也能进行有效的卷积操作,从而保持输出尺寸与输入尺寸的一致性。)
- 在
- 步长参数
c. 模型测试
# 由于卷积层还未实现多通道,所以我们的图像也默认是单通道的
fake_image = torch.randn((5,5))
# 需要为步长和填充指定参数,若未指定,则使用默认的参数1和0
narrow_conv = Conv2D(kernel_size=(3,3))
output1 = narrow_conv(fake_image)
print(output1.shape)
wide_conv = Conv2D(kernel_size=(3,3),stride=1,padding=2)
output2 = wide_conv(fake_image)
print(output2.shape)
same_width_conv = Conv2D(kernel_size=(3,3),stride=1,padding=1)
output3 = same_width_conv(fake_image)
print(output3.shape)
输出:
torch.Size([3, 3])
torch.Size([7, 7])
torch.Size([5, 5])
d. 代码整合
# 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
# 修改后的互相关函数
def corr2d(X, K, s):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - h + 1)//s , (X.shape[1] - w + 1)//s))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i*s:i*s + h, j*s:j*s + w] * K).sum()
return Y
# 修改后的卷积算子
class Conv2D(nn.Module):
def __init__(self, kernel_size, stride=1, padding=0, weight=None):
super().__init__()
if weight is not None:
self.weight = weight
else:
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0] + 2*self.padding, x.shape[1] + 2*self.padding))
new_x[self.padding:x.shape[0] + self.padding,self.padding:x.shape[1] + self.padding] = x
return corr2d(new_x, self.weight, self.stride) + self.bias
# 由于卷积层还未实现多通道,所以我们的图像也默认是单通道的
fake_image = torch.randn((5,5))
# 需要为步长和填充指定参数,若未指定,则使用默认的参数1和0
narrow_conv = Conv2D(kernel_size=(3,3))
output1 = narrow_conv(fake_image)
print(output1.shape)
wide_conv = Conv2D(kernel_size=(3,3),stride=1,padding=2)
output2 = wide_conv(fake_image)
print(output2.shape)
same_width_conv = Conv2D(kernel_size=(3,3),stride=1,padding=1)
output3 = same_width_conv(fake_image)
print(output3.shape)
2. 输入输出通道
a. corr2d_multi_in
def corr2d_multi_in(X, K, s):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(corr2d(x, k, s) for x, k in zip(X, K))
遍历输入张量 X 和核张量 K 的第一个维度(通道维度),并对每个通道执行互相关操作,然后将结果加在一起。
b. corr2d_multi_in_out
def corr2d_multi_in_out(X, K, s):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k, s) for k in K], 0)
用于处理多通道输入和多通道输出。它迭代核张量 K 的第一个维度,并对输入张量 X 执行多通道的互相关操作,将所有结果叠加在一起。
c. Conv2D
进一步修改:
class Conv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=None, stride=1, padding=0, weight=None):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if weight is not None:
h, w = weight.shape
weight = weight * torch.ones(in_channels, out_channels, h, w)
self.weight = nn.Parameter(weight)
else:
self.weight = nn.Parameter(torch.rand((in_channels, out_channels, kernel_size, kernel_size)))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0], x.shape[1] + 2 * self.padding, x.shape[2] + 2 * self.padding))
new_x[:, self.padding:x.shape[1] + self.padding, self.padding:x.shape[2] + self.padding] = x
return corr2d_multi_in_out(new_x, self.weight, self.stride)
-
在
Conv2D类的构造函数中,添加了输入通道数in_channels和输出通道数out_channels的参数。根据输入参数的不同,可以创建具有不同输入和输出通道数的卷积算子。 -
在
Conv2D类中,对权重参数进行了一些修改。如果传入了weight参数,则将其扩展为具有相同形状的多通道权重。否则,将随机生成一个具有指定输入和输出通道数的权重。 -
在
forward方法中,对输入张量x进行扩展,以适应填充操作。然后调用新的互相关函数corr2d_multi_in_out进行多通道的互相关操作。
d. 模型测试
fake_image = torch.randn((3,5,5))
conv = Conv2D(in_channels=3, out_channels=1, kernel_size=3, stride=2,padding=1)
output = conv(fake_image)
print(output.shape)
e. 代码整合
# 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
# 修改后的互相关函数
def corr2d(X, K, s):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - h + 1) // s, (X.shape[1] - w + 1) // s))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i * s:i * s + h, j * s:j * s + w] * K).sum()
return Y
# 修改后的卷积算子
# X为输入图像,K是输入的二维的核数组
def corr2d_multi_in(X, K, s):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(corr2d(x, k, s) for x, k in zip(X, K))
def corr2d_multi_in_out(X, K, s):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k, s) for k in K], 0)
class Conv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=None, stride=1, padding=0, weight=None):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if weight is not None:
h, w = weight.shape
weight = weight * torch.ones(in_channels, out_channels, h, w)
self.weight = nn.Parameter(weight)
else:
self.weight = nn.Parameter(torch.rand((in_channels, out_channels, kernel_size, kernel_size)))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0], x.shape[1] + 2 * self.padding, x.shape[2] + 2 * self.padding))
new_x[:, self.padding:x.shape[1] + self.padding, self.padding:x.shape[2] + self.padding] = x
return corr2d_multi_in_out(new_x, self.weight, self.stride)
fake_image = torch.randn((3,5,5))
conv = Conv2D(in_channels=3, out_channels=1, kernel_size=3, stride=2,padding=1)
output = conv(fake_image)
print(output.shape)