文件操作练习
关键字提取和查找
fo = open('data.txt', 'r')
fi = open('univ.txt', 'w')
for line in fo:
if 'alt=' in line:
# 根据【alt="】分割字符,返回一个字符串列表,用切片操作取最后一个元素,在用【"】分割最后一个元素,切片取第一个元素
name = line.split('alt="')[-1].split('"')[0]
# 题目要求写入每一行写一个大学机构名,则每一次写入都要加上换行符
fi.write("{}\n".format(name))
# fi.write(name+'\n')
fo.close()
fi.close()
知识回顾:
python中读取文件 写入文件,不会对自动对换行符做处理,需要手工删除str.strip() , 写入有格式化输出的时候,也要加入换行符。
fo = open('univ.txt', 'r')
m = 0 # 记录大学的数量
n = 0 # 记录学院的数量
for line in fo:
name = line.strip()
if '大学' in line and '大学生' not in line: # 迭代出每一行,对每一行进行判断,满足条件 数量加一,并打印输出
m += 1
print(name)
if '学院' in line:
n += 1
print(name)
# else:
# continue
print('包含大学名称数量是{}'.format(m))
print('包含学院名称的数量是{}'.format(n))
m = 0
n = 0
fo = open('univ.txt', 'r')
lines = f.readlines()
fo.close()
for line in lines:
line = line.replace('\n', '') # 将换行符 替换为空字符串,1.除去每一行的换行符 2.除去空行
# str.replace(old, new) 返回一个新的字符串
if '大学生' in line: # 排除大学生 关键词
continue
elif '学院' in line and '大学' in line:
# 序列切片判断是 序列结尾是学院还是大学
if line[-2:] == '大学':
m += 1
elif line[-2:] == '学院':
n += 1
print('{}'.format(line))
print("包含大学的名称数量是{}".format(m)) #输出大学计数
print("包含学院的名称数量是{}".format(n)) #输出学院计数
re正则表达式解题方法
文件读取格式化输出
打开一个data.txt文件,文件内容如下:
李涵剑:经济191,430
赵康剑:会计191,541
冯剑健:经济191,549
赵一一:机械191,301
冯风琳:计算191,352
…(略)
计算每个班的平均分并输出,平均分保留两位小数,班级名和分数用英文逗号隔开,格式如下:
计算191:390.43
机械191:324.99
…(略)
fo = open('data.txt', 'r')
clas = {}
for line in fo:
info = line.split(':')[1].strip('\n').split(',')
# key 班级名, value 成绩列表
#列表拼接+, 将每一位学生的成绩存入列表中
clas[info[0]] = clas.get(info[0], [])+[eval(info[1])]
# 遍历字典,计算平均值,并输出
for k in clas:
avg = sum(clas[k])/len(clas[k])
print("{}:{:.2f}".format(k, avg))
区域性提取文件
要求区域性提取,与单行提取不同。因此,可以借助写标记flag来标记操作的是哪里的文本。flag==True,进行提取
fo = open("论语.txt", 'r')
f = open('论语-原文.txt', 'w')
flag = False
for line in fo:
if "【注释】" in line:
flag = False
if "【原文】" in line:
flag = True
continue
if flag == True:
f.write(line.lstrip()) # 仅仅去掉行首空格和行尾空格,无空行 str.strip()默认删除空格、换行符...
# str.lstrip()删除str左边的空格和换行符(保证输出的内容无空行)
fo.close()
fi.clsse()
输出示例
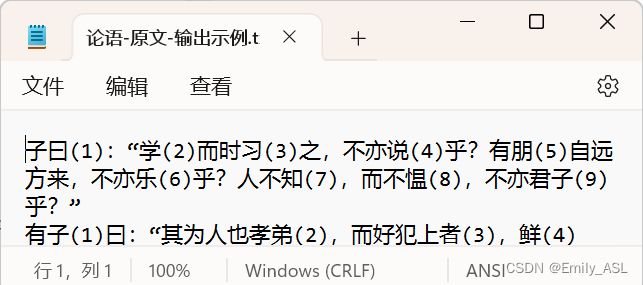
fo = open('论语-原文.txt', 'r')
fi = open('论语-提纯原文.txt', 'w')
# 遍历每一行,将每一行的标号e.g.(1)都替换为空字符串
for line in fo:
# 查看原文有1~22各标号
for i in range(1, 23):
line = line.replace("({})".format(i), "")
fi.write(line)
fo.close()
fi.close()