【代码复现】M2MRF采样算子代码实现流程
文章目录
- 1. 参数声明以及训练准备
- 2. 函数build_dataset()
-
- 2.1. class CustomDataset()
- 1.(1)
-
- 1.1. 函数train_segmentor()
-
- 1.1.1. 函数build_dataloader()
- 1.1.(1)
-
- 1.1.2. 函数train()
- 3. 模型的forward过程
- 4. 下采样class M2MRF()
-
- 4.1. 下采样class M2MRF_Module()
- 4.(1)
- 5. 上采样class M2MRF()
-
- 5.1. 上采样class M2MRF_Module()
- 5.(1)
- 附录. 模型框架图
摘要:对M2MRF分割模型代码逐行解读,该模型使用mmsegmentation架构,模型的创新点是改进采样算子,使用HRnet作为分割网络。
友情提示:如果进研究M2MRF算子,直接从第4节开始阅读。
1. 参数声明以及训练准备
启动命令:
python train.py --config ../configs/m2mrf/fcn_hr48-M2MRF-C_40k_idrid_bdice.py
程序开始:
if __name__ == '__main__':
main()
def main():
args = parse_args() # 参数声明
# 跳转到def parse_args():
def parse_args():定义:
def parse_args():
parser = argparse.ArgumentParser(description='Train a segmentor') # 帮助信息的描述文本
parser.add_argument('--config', help='train config file path') # config文件夹中的配置文件路径
parser.add_argument('--work-dir', help='the dir to save logs and models') # 运行配置和结果的保存路径
parser.add_argument(
'--load-from', help='the checkpoint file to load weights from')
parser.add_argument(
'--resume-from', help='the checkpoint file to resume from')
parser.add_argument(
'--no-validate',
action='store_true',
help='whether not to evaluate the checkpoint during training')
# 互斥参数组:可以有效地限制命令行参数的组合,并避免不一致或冲突的配置。
group_gpus = parser.add_mutually_exclusive_group()
group_gpus.add_argument( # None
'--gpus',
type=int,
help='number of gpus to use '
'(only applicable to non-distributed training)')
group_gpus.add_argument( # None
'--gpu-ids',
type=int,
nargs='+',
help='ids of gpus to use '
'(only applicable to non-distributed training)')
# 随机种子:方便复现结果
parser.add_argument('--seed', type=int, default=None, help='random seed') # None
parser.add_argument( # Flase
'--deterministic',
action='store_true',
help='whether to set deterministic options for CUDNN backend.')
parser.add_argument( # None
'--options', nargs='+', action=DictAction, help='custom options')
parser.add_argument( # None
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
parser.add_argument('--local_rank', type=int, default=0) # 0
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ: # Ture
os.environ['LOCAL_RANK'] = str(args.local_rank) # 0
return args
# 跳转到main函数
main函数:
从cfg = Config.fromfile(args.config)开始
def main():
args = parse_args()
'''Config.fromfile:
该函数实现的功能:读取所有配置文件,将它们赋给cfg。
具体内容见这段代码的下方
'''
cfg = Config.fromfile(args.config)
# 执行完上面语句,继续往下执行
cfg.text 配置文件内容如下:
/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/configs/_base_/models/fcn_hr18.py
# model settings
# norm_cfg = dict(type='SyncBN', requires_grad=True)
norm_cfg = dict(type='BN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://msra/hrnetv2_w18',
backbone=dict(
type='HRNet',
norm_cfg=norm_cfg,
norm_eval=False,
extra=dict(
stage1=dict(
num_modules=1,
num_branches=1,
block='BOTTLENECK',
num_blocks=(4, ),
num_channels=(64, )),
stage2=dict(
num_modules=1,
num_branches=2,
block='BASIC',
num_blocks=(4, 4),
num_channels=(18, 36)),
stage3=dict(
num_modules=4,
num_branches=3,
block='BASIC',
num_blocks=(4, 4, 4),
num_channels=(18, 36, 72)),
stage4=dict(
num_modules=3,
num_branches=4,
block='BASIC',
num_blocks=(4, 4, 4, 4),
num_channels=(18, 36, 72, 144)))),
decode_head=dict(
type='FCNHead',
in_channels=[18, 36, 72, 144],
in_index=(0, 1, 2, 3),
channels=sum([18, 36, 72, 144]),
input_transform='resize_concat',
kernel_size=1,
num_convs=1,
concat_input=False,
dropout_ratio=-1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
# model training and testing settings
train_cfg = dict()
test_cfg = dict(mode='whole')
/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/configs/_base_/models/fcn_hr48.py
_base_ = './fcn_hr18.py'
model = dict(
pretrained='open-mmlab://msra/hrnetv2_w48',
backbone=dict(
extra=dict(
stage2=dict(num_channels=(48, 96)),
stage3=dict(num_channels=(48, 96, 192)),
stage4=dict(num_channels=(48, 96, 192, 384)))),
decode_head=dict(
in_channels=[48, 96, 192, 384], channels=sum([48, 96, 192, 384]))
)
/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/configs/_base_/datasets/idrid.py
# dataset settings
"""
rgb mean:
[116.51282647 56.43716432 16.30857136]
rgb std:
[80.20605713 41.23209693 13.29250962]
"""
dataset_type = 'LesionDataset'
# data_root = '../data/IDRID'
data_root = '/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/data/IDRID_h512'
img_norm_cfg = dict(
mean=[116.513, 56.437, 16.309], std=[80.206, 41.232, 13.293], to_rgb=True)
image_scale = (512, 512)
# crop_size = (960, 1440) # NOTE:
crop_size = (512, 512)
palette = [
[0, 0, 0],
[128, 0, 0], # EX: red
[0, 128, 0], # HE: green
[128, 128, 0], # SE: yellow
[0, 0, 128] # MA: blue
]
classes = ['bg', 'EX', 'HE', 'SE', 'MA']
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=image_scale, ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', flip_ratio=0),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=0),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=image_scale,
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
# dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=1,
workers_per_gpu=1,
train=dict(
img_dir='image/train',
ann_dir='label/train/annotations',
data_root=data_root,
classes=classes,
palette=palette,
type=dataset_type,
pipeline=train_pipeline),
val=dict(
img_dir='image/test',
ann_dir='label/test/annotations',
data_root=data_root,
classes=classes,
palette=palette,
type=dataset_type,
pipeline=test_pipeline),
test=dict(
img_dir='image/test',
ann_dir='label/test/annotations',
data_root=data_root,
classes=classes,
palette=palette,
type=dataset_type,
pipeline=test_pipeline))
/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/configs/_base_/default_runtime.py
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/configs/_base_/schedules/schedule_40k_idrid.py
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
# learning policy
lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
# runtime settings
runner = dict(type='IterBasedRunner', max_iters=40000)
checkpoint_config = dict(by_epoch=False, interval=5000)
# evaluation = dict(interval=5000, metric='mIoU')
evaluation = dict(interval=40000, metric='mIoU')
/home/pengdao.xu/python/pytorch/M2MRF-Lesion-Segmentation/configs/m2mrf/fcn_hr48-M2MRF-C_40k_idrid_bdice.py
_base_ = [
'../_base_/models/fcn_hr48.py',
'../_base_/datasets/idrid.py',
'../_base_/default_runtime.py',
'../_base_/schedules/schedule_40k_idrid.py'
]
model = dict(
use_sigmoid=True,
backbone=dict(
type='HRNet_M2MRF_C', # DownSample/UpSample: Cascade/One-Step
m2mrf_patch_size=(8, 8),
m2mrf_encode_channels_rate=4,
m2mrf_fc_channels_rate=64,
),
decode_head=dict(
num_classes=4,
loss_decode=dict(type='BinaryLoss', loss_type='dice', loss_weight=1.0, smooth=1e-5)
)
)
test_cfg = dict(mode='whole', compute_aupr=True)
继续执行main函数
从if args.options is not None:开始看
def main():
args = parse_args()
'''Config.fromfile:
该函数实现的功能:读取所有配置文件,将它们赋给cfg。
具体内容见这段代码的下方
'''
cfg = Config.fromfile(args.config)
if args.options is not None: # False
cfg.merge_from_dict(args.options)
# set cudnn_benchmark:如果不存在该参数,则默认返回 False
if cfg.get('cudnn_benchmark', False): # 存在cudnn_benchmark,返回Ture,即执行下一行
torch.backends.cudnn.benchmark = True
# work_dir is determined in this priority: CLI > segment in file > filename
if args.work_dir is not None: # False
# update configs according to CLI args if args.work_dir is not None
cfg.work_dir = args.work_dir
elif cfg.get('work_dir', None) is None: # Ture
# use config filename as default work_dir if cfg.work_dir is None
'''
osp.basename(args.config)='fcn_hr48-M2MRF-C_40k_idrid_bdice.py'
osp.splitext(osp.basename(args.config))[0]='fcn_hr48-M2MRF-C_40k_idrid_bdice'
osp.join('./work_dirs',osp.splitext(osp.basename(args.config))[0]) = './work_dirs/fcn_hr48-M2MRF-C_40k_idrid_bdice'
''' # cfg.work_dir:配置文件的保存路径
cfg.work_dir = osp.join('./work_dirs', # './work_dirs/fcn_hr48-M2MRF-C_40k_idrid_bdice'
osp.splitext(osp.basename(args.config))[0])
if args.load_from is not None: # Flase
cfg.load_from = args.load_from
if args.resume_from is not None: # Flase
cfg.resume_from = args.resume_from
if args.gpu_ids is not None: # Flase
cfg.gpu_ids = args.gpu_ids
else:
cfg.gpu_ids = range(1) if args.gpus is None else range(args.gpus) # (0,1)
# init distributed env first, since logger depends on the dist info.
if args.launcher == 'none': # Ture
distributed = False # 不采用分布式训练
else:
distributed = True
init_dist(args.launcher, **cfg.dist_params)
# 创建./work_dir/fcn_hr48-M2MRF-C_40k_idrid_bdice文件夹
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# dump config:将fcn_hr48-M2MRF-C_40k_idrid_bdice.py文件保存在work_dir中
cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
# init the logger before other steps
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime()) # 获取当前日期和时间的时间戳,格式为 %Y%m%d_%H%M%S,例如:20230921_112337
log_file = osp.join(cfg.work_dir, f'{timestamp}.log') # 将 cfg.work_dir路径 和 timestamp文件名 拼接起来,生成最终的日志文件路径
# 创建一个根日志记录器。log_file 参数指定了日志文件的路径,log_level 参数指定了日志记录的等级。
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level) # log_level:INFO
# init the meta dict to record some important information such as
# environment info and seed, which will be logged
meta = dict()
# log env info:记录环境信息
env_info_dict = collect_env() # 收集运行环境的信息赋给env_info_dict
env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()]) #逐个读取字典信息
# env_info信息在这段代码后面展示
dash_line = '-' * 60 + '\n'
logger.info('Environment info:\n' + dash_line + env_info + '\n' +
dash_line) # 将环境信息写入log中
meta['env_info'] = env_info # 写入meta字典中
# log some basic info
logger.info(f'Distributed training: {distributed}') # None
logger.info(f'Config:\n{cfg.pretty_text}') # 将cfg.pretty_text信息写入log
# set random seeds
if args.seed is not None: # False
logger.info(f'Set random seed to {args.seed}, deterministic: '
f'{args.deterministic}')
set_random_seed(args.seed, deterministic=args.deterministic)
cfg.seed = args.seed # None
meta['seed'] = args.seed # None
meta['exp_name'] = osp.basename(args.config) # 'fcn_hr48-M2MRF-C_40k_idrid_bdice.py'
# 构建segmentor模型
model = build_segmentor(
cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
# 模型信息在该代码段下面展示
logger.info(model) # model信息载入log
# 构建数据集,接下来跳转到2.小节函数build_dataset
datasets = [build_dataset(cfg.data.train)]
env_info环境信息:在文章 《M2MRF配置信息》 可查看
model模型信息:在文章 《M2MRF配置信息》 可查看
2. 函数build_dataset()
由下面代码行进入函数build_dataset
datasets = [build_dataset(cfg.data.train)]
函数build_dataset:
def build_dataset(cfg, default_args=None):
"""Build datasets."""
from .dataset_wrappers import ConcatDataset, RepeatDataset
if isinstance(cfg, (list, tuple)): # False
dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
elif cfg['type'] == 'RepeatDataset': # False
dataset = RepeatDataset(
build_dataset(cfg['dataset'], default_args), cfg['times'])
elif isinstance(cfg.get('img_dir'), (list, tuple)) or isinstance( # False
cfg.get('split', None), (list, tuple)):
dataset = _concat_dataset(cfg, default_args)
else:
# 进入class CustomDataset(),下面跳转到2.1. class CustomDataset()
dataset = build_from_cfg(cfg, DATASETS, default_args)
return dataset
2.1. class CustomDataset()
类CustomDataset:
@DATASETS.register_module()
class CustomDataset(Dataset):
"""Custom dataset for semantic segmentation.
An example of file structure is as followed.
.. code-block:: none
├── data
│ ├── my_dataset
│ │ ├── img_dir
│ │ │ ├── train
│ │ │ │ ├── xxx{img_suffix}
│ │ │ │ ├── yyy{img_suffix}
│ │ │ │ ├── zzz{img_suffix}
│ │ │ ├── val
│ │ ├── ann_dir
│ │ │ ├── train
│ │ │ │ ├── xxx{seg_map_suffix}
│ │ │ │ ├── yyy{seg_map_suffix}
│ │ │ │ ├── zzz{seg_map_suffix}
│ │ │ ├── val
The img/gt_semantic_seg pair of CustomDataset should be of the same
except suffix. A valid img/gt_semantic_seg filename pair should be like
``xxx{img_suffix}`` and ``xxx{seg_map_suffix}`` (extension is also included
in the suffix). If split is given, then ``xxx`` is specified in txt file.
Otherwise, all files in ``img_dir/``and ``ann_dir`` will be loaded.
Please refer to ``docs/tutorials/new_dataset.md`` for more details.
Args:
pipeline (list[dict]): Processing pipeline
img_dir (str): Path to image directory
img_suffix (str): Suffix of images. Default: '.jpg'
ann_dir (str, optional): Path to annotation directory. Default: None
seg_map_suffix (str): Suffix of segmentation maps. Default: '.png'
split (str, optional): Split txt file. If split is specified, only
file with suffix in the splits will be loaded. Otherwise, all
images in img_dir/ann_dir will be loaded. Default: None
data_root (str, optional): Data root for img_dir/ann_dir. Default:
None.
test_mode (bool): If test_mode=True, gt wouldn't be loaded.
ignore_index (int): The label index to be ignored. Default: 255
reduce_zero_label (bool): Whether to mark label zero as ignored.
Default: False
classes (str | Sequence[str], optional): Specify classes to load.
If is None, ``cls.CLASSES`` will be used. Default: None.
palette (Sequence[Sequence[int]]] | np.ndarray | None):
The palette of segmentation map. If None is given, and
self.PALETTE is None, random palette will be generated.
Default: None
"""
CLASSES = None
PALETTE = None
def __init__(self,
pipeline, # 见文章:M2MRF配置信息
img_dir, # 'image/train'
img_suffix='.jpg', # '.jpg'
ann_dir=None, # 'label/train/annotations'
seg_map_suffix='.png', # '.png'
split=None, # None
data_root=None, # '/home/***/python/pytorch/M2MRF-Lesion-Segmentation/data/IDRID_h512'
test_mode=False, # False
ignore_index=255, # 255
reduce_zero_label=False, # False
classes=None, # ['bg', 'EX', 'HE', 'SE', 'MA']
palette=None): # [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128]]
self.pipeline = Compose(pipeline) # 数据处理方式,见文章:M2MRF配置信息
self.img_dir = img_dir
self.img_suffix = img_suffix
self.ann_dir = ann_dir
self.seg_map_suffix = seg_map_suffix
self.split = split
self.data_root = data_root
self.test_mode = test_mode
self.ignore_index = ignore_index
self.reduce_zero_label = reduce_zero_label
self.label_map = None
self.CLASSES, self.PALETTE = self.get_classes_and_palette(
classes, palette)
# join paths if data_root is specified:设置绝对路径
if self.data_root is not None: # True
if not osp.isabs(self.img_dir):
self.img_dir = osp.join(self.data_root, self.img_dir)
if not (self.ann_dir is None or osp.isabs(self.ann_dir)):
self.ann_dir = osp.join(self.data_root, self.ann_dir)
if not (self.split is None or osp.isabs(self.split)):
self.split = osp.join(self.data_root, self.split) # None
# load annotations:载入所有训练图片以及掩码数据
self.img_infos = self.load_annotations(self.img_dir, self.img_suffix,
self.ann_dir,
self.seg_map_suffix, self.split)
# 跳转到1.(1)
def __len__(self):
"""Total number of samples of data."""
return len(self.img_infos)
def load_annotations(self, img_dir, img_suffix, ann_dir, seg_map_suffix,
split):
"""Load annotation from directory.
Args:
img_dir (str): Path to image directory
img_suffix (str): Suffix of images.
ann_dir (str|None): Path to annotation directory.
seg_map_suffix (str|None): Suffix of segmentation maps.
split (str|None): Split txt file. If split is specified, only file
with suffix in the splits will be loaded. Otherwise, all images
in img_dir/ann_dir will be loaded. Default: None
Returns:
list[dict]: All image info of dataset.
"""
img_infos = []
if split is not None:
with open(split) as f:
for line in f:
img_name = line.strip()
img_info = dict(filename=img_name + img_suffix)
if ann_dir is not None:
seg_map = img_name + seg_map_suffix
img_info['ann'] = dict(seg_map=seg_map)
img_infos.append(img_info)
else:
for img in mmcv.scandir(img_dir, img_suffix, recursive=True):
img_info = dict(filename=img)
if ann_dir is not None:
seg_map = img.replace(img_suffix, seg_map_suffix)
img_info['ann'] = dict(seg_map=seg_map)
img_infos.append(img_info)
print_log(f'Loaded {len(img_infos)} images', logger=get_root_logger())
return img_infos
def get_ann_info(self, idx):
"""Get annotation by index.
Args:
idx (int): Index of data.
Returns:
dict: Annotation info of specified index.
"""
return self.img_infos[idx]['ann']
def pre_pipeline(self, results):
"""Prepare results dict for pipeline."""
results['seg_fields'] = []
results['img_prefix'] = self.img_dir
results['seg_prefix'] = self.ann_dir
if self.custom_classes:
results['label_map'] = self.label_map
def __getitem__(self, idx):
"""Get training/test data after pipeline.
Args:
idx (int): Index of data.
Returns:
dict: Training/test data (with annotation if `test_mode` is set
False).
"""
if self.test_mode:
return self.prepare_test_img(idx)
else:
return self.prepare_train_img(idx)
def prepare_train_img(self, idx):
"""Get training data and annotations after pipeline.
Args:
idx (int): Index of data.
Returns:
dict: Training data and annotation after pipeline with new keys
introduced by pipeline.
"""
img_info = self.img_infos[idx]
ann_info = self.get_ann_info(idx)
results = dict(img_info=img_info, ann_info=ann_info)
self.pre_pipeline(results)
return self.pipeline(results)
def prepare_test_img(self, idx):
"""Get testing data after pipeline.
Args:
idx (int): Index of data.
Returns:
dict: Testing data after pipeline with new keys intorduced by
piepline.
"""
img_info = self.img_infos[idx]
results = dict(img_info=img_info)
self.pre_pipeline(results)
return self.pipeline(results)
def format_results(self, results, **kwargs):
"""Place holder to format result to dataset specific output."""
pass
def get_gt_seg_maps(self):
"""Get ground truth segmentation maps for evaluation."""
gt_seg_maps = []
for img_info in self.img_infos:
seg_map = osp.join(self.ann_dir, img_info['ann']['seg_map'])
gt_seg_map = mmcv.imread(
seg_map, flag='unchanged', backend='pillow')
# modify if custom classes
if self.label_map is not None:
for old_id, new_id in self.label_map.items():
gt_seg_map[gt_seg_map == old_id] = new_id
if self.reduce_zero_label:
# avoid using underflow conversion
gt_seg_map[gt_seg_map == 0] = 255
gt_seg_map = gt_seg_map - 1
gt_seg_map[gt_seg_map == 254] = 255
gt_seg_maps.append(gt_seg_map)
return gt_seg_maps
def get_classes_and_palette(self, classes=None, palette=None):
"""Get class names of current dataset.
Args:
classes (Sequence[str] | str | None): If classes is None, use
default CLASSES defined by builtin dataset. If classes is a
string, take it as a file name. The file contains the name of
classes where each line contains one class name. If classes is
a tuple or list, override the CLASSES defined by the dataset.
palette (Sequence[Sequence[int]]] | np.ndarray | None):
The palette of segmentation map. If None is given, random
palette will be generated. Default: None
"""
if classes is None:
self.custom_classes = False
return self.CLASSES, self.PALETTE
self.custom_classes = True
if isinstance(classes, str):
# take it as a file path
class_names = mmcv.list_from_file(classes)
elif isinstance(classes, (tuple, list)):
class_names = classes
else:
raise ValueError(f'Unsupported type {type(classes)} of classes.')
if self.CLASSES:
if not set(classes).issubset(self.CLASSES):
raise ValueError('classes is not a subset of CLASSES.')
# dictionary, its keys are the old label ids and its values
# are the new label ids.
# used for changing pixel labels in load_annotations.
self.label_map = {}
for i, c in enumerate(self.CLASSES):
if c not in class_names:
self.label_map[i] = -1
else:
self.label_map[i] = classes.index(c)
palette = self.get_palette_for_custom_classes(class_names, palette)
return class_names, palette
def get_palette_for_custom_classes(self, class_names, palette=None):
if self.label_map is not None:
# return subset of palette
palette = []
for old_id, new_id in sorted(
self.label_map.items(), key=lambda x: x[1]):
if new_id != -1:
palette.append(self.PALETTE[old_id])
palette = type(self.PALETTE)(palette)
elif palette is None:
if self.PALETTE is None:
palette = np.random.randint(0, 255, size=(len(class_names), 3))
else:
palette = self.PALETTE
return palette
def evaluate(self, results, metric='mIoU', logger=None, **kwargs):
"""Evaluate the dataset.
Args:
results (list): Testing results of the dataset.
metric (str | list[str]): Metrics to be evaluated.
logger (logging.Logger | None | str): Logger used for printing
related information during evaluation. Default: None.
Returns:
dict[str, float]: Default metrics.
"""
if not isinstance(metric, str):
assert len(metric) == 1
metric = metric[0]
allowed_metrics = ['mIoU']
if metric not in allowed_metrics:
raise KeyError('metric {} is not supported'.format(metric))
eval_results = {}
gt_seg_maps = self.get_gt_seg_maps()
if self.CLASSES is None:
num_classes = len(
reduce(np.union1d, [np.unique(_) for _ in gt_seg_maps]))
else:
num_classes = len(self.CLASSES)
all_acc, acc, iou = mean_iou(
results, gt_seg_maps, num_classes, ignore_index=self.ignore_index)
summary_str = ''
summary_str += 'per class results:\n'
line_format = '{:<15} {:>10} {:>10}\n'
summary_str += line_format.format('Class', 'IoU', 'Acc')
if self.CLASSES is None:
class_names = tuple(range(num_classes))
else:
class_names = self.CLASSES
for i in range(num_classes):
iou_str = '{:.2f}'.format(iou[i] * 100)
acc_str = '{:.2f}'.format(acc[i] * 100)
summary_str += line_format.format(class_names[i], iou_str, acc_str)
summary_str += 'Summary:\n'
line_format = '{:<15} {:>10} {:>10} {:>10}\n'
summary_str += line_format.format('Scope', 'mIoU', 'mAcc', 'aAcc')
iou_str = '{:.2f}'.format(np.nanmean(iou) * 100)
acc_str = '{:.2f}'.format(np.nanmean(acc) * 100)
all_acc_str = '{:.2f}'.format(all_acc * 100)
summary_str += line_format.format('global', iou_str, acc_str,
all_acc_str)
print_log(summary_str, logger)
eval_results['mIoU'] = np.nanmean(iou)
eval_results['mAcc'] = np.nanmean(acc)
eval_results['aAcc'] = all_acc
return eval_results
1.(1)
函数main:
从if len(cfg.workflow) == 2:开始看
datasets = [build_dataset(cfg.data.train)]
if len(cfg.workflow) == 2: # cfg.workflow=1:Flase
val_dataset = copy.deepcopy(cfg.data.val)
val_dataset.pipeline = cfg.data.train.pipeline
datasets.append(build_dataset(val_dataset))
if cfg.checkpoint_config is not None: # Ture
'''
save mmseg version, config file content and class names in
checkpoints as meta data
'''
cfg.checkpoint_config.meta = dict(
mmseg_version=f'{__version__}+{get_git_hash()[:7]}',
config=cfg.pretty_text,
CLASSES=datasets[0].CLASSES,
PALETTE=datasets[0].PALETTE)
# add an attribute for visualization convenience
model.CLASSES = datasets[0].CLASSES # ['bg', 'EX', 'HE', 'SE', 'MA']
# 跳到 1.1.小节
train_segmentor(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
1.1. 函数train_segmentor()
函数train_segmentor:
def train_segmentor(model,
dataset,
cfg,
distributed=False,
validate=False,
timestamp=None,
meta=None):
"""Launch segmentor training."""
logger = get_root_logger(cfg.log_level)
# prepare data loaders
dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
# 跳转到1.1.1小节
data_loaders = [
build_dataloader(
ds,
cfg.data.samples_per_gpu, # 1
cfg.data.workers_per_gpu, # 1
# cfg.gpus will be ignored if distributed
len(cfg.gpu_ids), # 2
dist=distributed, # False
seed=cfg.seed, # None
drop_last=True) for ds in dataset
]
# put model on gpus
if distributed:
find_unused_parameters = cfg.get('find_unused_parameters', False)
# Sets the `find_unused_parameters` parameter in
# torch.nn.parallel.DistributedDataParallel
model = MMDistributedDataParallel(
model.cuda(),
device_ids=[torch.cuda.current_device()],
broadcast_buffers=False,
find_unused_parameters=find_unused_parameters)
else:
model = MMDataParallel(
model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)
# build runner
optimizer = build_optimizer(model, cfg.optimizer)
if cfg.get('runner') is None:
cfg.runner = {'type': 'IterBasedRunner', 'max_iters': cfg.total_iters}
warnings.warn(
'config is now expected to have a `runner` section, '
'please set `runner` in your config.', UserWarning)
runner = build_runner(
cfg.runner,
default_args=dict(
model=model,
batch_processor=None,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta))
# register hooks
runner.register_training_hooks(cfg.lr_config, cfg.optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# an ugly walkaround to make the .log and .log.json filenames the same
runner.timestamp = timestamp
# register eval hooks
if validate:
val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
val_dataloader = build_dataloader(
val_dataset,
samples_per_gpu=1,
workers_per_gpu=cfg.data.workers_per_gpu,
dist=distributed,
shuffle=False)
eval_cfg = cfg.get('evaluation', {})
eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
eval_hook = DistEvalHook if distributed else EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
runner.run(data_loaders, cfg.workflow)
1.1.1. 函数build_dataloader()
函数build_dataloader:
def build_dataloader(dataset,
samples_per_gpu, # 1
workers_per_gpu, # 1
num_gpus=1, # 1
dist=True, # False
shuffle=True, # Ture
seed=None, # None
drop_last=False, # True
pin_memory=True, # True
dataloader_type='PoolDataLoader', # 'PoolDataLoader'
**kwargs): # {}
"""Build PyTorch DataLoader.
In distributed training, each GPU/process has a dataloader.
In non-distributed training, there is only one dataloader for all GPUs.
Args:
dataset (Dataset): A PyTorch dataset.
samples_per_gpu (int): Number of training samples on each GPU, i.e.,
batch size of each GPU.
workers_per_gpu (int): How many subprocesses to use for data loading
for each GPU.
num_gpus (int): Number of GPUs. Only used in non-distributed training.
dist (bool): Distributed training/test or not. Default: True.
shuffle (bool): Whether to shuffle the data at every epoch.
Default: True.
seed (int | None): Seed to be used. Default: None.
drop_last (bool): Whether to drop the last incomplete batch in epoch.
Default: False
pin_memory (bool): Whether to use pin_memory in DataLoader.
Default: True
dataloader_type (str): Type of dataloader. Default: 'PoolDataLoader'
kwargs: any keyword argument to be used to initialize DataLoader
Returns:
DataLoader: A PyTorch dataloader.
"""
rank, world_size = get_dist_info() # 0, 1
if dist: # False
sampler = DistributedSampler(
dataset, world_size, rank, shuffle=shuffle)
shuffle = False
batch_size = samples_per_gpu
num_workers = workers_per_gpu
else:
sampler = None
batch_size = num_gpus * samples_per_gpu # 1*1=1
num_workers = num_gpus * workers_per_gpu # 1
init_fn = partial( # None
worker_init_fn, num_workers=num_workers, rank=rank,
seed=seed) if seed is not None else None
assert dataloader_type in (
'DataLoader',
'PoolDataLoader'), f'unsupported dataloader {dataloader_type}'
if dataloader_type == 'PoolDataLoader': # True
dataloader = PoolDataLoader
elif dataloader_type == 'DataLoader':
dataloader = DataLoader
data_loader = dataloader(
dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers,
collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
pin_memory=pin_memory,
shuffle=shuffle,
worker_init_fn=init_fn,
drop_last=drop_last,
**kwargs)
return data_loader
# 跳转到 1.1.(1)函数train_segmentor
1.1.(1)
函数train_segmentor:
从if distributed:开始看
def train_segmentor(model,
dataset,
cfg,
distributed=False,
validate=False,
timestamp=None,
meta=None):
"""Launch segmentor training."""
logger = get_root_logger(cfg.log_level)
# prepare data loaders
dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
# 跳转到1.1.1小节
data_loaders = [
build_dataloader(
ds,
cfg.data.samples_per_gpu, # 1
cfg.data.workers_per_gpu, # 1
# cfg.gpus will be ignored if distributed
len(cfg.gpu_ids), # 2
dist=distributed, # False
seed=cfg.seed, # None
drop_last=True) for ds in dataset
]
# put model on gpus
if distributed: # False
find_unused_parameters = cfg.get('find_unused_parameters', False)
# Sets the `find_unused_parameters` parameter in
# torch.nn.parallel.DistributedDataParallel
model = MMDistributedDataParallel(
model.cuda(),
device_ids=[torch.cuda.current_device()],
broadcast_buffers=False,
find_unused_parameters=find_unused_parameters)
# 执行else
else:
model = MMDataParallel(
model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)
# build runner
optimizer = build_optimizer(model, cfg.optimizer) # SGD
if cfg.get('runner') is None: # False
cfg.runner = {'type': 'IterBasedRunner', 'max_iters': cfg.total_iters}
warnings.warn(
'config is now expected to have a `runner` section, '
'please set `runner` in your config.', UserWarning)
runner = build_runner(
cfg.runner,
default_args=dict(
model=model,
batch_processor=None,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta))
# register hooks
runner.register_training_hooks(cfg.lr_config, cfg.optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# an ugly walkaround to make the .log and .log.json filenames the same
runner.timestamp = timestamp
# register eval hooks
if validate:
val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
val_dataloader = build_dataloader(
val_dataset,
samples_per_gpu=1,
workers_per_gpu=cfg.data.workers_per_gpu,
dist=distributed,
shuffle=False)
eval_cfg = cfg.get('evaluation', {}) # {'interval': 40000, 'metric': 'mIoU'}
eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner' # False
eval_hook = DistEvalHook if distributed else EvalHook # EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
# 跳转到1.1.2小节def train
runner.run(data_loaders, cfg.workflow)
1.1.2. 函数train()
函数train:在hrnet_m2mrf.py文件中
def train(self, mode=True):
"""Convert the model into training mode whill keeping the normalization
layer freezed."""
super(HRNet_M2MRF, self).train(mode)
if mode and self.norm_eval: # Flase
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()
# 跳出if语句后,后面进入mmcv库(这个地方就不详细说明),直接从模型前向传播开始
3. 模型的forward过程
HRNet_M2MRF-C前向传播过程:这地方可以对照配置信息-----在文章 《M2MRF配置信息》 可查看
def forward(self, x):
"""Forward function."""
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.norm2(x)
x = self.relu(x)
x = self.layer1(x)
x_list = []
for i in range(self.stage2_cfg['num_branches']):
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
y_list = self.stage2(x_list)
x_list = []
for i in range(self.stage3_cfg['num_branches']):
if self.transition2[i] is not None:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
y_list = self.stage3(x_list)
x_list = []
for i in range(self.stage4_cfg['num_branches']):
if self.transition3[i] is not None:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
y_list = self.stage4(x_list)
return y_list
4. 下采样class M2MRF()
类M2MRF:下采样2倍
从forward开始看
class M2MRF(nn.Module):
def __init__(self,
scale_factor, # 0.5 下采样2倍
in_channels, # 输入通道
out_channels, # 输出通道
patch_size=8, # 滑动窗口大小
encode_channels_rate=4, # 压缩通道的缩小因子,默认 4
fc_channels_rate=64, # m2mrf中间的线性映射的第一层输出通道(第二层输入通道),默认64
version=0, # 默认值
groups=1): # Conv1d的参数,默认为 1
super(M2MRF, self).__init__()
self.scale_factor = scale_factor
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.size = patch_size
self.patch_size = patch_size
self.version = version
if encode_channels_rate is not None: # 默认为4:Ture
self.encode_channels = int(in_channels / encode_channels_rate) # C/4
else:
raise NotImplementedError
'''fc_channels: 是m2mrf中间的线性映射的第一层输出通道(第二层输入通道)
猜想fc_channels_rate与patch_size的关系: fc_channels_rate=patch_size*patch_size
'''
if fc_channels_rate is not None: # 默认为64:Ture
# self.fc_channels = int(8* 8 * (C/4) / 64) = C/4
self.fc_channels = int(self.size * self.size * self.encode_channels / fc_channels_rate) # C/4
else:
self.fc_channels = self.encode_channels # C/4
# 通道压缩
self.sample_encode_conv = nn.Conv2d(self.in_channels, self.encode_channels, kernel_size=1, stride=1, padding=0)
#
self.sample = M2MRF_Module(self.scale_factor, self.encode_channels, self.fc_channels,
size=self.size, groups=self.groups)
self.sample_decode_conv = nn.Conv2d(self.encode_channels, self.out_channels, kernel_size=1, stride=1, padding=0)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
xavier_init(m, distribution='uniform')
def pad_input(self, x): # (B,C,H,W)=(B,256,128,128)
b, c, h, w = x.shape # B,C,H,W
fold_h, fold_w = h, w # H,W
# self.patch_size=8,输入x如果不能被patch_size整除就补0
if h % self.patch_size > 0:
fold_h = h + (self.patch_size - h % self.patch_size)
if w % self.patch_size > 0:
fold_w = w + (self.patch_size - w % self.patch_size)
x = F.pad(x, [0, fold_w - w, 0, fold_h - h], mode='constant', value=0)
'''下采样
缩放因子:self.scale_factor=0.5
使用max图像尺寸最小缩放到 1
'''
out_h = max(int(h * self.scale_factor), 1) # H/2
out_w = max(int(w * self.scale_factor), 1) # W/2
return x, (out_h, out_w)
def forward(self, x): # (B,C,H,W)=(B,256,128,128)
'''函数pad_input:
(1)根据patch_size对x进行padding操作
(2)根据scale_factor对x进行采样操作
(3)返回: padding后的:x, 采样后的高和宽:(out_h, out_w)
'''# 这里假设x能被patch_size整除,即x的shape不变
x, out_shape = self.pad_input(x) # (B,C,H,W); (H/2, W/2)
'''sample_encode_conv:
通道压缩:默认为in_channels/4
'''
# 卷积层Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1)):特征图的H和W不变,只改变通道数 C->C1
x = self.sample_encode_conv(x) # (B,C1,H,W)
# 接下来跳转到4.1小节:下采样class M2MRF_Module
'''M2MRF_Module:
'''
x = self.sample(x)
x = self.sample_decode_conv(x)
x = x[:, :, :out_shape[0], :out_shape[1]]
return x
4.1. 下采样class M2MRF_Module()
类M2MRF_Module:
从forward开始看
class M2MRF_Module(nn.Module):
def __init__(self,
scale_factor,
encode_channels,
fc_channels,
size,
groups=1):
super(M2MRF_Module, self).__init__()
self.scale_factor = scale_factor
self.encode_channels = encode_channels
self.fc_channels = fc_channels
self.size = size
self.groups = groups
self.unfold_params = dict(kernel_size=self.size,
dilation=1, padding=0, stride=self.size)
self.fold_params = dict(kernel_size=int(self.size * self.scale_factor),
dilation=1, padding=0, stride=int(self.size * scale_factor))
self.sample_fc = nn.Conv1d(
self.size * self.size * self.encode_channels,
self.fc_channels,
groups=self.groups,
kernel_size=1)
self.sample_fc1 = nn.Conv1d(
self.fc_channels,
int(self.size * self.size * self.scale_factor * self.scale_factor * self.encode_channels),
groups=self.groups,
kernel_size=1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
xavier_init(m, distribution='uniform')
def forward(self, x): # (B,C1,H,W)
n, c, h, w = x.shape # B,C1,H,W
'''nn.Unfold(kernel_size,dilation=1,paddding=0,stride):
在图片上进行滑动的窗口操作:将图片切割成patch,而不需要进行卷积核和图片值的卷积乘法操作。
该函数是从一个batch图片中,提取出滑动的局部区域块,也就是卷积操作中的提取kernel filter对应的滑动窗口。
(1)输入是(B,C,H,W),其中B为batch-size,C是channel的个数。
(2)输出是(B,Cxkernel_size[0]xkernel_size[1],L)
其中L是特征图或者图片的尺寸根据kernel_size的长宽滑动裁剪后得到的多个patch的数量。
'''# nn.Unfold(kernel_size=8,dilation=1,paddding=0,stride=8)
x = nn.Unfold(**self.unfold_params)(x) # (B,C1,H,W)->(B, C1*8*8, H/8 * W/8)
# 这里的size=8,即shape不变
x = x.view(n, c * self.size * self.size, -1) # (B, C1*8*8, H/8 * W/8)
# 卷积核Conv1d(4096, 64, kernel_size=(1,), stride=(1,)):卷积后的size不变,只改变通道数C1*8*8->fc_channels
x = self.sample_fc(x) # (B, C1, H/8 * W/8)
# 卷积核Conv1d(64, 1024, kernel_size=(1,), stride=(1,)):卷积后的size不变,只改变通道数fc_channels->C1*16
x = self.sample_fc1(x) # (B, C1*16 , H/8 * W/8)=(B,1024,256)
'''nn.Fold: nn.Unfold的逆操作,上面1024是64的16倍,故这里的kernel_size=stride=4
'''# nn.Fold(output_size=(H/2, W/2),kernel_size=4,dilation=1,padding=0,stride=4)
x = nn.Fold((int(h * self.scale_factor), int(w * self.scale_factor)), **self.fold_params)(x) # (B,C1,H/2,W/2)
return x # (B,C1,H/2,W/2)
# 到这里M2MRF_Module结束,即4.中的x = self.sample(x)执行结束,接下来跳转到4.(1)
4.(1)
类M2MRF:简洁起见,只显示前向传播部分
从forward中的x = self.sample_decode_conv(x)开始看
def forward(self, x): # (B,C,H,W)
'''函数pad_input:
(1)根据patch_size对x进行padding操作
(2)根据scale_factor对x进行采样操作
(3)返回: padding后的:x, 采样后的高和宽:(out_h, out_w)
'''# 这里假设x能被patch_size整除,即x的shape不变
x, out_shape = self.pad_input(x) # (B,C,H,W); (out_h, out_w)=(H/2, W/2)
# 卷积层(kernel_size=1, stride=1, padding=0):特征图的H和W不变,只改变通道数 C->C1
x = self.sample_encode_conv(x) # (B,C1,H,W)
# 接下来跳转到4.1小节class M2MRF_Module
'''M2MRF_Module:
'''
x = self.sample(x) # (B,C1,H/2,W/2)
# sample_decode_conv=Conv2d(64, 96, kernel_size=(1, 1), stride=(1, 1)): 只改变通道数: C1->C2
x = self.sample_decode_conv(x) # (B,C1,H/2,W/2)->(B,C2,H/2,W/2)
# 上面已经证明: out_shape[0]=H/2, out_shape[1]=W/2
x = x[:, :, :out_shape[0], :out_shape[1]] # (B, C2, out_h, out_w)=(B, C2, H/2, W/2)
return x # (B, C2, H/2, W/2)
'''到这里完成class M2MRF结束
x.shape: (B,C,H,W)->(B, C2, H/2, W/2): (B,256,128,128)->(B,96,64,64)
实现了2倍下采样
建议:在M2MRF后面加上
(1): BatchNorm2d(C2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
'''
下面在走一遍上采样的流程
5. 上采样class M2MRF()
类M2MRF:上采样2倍
从forward开始看
class M2MRF(nn.Module):
def __init__(self,
scale_factor, # 2
in_channels,
out_channels,
patch_size=8,
encode_channels_rate=4, # 4
fc_channels_rate=64, # 64
version=0,
groups=1):
super(M2MRF, self).__init__()
self.scale_factor = scale_factor
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.size = patch_size
self.patch_size = patch_size
self.version = version
if encode_channels_rate is not None:
self.encode_channels = int(in_channels / encode_channels_rate)
else:
raise NotImplementedError
if fc_channels_rate is not None:
self.fc_channels = int(self.size * self.size * self.encode_channels / fc_channels_rate)
else:
self.fc_channels = self.encode_channels
self.sample_encode_conv = nn.Conv2d(self.in_channels, self.encode_channels, kernel_size=1, stride=1, padding=0)
self.sample = M2MRF_Module(self.scale_factor, self.encode_channels, self.fc_channels,
size=self.size, groups=self.groups)
self.sample_decode_conv = nn.Conv2d(self.encode_channels, self.out_channels, kernel_size=1, stride=1, padding=0)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
xavier_init(m, distribution='uniform')
def pad_input(self, x): # (B,C,H,W)=(B,48,64,64)
b, c, h, w = x.shape # B,C,H,W
fold_h, fold_w = h, w # H,W
# self.patch_size=8,输入x如果不能被patch_size整除就补0
# 这里可以整除
if h % self.patch_size > 0:
fold_h = h + (self.patch_size - h % self.patch_size)
if w % self.patch_size > 0:
fold_w = w + (self.patch_size - w % self.patch_size)
# 因为可以整除,故x的shape不变
x = F.pad(x, [0, fold_w - w, 0, fold_h - h], mode='constant', value=0)
'''下采样
缩放因子:self.scale_factor=0.5
使用max图像尺寸最小缩放到 1
'''
out_h = max(int(h * self.scale_factor), 1) # 2H
out_w = max(int(w * self.scale_factor), 1) # 2W
return x, (out_h, out_w)
def forward(self, x): # (B,C,H,W)=(B,48,64,64)
'''函数pad_input:
(1)根据patch_size对x进行padding操作
(2)根据scale_factor对x进行采样操作
(3)返回: padding后的:x, 采样后的高和宽:(out_h, out_w)
'''# 这里假设x能被patch_size整除,即x的shape不变
x, out_shape = self.pad_input(x) # (B,C,H,W); (2H, 2W)
# 卷积层Conv2d(48, 12, kernel_size=(1, 1), stride=(1, 1)):特征图的H和W不变,只改变通道数 C->C1
x = self.sample_encode_conv(x) # (B,C1,H,W)
# 接下来跳转到5.1小节: 上采样class M2MRF_Module
'''M2MRF_Module:
'''
x = self.sample(x)
x = self.sample_decode_conv(x)
x = x[:, :, :out_shape[0], :out_shape[1]]
return x
5.1. 上采样class M2MRF_Module()
类M2MRF_Module:2倍上采样
从forward开始看
class M2MRF_Module(nn.Module):
def __init__(self,
scale_factor,
encode_channels,
fc_channels,
size,
groups=1):
super(M2MRF_Module, self).__init__()
self.scale_factor = scale_factor
self.encode_channels = encode_channels
self.fc_channels = fc_channels
self.size = size
self.groups = groups
self.unfold_params = dict(kernel_size=self.size,
dilation=1, padding=0, stride=self.size)
self.fold_params = dict(kernel_size=int(self.size * self.scale_factor),
dilation=1, padding=0, stride=int(self.size * scale_factor))
self.sample_fc = nn.Conv1d(
self.size * self.size * self.encode_channels,
self.fc_channels,
groups=self.groups,
kernel_size=1)
self.sample_fc1 = nn.Conv1d(
self.fc_channels,
int(self.size * self.size * self.scale_factor * self.scale_factor * self.encode_channels),
groups=self.groups,
kernel_size=1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
xavier_init(m, distribution='uniform')
def forward(self, x): # (B,C1,H,W)=(B,12,64,64)
n, c, h, w = x.shape # B,C1,H,W
'''nn.Unfold(kernel_size,dilation=1,paddding=0,stride):
在图片上进行滑动的窗口操作:将图片切割成patch,而不需要进行卷积核和图片值的卷积乘法操作。
该函数是从一个batch图片中,提取出滑动的局部区域块,也就是卷积操作中的提取kernel filter对应的滑动窗口。
(1)输入是(B,C,H,W),其中B为batch-size,C是channel的个数。
(2)输出是(B,Cxkernel_size[0]xkernel_size[1],L)
其中L是特征图或者图片的尺寸根据kernel_size的长宽滑动裁剪后得到的多个patch的数量。
'''# nn.Unfold(kernel_size=8,dilation=1,paddding=0,stride=8)
x = nn.Unfold(**self.unfold_params)(x) # (B,C1,H,W)->(B, C1*8*8, H/8 * W/8)
# 这里的size=8,即shape不变
x = x.view(n, c * self.size * self.size, -1) # (B, C1*8*8, H/8 * W/8)
# 卷积核Conv1d(768, 12, kernel_size=(1,), stride=(1,)):卷积后的size不变,只改变通道数C1*8*8->C1
x = self.sample_fc(x) # (B, C1, H/8 * W/8)
# 卷积核Conv1d(12, 3072, kernel_size=(1,), stride=(1,)):卷积后的size不变,只改变通道数C1->C1*256
x = self.sample_fc1(x) # (B, C1*256 , H/8 * W/8)=(B,3072,64)
'''nn.Fold: nn.Unfold的逆操作,上面3072是12的256倍,故这里的kernel_size=stride=16
'''# nn.Fold(output_size=(2H, 2W),kernel_size=16,dilation=1,padding=0,stride=16)
x = nn.Fold((int(h * self.scale_factor), int(w * self.scale_factor)), **self.fold_params)(x) # (B,C1,2H,2W)
return x # (B,C1,2H,2W)
# 到这里M2MRF_Module结束,即4.上采样.中的x = self.sample(x)执行结束,接下来跳转到5.(1)
5.(1)
类M2MRF:上采样2倍
从forward中的x = self.sample_decode_conv(x)开始看
def forward(self, x): # (B,C,H,W)=(B,48,64,64)
'''函数pad_input:
(1)根据patch_size对x进行padding操作
(2)根据scale_factor对x进行采样操作
(3)返回: padding后的:x, 采样后的高和宽:(out_h, out_w)
'''# 这里假设x能被patch_size整除,即x的shape不变
x, out_shape = self.pad_input(x) # (B,C,H,W); (2H, 2W)
# 卷积层Conv2d(48, 12, kernel_size=(1, 1), stride=(1, 1)):特征图的H和W不变,只改变通道数 C->C1
x = self.sample_encode_conv(x) # (B,C1,H,W)
# 接下来跳转到4.上采样.1小节class M2MRF_Module
'''M2MRF_Module:
'''
x = self.sample(x) # (B,C1,2H,2W)
# sample_decode_conv=Conv2d(12, 48, kernel_size=(1, 1), stride=(1, 1)): 只改变通道数: C1->C
x = self.sample_decode_conv(x) # (B,C1,2H,2W)->(B,C,2H,2W)=(B,48,128,128)
# 上面已经证明: out_shape[0]=2H, out_shape[1]=2W
x = x[:, :, :out_shape[0], :out_shape[1]] # (B, C, out_h, out_w)=(B, C, 2H, 2W)
return x # (B, C, 2H, 2W)
'''到这里完成class M2MRF结束
x.shape: (B,C,H,W)->(B, C, 2H, 2W):(B,48,64,64)->(B,48,128,128)
实现了2倍上采样
建议:在M2MRF后面加上
(1): BatchNorm2d(C2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
'''
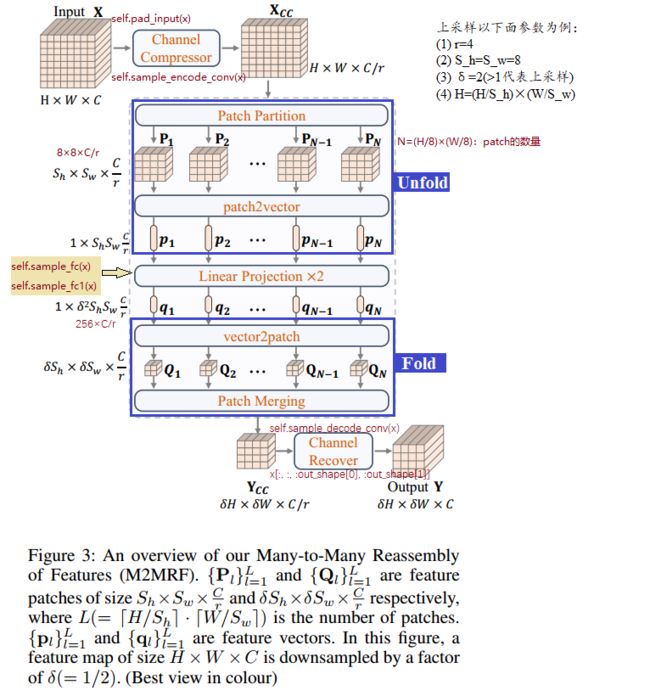
附录. 模型框架图