mysql索引分类
我们可以按照四个角度来分类索引。
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
1 按照数据结构分类
从数据结构的角度来看,MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
每一种存储引擎支持的索引类型不一定相同,我在表中总结了 MySQL 常见的存储引擎 InnoDB、MyISAM 和 Memory 分别支持的索引类型。
InnoDB 是在 MySQL 5.5 之后成为默认的 MySQL 存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
在创建表时,InnoDB 存储引擎会根据不同的场景选择不同的列作为聚簇索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key)
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key)
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key)
其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。创建的主键索引和二级索引默认使用的是 B+Tree 索引。
补充
2 按物理存储分类
从物理存储的角度来看,索引分为聚簇索引(主键索引)、二级索引(辅助索引)。
这两个区别在前面也提到了:
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
所以,在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引。如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表。
3 按字段特性分类
从字段特性的角度来看,索引分为主键索引、唯一索引、普通索引、前缀索引。
3.1 主键索引
主键索引就是建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
在创建表时,创建主键索引的方式如下:
CREATE TABLE table_name (
....
PRIMARY KEY (index_column_1) USING BTREE
);
3.2 唯一索引
唯一索引建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
在创建表时,创建唯一索引的方式如下:
CREATE TABLE table_name (
....
UNIQUE KEY(index_column_1,index_column_2,...)
);
建表后,如果要创建唯一索引,可以使用这面这条命令:
CREATE UNIQUE INDEX index_name
ON table_name(index_column_1,index_column_2,...);
3.3 普通索引
普通索引就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
在创建表时,创建普通索引的方式如下:
CREATE TABLE table_name (
....
INDEX(index_column_1,index_column_2,...)
);
建表后,如果要创建普通索引,可以使用这面这条命令:
CREATE INDEX index_name
ON table_name(index_column_1,index_column_2,...);
3.4 前缀索引
前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
在创建表时,创建前缀索引的方式如下:
CREATE TABLE table_name(
column_list,
INDEX(column_name(length))
);
建表后,如果要创建前缀索引,可以使用这面这条命令:
CREATE INDEX index_name
ON table_name(column_name(length));
4 按字段个数分类
从字段个数的角度来看,索引分为单列索引、联合索引(复合索引)。
- 建立在单列上的索引称为单列索引,比如主键索引;
- 建立在多列上的索引称为联合索引;
4.1 联合索引
通过将多个字段组合成一个索引,该索引就被称为联合索引。
比如,将商品表中的 product_no 和 name 字段组合成联合索引(product_no, name),创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);
联合索引(product_no, name) 的 B+Tree 示意图如下:
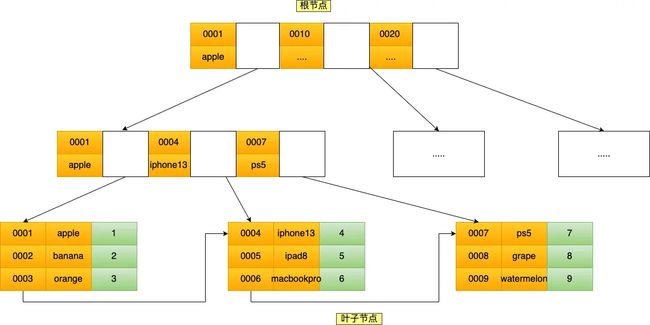
可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。当在联合索引查询数据时,先按 product_no 字段比较,在 product_no 相同的情况下再按 name 字段比较。
也就是说,联合索引查询的 B+Tree 是先按 product_no 进行排序,然后再 product_no 相同的情况再按 name 字段排序。
因此,使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以匹配上联合索引:
- where a=1;
- where a=1 and b=2 and c=3;
- where a=1 and b=2;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
- where b=2;
- where c=3;
- where b=2 and c=3;
上面这些查询条件之所以会失效,是因为(a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。
补充
https://www.xiaolincoding.com/mysql/index/index_interview.html#按字段个数分类