oracle 拉链表如何分区,利用Hive实现数据仓库中的拉链表
拉链表介绍
在数据分析中,有时会需要维护一些历史状态,比如订单状态变化、评分变化等,为了保存下来这些状态变化的路径,可以通过拉链表实现
适用场景数据量比较大,但业务要求每次需要查询全量历史,每天存储一份全量数据太占用存储空间
记录变更不大,比如只有状态和更新时间有变动,其它字段都不变
实现思路通过在记录末尾增加start_date和end_date字段来实现
同一ID按时间排序后,如果有较新的记录,则当前记录的end_date等于较新记录的start_date-1,如果没有较新的记录,则当前记录的end_date等于一个默认值,比如99991231
拉链表示例
查询拉链表最新分区SELECT * from tmp_order_detail t WHERE dt = '20180104'
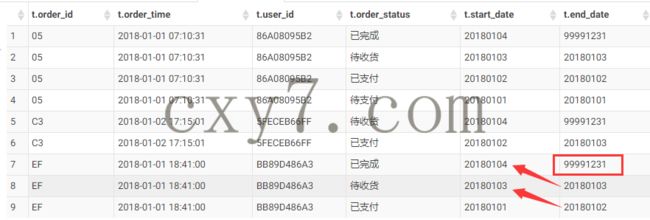
查询最新有效数据SELECT * from tmp_order_detail t WHERE dt = '20180104' AND t.end_date = '99991231't.order_idt.order_timet.user_idt.order_statust.start_datet.end_datet.dt1052018-01-01 07:10:3186A08095B2已完成201801049999123120180104
2C32018-01-02 17:15:015FECEB66FF待收货201801049999123120180104
3EF2018-01-01 18:41:00BB89D486A3已完成201801049999123120180104
查询20180103的历史快照数据SELECT * from tmp_order_detail t WHERE dt = '20180104' AND t.start_date <='20180103' AND t.end_date >= '20180103't.order_idt.order_timet.user_idt.order_statust.start_datet.end_datet.dt1052018-01-01 07:10:3186A08095B2待收货201801032018010320180104
2C32018-01-02 17:15:015FECEB66FF已支付201801022018010320180104
3EF2018-01-01 18:41:00BB89D486A3待收货201801032018010320180104
准备数据
创建Hive表CREATE EXTERNAL TABLE `tmp_order`(
`order_id` string COMMENT '订单ID',
`order_time` string COMMENT '下单时间',
`user_id` string COMMENT '用户ID',
`order_status` string COMMENT '订单状态')
PARTITIONED BY (
`dt` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION
'hdfs://ns1/tmp/order';
添加分区ALTER TABLE tmp_order ADD IF NOT EXISTS partition(dt='20180101') LOCATION '20180101';
ALTER TABLE tmp_order ADD IF NOT EXISTS partition(dt='20180102') LOCATION '20180102';
ALTER TABLE tmp_order ADD IF NOT EXISTS partition(dt='20180103') LOCATION '20180103';
上传文件
按以下方式组织HDFS上的数据[mapred@gateway2 ~]$ hdfs dfs -cat /tmp/order/20180101/20180101.txt
052018-01-01 07:10:3186A08095B2待支付20180101
EF2018-01-01 18:41:00BB89D486A3已支付20180101
[mapred@gateway2 ~]$ hdfs dfs -cat /tmp/order/20180102/20180102.txt
052018-01-01 07:10:3186A08095B2已支付20180102
C32018-01-02 17:15:015FECEB66FF已支付20180102
[mapred@gateway2 ~]$ hdfs dfs -cat /tmp/order/20180103/20180103.txt
052018-01-01 07:10:3186A08095B2待收货20180103
EF2018-01-01 18:41:00BB89D486A3待收货20180103
查看数据SELECT * from tmp_order t WHERE dt BETWEEN '20180101' AND '20180103't.order_idt.order_timet.user_idt.order_statust.dt1052018-01-01 07:10:3186A08095B2待支付20180101
2EF2018-01-01 18:41:00BB89D486A3已支付20180101
3052018-01-01 07:10:3186A08095B2已支付20180102
4C32018-01-02 17:15:015FECEB66FF已支付20180102
5052018-01-01 07:10:3186A08095B2待收货20180103
6EF2018-01-01 18:41:00BB89D486A3待收货20180103
数据说明订单ID下单时间用户ID订单状态分区key
order_idorder_timeuser_idorder_statusdt假定订单变化状态为:待支付→已支付→待收货→已完成,方便查看记录的变化
分区为天级别,所以会丢失一天之内的状态变化信息,不过对于一般的需求分析而言,这也已经足够了
生成拉链表
建立Hive表CREATE EXTERNAL TABLE `tmp_order_detail`(
`order_id` string COMMENT '订单ID',
`order_time` string COMMENT '下单时间',
`user_id` string COMMENT '用户ID',
`order_status` string COMMENT '订单状态',
`start_date` string COMMENT '开始生效日期',
`end_date` string COMMENT '失效日期')
PARTITIONED BY (
`dt` string)
STORED AS PARQUET
LOCATION
'hdfs://ns1/tmp/order_detail';
初始化第一个分区加载原始表所有数据,以分区key字段dt为开始生效日期
按start_date倒序排序后,取上一条记录的前一天为当前记录的失效日期
如果没有更新的记录,记失效日期为默认值99991231INSERT OVERWRITE TABLE tmp_order_detail PARTITION (dt='20180103')
SELECT
order_id,order_time,user_id,order_status,dt AS start_date,
regexp_replace (
split (
LAG (
date_add(
from_unixtime(
unix_timestamp(dt, 'yyyyMMdd')
),
- 1
),
1,
'9999-12-31 00:00:00'
) OVER (
PARTITION BY order_id
ORDER BY
dt DESC
),
' '
)[0], '-',
''
) AS end_date
FROM
tmp_order
WHERE dt BETWEEN '20180101' AND '20180103'
查看拉链表第一个分区SELECT * from tmp_order_detail t WHERE dt='20180103'
t.order_idt.order_timet.user_idt.order_statust.start_datet.end_datet.dt1052018-01-01 07:10:3186A08095B2待收货201801039999123120180103
2052018-01-01 07:10:3186A08095B2已支付201801022018010220180103
3052018-01-01 07:10:3186A08095B2待支付201801012018010120180103
4C32018-01-02 17:15:015FECEB66FF已支付201801029999123120180103
5EF2018-01-01 18:41:00BB89D486A3待收货201801039999123120180103
6EF2018-01-01 18:41:00BB89D486A3已支付201801012018010220180103
此处用到了Hive窗口函数LAG,关于该函数的使用可以参考《LAG用法》
此处使用LEAD函数也可以,不过需要更改排序方式
拉链表更新
添加20180104的数据ALTER TABLE tmp_order ADD IF NOT EXISTS partition(dt='20180104') LOCATION '20180104';[mapred@gateway2 ~]$ hdfs dfs -cat /tmp/order/20180104/20180104.txt
052018-01-01 07:10:3186A08095B2已完成20180104
C32018-01-02 17:15:015FECEB66FF待收货20180104
EF2018-01-01 18:41:00BB89D486A3已完成20180104
合并增量数据合并原始订单增量分区和拉链表前一个分区
按start_date倒序排序后,取上一条记录的前一天为当前记录的失效日期
如果没有更新的记录,记失效日期为默认值99991231INSERT OVERWRITE TABLE tmp_order_detail PARTITION (dt='20180104')
SELECT
order_id,order_time,user_id,order_status,start_date,
regexp_replace (
split (
LAG (
date_add(
from_unixtime(
unix_timestamp(start_date, 'yyyyMMdd')
),
- 1
),
1,
'9999-12-31 00:00:00'
) OVER (
PARTITION BY order_id
ORDER BY
start_date DESC
),
' '
)[0], '-',
''
) AS end_date
FROM
(
SELECT
order_id,order_time,user_id,order_status,dt AS start_date
FROM
tmp_order
WHERE dt = '20180104'
UNION ALL
SELECT
order_id,order_time,user_id,order_status,start_date
FROM
tmp_order_detail
WHERE dt = '20180103'
) tmp
查看拉链表的新分区SELECT * from tmp_order_detail t WHERE dt='20180104't.order_idt.order_timet.user_idt.order_statust.start_datet.end_datet.dt1052018-01-01 07:10:3186A08095B2已完成201801049999123120180104
2052018-01-01 07:10:3186A08095B2待收货201801032018010320180104
3052018-01-01 07:10:3186A08095B2已支付201801022018010220180104
4052018-01-01 07:10:3186A08095B2待支付201801012018010120180104
5C32018-01-02 17:15:015FECEB66FF待收货201801049999123120180104
6C32018-01-02 17:15:015FECEB66FF已支付201801022018010320180104
7EF2018-01-01 18:41:00BB89D486A3已完成201801049999123120180104
8EF2018-01-01 18:41:00BB89D486A3待收货201801032018010320180104
9EF2018-01-01 18:41:00BB89D486A3已支付201801012018010220180104
读后有收获可以支付宝请作者喝咖啡