试图一文彻底讲清 “精准测试”

在软件测试中,我们常常碰到两个基本问题(困难):
很难保障无漏测:我们做了大量测试,但不清楚测得怎样,对软件上线后会不会出问题,没有信心;
选择待执行的测试用例:面对大量的回归测试用例时,我们没有足够的时间完成测试,如何选择出有效的测试用例呢?虽然我们会有一些策略,如基于风险的测试策略、基于操作剖面的测试策略 或组合测试策略,但主要还是靠测试人员的经验,比较主观。
人们试图解决这样的基本问题,由此产生了“精准测试”。在敏捷开发模式下,开发节奏加快,测试资源反而比之前少了,这样的问题更突出了,因此我们更加关注 “精准测试”。
1. 什么是精准测试呢?
精准测试就是通过数据回答了两个基本问题:测得这样、要测什么,即精准测试是借助特定的算法、技术手段和工具,分析代码、程序运行过程、测试用例等及其之间关系,从而获取相关信息和知识,精准定位和优化测试范围(如精简测试用例),以精准的数据评估测试结果和产品质量,使整个测试过程更加高效、准确和可信,同时能有效地减少漏测风险,将测试成本降到最低。
精准测试是质量工程智能化建设的重要趋势,也是软件测试数字化的体现,让我们能够清楚地了解测试过程,达到我们所需要的、量化的测试目标(如测试覆盖率)。
2. 精准测试实现方法
实现精准测试,从原理看比较简单,关键要实现两项基本的工作:
能完成有效的代码依赖性分析,甚至扩展到业务依赖性分析,从而正确、精确识别每次代码修改所影响的代码范围,代码影响范围可以精确到类的方法、函数级或代码块;
建立代码和测试用例的映射关系,这样就可以根据识别对影响范围而推荐需要执行的测试用例。
如果要建立代码和测试用例的映射关系、或评测精准测试带来的效果,一般会借助代码的覆盖率分析来更好地了解测试用例执行了哪些代码,进一步明确哪些代码在测试执行中被覆盖、哪些代码在测试执行中没有被覆盖等。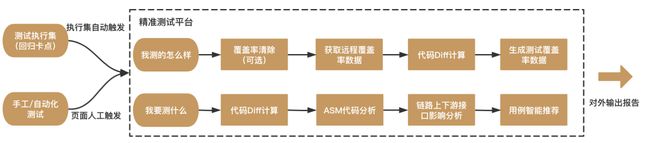
3. 精准测试实践
在精准测试实施实践中,需要借助一些开源工具或自己开发一些平台来实现上述的两项基本工作。例如,可以借助代码覆盖率监测平台,收集程序运行时的动态代码覆盖率数据,以此为基础来构建用例知识库;用开源的JVM-sandbox(https://github.com/alibaba/jvm-sandbox)可以录制真实的系统运行情况(即流量录制)。
针对人工执行的测试用例和自动化测试脚本,也会有不同的处理。例如,人工执行的测试用例录制会利用内嵌到客户端的SDK,提供UI界面供用户进行录制操作并完成数据清理、采集、上报,然后在服务端实时解析。自动化测试脚本就比较简单,可以一个一个用例执行,收集覆盖率数据,很容易建立代码和用例的关联关系。
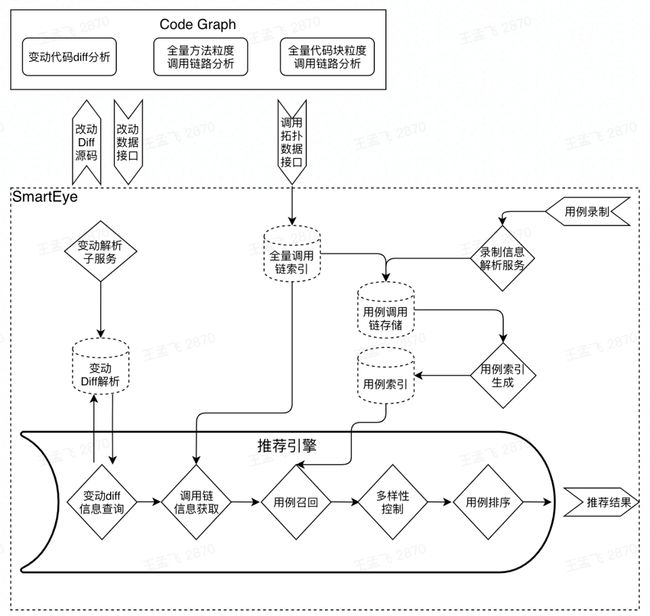
从代码层次的依赖性分析还可以扩展到调用链的分析,因为是在程序运行时所采集到的信息,更能真实反映代码的调用关系(依赖性),正像我们做代码依赖性分析时,从源代码上升到编译后的Binary字节码,更能真实反映方法/代码块调用关系。
还有,我们要为用例ID建立索引,提高用例推荐的效率。基于用例的关联方法(或代码块)、上下游调用链路以及对应覆盖率等信息,建设不同粒度不同版本的调用信息,提供测试用例索引服务、用例召回服务等。
在今天AI盛行的时代,我们自然可以引入知识图谱和机器学习算法进一步优化精准测试的效果。例如:
代码依赖关系结构可以通过图谱来存储,如“ (代码所属包)-[包含]->(文件)-[包含]->(函数)-[调用]->(函数)”这样的结构,在获取项目调用链原数据后,再深度遍历每一条调用链路采集每个包、文件、函数的对应关系,以及路径、所处位置、出参入参、注释、代码行等信息;
可以进一步采集“用例-函数调用链”权重,从而根据权重来推荐用例;
根据用例相似度可以排除一些相似度高的用例,如对所有用例进行分词、建立词库,使用tf-idf的方式计算用例与用例间的文本相似度,借助GCN(图卷积神经网络)计算用例相似性。
4. 常见问答
Q1:如何从0到1建设精准测试体系?
A1:可以基于Java的技术栈和相应的工具开始做、各个击破。先从开始先从覆盖率分析开发,了解测试用例的有效性,提升测试用例的质量和测试效率;然后再做代码依赖性分析,结合Code diff了解代码影响范围,慢慢建立代码和测试用例的依赖性关系,能做到比较精准、有效的测试;最后,向全自动化方式迈进,构建出高效的精准测试体系,即完成代码知识库、用例知识库的建设,完成流量录制、调用链自动分析、用例自动推荐和召回等工具平台的建设。
Q2:能否给出一套完整、详实、可复用的精准测试方案?想要了解更多的是可以用哪些开源的工具来构建这个精准测试的平台?如何形成工具链能够支持精准测试的快速实施?
A2::前面介绍的字节跳动、优酷度已实现完整的落地方案,这得力于流量采集和代码分析这两个基础能力,流量采集可以基于开源的JVM-sandbox来做,虽然需要二次开发。代码分析,一方面可以借助code diff工具了解代码的变更,另方面可以借助AST类工具(Babel、jscodeshift以及esprima、recast、acorn、estraverse等)、覆盖率分析工具(如JaCoCo)、Java Dependence Analysis(JDA)+ Java自带的jdeps等方案进行代码依赖性分析。
Q3:精准化测试从1到N如何实现的,实现从一个团队到规模化复制?
A3:一旦建成精准测试体系(平台),从使用团队的收益出发,推广是比较容易的,因为收益是明显的,特别是当全自动化方式来运行精准测试,也可以配合一些统一的规则和流程,更重要的是精准测试平台和公司的研发平台要实现无缝对接,理想的情况下,和CI/CD流水线实现灵活的集成,让团队无感地使用起来。
Q4:精准测试只能用于回归,如何赋能新功能测试呢?
A4:因为回归测试用例是不断增加的,会达到一个巨量的水平,全量回归成本很大;同时新增/修改的代码量比较小,影响范围是有限的,没有必要运行所有的回归测试用例,凭经验去选用例会导致漏测,所以非常有必要做精准测试。而新功能比较有限,而为新功能写的测试用例都需要执行,所以一般无需“精准测试”策略。但是,借助精准测试平台,可以更好地完成测试覆盖率,提高测试用例的质量和测试结果的充分性。 而且新功能在下一个迭代就是旧功能,为其写的测试用例也变成了回归测试用例,所以新功能也需要在精准测试平台运行,获取代码、测试用例相关信息,完善代码知识库、用例知识库。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
文档获取方式:
这份文档,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
以上均可以分享,只需要你搜索vx公众号:程序员雨果,即可免费领取