JVM源码解读笔记
第三部分:汇编
在计算机最开始,就是编写0,1组合,这个可以想下编写程序的麻烦程度。所以就有了汇编,一些助记符。当然,在汇编与0、1之间肯定还有一个逻辑来讲汇编最终变成0、1。因为0、1是硬件认识的东西。汇编只是0、1的变现形式,肯定是不能脱离硬件支持的,因为一切操作都是由硬件通过逻辑电路去计算的。
===============================================
在看一些jvm性能调优的时候总会提到:运行时数据区、栈帧、操作数栈、动态链接一些概念,但没有看到源码,总感觉有一层雾蒙在面前,所以这次就看一些关于源码的书及代码
第四部分:JVM
1:C、C++、汇编、JVM关系
汇编语言是机器码,从我们编程的角度来说汇编就是我们的最低端。我们的高级语言就是基于汇编。
JVM基于C与C++,而在C中,能嵌入汇编语言,同时C最终也会通过被编译为汇编语言。
2:机器码与字节码
机器码就是前面提到的汇编语言。而字节码就是我们java源码进行javac编译后的字节码。
在JVM中会有这些字节码的定义,例如在bytecodes.hpp中:

在这里我们知道JVM肯定也会进行一次字节码到机器码的转换,JVM虚拟机,之所以叫虚拟机是因为其只是由底层硬件虚拟出来的将其。所以字节码对于JVM也是相当于机器码对于CPU,并且JVM是语言层面虚拟出来的,当然最终还是需要变为机器码来操作硬件。
三:源码->字节码
这个对于我们了解JVM整体的运作影响不大,就先不了解了。
四:class文件的解析
class文件由JVM定义出来的,所以在JVM的源码中肯定是有其数据结构的定义的。程序由算法+数据结构组成。算法就是数据结构的操作规则,而数据结构则是描叙数据前后之间互相联系的规则(例如线性与非线性等)

以上文件是我们javap看到的class文件清晰的结构,但我们知道实际文件是个二进制流,而且这个二进制流文件是JVM根据一定规则产生的,所以关于其的解析则是这个的规则的逆向。
JVM规定class文件一般有10部分组成:

所以class文件的解析就是分析这些内容,并且将其保存到JVM中。
关于这些内容的读取,这10部分是按顺序并且是连续保存的,所以有些标志性的部分、例如MagicNumber、Version、Access_flag(该类的访问标识符,如是private、public)等,JVM可以确定其名字与其值的长度、所以就可以根据其的起始位置+偏移量决定。而不能确认的如Fields、Methods的长度、有几个全局变量、类变量这些,方法的个数这种,。就会再最前面定义其的个数,并且关于方法的描述与变量的描叙,由于JVM在内部定义了一些属性来描叙它,而这些属性的值也是确认的,所以关于方法描叙的开始位置与结束位置也可以确定。关于变量的描叙:

在JVM对于内容的读取有两种方式:一种方式是知道开始位置与偏移量(JVM规定的描叙规,所以JVM能知道偏移量),第二种是JVM不能确定的偏移量,就可以定义一个新的C++类来描叙它的长度,同时这个类的长度是确定的。
关于如何读取这些信息的规则讲了,现在来解析这些属性并将其保存到JVM中。
关于MagicNumber与version这两个都是确定的。
然后是常量池、Method等。
这里就需要引入JVM一个重要的概念了
五:oop-Klass模型
我们知道对象是通过类定义出来的,而不管是对象还是类,其都是由JVM进行描叙的,所以JVM定义一个结果去描叙对象与类,同时我们通过对象能通过反射找到它的类,所以这里JVM就定义了Oop-Klass描叙来描叙这个关系:
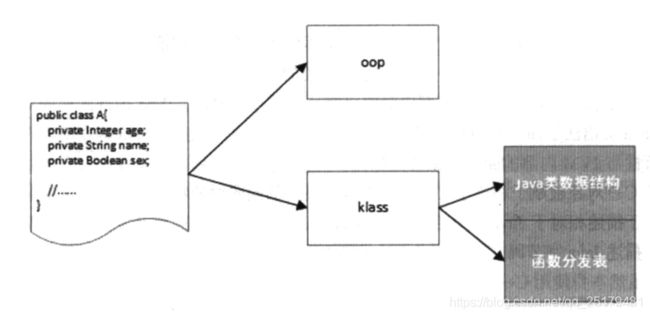
Oop结构描叙对象,klass结构描叙类信息。
并且这个整体关系是通过handler、oop、method(这样处理有利于逻辑回收以及对对象的分代迁移)来具体描叙的,

JVM要获取oop是通过handler来获取的,oop主要由对象头、专属数据区(描叙这个oop本身的信息)、数据区。对象头有
_mark与_metadate组成、_mark代表这个oop的标记、例如偏向锁、hash值等,而_metadate则指向与其对应的klass。
这里有个重要的地方、在jvm中,有很多oop对应也有很多klass、这是因为JVM对于一个类描叙,会把方法拉出去另外用一个oop描叙,如果有数组也会拉出去等,并在描叙这个类的oop中保存其他oop的地址。
在这里,垃圾回收的时候不管是oop、klass都是需要回收的,所以JVM将klass包装为了Oop,所以klass也有_mark、_metadata。
六:常量池解析
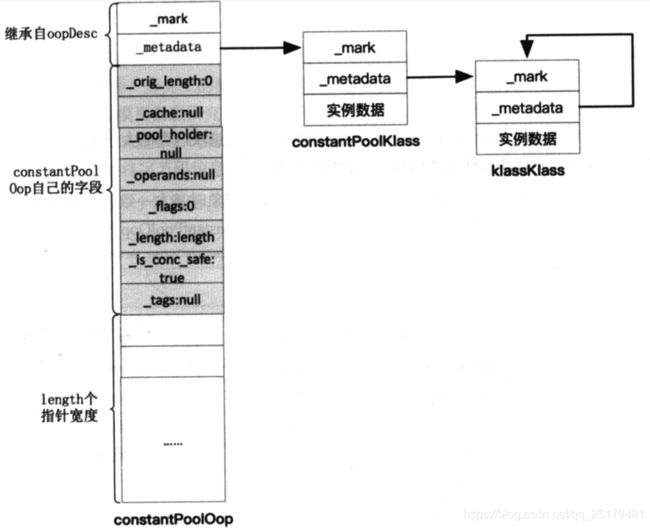
关于这个的写过一次了,然后没有保存就全都没了。现在简单什么下吧。
这里首先是Oop-klass的关系,然后多了一个klassKlass。我们知道垃圾回收需要具体地址,而在JVM中关于常量池数量的描叙不能直接直接确认,constantPoolOop是创建对象的时候通过constantPoolKlass来创建的、所以创建constantPoolOop时其的内存依赖constantPoolKlass,由constantPoolKlass来确定这个length,而klassKlass则又是来描叙这个klass的基本信息的,而klassKlass是一个基本的结构,不需要其他的再来描叙它,所以其指向自己。
同时一行常量有两部分组成:一部分由索引、类型(JVM确定有限个,以及其值的类型,所以代表了比较容易从内存读取解析)组成,另一部分由其值(可以为其他索引会具体的值)。

七:类变量解析
关于这些解析读取有些基本的东西,就是前面关于内存读取的描叙()。其他都是大同小异。不具体说明了,先熟悉JVM整体流程。
八:栈帧
这里有一些基础的概念就不展开了,就是操作系统对于方法的调用其实就是压栈、操作的过程,这个过程中就有一些问题,例如此方法调用完了如何找到其调用它的方法接着执行,在硬件层面还有两个寄存器SP、BP支持对方法栈的发展。所以栈帧是JVM结合自己特性将C程序的方法栈进行了更进一步的补充。更复杂了
所以JVM说的栈帧 其实就是规定以及组装一个方法的环境结构以及数据。
要运行方法,首先需要对象Oop,同时也有了methodOop,然后根据MethodOop、MethodKlass创建这个栈帧。
创建一个栈帧就需要为其分配空间,再在其中,所以首先是为其分配内存,再填充值。栈帧由三部分组成:

这里主要有一些要注意的地方,就是操作数栈的深度,即stack


最大深度,就是说如果你定义了五个参数,计算时就会复用操作数栈,因为参数都在局部变量表中,进行计算时,才需要将局部变量表压到操作数栈中,不会都在操作数栈中,所以只需要一个最大深度就可以了。
这里之所以会是3,是因为还压了this。
同时在这个帧中关键的需要记住方法指令的首地址,因为现在这里只是准备环境,还没有调用这个方法的字节码运行,记下之后,就能在之后就能调用了。
这里还有一个入参与此方法的局部变量是连在一起的,所以分配空间的时候就复用调用方的局部变量,不用为调用方的入参再分配空间(要具体实现这句话就有其它问题要处理了,例如分辨范围、返回地址等问题)
栈帧创建的过程:

获取第一个字节码的位置,就是通过methodOop+偏移量,找到methodKlass通过偏移量找到字节码。记住这个位置,之后进行方法调用时就从这里取值运行。
九:执行引擎
JVM的执行引擎就是对字节的的运行。当然这里过程就是如何将字节码转换为字节码交个CPU运行的过程。
当运行Main函数,获取其第一个字节码,然后翻译为一组字节码,之后就是重复整个过程。之所以是一组,我们有字节码来看,其是面向栈的指令,即没有操作数,只有指令,而机器指令是操作码+操作数,所以一串字节码会通过“汇编器”将其变为一组机器码,JVM有一系列继承关系的汇编器。
这个过程是: JVM中一个模板器,器有一个映射表,即字节码与对应的生成器的关系。一个个字节码有对应的生成器,而生成器调用对应的汇编器将这个字节码变成定的将机器码。
在templateTable.cpp中定义了这个关系:
// Java spec bytecodes ubcp|disp|clvm|iswd in out generator argument
def(Bytecodes::_nop , ____|____|____|____, vtos, vtos, nop , _ );
def(Bytecodes::_aconst_null , ____|____|____|____, vtos, atos, aconst_null , _ );
def(Bytecodes::_iconst_m1 , ____|____|____|____, vtos, itos, iconst , -1 );
def(Bytecodes::_iconst_0 , ____|____|____|____, vtos, itos, iconst , 0 );
def(Bytecodes::_iconst_1 , ____|____|____|____, vtos, itos, iconst , 1 );
def(Bytecodes::_iconst_2 , ____|____|____|____, vtos, itos, iconst , 2 );
这里映射了字节码,以及其对应所需的操作数个数、生成器等信息。
而关于汇编器,器有最底层的注解翻译为机器码的汇编器,也有为了JVM处理方便(基本指令的包装)的汇编器。
其中assembler_x86中就有这些方法的定义:
void mov(Register dst, Register src);
void pusha();
void popa();
void pushf();
void popf();
void push(int32_t imm32);
看下这些在cpp中的实现:
void Assembler::movq( MMXRegister dst, Address src ) {
assert( VM_Version::supports_mmx(), "" );
emit_int8(0x0F);
emit_int8(0x6F);
emit_operand(dst, src);
}其中emit_int8的底层设置内存设置
void emit_int8 ( int8_t x) { *((int8_t*) end()) = x; set_end(end() + sizeof(int8_t)); }所以整个的处理是JVM的两层取指,即先取字节码,再通过字节码取到机器码,在取下一条字节码如此循环。
本文内容及配图主要参考:《揭秘Java虚拟机-JVM设计原理与实现》
第一部分:计算机模型篇
“”我们周围的很多(一切)其实应该都是由简单的阴阳+ 一生二,二生三,三生万物构成的。而计算机就是按这个模型做出来的。“”
一:图灵机
我们现代计算机应该是由图灵机的理论发展而来的:
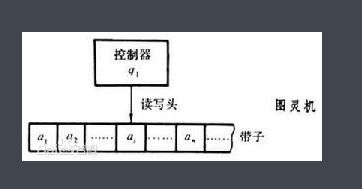

图灵机的概念具体的可以搜索一下。
图灵机等于是一个定义。在这个定义中在带子上的a1、a2等都对应表明一个符号(状态),二在控制器中根据读到的这个状态在根据其内部的规则集去决定怎样去处理这个输入的状态。例如将当前状态a2抹除或者改写为一个新状态,同时再决定下一步是向左还是向右移动读写头。
二:冯诺依曼机
冯洛伊曼机则是将这个定义实现并且改进。冯洛伊曼机的组成是:
输入设备+输出设备+存储器+运算器+控制器,对图灵机进行了补充说明。
读写头被进一步描叙为读设备(输入设备)与写设备(输出设备),当然读写设备并不是互斥的。带子则被抽象为存储器,而控制器则又被细分为控制器+运算器。
设备定义好了,然后是运行规则。控制器操作的是操作指令,操作指令由操作码+操作数组成,即用什么东西去做什么。这里就需要输入设备将指令从存储器中取出来并输入到控制器中(取指)。然后控制器拿到这个指令,进行分析这个指令是干什么的(译码),然后控制器将指令分析对应的运算规则后交给运算器去运算(执行)。然后再是下一条执行。
第二部分:计算机运行规则篇:
上面是概况性的描叙。现代计算机具体的规则:
首先我们知道,计算机问题其实就是0,1的或且非等逻辑运算。而0,1(状态)问题其实又需要转换为电流电压问题,两种状态高电压、低电压,通点、不通电。
我我们启动电源,电流流向一组固化到计算机内主板上一个ROM芯片上的程序(BIOS),然后程序的指令不断的传输到指令寄存器(看下寄存器的分类),之后控制器从指令寄存器中取到指令并译码,需要操作数(之前的指令需要准备好之后指令的操作数放到寄存器),就从寄存器中取到再将运算规则与操作数传递给运算器,运算器进行0,1的逻辑运算将运算结果保存到寄存器中,作为之后指令的操作数,如果需要输出这个运算结果通过指令再将这个结果从寄存器取出到输出设备。
例如一串0,1组合表示的指令,其表示的含义例如是将一个操作数放到一个通用寄存器,这个含义的逻辑是已经通过逻辑电路写在了CPU中了,所以CPU知道怎样去处理它。