大数据学习----Hadoop分布式环境搭建
大数据学习----Hadoop完全分布式环境搭建
永远谦逊,保持对学习的渴望。
第一章 Linux安装 第二章 Linux配置 第三章 Hadoop完全分布式环境搭建 第四章 Zookeeper的安装 第五章 HBase的安装和基础命令
参考文章:
一、ssh免密码登录配置方法
二、Hadoop完全分布式的搭建
文章目录
- 大数据学习----Hadoop完全分布式环境搭建
- 前言
- 一、所需要的资源
- 二、Hadoop概要及原理介绍
-
- Hadoop概要
- 三、Hadoop环境搭建前的准备
-
- (一)创建Hadoop用户
- (二)更新apt
- (三)安装SSH
-
- 1.安装SecureCRT
- 2.每个节点生成公私密钥。
- 2.将公钥文件复制成为成被免登录机器的authorized_keys文件
- 3.测试自身免登录
- 4.测试主节点免登录从属节点
- (四)安装Java环境
-
- 1.解压文件
- 2.配置环境变量
- 3.配置生效
- 三、安装Hadoop
-
- (一)在主节点Hadoop101上安装Hadoop并完成相关文件配置
-
- 1.下载解压Hadoop
- 2.配置Hadoop环境变量
-
- 首行添加语句
- 配置生效
- 3.配置Hadoop分布式环境
-
- 修改hadoop-env.sh及yarn-env.sh中的JAVA_HOME
- 修改core-site.xml文件
- 修改hdfs-site.xml文件
- 修改mapred-site.xml
- 修改Yarn-site.xml
- 修改Slaves
- (二)将主节点的/usr/local/hadoop目录复制到其他节点上
- (三)启动主节点的Hadoop
-
- 1.格式化主节点
- 2.启动Hadoop
- 3.查看启动情况
- (四)启动Hadoop的分布式环境
- 总结
前言
本文紧接上文,包括完全分布式环境搭建之前的一些其他的工具的安装,准备和搭建完成后的测试
以下是本篇文章正文内容
一、所需要的资源
资源分享:
所需要用到资源:
eclipse、Java、Hadoop
本文只有概括完全分布式环境的搭建
链接: 网盘链接,点击此处
提取码:k6wy
二、Hadoop概要及原理介绍
Hadoop概要
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。Hadoop的核心是分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce。
Apache Hadoop版本分为三代,分别是Hadoop 1.0、Hadoop 2.0和Hadoop3.0。
除了免费开源的Apache Hadoop以外,还有一些商业公司推出Hadoop的发行版。2008年,Cloudera成为第一个Hadoop商业化公司,并在2009年推出第一个Hadoop发行版。此后,很多大公司也加入了做Hadoop产品化的行列,比如MapR、Hortonworks、星环等。2018年10月,Cloudera和Hortonworks宣布合并。一般而言,商业化公司推出的Hadoop发行版也是以Apache Hadoop为基础,但是前者比后者具有更好的易用性、更多的功能以及更高的性能。
三、Hadoop环境搭建前的准备
(一)创建Hadoop用户
在上文有提及创建普通用户,并没有操作。所以放在这里创建普通用户,用来进行相关操作,一般在Linux系统都是不使用超级用户来进行操作的。
创建用户:

修改密码:
增加管理员权限

创建成功

(二)更新apt
Ubuntu16.04版本图形界面是有更换安装源的操作的,可以直接在图形界面里面更新下载源地址。

(三)安装SSH
上文已经进行操作安装SSH,但是没有设置免密登录,所以还需要设置免密登录。原理是验证公钥而不验证密码。这一步在安装环境中也是容易出现问题的一步。
1.安装SecureCRT
这个工具能够在主机Windows系统上通过SSH连接虚拟机的Ubuntu系统,减少系统切换带来的时间消耗和不便利的地方。
2.每个节点生成公私密钥。
每一个节点都要生成,也就是第一步和第二步。包括主节点和从属节点。ssh-keygen 不带参数就能生成,但是需要点三个回车来创建。
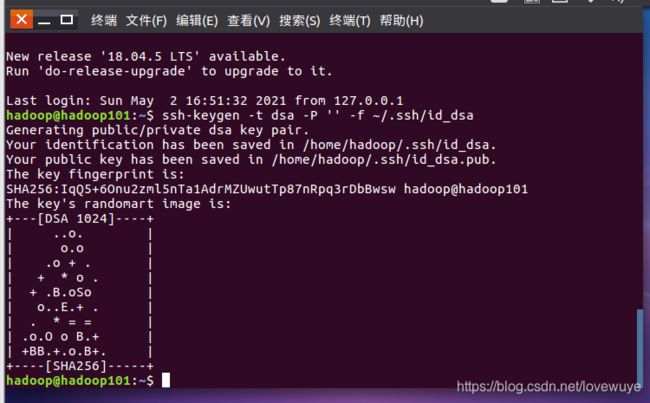
2.将公钥文件复制成为成被免登录机器的authorized_keys文件
有三种方案:
1、将公钥通过scp拷贝到服务器上,然后追加到~/.ssh/authorized_keys文件中,这种方式比较麻烦。scp -P 22 ~/.ssh/id_rsa.pub user@host:~/。
2、通过ssh-copy-id程序,就是下面演示的这个方法,ssh-copyid user@host即可
3、可以通过cat ~/.ssh/id_rsa.pub | ssh -p 22 user@host ‘cat >> ~/.ssh/authorized_keys’,这个也是比较常用的方法,因为可以更改端口号。

3.测试自身免登录
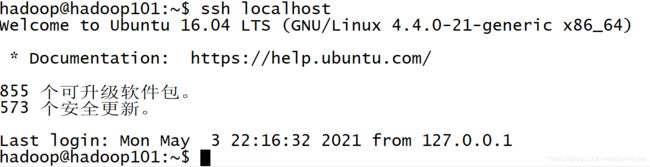
4.测试主节点免登录从属节点

(四)安装Java环境
1.解压文件
![]()
2.配置环境变量
![]()
在第一行插入语句:

这里要把JAVA_HOME的路径看好,PATH变量的是JAVA_HOME指示的目录下的bin文件夹
3.配置生效


三、安装Hadoop
在此之前,三部机器的SSH免密登录设置完成,Java安装完毕并配置成功。
(一)在主节点Hadoop101上安装Hadoop并完成相关文件配置
1.下载解压Hadoop
![]()
2.配置Hadoop环境变量
![]()
首行添加语句
export PATH=$PATH:usr/local/hadoop/bin:/usr/lcoal/haddoop/sbin
配置生效
![]()
3.配置Hadoop分布式环境
修改hadoop-env.sh及yarn-env.sh中的JAVA_HOME

修改core-site.xml文件
fs.defaultFS</name>
hdfs://master:9000</value>
</property>
hadoop.tmp.dir</name>
/usr/local/hadoop/tmp</value>
</property>
</configuration>

修改hdfs-site.xml文件
dfs.replication</name>
2</value>
</property>
dfs.namenode.secondary.http-address</name>
master:50090</value>
</property>
dfs.name.dir</name>
/usr/local/hadoop/namenode</value>
</property>
dfs.data.dir</name>
/usr/local/hadoop/datanode</value>
</property>
</configuration>

修改mapred-site.xml
复制原理同上的。
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>

修改Yarn-site.xml
yarn.resourcemanager.hostname</name>
master</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.log-aggregation-enable</name>
true</value>
</property>
yarn.log-aggregation.retain-seconds</name>
604800</value>
</property>
yarn.nodemanager.resource.memory-mb</name>
2000</value>
</property>
yarn.scheduler.maximum-allocation-mb</name>
2000</value>
</property>
yarn.scheduler.minimum-allocation-mb</name>
500</value>
</property>
mapreduce.reduce.memory.mb</name>
2000</value>
</property>
mapreduce.map.memory.mb</name>
2000</value>
</property>
yarn.nodemanager.vmem-pmem-ratio</name>
2.1</value>
</property>
yarn.resourcemanager.address</name>
master:8032</value>
</property>
yarn.resourcemanager.scheduler.address</name>
master:8030</value>
</property>
yarn.resourcemanager.resource-tracker.address</name>
master:8031</value>
</property>
</configuration>
将master改成Hadoop101
修改Slaves
vi slaves

(二)将主节点的/usr/local/hadoop目录复制到其他节点上
scp -r /usr/local/hadoop hadoop@hadoop102:/usr/local
scp -r /usr/local/hadoop hadoop@hadoop103:/usr/local
这里要注意文件夹的权限问题,可能会出现权限不足,无法发送文件的情况。
(三)启动主节点的Hadoop
1.格式化主节点
![]()
2.启动Hadoop

3.查看启动情况

(四)启动Hadoop的分布式环境
每个节点启动hdfs:进入/usr/local/hadoop ./sbin/start-hdfs.sh
就不截图了
每个节点启动yarn:进入/usr/local/hadoop ./sbin/start-yarn.sh
最后网页版测试:

总结
这里对文章进行总结:
上个学期学习搭建的时候没有这么顺手,可能是因为操作过一遍,这次三个小时就把完全分布式环境搭建好了,但是也还是出现了几个问题,在这里统一总结一下:
1.Java环境变量配置问题。路径配置一定要准确。
2.用户权限问题。尤其是在SSH免密登录的时候,目录文件的权限一定要理清楚,另外在复制主机文件到从属节点也出现这个问题。
3.日志大法。现在对于日志查看大法寻找问题的能力又有了提升,遇到问题我现在觉得不一定要第一时间去博客或者百度,而是经过自己的思考或者理清一遍思路,自己找到问题出现在哪里,实在无法解决了,再去百度或者谷歌,才能使自己的能力得到更快速的成长,毕竟思维能力和解决问题的能力是别人无法给与的,只能通过一次又一次碰到问题然后去解决才能得到提升。
tip:另有一篇文章总结了我遇到一些问题的解决方案,以后碰到问题,结合那篇文章能够希望准确定位。附链接:
大数据环境配置遇到的问题
努力,奋斗!!!