Spring IOC 复习和理解
以下内容不含任何顺序,为个人笔记,适合闲时看看,巩固部分疑难点记忆
一、SpringIOC和DI
IOC:Inversion Of Control,即控制反转,是一种设计思想。在传统的 Java SE 程序设计中,我们直接在对象内部通过 new 的方式来创建对象,是程序主动创建依赖对象;而在Spring程序设计中,IOC 是有专门的容器去控制对象。
所谓控制就是对象的创建、初始化、销毁。
- 创建对象:原来是 new 一个,现在是由 Spring 容器创建。
- 初始化对象:原来是对象自己通过构造器或者 setter 方法给依赖的对象赋值,现在是由 Spring 容器自动注入。
- 销毁对象:原来是直接给对象赋值 null 或做一些销毁操作,现在是 Spring 容器管理生命周期负责销毁对象。
总结:IOC 解决了繁琐的对象生命周期的操作,解耦了我们的代码。
所谓反转:
其实是反转的控制权,前面提到是由 Spring 来控制对象的生命周期,那么对象的控制就完全脱离了我们的控制,控制权交给了 Spring 。这个反转是指:我们由对象的控制者变成了 IOC 的被动控制者。
IOC 能做什么?
IOC 容器完美解决了耦合问题,甚至可以让互不相关的对象产生注入关系。
在 IOC 模式下,你只需要设计良好的流程和依赖,定义出需要什么,然后把控制权交给 Spring 即可。
DI:Dependency injection,即依赖注入。
依赖注入是一种实现,而 IOC 是一种设计思想。从 IOC 到 DI ,就是从理论到实践。程序把依赖交给容器,容器帮你管理依赖,这就是依赖注入的核心。
好处:依赖注入降低了开发的成本,提高了代码复用率、软件的灵活性。
谁依赖谁,为什么需要依赖;谁注入谁,注入了什么:
- 谁依赖谁:A对象 依赖于 IOC 容器。
- 为什么需要依赖:A对象需要 IOC 容器提供对象需要的数据、B对象 等外部资源,没有这些资源不能完成业务处理。
- 谁注入谁:IOC 容器注入 A对象。
- 注入了什么:IOC 容器将 A对象 需要的数据、B对象等外部资源按需注入给对象。
IOC 和DI 的关系:
是同一概念不同角度的描述,但实际上也有区别。IOC 强调的是容器和对象的控制权发生了反转,而 DI 强调的是对象的依赖由容器进行注入。从广义上讲,IOC 是一种开发模式,DI 是其中的一种实现方式,可以理解为:使用依赖注入来实现了控制反转。Spring 选择了 DI,从而使 DI 在 Java 开发中深入人心。
总结
IOC:是一种设计思想。在 Spring 开发中,由 IOC 容器控制对象的创建、初始化、销毁等。这也就实现了对象控制权的反转,由 我们对对象的控制 转变成了 Spring IOC 对对象的控制。IOC 解耦了代码,甚至可以让互不相关的对象产生注入关系。
DI:是 IOC 的具体实现。程序把依赖交给容器,容器帮你管理依赖,这就是依赖注入的核心。还需要明白 谁依赖谁,为什么需要依赖;谁注入谁,注入了什么 等逻辑。
IOC 强调的是容器和对象的控制权发生了反转,而 DI 强调的是对象的依赖由容器进行注入。
二、IOC核心理论回顾
知识点:
- Ioc理念概要
- 实体Bean的创建
- Bean的基本特性
- 依赖注入[set、constructor]
- 自动注入(byName、byType)
1、Ioc理论概要
控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection,简称DI),还有一种方式叫“依赖查找”(Dependency Lookup)
Spring实现IOC的思路和方法
spring实现IOC的思路是提供一些配置信息用来描述类之间的依赖关系,然后由容器去解析这些配置信息,继而维护好对象之间的依赖关系,前提是对象之间的依赖关系必须在类中定义好,比如A.class中有一个B.class的属性,那么我们可以理解为A依赖了B。既然我们在类中已经定义了他们之间的依赖关系那么为什么还需要在配置文件中去描述和定义呢? spring实现IOC的思路大致可以拆分成3点
- 应用程序中提供类,提供依赖关系(属性或者构造方法)
- 把需要交给容器管理的对象通过配置信息告诉容器(xml、annotation,javaconfig)
- 把各个类之间的依赖关系通过配置信息告诉容器
配置这些信息的方法有三种分别是xml,annotation和javaconfig 维护的过程称为自动注入,自动注入的方法有两种构造方法和setter 自动注入的值可以是对象,数组,map,list和常量比如字符串整形等
在JAVA的世界中,一个对象A怎么才能调用对象B?通常有以下几种方法。
| 类别 | 描述 | 描述 |
|---|---|---|
| 外部传入 | 构造方法传入 | |
| 属性设置传入 | 设置对象状态时 | |
| 运行时做为参数传入 | 调用时 | |
| 内部创建 | 属性中直接创建 | 创建引用对象时 |
| 初始化方法创建 | 创建引用对象时 | |
| 运行时动态创建 | 调用时 |
上表可以看到, 引用一个对象可以在不同地点(其它引用者)、不同时间由不同的方法完成。如果B只是一个非常简单的对象 如直接new B(),怎样都不会觉得复杂,比如你从来不会觉得创建一个String 是一个件复杂的事情。但如果B 是一个有着复杂依赖的Service对象,这时在不同时机引用B将会变得很复杂。
无时无刻都要维护B的复杂依赖关系,试想B对象如果项目中有上百过,系统复杂度将会成陪数增加。
IOC容器 的出现正是为解决这一问题,其可以将对象的构建方式统一,并且自动维护对象的依赖关系,从而降低系统的实现成本。
2、实体Bean的构建
- 基于Class构建 or 构造方法构建
- 静态工厂方法创建
- FactoryBean创建
1、基于ClassName构建 or 构造方法构建
<bean class="com.tuling.spring.HelloSpring"></bean>
<bean class="com.tuling.spring.HelloSpring">
<constructor-arg name="name" type="java.lang.String" value="luban"/>
<constructor-arg index="1" type="java.lang.String" value="sex" />
</bean>
第一种是最常规的方法,其原理是在spring底层会基于class属性通过反射调用默认构造方法进行构建。
如果需要基于参数进行构建,就采用构造方法构建,其对应属性如下:
- name: 构造方法参数变量名称
- type: 参数类型
- index: 参数索引,从0开始
- value: 参数值,spring会自动转换成参数实际类型值
- ref: 引用容串的其它对象
2、静态工厂方法创建
<bean class="com.tuling.spring.HelloSpring" factory-method="build">
<constructor-arg name="type" type="java.lang.String" value="B"/>
</bean>
如果你正在对一个对象进行A/B测试 ,就可以采用静态工厂方法的方式创建,其于策略创建不同的对像或填充不同的属性。
该模式下必须创建一个静态工厂方法,并且方法返回该实例,spring 会调用该静态方法创建对象。
public static HelloSpring build(String type) {
if (type.equals("A")) {
return new HelloSpring("luban", "man");
} else if (type.equals("B")) {
return new HelloSpring("diaocan", "woman");
} else {
throw new IllegalArgumentException("type must A or B");
}
}
3、FactoryBean创建
指定一个Bean工厂来创建对象,对象构建初始化 完全交给该工厂来实现。配置Bean时指定该工厂类的类名。
public class LubanFactoryBean implements FactoryBean {
@Override
public Object getObject() throws Exception {
return new HelloSpring();
}
@Override
public Class<?> getObjectType() {
return HelloSpring.class;
}
@Override
public boolean isSingleton() {
return false;
}
}
3、bean的基本特性
- 作用范围
- 生命周期
- 装载机制
a、作用范围
很多时候Bean对象是无状态的 ,而有些又是有状态的 无状态的对象我们采用单例即可,而有状态则必须是多例的模式,通过scope 即可创建
scope=“prototype”
scope=“singleton”
scope=“prototype
<bean class="com.tuling.spring.HelloSpring" scope="prototype">
</bean>
如果一个Bean设置成 prototype 我们可以 通过BeanFactoryAware 获取 BeanFactory 对象即可每次获取的都是新对像。
b、生命周期
Bean对象的创建、初始化、销毁即是Bean的生命周期。通过 init-method、destroy-method 属性可以分别指定期构建方法与初始方法。
<bean class="com.tuling.spring.HelloSpring" init-method="init" destroy-method="destroy"></bean>
如果觉得麻烦,可以让Bean去实现 InitializingBean.afterPropertiesSet()、DisposableBean.destroy()方法。分别对应 初始和销毁方法
c、加载机制
指示Bean在何时进行加载。设置lazy-init 即可,其值如下:
true: 懒加载,即延迟加载
false:非懒加载,容器启动时即创建对象
default:默认,采用default-lazy-init 中指定值,如果default-lazy-init 没指定就是false
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"
default-lazy-init="true">
什么时候使用懒加载?
懒加载会容器启动的更快,而非懒加载可以容器启动时更快的发现程序当中的错误 ,选择哪一个就看追求的是启动速度,还是希望更早的发现错误,一般我们会选 择后者。
4、依赖注入
试想IOC中如果没有依赖注入,那这个框架就只能帮助我们构建一些简单的Bean,而之前所说的复杂Bean的构建问题将无法解决,spring这个框架不可能会像现在这样成功。 spring 中 ioc 如何依赖注入呢。这里我理解的依赖注入(DI)主要有 3 种方式:基于构造函数的依赖注入 、基于Setter方法的依赖注入、基于反射实现的字段注入。
2、set方法注入
<bean class="com.tuling.spring.HelloSpring">
<property name="fine" ref="fineSpring"/>
</bean>
3、构造方法注入
<bean class="com.tuling.spring.HelloSpring">
<constructor-arg name="fine">
<bean class="com.tuling.spring.FineSpring"/>
</constructor-arg>
</bean>
5、自动绑定(byName\byType\constructor)
// 默认不注入,也是默认级别 = 0
public static final int AUTOWIRE_NO = AutowireCapableBeanFactory.AUTOWIRE_NO;
// 按name = 1
public static final int AUTOWIRE_BY_NAME = AutowireCapableBeanFactory.AUTOWIRE_BY_NAME;
// 按type = 2
public static final int AUTOWIRE_BY_TYPE = AutowireCapableBeanFactory.AUTOWIRE_BY_TYPE;
// 按构造器 = 3
public static final int AUTOWIRE_CONSTRUCTOR = AutowireCapableBeanFactory.AUTOWIRE_CONSTRUCTOR;
// 还有一种已经不建议使用了,这里就不赘述自动装配的细节了
例子:
<bean id="helloSpringAutowireConstructor" class="com.tuling.spring.HelloSpring" autowire="byName">
</bean>
byName:基于变量名与bean 名称相同作为依据插入
byType:基于变量类别与bean 名称
constructor:基于IOC中bean与构造方法进行匹配(语义模糊,不推荐)
其实这里我理解的依赖注入和自动绑定是不一样的,依赖注入主要有两种模式,手动和自动,然后通过set方法,构造器方法去注入属于依赖注入的类型,但注入什么,怎么查找注入的对象就是自动绑定干的事情,就比如我自己测试的时候,属性上不加@Autowired.,但提供对应的set方法,因为Spring默认的装配机制是No = 0,那么其实Spring什么都不会做
@Component
public class TService {
//@Autowired
private TDao tDao;
/**
* 默认情况下Spring的装配机制不会调用该方法
* @param tDao
*/
public void settDao(TDao tDao) {
this.tDao = tDao;
}
public void list(){
System.out.println(tDao.list());
}
}
那么我们如果想让Spring自动帮我们装配的话,我们可以通过这样,其实这里在Spring整合Mybatis的MapperScannerRegistrar中有用到,这也是一种中间件开发的思想,比如你开发一个中间件肯定不想强依赖Spring,那么在不使用Spring注解的情况下,怎么做到当和Spring整合却能自动装配呢
public class CeshiImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
BeanDefinitionBuilder definitionBuilder = BeanDefinitionBuilder.genericBeanDefinition(TService.class);
AbstractBeanDefinition definition = definitionBuilder.getBeanDefinition();
// 改变这个Bd的自动装配模型
definition.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE);
registry.registerBeanDefinition("zhulinFactoryBean",definition);
}
}
这里只是简单提及,以后在总结一篇关于这个Spring和Mybatis整合的笔记
扩展:依赖方法注入(lookup-method)
当一个单例的Bean,依赖于一个多例的Bean,用常规方法只会被注入一次,如果每次都想要获取一个全新实例就可以采用lookup-method 方法来实现。
#编写一个抽象类
public abstract class MethodInject {
public void handlerRequest() {
// 通过对该抽像方法的调用获取最新实例
getFine();
}
# 编写一个抽象方法
public abstract FineSpring getFine();
}
// 设定抽象方法实现
<bean id="MethodInject" class="com.tuling.spring.MethodInject">
<lookup-method name="getFine" bean="fine"></lookup-method>
</bean>
该操作的原理是基于动态代理技术,重新生成一个继承至目标类,然后重写抽象方法到达注入目的。
前面说所单例Bean依赖多例Bean这种情况也可以通过实现 ApplicationContextAware 、BeanFactoryAware 接口来获取BeanFactory 实例,从而可以直接调用getBean方法获取新实例,推荐使用该方法,相比lookup-method语义逻辑更清楚一些。
三、IOC 设计原理与实现
知识点:
1、源码学习的目标
2、Bean的构建过程
3、BeanFactory与ApplicationContext区别
1、源码学习目标:
不要为了读书而读书,同样不要为了阅读源码而读源码。没有目的一头扎进源码的黑森林当中很快就迷路了。到时就不是我们读源码了,而是源码‘毒’我们。毕竟一个框架是由专业团队,历经N次版本迭代的产物,我们不能指望像读一本书的方式去阅读它。 所以必须在读源码之前找到目标。是什么呢?
大家会想,读源码的目标不就是为了学习吗?这种目标太过抽像,目标无法验证。通常我们会设定两类型目标:一种是对源码进行改造,比如添加修改某些功能,在实现这种目标的过程当中自然就会慢慢熟悉了解该项目。但然这个难度较大,耗费的成本也大。另一个做法是 自己提出一些问题,阅读源码就是为这些问题寻找答案。以下就是我们要一起在源码中寻找答案的问题:
- Bean工厂是如何生产Bean的?
- Bean的依赖关系是由谁解来决的?
- Bean工厂和应用上文的区别?
2、Bean的构建过程
spring.xml 文件中保存了我们对Bean的描述配置,BeanFactory 会读取这些配置然后生成对应的Bean。这是我们对ioc 原理的一般理解。但在深入一些我们会有更多的问题?
- 配置信息最后是谁JAVA中哪个对象承载的?
- 这些承载对象是谁业读取XML文件并装载的?
- 这些承载对象又是保存在哪里?
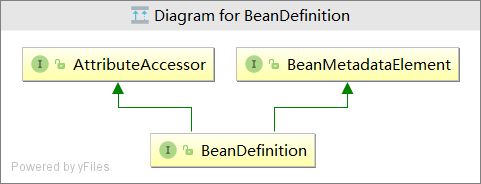
BeanDefinition (Bean定义)
ioc 实现中 我们在xml 中描述的Bean信息最后 都将保存至BeanDefinition (定义)对象中,其中xml bean 与BeanDefinition 程一对一的关系。
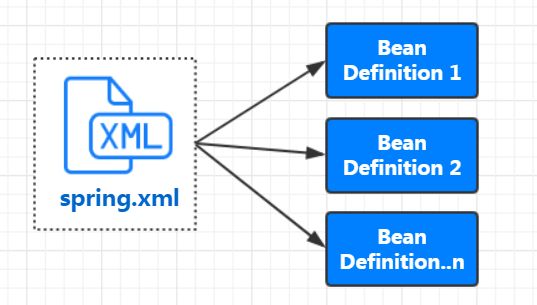
由此可见,xml bean中设置的属性最后都会体现在BeanDefinition中。如:
| XML-bean | BeanDefinition |
|---|---|
| class | beanClassName |
| scope | scope |
| lazy-init | lazyInit |
| constructor-arg | ConstructorArgument |
| property | MutablePropertyValues |
| factory-method | factoryMethodName |
| destroy-method | AbstractBeanDefinition.destroyMethodName |
| init-method | AbstractBeanDefinition.initMethodName |
| autowire | AbstractBeanDefinition.autowireMode |
| id | |
| name |
- 演示查看 BeanDefinition 属性结构
BeanDefinitionRegistry(Bean注册器)
在上表中我们并没有看到 xml bean 中的 id 和name属性没有体现在定义中,原因是ID 其作为当前Bean的存储key注册到了BeanDefinitionRegistry 注册器中。name 作为别名key 注册到了 AliasRegistry 注册中心。其最后都是指向其对应的BeanDefinition。
- 演示查看 BeanDefinitionRegistry属性结构

BeanDefinitionReader(Bean定义读取)
至此我们学习了 BeanDefinition 中存储了Xml Bean信息,而BeanDefinitionRegister 基于ID和name 保存了Bean的定义。接下要学习的是从xml Bean到BeanDefinition 然后在注册至BeanDefinitionRegister 整个过程。

上图中可以看出Bean的定义是由BeanDefinitionReader 从xml 中读取配置并构建出 BeanDefinitionReader,然后在基于别名注册到BeanDefinitionRegister中。
- 查看BeanDefinitionReader结构
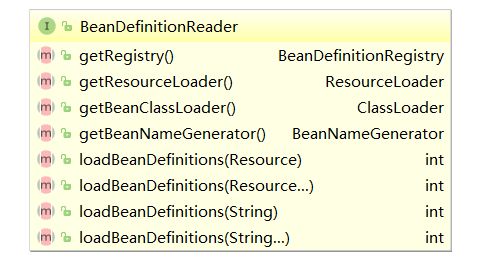
方法说明:
- loadBeanDefinitions(Resource resource)
- 基于资源装载Bean定义并注册至注册器
- int loadBeanDefinitions(String location)
- 基于资源路径装载Bean定义并注册至注册器
- BeanDefinitionRegistry getRegistry()
- 获取注册器
- ResourceLoader getResourceLoader()
- 获取资源装载器
- 基于示例演示BeanDefinitionReader装载过程
//创建一个简单注册器
BeanDefinitionRegistry register = new SimpleBeanDefinitionRegistry();
//创建bean定义读取器
BeanDefinitionReader reader = new XmlBeanDefinitionReader(register);
// 创建资源读取器
DefaultResourceLoader resourceLoader = new DefaultResourceLoader();
// 获取资源
Resource xmlResource = resourceLoader.getResource("spring.xml");
// 装载Bean的定义
reader.loadBeanDefinitions(xmlResource);
// 打印构建的Bean 名称
System.out.println(Arrays.toString(register.getBeanDefinitionNames());
Beanfactory(bean 工厂)
有了Bean的定义就相当于有了产品的配方,接下来就是要把这个配方送到工厂进行生产了。在ioc当中Bean的构建是由BeanFactory 负责的。其结构如下:
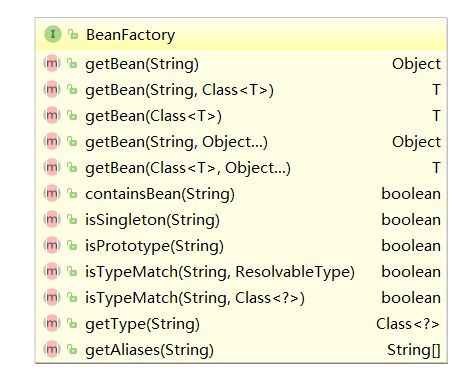
方法说明:
- getBean(String)
- 基于ID或name 获取一个Bean
- T getBean(Class requiredType)
- 基于Bean的类别获取一个Bean(如果出现多个该类的实例,将会报错。但可以指定 primary=“true” 调整优先级来解决该错误 )
- Object getBean(String name, Object… args)
- 基于名称获取一个Bean,并覆盖默认的构造参数
- boolean isTypeMatch(String name, Class typeToMatch)
- 指定Bean与指定Class 是否匹配
以上方法中重点要关注getBean,当用户调用getBean的时候就会触发 Bean的创建动作,其是如何创建的呢?
- 演示基本BeanFactory获取一个Bean
#创建Bean堆栈
// 其反射实例化Bean
java.lang.reflect.Constructor.newInstance(Unknown Source:-1)
BeanUtils.instantiateClass()
//基于实例化策略 实例化Bean
SimpleInstantiationStrategy.instantiate()
AbstractAutowireCapableBeanFactory.instantiateBean()
// 执行Bean的实例化方法
AbstractAutowireCapableBeanFactory.createBeanInstance()
AbstractAutowireCapableBeanFactory.doCreateBean()
// 执行Bean的创建
AbstractAutowireCapableBeanFactory.createBean()
// 缓存中没有,调用指定Bean工厂创建Bean
AbstractBeanFactory$1.getObject()
// 从单例注册中心获取Bean缓存
DefaultSingletonBeanRegistry.getSingleton()
AbstractBeanFactory.doGetBean()
// 获取Bean
AbstractBeanFactory.getBean()
// 调用的客户类
com.tuling.spring.BeanFactoryExample.main()
Bean创建时序图:
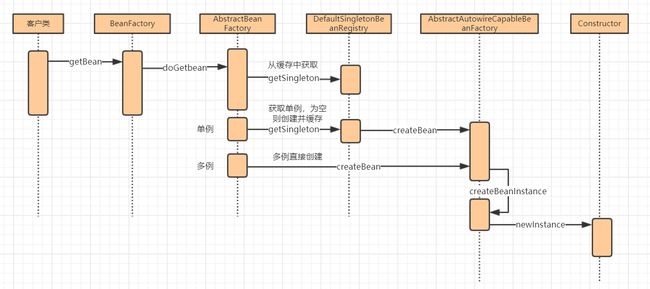
从调用过程可以总结出以下几点:
- 调用BeanFactory.getBean() 会触发Bean的实例化。
- DefaultSingletonBeanRegistry 中缓存了单例Bean
- Bean的创建与初始化是由AbstractAutowireCapableBeanFactory 完成的。
3、BeanFactory 与 ApplicationContext区别
BeanFactory 看下去可以去做IOC当中的大部分事情,为什么还要去定义一个ApplicationContext 呢?
ApplicationContext 结构图

从图中可以看到 ApplicationContext 它由BeanFactory接口派生而来,因而提供了BeanFactory所有的功能。除此之外context包还提供了以下的功能:
- MessageSource, 提供国际化的消息访问
- 资源访问,如URL和文件
- 事件传播,实现了ApplicationListener接口的bean
- 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
总结回顾:
BeanDefinition // Bean定义
DefaultResourceLoader //默认的资源加载器
XmlBeanDefinitionReader //xml解析,用于解析xml中定义的bean标签,转换成bd
BeanDefinitionRegistry //用于注册bd的
BeanFactory //它是Spring中工厂的顶层规范,是SpringIoc容器的核心接口
DefaultListableBeanFactory //spring环境中的默认工厂
AutowireCapableBeanFactory //定义Bean的自动装配规则
AbstractAutowireCapableBeanFactory //实例化bean和依赖注入
SingletonBeanRegistry
DefaultSingletonBeanRegistry
总结SpringBean的生命周期
/**
* 1. abstractApplicationContext的refresh方法
* 2. prepareRefresh and prepareBeanFactory 准备刷新和准备BeanFactory 例如:DefaultListableBeanFactory
* 3. invokeBeanFactoryPostProcessors 执行内部的和用户扩展的BeanFactoryPostProcessors
* 例如:ConfigurationClassPostProcessor处理@Configuration的cglib代理,Bean的扫描等
* class transform -> BeanDefinition -> put BeanFactory的BeanDefinitionMap中
* 4. registerBeanPostProcessors 注册Bean后置处理器,比如aop代理的后置处理器
* 5. 初始化容器事件传播器、注册事件监听器
* 6、finishBeanFactoryInitialization 初始化No Lazy的单例Bean对象
* 遍历BeanDefinitionMap 拿出get BeanDefinition
* validate
* BeanDefinition getClass -> 调用Bean后置处理器推断构造方法 -> 实例化对象newInstance
* 合并BeanDefinition
* 提前暴露一个工厂[用来解决循环依赖的关键,三级缓存机制]
* 填充属性---自动注入[这里重点是循环依赖]
* 执行部分Aware[BeanNameAware]方法
* 调用Bean后置处理器,执行剩下的部分Aware[ApplicationContextAware],并执行注解版的生命周期函数
* 执行InitializingBean的回调 or xml的init-method方法
* 判断是否要进行AOP代理返回代理类[代理类持有被代理对象的引用]
* 7、销毁Bean
*/
扩展:Spring的BeanPostProcessor处理器
Spring在9个地方调用了5个BeanPostProcessor
一、InstantiationAwareBeanPostProcessor
InstantiationAwareBeanPostProcessor接口继承BeanPostProcessor接口,它内部提供了3个方法,再加上BeanPostProcessor接口内部的2个方法,所以实现这个接口需要实现5个方法。InstantiationAwareBeanPostProcessor接口的主要作用在于目标对象的实例化过程中需要处理的事情,包括实例化对象的前后过程以及实例的属性设置
在org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean()方法的Object bean = resolveBeforeInstantiation(beanName, mbdToUse);方法里面执行了这个后置处理器
- postProcessBeforeInstantiation
在目标对象实例化之前调用,方法的返回值类型是Object,我们可以返回任何类型的值。由于这个时候目标对象还未实例化,所以这个返回值可以用来代替原本该生成的目标对象的实例(一般都是代理对象)。如果该方法的返回值代替原本该生成的目标对象,后续只有postProcessAfterInitialization方法会调用,其它方法不再调用;否则按照正常的流程走
- postProcessAfterInstantiation
方法在目标对象实例化之后调用,这个时候对象已经被实例化,但是该实例的属性还未被设置,都是null。如果该方法返回false,会忽略属性值的设置;如果返回true,会按照正常流程设置属性值。方法不管postProcessBeforeInstantiation方法的返回值是什么都会执行
- postProcessPropertyValues
方法对属性值进行修改(这个时候属性值还未被设置,但是我们可以修改原本该设置进去的属性值)。如果postProcessAfterInstantiation方法返回false,该方法不会被调用。可以在该方法内对属性值进行修改
- postProcessBeforeInitialization&postProcessAfterInitialization
父接口BeanPostProcessor的2个方法postProcessBeforeInitialization和postProcessAfterInitialization都是在属性被设置之后并且Aware系列接口回调被调用之后,目标对象被初始化前后进行调用的。
二、SmartInstantiationAwareBeanPostProcessor
智能实例化Bean后置处理器(继承InstantiationAwareBeanPostProcessor)
- determineCandidateConstructors
检测Bean的构造器,可以检测出多个候选构造器
- getEarlyBeanReference
循环引用的后置处理器,这个东西比较复杂, 获得提前暴露的bean引用。主要用于解决循环引用的问题,只有单例对象才会调用此方法
- predictBeanType
预测bean的类型
三、MergedBeanDefinitionPostProcessor
- postProcessMergedBeanDefinition
缓存bean的注入信息的后置处理器,仅仅是缓存或者干脆叫做查找更加合适,没有完成注入,注入是另外一个后置处理器的作用
还有一个BeanPostProcessor和一个销毁Bean的
四、执行过程
Spring的BeanPostProcessor贯穿整个Bean的实例化过程
第一次:在bean没有开始实例化之前执行,给BeanPostProcessors 一个机会来返回代理对象来代替真正的 Bean 实例,在这里实现创建代理对象功能。如果这个后置处理器返回了bean那么Spring在这就不会继续往下走了
resolveBeforeInstantiation(beanName, mbdToUse) =>
[InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()]
=> 返回了bean就执行下面的方法
[InstantiationAwareBeanPostProcessor.postProcessorsAfterInitialization()]
第二次:创建实例,推断构造方法
执行 createBeanInstance => determineConstructorsFromBeanPostProcessors
=> SmartInstantiationAwareBeanPostProcessor => determineCandidateConstructors
第三次:缓存注解信息
applyMergedBeanDefinitionPostProcessors => MergedBeanDefinitionPostProcessor => postProcessMergedBeanDefinition
第四次:得到一个体现暴露的对象----对象不是bean(在spring容器当中,并且由sping自己产生的)
addSingletonFactory => SmartInstantiationAwareBeanPostProcessor => getEarlyBeanReference
第五次:判断你的bean需不需要完成属性填充
populateBean => InstantiationAwareBeanPostProcessor => postProcessAfterInstantiation
第六次:属性填充 => 自动注入
populateBean => InstantiationAwareBeanPostProcessor => postProcessProperties
第七次:BeanPostProcessor调用,前面调用的都是扩展了该接口的,比如ApplicationContextAwareProcessor处理继承了ApplicationAware的,CommonAnnotationBeanPostProcessor处理@PostConstruct
AbstractAutowireCapableBeanFactory => initializeBean => BeanPostProcessor => postProcessBeforeInitialization
注意:其实此时的Bean已经是一个完整的对象了,bean已经new出来,并且完成了属性的填充(自动装配)和生命周期,在来执行BeanPostProcessor的After
第八次:BeanPostProcessor调用,比如完成代理aop[AbstractAutoProxyCreator的postProcessAfterInitialization]
AbstractAutowireCapableBeanFactory => initializeBean => BeanPostProcessor =>
postProcessAfterInitialization
第九次:bean销毁的一个后置处理器销毁 => destory
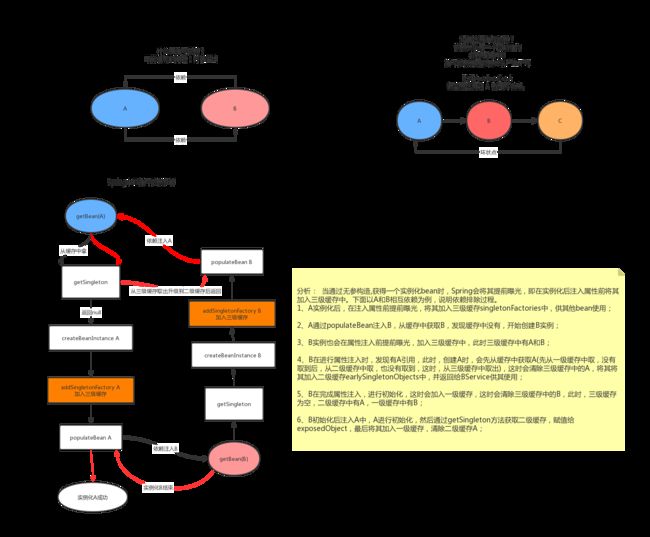
扩展:Spring的循环依赖图解