【新版】系统架构设计师 - 层次式架构设计理论与实践

个人总结,仅供参考,欢迎加好友一起讨论
文章目录
- 架构 - 层次式架构设计理论与实践
- 考点摘要
- 层次式体系结构概述
- 表现层框架设计
-
- MVC模式
- MVP模式
- MVVM模式
- 使用XML设计表现层
- 表现层中UIP设计思想
- 中间层架构设计
-
- 业务逻辑层工作流设计
- 业务逻辑层设计
- 数据访问层设计
-
- 5种数据访问模式
- 工厂模式在数据访问层应用
- ORM、Hibernate与CMP2.0设计思想
- 灵活运用XML Schema
- 事务处理设计
- 数据架构规划与设计
架构 - 层次式架构设计理论与实践
考点摘要
- 层次式体系结构概述(★)
第二版架构新教材里新增加内容,对应第13章,新增的内容是有关层次架构的总结性知识,偏理论多,案例题中有内容涉及。
层次式体系结构概述
层次式体系结构设计是将系统组成一个层次结构,每一层为上层服务,并作为下层客户。 在一些层次系统中,除了一些精心挑选的输出函数外,内部的层接口只对相邻的层可见。连接件通过决定层间如何交互的协议来定义,拓扑约束包括对相邻层间交互的约束。由于每一层最多只影响两层,同时只要给相邻层提供相同的接口,允许每层用不同的方法实现,同样为软件重用提供了强大的支持。
分层架构的一个特性就是关注分离(separation of concerns)。 该层中的组件只负责本层的逻辑,组件的划分很容易明确组件的角色和职责,也比较容易开发、测试、管理和维护。
层次式体系结构是一个可靠的通用的架构,对很多应用来说,如果不确定哪种架构适合,可以用它作为一个初始架构。但是,设计时要注意以下两点:
-
要注意的是污水池反模式。
污水池反模式(architecture sinkhole anti-pattern),就是请求流简单地穿过几个层,每层里面基本没有做任何业务逻辑,或者做了很少的业务逻辑。比如一些JavaEE例子,业务逻辑层只是简单的调用了持久层的接口,本身没有什么业务逻辑。
-
需要考虑的是分层架构可能会让你的应用变得庞大。
即使你的表现层和中间层可以独立发布,但它的确会带来一些潜在的问题,比如:分布模式复杂、健壮性下降、可靠性和性能的不足,以及代码规模的膨胀等。
表现层框架设计
MVC模式

MVC强制性地把一个应用的输入、处理、输出流程按照视图、控制、模型的方式进行分离,形成了控制器、模型、视图三个核心模块。
- 控制器(Controller):接受用户的输入并调用模型和视图去完成用户的需求。该部分是用户界面与Model的接口。一方面它解释来自于视图的输入,将其解释成为系统能够理解的对象,同时它也识别用户动作,并将其解释为对模型特定方法的调用;另一方面,它处理来自于模型的事件和模型逻辑执行的结果,调用适当的视图为用户提供反馈。
- 模型(Model):应用程序的主体部分。模型表示业务数据和业务逻辑。一个模型能为多个视图提供数据。由于同一个模型可以被多个视图重用,所以提高了应用的可重用性。
- 视图(View):用户看到并与之交互的界面。视图向用户显示相关的数据,并能接收用户输入的数据,但是它并不进行任何实际的业务处理。视图可以向模型查询业务状态,但不能改变模型。视图还能接受模型发出的数据更新事件,从而对用户界面进行同步更新。
使用MVC模式来设计表现层,可以有以下的优点:
- 允许多种用户界面的扩展。在MVC模式中,视图与模型没有必然的联系,都是通过控制器发生关系,这样如果要增加新类型的用户界面,只需要改动相应的视图和控制器即可,而模型则无须发生改动。
- 易于维护。控制器和视图可以随着模型的扩展而进行相应的扩展,只要保持一种公共的接口,控制器和视图的旧版本也可以继续使用。
- 功能强大的用户界面。用户界面与模型方法调用组合起来,使程序的使用更清晰,可将友好的界面发布给用户。
MVP模式

MVP(Model-View-Presenter)模式提供数据, View负责显示, Controller/Presenter负责逻辑的处理。
MVP是从经典的模式MVC演变而来,MVP与MVC 的区别:MVC模式中元素之间“混乱”的交互主要体现在允许View和Model直接进行“交流”,这在MVP模式中是不允的。在MVP中View并不直接使用Model,它们之间的通信是通过Presenter(MVC中的Controller)来进行的,所有的交互都发生在Presenter内部,而在MVC中View会直接从Model中读取数据而不是通过Controller 。
使用MVP模式来设计表现层,可以有以下的优点:
- 模型与视图完全分离,可以修改视图而不影响模型。
- 可以更高效地使用模型,因为所有的交互都发生在一个地方,Presenter内部。
- 可以将一个Presenter用于多个视图,而不需要改变Presenter的逻辑。这个特性非常的有用,因为视图的变化总是比模型的变化频繁。
- 如果把逻辑放在Presenter中,就可以脱离用户接口来测试这些逻辑(单元测试)。
MVVM模式

MVM模式全称是模型 - 视图 - 视图模型(Model - View - ViewModel),它和MVC、MVP不同的是:View与Model的交互通过ViewModel来实现。ViewModel是MVVM的核心,它通过DataBinding实现View与Model之间的双向绑定,其内容包括数据状态处理、数据绑定及数据转换。例如,View中某处的状态和Model中某部分数据绑定在一起,这部分数据一旦变更将-会反映到View层。而这个机制通过ViewModel来实现。
ViewModel,即视图模型,是一个专门用于数据转换的控制器,它可以把对象信息转换为视图信息,将命令从视图携带到对象。
ViewModel通常要实现一个观察者,当数据发生变化,ViewModel能够监听到数据的变化,然后通知对应的视图做自动更新:而当用户操作视图,ViewModel也能监听到视图的变化,再通知数据做改动,从而形成数据的双向绑定。这使得MVM更适用于数据驱动的场景,尤其是数据操作特别频繁的场景。
使用XML设计表现层
XML(可扩展标记语言)与HTML类似,是一种标记语言。与主要用于控制数据的显示和外观的HTML标记不同,XML标记用于定义数据本身的结构和数据类型。XML已被公认为是优秀的数据描述语言,并且成为了业内广泛采用的数据描述标准。
由于XML本身就是一种树形结构描述语言,所以可以很好地支持控件之间的层次结构。GUI主要是由GUI控件组成。控件可以看成是一个数据对象,其包含位置信息、类型和绑定的事件等。这些信息在XML 中都可以作为数据结点保存下来,每一个控件都可以被描述成一个 XML结点,而控件的那些相关属性都可以描述成这个XML结点的Attribute。
表现层中UIP设计思想
表现层开发的痛点:
- 导航和工作流控制:这些将不会出现的Ul中,但是经常因为要基于业务逻辑决定哪一个视图将被显示。这导致代码的不雅和难于管理。
- 导航和工作流改变:用传统的UI技术改变应用程序的界面(改变页面的顺序或者添加删除页面)是非常痛苦的。
- 状态管理:不管是在windows form还是在web form中,在视图间维护状态都是比较困难的。
- 保存当前交互的快照:你可能想保存一个交互的快照并且在别的地方(不同的时间,不同的地点)重新开始它。
UIP(UserInterface Process Application Block)是微软社区开发的众多Application Block中的其中之一,它是开源的。 UIP 提供了一个扩展的框架,用于简化用户界面与商业逻辑代码的分离的方法,可以用它来写复杂的用户界面导航和工作流处理,并且它能够复用在不同的场景、并可以随着应用的增加而进行扩展。

UIP框架的应用程序把表现层分为了以下几层:
- User Interface Components:这个组件就是原来的表现层,用户看到的和进行交互都是这个组件,它负责获取用户的数据并且返回结果。
- User Interface Process Components:这个组件用于协调用户界面的各部分,使其配合后台的活动,例如导航和工作流控制,以及状态和视图的管理。用户看不到这一组件,但是这些组件为User Interface Components提供了重要的支持功能。
中间层架构设计
业务逻辑组件分为接口和实现类两个部分。
- 接口:用于定义业务逻辑组件,定义业务逻辑组件必须实现的方法是整个系统运行的核心通常按模块来设计业务逻辑组件,每个模块设计一个业务逻辑组件,并且每个业务逻辑组件以多个DAO(Data Access Object)组件作为基础,从而实现对外提供系统的业务逻辑服务。增加业务逻辑组件的接口,是为了提供更好的解耦,控制器无须与具体的业务逻辑组件耦合,而是面向接口编程。
- 实现类:业务逻辑组件以DAO组件为基础,必须接收Spring容器注入的DAO组件,因此必须为业务逻辑组件的实现类提供对应的Setter方法。业务逻辑组件的实现类将DAO组件接口实例作为属性(面向接口编程),而对于复杂的业务逻辑,可能需要访问多个对象的数据,那么只需在这个方法里调用多个DAO接口,将具体实现委派给DAO完成。
业务逻辑层工作流设计
工作流管理联盟(Workflow Management Coalition)将工作流定义为:业务流程的全部或部分自动化,在此过程中,文档、信息或任务按照一定的过程规则流转,实现组织成员间的协调工作以达到业务的整体目标。

- 过程定义导入/导出接口。这个接口的特点是:转换格式和API调用,从而支持过程定义信息间的互相转换。这个接口也支持已完成的过程定义或过程定义的一部分之间的互相转换。早期标准是WPDL,后来发展为XPDL。
- 客户端应用程序接口。通过这个接口工作流机可以与任务表处理器交互,代表用户资源来组织任务。然后由任务表处理器负责,从任务表中选择、推进任务项。由任务表处理器或者终端用户来控制应用工具的活动。
- 应用程序调用接口。允许工作流机直接激活一个应用工具,来执行一个活动。典型的是调用以后台服务为主的应用程序,没有用户接口。当执行活动要用到的工具,需要与终端用户交互,通常是使用客户端应用程序接口来调用那个工具,这样可以为用户安排任务时间表提供更多的灵活性。
- 工作流机协作接口。其目标是定义相关标准,以使不同开发商的工作流系统产品相互间能够进行无缝的任务项传递。 WFMC定义了4个协同工作模型,包含多种协同工作能力级别。
- 管理和监视接口。提供的功能包括用户管理、角色管理、审查管理、资源控制、过程管理和过程状态处理器等。
用工作流的思想组织业务逻辑,优点是:将应用逻辑与过程逻辑分离,在不修改具体功能的情况下,通过修改过程模型改变系统功能,完成对生产经营部分过程或全过程的集成管理,可有效地把人、信息和应用工具合理地组织在一起,发挥系统的最大效能。
业务逻辑层设计
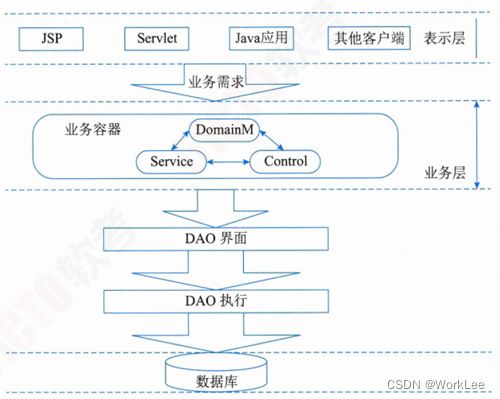
业务框架位于系统架构的中间层,是实现系统功能的核心组件。采用容器的形式,便于系统功能的开发、代码重用和管理。大大降低业务层和相邻各层的耦合。表示层代码只需要将业务参数传递给业务容器,而不需要业务层多余的干预。有效地防止业务层代码渗透到表示层。
- Domain Model是领域层业务对象,它仅仅包含业务相关的属性。
- Service是业务过程实现的组成部分,是应用程序的不同功能单元,通过在这些服务之间定义良好的接口和契约联系起来。接口是采用中立的方式进行定义的,这使得构建在各种这样的系统中的服务可以以一种统一和通用的方式进行交互。这种具有中立的接口定义(没有强制绑定到特定的实现上)的特征称为服务之间的松耦合。松耦合系统的好处有两点,一是它的灵活性,二是当组成整个应用程序的每个服务的内部结构和实现逐渐地发生改变时,它能够继续存在。
- Control服务控制器,是服务之间的纽带,不同服务之间的切换就是通过它来实现的。通过服务控制器控制服务切换可以将服务的实现和服务的转向控制分离,提高了服务实现的灵活性和重用性。
数据访问层设计
5种数据访问模式
在线访问
在线访问是最基本的数据访问模式,在实际开发过程中最常采用的。
这种数据访问模式会占用一个数据库连接,读取数据,每个数据库操作都会通过这个连接不断地与后台的数据源进行交互。
Data Access Object
DAO模式是标准J2EE设计模式之一,开发人员常常用这种模式将底层数据访问操作与高层业务逻辑分离开。
一个典型的DAO实现通常有以下组件:
- 一个DAO 工厂类
- 一个DAO接口
- 一个实现了DAO接口的具体类
- 数据传输对象,这当中具体的DAO类包含访问特定数据源的数据的逻辑。
Data Transfer Object
Data Transfer Object是经典EJB设计模式之一。 DTO本身是这样一组对象或是数据的容器,它需要跨不同的进程或是网络的边界来传输数据。这类对象本身应该不包含具体的业务逻辑,并且通常这些对象内部只能进行一些诸如内部一致性检查和基本验证之类的方法,而且这些方法最好不要再调用其他的对象行为。
在具体设计这类对象(DTO)时,通常可以有如下两种选择:
- 使用编程语言内置的集合对象。
- 通过创建自定义类来实现DTO对象。
离线数据模式
离线数据模式是以数据为中心,数据从数据源获取之后,将按照某种预定义的结构(这种结构可以是SDO中的Data图表结构,也同样可以是 ADO.NET 中的关系结构)存放在系统中,成为应用的中心。离线,对数据的各种操作独立于各种与后台数据源之间的连接或是事务;与XML集成,数据可以方便地与XML格式的文档之间互相转换;独立于数据源,离线数据模式的不同实现定义了数据的各异的存放结构和规则,这些都是独立于具体的某种数据源的。
对象/关系映射(Object/Relation Mapping,O/R Mapping)
大多数应用中的数据都是依据关系模型存储在关系型数据库中,而很多应用程序中的数据在开发或是运行时则是以对象的形式组织起来的。
工厂模式在数据访问层应用
在编写应用系统的时候,尽量做到数据库无关。这就需要在实际开发过程中将数据库访问类作一次封装。经过这样的封装,不仅可以达到良好的封装性和可维护性,还可以减少操作数据库的步骤,减少代码编写量。工厂设计模式是使用的主要方法。
工厂模式定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。这里可能会处理对多种数据库的操作,因此,需要首先定义一个操纵数据库的接口,然后根据数据库的不同,由类工厂决定实例化哪个类。
ORM、Hibernate与CMP2.0设计思想
ORM(Object-Relation Mapping)在关系型数据库和对象之间作一个映射,这样,在具体操纵数据库时,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作即可。
提到Hibernate必须要说到Mybatis,相关内容自行搜索,开发人员必备。
灵活运用XML Schema
XML Schema用来描述XML文档合法结构、内容和限制。XML Schema由XML1.0自描述,并且使用了命名空间,有丰富的内嵌数据类型及其强大的数据结构定义功能,充分地改造了并且极大地扩展了DTDs(传统描述XML文档结构和内容限制的机制)的能力,将逐步替代DTDs,成为XML体系中正式的类型语言,同XML规范、Namespace规范一起成为XML体系的坚实基础。
事务处理设计
事务必须服从ISO/IEC所制定的ACID原则。 ACID是原子性(Atomicity)、 一致性(Consistency)、 隔离性(Isolation)和持久性(Durability)的缩写。
- 原子性:表示事务执行过程中的任何失败都将导致事务所做的任何修改失效。
- 一致性:表示当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。
- 隔离性:表示在事务执行过程中对数据的修改,在事务提交之前对其他事务不可见。
- 持久性:表示已提交的数据在事务执行失败时,数据的状态都应该正确。
数据架构规划与设计
Web上存有大量的XML文档,并需要持久保存,这一需求引发了人们对XML文档的存储技术研究。已经提
出的XML文档的存储方式有两种:基于文件的存储方式和数据库存储方式。
- 基于文件的存储方式。基于文件的存储方式是指将XML文档按其原始文本形式存储,主要存储技术包括操作系统文件库、通用文档管理系统和传统数据库的列(作为二进制大对象BLOB或字符大对象CLOB)。这种存储方式需维护某种类型的附加索引,以建立文件之间的层次结构。基于文件的存储方式的特点:无法获取XML文档中的结构化数据;通过附加索引可以定位具有某些关键字的 XML 文档,一旦关键字不确定,将很难定位;查询时,只能以原始文档的形式返回,即不能获取文档内部信息;文件管理存在容量大、管理难的缺点。
- 数据库存储方式。数据库在数据管理方面具有管理方便、存储占用空间小、检索速度快、修改效率高和安全性好等优点。一种比较自然的想法是采用数据库对XML文档进行存取和操作,这样可以利用相对成熟的数据库技术处理XML文档内部的数据。数据库存储方式的特点:能够管理结构化和半结构化数据;具有管理和控制整个文档集合本身的能力;可以对文档内部的数据进行操作;具有数据库技术的特性,如多用户、并发控制和致性约束等;管理方便,易于操作。