hadoop3.1.4 完全分布式搭建HA(namenode resourcemanager高可用)保姆级教程-详细步骤-快速搭建-详解配置-历史服务器
一. 集群规划
| ip | 主机名 | 安装进程 |
|---|---|---|
| 192.168.204.14 | hdp14 | namenode,ZKFC,resourcemanager |
| 192.168.204.15 | hdp15 | namenode,ZKFC,resourcemanager |
| 192.168.204.16 | hdp16 | natanode,nodemanager,zookeeper,Journalnode |
| 192.168.204.17 | hdp17 | natanode,nodemanager,zookeeper,Journalnode |
| 192.168.204.18 | hdp18 | natanode,nodemanager,zookeeper,Journalnode |
需要5台虚拟机,电脑配置20G以上。
二. 虚拟机环境配置
准备好一台虚拟机,4G内存,50G硬盘,配置好网络,连接Xshell工具
2.1 设置静态ip及主机名修改
root用户添加,修改ip的脚本ip.sh
[root@hdp14 ~]# cd /root/
[root@hdp14 ~]# mdkir bin
[root@hdp14 ~]# vim ip.sh
#添加下面的脚本内容
[root@hdp14 bin]# chmod +x ip.sh
[root@hdp14 bin]# ls
ip.sh
脚本内容
#!/bin/bash
file=/etc/sysconfig/network-scripts/ifcfg-ens33
hostnamectl --static set-hostname hdp14$1
echo "TYPE="Ethernet"" > $file
echo "BOOTPROTO="static"" >> $file
echo "NAME="ens33"" >> $file
echo "DEVICE="ens33"" >> $file
echo "ONBOOT="yes"" >> $file
echo ""IPADDR=192.168.204.$1"" >> $file
echo "PREFIX=24" >> $file
echo "GATEWAY=192.168.204.2" >> $file
echo "DNS1=192.168.204.2" >> $file
echo "DNS2=192.168.0.168" >> $file
#重启
reboot
执行修改语句
[root@hdp14 ~]# ip.sh 14
Invalid number of arguments.
Connection closed by foreign host.
Disconnected from remote host(hdp14149) at 18:24:40.
Type `help' to learn how to use Xshell prompt.
[c:\~]$
2.2 安装必要的环境
sudo yum install -y epel-release
sudo yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
注:可使用Xshell工具,开多个窗口,将命令发送到所有会话,也可单台操作后期克隆,这里采用克隆虚拟机的方式
2.3 关闭防火墙和selinucx
关闭防火墙
[root@hdp14 ~]# systemctl stop firewalld
[root@hdp14 ~]# systemctl disable firewalld
关闭selinux
[root@hdp14 ~]# vi /etc/selinux/config
把SELINUX=enforce 改成SELINUX=disabled
2.4 修改hosts文件
vim /etc/hosts
#添加如下内容
192.168.204.10 hdp10
192.168.204.11 hdp11
192.168.204.12 hdp12
192.168.204.13 hdp13
192.168.204.14 hdp14
192.168.204.15 hdp15
192.168.204.16 hdp16
192.168.204.17 hdp17
192.168.204.18 hdp18
192.168.204.19 hdp19
2.5 配置普通用户(along)具有root权限
修改sudoers文件,添加新用户
[root@hdp14 ~]# adduser along
[root@hdp14 ~]# passwd along
修改权限
[root@hdp14 ~]# sudo vim /etc/sudoers
放开这一行:%wheel ALL=(ALL) ALL ,并下面添加一行
along ALL=(ALL) NOPASSWD:ALL
2.6 创建集群安装文件夹
创建/opt/bigdata和/opt/resource文件夹,并赋予along权限
[root@hdp14 ~]# sudo mkdir /opt/bigdata /opt/resource
[root@hdp14 ~]# sudo chown -R along:along /opt/bigdata /opt/resource
2.7 安装jdk1.8 配置环境变量
用along登陆,安装jdk
将jdk的tar包上传到集群的/opt/resource,并解压到/opt/bigdata
tar -zxf /opt/resource/jdk-8u212-linux-x64.tar.gz -C /opt/bigdata/
配置环境变量
sudo vim /etc/profile.d/my_env.sh
注意:这里环境变量不配置到/etc/profile文件中?
查看这个文件
[along@hdp14 hadoop-3.1.4]$ vim /etc/profile
靠前的地方有一段提示
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
文件末尾添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/bigdata/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
克隆4台虚拟机【hdp15,hdp16,hdp17,hdp18】分别使用ip.sh 脚本修改主机名和ip地址
ip.sh 15
...
2.8 为along,root用户配置免密登陆
每台服务器的root 和along用户都需要配置,以hdp14的root为例
进入用户目录:
[root@hdp14 ~]# ssh-keygen -t ecdsa
连续三次回车,生成公钥和私钥
将公钥复制到目标服务器:
[root@hdp14 opt]# ssh-copy-id hdp14
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_ecdsa.pub"
The authenticity of host 'hdp14 (192.168.204.14)' can't be established.
ECDSA key fingerprint is SHA256:cmFNNQajtQRotZPgk4ZmEFDJPChYRibK26PaCC81/pc.
ECDSA key fingerprint is MD5:d7:0b:cb:9c:0a:04:76:80:aa:37:f9:80:17:e8:4e:6b.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hdp14's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hdp14'"
and check to make sure that only the key(s) you wanted were added.
剩余4台,执行相同操作
ssh-copy-id hdp15
ssh-copy-id hdp16
ssh-copy-id hdp17
ssh-copy-id hdp18
重启,along用户登录,重复上面的操作。
2.9 编辑工具脚本
2.9.1 批量发送命令的脚本xcall
#!/bin/bash
hosts=(hdp14 hdp15 hdp16 hdp17 hdp18)
for host in ${hosts[@]}
do
echo =============== $host ===============
ssh $host "$*"
done
添加执行权限,测试脚本
2.9.2 文件分发脚本 axync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo 请指定要分发的文件!
exit;
fi
#2. 遍历集群所有机器
hosts=(hdp14 hdp15 hdp16 hdp17 hdp18)
for host in ${hosts[@]}
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file 文件不存在!
fi
done
done
添加执行权限
[along@hdp14 bin]$ chmod +x axync
测试脚本
[along@hdp14 bin]$ axync axync
2.10 服务器之间集群同步
全部切换到root用户。
(0)查看所有节点ntpd服务状态和开机自启动状态
[along@hdp14 ~]$ sudo systemctl status ntpd
[along@hdp14 ~]$ sudo systemctl is-enabled ntpd
(1)在所有节点关闭ntp服务和自启动
[along@hdp14 ~]$ sudo systemctl stop ntpd
[along@hdp14 ~]$ sudo systemctl disable ntpd
(2)修改hdp14的ntp.conf配置文件
[along@hdp14 ~]$ sudo vim /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.204.0-192.168.204.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
为
restrict 192.168.204.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改hdp14的/etc/sysconfig/ntpd 文件
[along@hdp14 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[along@hdp14 ~]$ sudo systemctl start ntpd
(5)设置ntpd服务开机启动
[along@hdp14 ~]$ sudo systemctl enable ntpd
(6)在其他机器配置10分钟与时间服务器同步一次
[along@hdp15 ~]$ sudo crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hdp14
(7)修改任意机器时间
[along@hdp15 ~]$ sudo date -s "2020-8-19 13:01:19"
(8)十分钟后查看机器是否与时间服务器同步
[along@hdp15 ~]$ sudo date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。
2.10 安装zookeeper集群
下载zookeeper安装包 apache-zookeeper-3.5.9-bin.tar.gz
https://downloads.apache.org/zookeeper/zookeeper-3.5.9/
注意包名,不要下载错了
上传到hdp16的/opt/resource目录,解压到/opt/bigdata目录,修改文件夹名称
[along@hdp16 resource]$ tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /opt/bigdata/
[along@hdp16 resource]$ cd /opt/bigdata/
[along@hdp16 bigdata]$ mv apache-zookeeper-3.5.9/ zookeeper-3.5.9
创建zkData目录,配置服务器编号
[along@hdp16 bigdata]$ cd zookeeper-3.5.9/
[along@hdp16 zookeeper-3.5.9]$ mkdir zkData
[along@hdp16 zookeeper-3.5.9]$ cd zkData/
[along@hdp16 zkData]$ vim myid
新文件myid添加如下内容
6
修改配置文件
[along@hdp16 zkData]$ cd ../conf/
[along@hdp16 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[along@hdp16 conf]$ mv zoo_sample.cfg zoo.cfg
[along@hdp16 conf]$ vim zoo.cfg
数据存储路径修改为
dataDir=/opt/bigdata/zookeeper-3.5.9/zkData
在文件末尾添加
server.6=hdp16:2888:3888
server.7=hdp17:2888:3888
server.8=hdp18:2888:3888
同步/opt/bigdata/zookeeper-3.5.9 到hdp17,hdp18
[along@hdp16 bigdata]$ scp -r zookeeper-3.5.9/ along@hdp17:/opt/bigdata/
[along@hdp16 bigdata]$ scp -r zookeeper-3.5.9/ along@hdp18:/opt/bigdata/
在hdp17,hdp18上修改/opt/bigdata/zookeeper-3.5.9/zkData/myid中的6改为对应的id
[along@hdp17 zkData]$ vim /opt/bigdata/zookeeper-3.5.9/zkData/myid
7
[along@hdp18 zkData]$ vim /opt/bigdata/zookeeper-3.5.9/zkData/myid
8
进入zk所在目录,分别启动Zookeeper
[along@hdp16 zookeeper-3.5.9]$ bin/zkServer.sh start
[along@hdp17 zookeeper-3.5.9]$ bin/zkServer.sh start
[along@hdp18 zookeeper-3.5.9]$ bin/zkServer.sh start
最好使用集群启动脚本, zk.sh
[along@hdp14 bin]$ vim zk.sh
脚本内容
#!/bin/bash
hosts=(hdp16 hdp17 hdp18)
path=/opt/bigdata/zookeeper-3.5.9
case $1 in
"start"){
for i in ${hosts[@]}
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "$path/bin/zkServer.sh start"
done
};;
"stop"){
for i in ${hosts[@]}
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "$path/bin/zkServer.sh stop"
done
};;
"status"){
for i in ${hosts[@]}
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "$path/bin/zkServer.sh status"
done
};;
esac
增加执行权限
[along@hdp14 bin]$ sudo chmod +x zk.sh
三. hadoo安装配置
3.1 上传安装包并解压
将编译好的hadoop安装包上传到/opt/resource 文件夹,之前我在hdp16上编译
编译教程查看我的另一篇文章
https://blog.csdn.net/weixin_52918377/article/details/116456751
[root@hdp16 target]# scp hadoop-3.1.4.tar.gz along@hdp14:/opt/resource
along@hdp14's password:
hadoop-3.1.4.tar.gz 100% 287MB 17.8MB/s 00:16
解压到/opt/bigdata文件夹
[along@hdp14 resource]# tar -zxvf hadoop-3.1.4.tar.gz -C /opt/bigdata/
3.2 配置配置hadoop环境变量
查看hadoop安装的全路径
[along@hdp14 bigdata]$ cd hadoop-3.1.4/
[along@hdp14 hadoop-3.1.4]$ pwd
/opt/bigdata/hadoop-3.1.4
修改etc/profile.d/my_env.sh文件
[along@hdp11 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
文件末尾添加hadoop环境变量
#HADOOP_HOME
export HADOOP_HOME=/opt/bigdata/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
分发环境变量
[along@hdp14 hadoop-3.1.4]$ sudo /home/along/bin/axync /etc/profile.d/my_env.sh
使环境变量生效,可使用Xshell,将命令发送到所有会话
[along@hdp14 ~]$ source /etc/profile.d/my_env.sh
[along@hdp15 ~]$ source /etc/profile.d/my_env.sh
[along@hdp16 ~]$ source /etc/profile.d/my_env.sh
...
3.3 集群配置
3.3.1 修改core-site.xml文件
[along@hdp14 hadoop-3.1.4]$ cd etc/hadoop/
[along@hdp14 hadoop]$ vim core-site.xml
文件内容
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://nsvalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/bigdata/hadoop-3.1.4/data/tmpvalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>alongvalue>
property>
<property>
<name>hadoop.proxyuser.along.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.along.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.along.groupsname>
<value>*value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hdp16:2181,hdp17:2181,hdp18:2181value>
property>
configuration>
3.3.2 修改hdfs-site.xml文件
[along@hdp14 hadoop]$ vim hdfs-site.xml
配置内容
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.nameservicesname>
<value>nsvalue>
property>
<property>
<name>dfs.ha.namenodes.nsname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1name>
<value>hdp14:8020value>
property>
<property>
<name>dfs.namenode.http-address.ns.nn1name>
<value>hdp14:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2name>
<value>hdp15:8020value>
property>
<property>
<name>dfs.namenode.http-address.ns.nn2name>
<value>hdp15:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hdp16:8485;hdp17:8485;hdp18:8485/nsvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/bigdata/hadoop-3.1.4/data/journalvalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.nsname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/along/.ssh//id_rsavalue>
property>
configuration>
生产环境磁盘会有多个,可以配置多目录,这里我们是虚拟机。具体配置方式
<property>
<name>dfs.datanode.data.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2value>
property>
注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
3.3.3 修改mapred-site.xml
[along@hdp14 hadoop]$ vim mapred-site.xml
文件内容
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hdp14:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hdp14:19888value>
property>
configuration>
3.3.4 修改yarn-site.xml文件
[along@hdp14 hadoop]$ vim yarn-site.xml
文件内容
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>rmclustervalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hdp14value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hdp15value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hdp16:2181,hdp17:2181,hdp18:2181value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://hdp14:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
3.3.5 修改workers
[along@hdp14 hadoop]$ vim workers
添加内容
hdp16
hdp17
hdp18
3.3.6 删除share/doc
[along@hdp14 hadoop-3.1.4]$ pwd
/opt/bigdata/hadoop-3.1.4
[along@hdp14 hadoop-3.1.4]$ ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[along@hdp14 hadoop-3.1.4]$ rm -rf share/doc/*
3.3.7 分发hadoop-3.1.4文件夹到其他节点
axync hadoop-3.1.4/hadoop-3.1.4
3.3.8 配置ResourceManager节点
在主节点hdp14的yarn-site.xml上添加
<property>
<name>yarn.resourcemanager.ha.idname>
<value>rm1value>
property>
hdp15的yarn-site.xml上添加
<property>
<name>yarn.resourcemanager.ha.idname>
<value>rm2value>
proper3ty>
注意集群不同节点之间yarn-site.xml这个是不同的,不要覆盖了
3.4 启动初始化
3.4.1 启动zk
[along@hdp14 bin]$ zk.sh start
---------- zookeeper hdp16 启动 ------------
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.5.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper hdp17 启动 ------------
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.5.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
---------- zookeeper hdp18 启动 ------------
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.5.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
3.4.2 启动journalnode
[along@hdp16 hadoop-3.1.4]$ sbin/hadoop-daemon.sh start journalnode
[along@hdp17 hadoop-3.1.4]$ sbin/hadoop-daemon.sh start journalnode
[along@hdp18 hadoop-3.1.4]$ sbin/hadoop-daemon.sh start journalnode
查看进程
[along@hdp14 hadoop-3.1.4]$ xcall jps
=============== hdp14 ===============
8102 Jps
=============== hdp15 ===============
8321 Jps
=============== hdp16 ===============
7172 QuorumPeerMain
10649 Jps
9611 JournalNode
=============== hdp17 ===============
4197 QuorumPeerMain
5704 JournalNode
5964 Jps
=============== hdp18 ===============
4956 Jps
2878 QuorumPeerMain
4719 JournalNode
3.4.3 namenode格式化 启动和同步
hdp14节点,格式化namenode
[along@hdp14 hadoop-3.1.4]$ bin/hdfs namenode -format
...
2021-05-07 18:01:13,394 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1059449715-192.168.204.14-1620381673394
2021-05-07 18:01:13,426 INFO common.Storage: Storage directory /opt/bigdata/hadoop-3.1.4/data/dfs/name has been successfully formatted.
2021-05-07 18:01:14,232 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/bigdata/hadoop-3.1.4/data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2021-05-07 18:01:16,722 INFO namenode.FSImageFormatProtobuf: Image file /opt/bigdata/hadoop-3.1.4/data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 392 bytes saved in 2 seconds .
2021-05-07 18:01:16,749 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2021-05-07 18:01:16,847 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2021-05-07 18:01:16,848 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hdp14/192.168.204.14
************************************************************/
启动hdp14 namebode
[along@hdp14 hadoop-3.1.4]$ hdfs --daemon start namenode
hdp15上同步namenode
[along@hdp15 hadoop-3.1.4]$ bin/hdfs namenode -bootstrapStandby
成功之后启动这两台机器的namenode
[along@hdp15 hadoop-3.1.4]$ hdfs --daemon start namenode
访问web页面
http://hdp14:50070/dfshealth.html#tab-overview
http://hdp15:50070/dfshealth.html#tab-overview
可以看到2个name都是standby状态
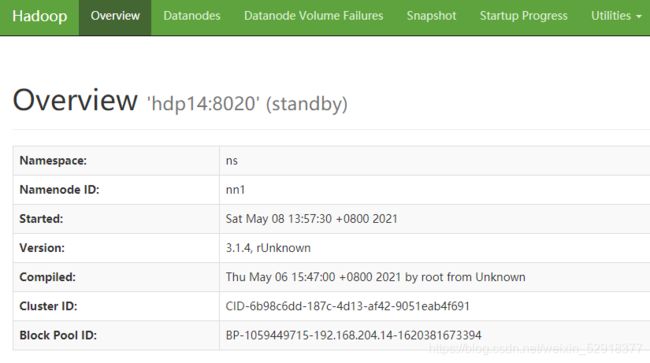
#hdp14
Overview 'hdp14:8020' (standby)
Namespace: ns
Namenode ID: nn1
Started: Fri May 07 18:05:06 +0800 2021
Version: 3.1.4, rUnknown
Compiled: Thu May 06 15:47:00 +0800 2021 by root from Unknown
Cluster ID: CID-6b98c6dd-187c-4d13-af42-9051eab4f691
Block Pool ID: BP-1059449715-192.168.204.14-1620381673394
#hdp15
Overview 'hdp15:8020' (standby)
Namespace: ns
Namenode ID: nn2
Started: Fri May 07 18:29:37 +0800 2021
Version: 3.1.4, rUnknown
Compiled: Thu May 06 15:47:00 +0800 2021 by root from Unknown
Cluster ID: CID-6b98c6dd-187c-4d13-af42-9051eab4f691
Block Pool ID: BP-1059449715-192.168.204.14-1620381673394
先强制手动是其中一个节点变为active
[along@hdp14 hadoop-3.1.4]$ bin/hdfs haadmin -transitionToActive nn1 --forcemanual
You have specified the --forcemanual flag. This flag is dangerous, as it can induce a split-brain scenario that WILL CORRUPT your HDFS namespace, possibly irrecoverably.
It is recommended not to use this flag, but instead to shut down the cluster and disable automatic failover if you prefer to manually manage your HA state.
You may abort safely by answering 'n' or hitting ^C now.
Are you sure you want to continue? (Y or N) y
2021-05-07 18:44:00,417 WARN ha.HAAdmin: Proceeding with manual HA state management even though
automatic failover is enabled for NameNode at hdp15/192.168.204.15:8020
2021-05-07 18:44:00,909 WARN ha.HAAdmin: Proceeding with manual HA state management even though
automatic failover is enabled for NameNode at hdp14/192.168.204.14:8020
刷新web页面hdp14已变成active
Overview 'hdp14:8020' (active)
3.4.4 初始化zkfc和启动zkfc
hdp14上初始化
[along@hdp14 hadoop-3.1.4]$ hdfs zkfc -formatZK
hdp14启动zkfc
[along@hdp14 hadoop-3.1.4]$ sbin/hadoop-daemon.sh start zkfc
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
hdp15上启动zkfc
[along@hdp15 hadoop-3.1.4]$ sbin/hadoop-daemon.sh start zkfc
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
3.4.5 启动resourceManager
hdp14 启动 resourceManager
[along@hdp14 hadoop-3.1.4]$ yarn --daemon start resourcemanager
hdp15 启动 resourceManager
[along@hdp15 hadoop-3.1.4]$ yarn --daemon start resourcemanager
web页面查看一下

3.4.6 启动历史服务器
[along@hdp14 hadoop-3.1.4]$ mapred --daemon start historyserver
通过web页面查看一下
http://hdp14:19888/jobhistory
集群启动完成,看一下所有的进程
[along@hdp14 hadoop-3.1.4]$ xcall jps
=============== hdp14 ===============
20208 JobHistoryServer
22231 ResourceManager
22793 NameNode
21899 DFSZKFailoverController
22894 Jps
=============== hdp15 ===============
77299 NameNode
77412 DFSZKFailoverController
77700 Jps
77498 ResourceManager
=============== hdp16 ===============
117331 JournalNode
7172 QuorumPeerMain
119001 Jps
33225 ZooKeeperMain
117548 NodeManager
117167 DataNode
=============== hdp17 ===============
119792 JournalNode
4197 QuorumPeerMain
120711 Jps
119928 NodeManager
119647 DataNode
=============== hdp18 ===============
32215 JournalNode
33303 Jps
32392 NodeManager
32061 DataNode
2878 QuorumPeerMain
3.4.7 验证namenode高可用
在active namenode 节点,查看namenode的进程
[along@hdp14 hadoop-3.1.4]$ jps
15905 NameNode
16004 Jps
15494 ResourceManager
15166 DFSZKFailoverController
杀掉namenode进程
[along@hdp14 hadoop-3.1.4]$ kill -9 15905
刷新hdp14web页面,发现已经不能访问,刷新hdp15web页面,发现hdp15的namenode节点,已经从standby变成了active
Overview 'hdp15:8020' (active)
namenode高可用验证完成
3.4.8 验证yarn高可用
访问resourceManager地址
http://hdp15:8088
http://hdp14:8088
可以看到进入页面后两个地址都变成了
http://hdp14:8088/cluster
这个时候我们杀掉resourceManager所在的进程
[along@hdp14 hadoop-3.1.4]$ jps
16309 Jps
15494 ResourceManager
15166 DFSZKFailoverController
[along@hdp14 hadoop-3.1.4]$ kill -9 15494
刷新web页面,这个时候发现都进不去了,我们再打开
http://hdp15:8088
这个时候可以访问,yarn高可用验证成功
附录:
集群搭建的补充:必看
解决hadoop执行MapReduce程序时Ha和yarn的冲突问题
https://blog.csdn.net/weixin_52918377/article/details/116751791
解决hadoop高可用,使用start-dfs.sh脚本启动时,namenode启动不了的问题
https://blog.csdn.net/weixin_52918377/article/details/116756919