实验3Hive数据操作
实验3Hive数据操作
实验目的及要求
-
了解Hive的基本操作。
-
了解Hive的内部表与外部表的区别。
-
掌握表中数据的导入和导出的方法。
实验系统环境及版本
-
Linux Ubuntu 20.04
-
JDK1.8
-
Hadoop3.1.0
-
MySQL8.0.28
-
Hive3.1.2
实验任务
- Hive表中数据的导入和导出。
实验内容及步骤
-
Hive数据的导入
-
从本地文件系统中导入数据到Hive表。
在Hive中创建一个test表,包含id和name两个字段,数据类型分别为Int和String,以“\t”为分隔符,并查看结果。
create table test(id int,name string)
row format delimited fields terminated by ‘\t’
stored as textfile;

将Linux本地/opt/datas目录下的test.txt文件导入test表中:
load data local inpath ‘/opt/datas/test.txt’ into table test;

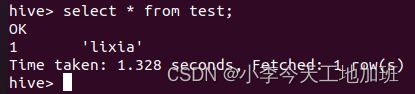
查看test表中是否成功导入数据:
select * from test;
将HDFS上的数据导入Hive中。
开启一个新终端,在HDFS上创建/myhive目录:
hdfs dfs -mkdir /myhive
![]()
将Linux本地/opt/datas目录下的文件test.txt文件上传到HDFS的/myhive中,并查看是否上传成功:
hdfs dfs -put /opt/datas/test.txt /myhive
hdfs dfs -ls /myhive

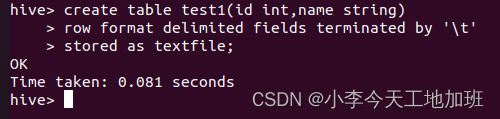
在Hive中创建名为test1的表:
create table test1(id int,name string)
row format delimited fields terminated by ‘\t’
stored as textfile;
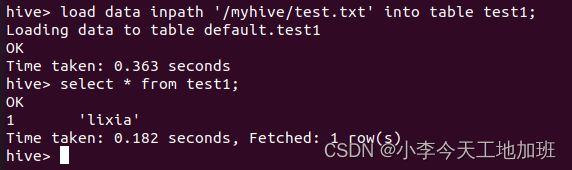
将HDFS的/myhive中的数据文件test.txt导入Hive的test1表中,并查看结果:
load data inpath ‘/myhive/test.txt’ into table test1;
select * from test1;
提示:HDFS中的数据导入Hive中与本地数据导入Hive中的区别是Load Data后少了Local关键字。
从其他表中查询出相应的数据并导入Hive中。
在Hive中创建一个名为test2的表:
create table test2(id int,name string)
row format delimited fields terminated by ‘\t’
stored as textfile;

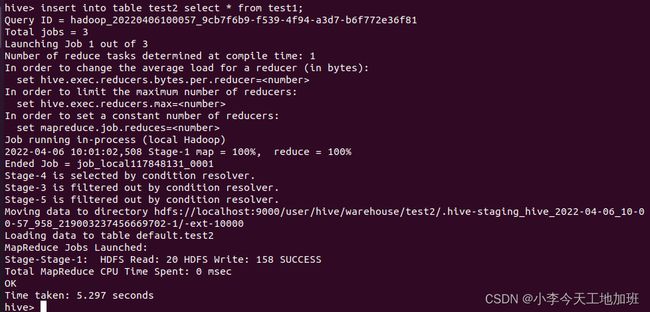
用下面两种方法将test1表中的数据导入test2表中:
insert into table test2 select * from test1;
或
insert overwrite table test2 select * from test1;
导入完成后,用select语句查询test2表:
select * from test2;

在创建表的同时从其他表中查询出相应数据并插入所创建的表中。
在Hive中创建表test3并直接从test2表中导入数据:
create table test3 as select * from test2;
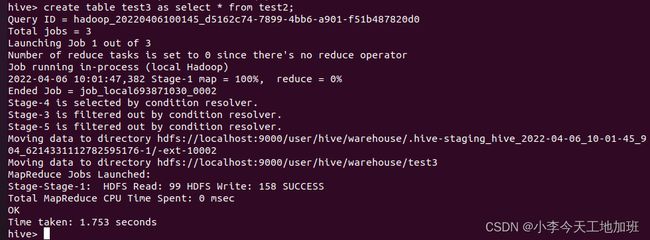
创建并导入完成后,用select语句查询结果:
select * from test3;

创建表,并指定加载数据在HDFS中的其他位置。
在Hive中创建表test4:
create table if not exists test4(
id int,name string)
row format delimited fields terminated by ‘\t’
location ‘/user/hive/warehouse/test4’;

开启一个新终端,上传数据到HDFS中:
hdfs dfs -put /opt/datas/test.txt /user/hive/warehouse/test4;

创建并导入完成后,用select语句查询结果:
select * from test4;

Hive数据导出
导出到本地文件系统
将Hive中的test表数据导出到本地文件系统/opt/datas/output中,output目录在数据导出时自动创建,不用事先创建。
注意:该方法和导入数据到Hive不一样,不能用Insert Into来将数据导出:
insert overwrite local directory ‘/opt/datas/output’ select * from test;
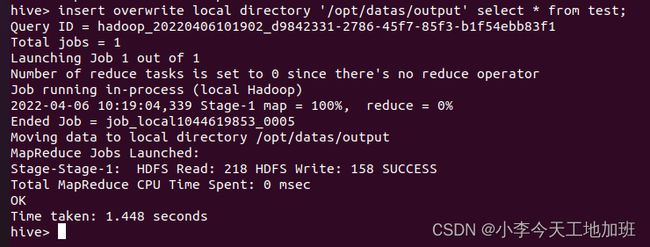
导出完成后,在Linux本地切换到/opt/datas/output目录,通过cat命令查询导出文件的内容:
cd /opt/datas/output
ls
cat 000000_0

可以看到导出的数据,字段之间没有分隔开,所以使用下面的方式,将输出字段以“\t”键分隔:
insert overwrite local directory ‘/opt/datas/output’
select concat(id,‘\t’,name) from test;
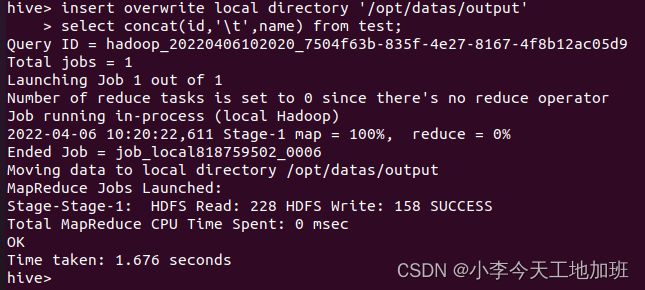
也可以使用下面的方式,将输出字段以“\t”键分隔:
insert overwrite local directory ‘/opt/datas/output’
row format delimited fields terminated by ‘\t’
select id,name from test;
通过cat命令查询/opt/datas/output目录下的导出文件:
cd /opt/datas/output/
cat 000000_0

Hive中数据导出到HDFS中
开启一个新终端,在HDFS中创建/myhive/output目录:
hdfs dfs -mkdir /myhive/output

将Hive表test中的数据导出到HDFS的/myhive/output目录中:
insert overwrite directory ‘/myhive/output/’
row format delimited fields terminated by ‘/t’
select id,name from test;

导出完成后,在HDFS的/myhive/output目录下查看结果:
hdfs dfs -cat /myhive/output/*

导出到Hive的另一个表中
将Hive的表test中的数据导入test5表中(两表字段及字符类型相同)。
在Hive中创建一个表test5,有id和name两个字段,数据类型分别为Int和String,以“\t”为分隔符:
create table test5(id int,name string)
row format delimited fields terminated by ‘\t’
stored as textfile;

将test表中的数据导出到test5表中:
insert into table test5 select * from test;

导出完成后,查看test5表中数据:
select * from test5;

Export语句导出
Export语句可以将Hive表中的数据导出到Hadoop集群的HDFS的其他目录下:
export table test to ‘/user/hive/warehouse/export/test’;

导出完成后,在HDFS的/user/hive/warehouse/export/test目录下查看导出的数据:
hdfs dfs -cat /user/hive/warehouse/export/test/data/*

Hive Shell命令导出
在不启动Hive的情况下,也可以将HQL语句的查询结果存储在本地指定目录下的test1.txt文件中。
退出Hive:
quit;

切换到Hive的安装目录:
cd /opt/hive
![]()
执行查询:
bin/hive -e ‘select * from test;’> /opt/datas/test1.txt;

开启一个新终端,切换到/opt/datas目录,查看test1.txt文件的内容:
cd /opt/datas
cat test1.txt

将HQL语句存储在执行脚本文件中
将执行脚本文件的执行结果存储在指定目录下的test2.txt2文件中。
创建hivef.sql脚本文件:
cd /opt/datas
vim hivef.sql
![]()
将HQL语句“select * from test;”保存其中,并退出。
切换到Hive的安装目录:
cd /opt/hive
执行hivef.sql脚本文件中的查询语句,并将查询结果输出到test2.txt文件中:
bin/hive -f /opt/datas/hivef.sql > /opt/datas/test2.txt
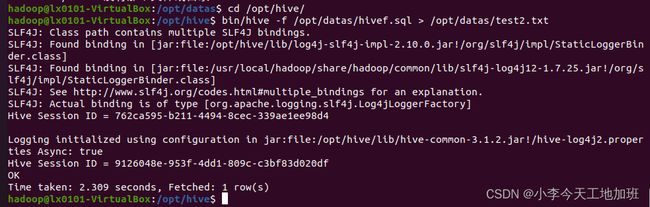
开启一个新终端,切换到/opt/datas目录,查看test2.txt文件的内容:
cd /opt/datas
cat test2.txt
