小米云原生文件存储平台化实践:支撑 AI 训练、大模型、容器平台多项业务
小米作为全球知名的科技巨头公司,已经在数百款产品中广泛应用了 AI 技术,这些产品包括手机、电视、智能音箱、儿童手表和翻译机等。这些 AI 应用主要都是通过小米的深度学习训练平台完成的。
在训练平台的存储方案中,小米曾尝试了多种不同的存储方式,包括 Ceph+NFS、HDFS 和对象存储挂载等。然而,这些不同的存储方式导致了数据冗余和维护管理成本的增加,同时也带来了扩展性和性能方面的问题。另外,随着公司云原生化进程的推进,越来越多的应用从物理机迁移到容器平台,这进一步增加了对文件存储和多节点共享访问数据的需求。
因此,小米存储团队自 2021 年开始启动了文件存储项目,基于 JuiceFS 构建了一个文件存储平台化产品,并通过 CSI Driver 组件提供了云原生存储的能力,以满足上述各种业务场景对文件存储的需求。
目前,这个平台已经承载了超过 50 亿个文件,总容量 2.5PB 以上,集群吞吐达到每秒 300~400Gbps。业务场景也在不断扩展,涵盖了大模型数据存储、大数据以及数据湖上云等领域。在接下来的内容中,我们将深入介绍小米在这一过程中的设计思路和实践经验。
01 为什么要建设统一的存储平台
一方面,我们面临着以下三方面的需求增长:日益增长的应用场景:随着人工智能业务的发展,我们对大规模文件存储的需求也在快速增长,此外在容器内共享访问数据、存算分离、大数据上云、大模型等场景同样对文件存储有着众多的应用需求,这些场景均需要高效、可靠的文件存储服务。
统一的文件存储方案:在我们立项并进行 JuiceFS 项目之前,在机器学习平台我们采用了 Ceph RBD+NFS、S3 FUSE、HDFS 等多种数据存储方式,我们期望能够统一存储方案,将大部分数据放到同一存储平台,降低维护及数据冗余成本。
混合云场景:小米作为全球化企业,业务遍布全球多个国家,在海外多个区域都会有文件存储相关的业务需求,我们需要满足私有云+公有云一体的文件存储架构。我们预期中的存储平台需要具备如下特性:
-
功能丰富,拥有完善的存储功能,支持 POSIX 等多种访问协议,同时具备易用性,面向云原生平台设计。
-
规模扩展性,能够支撑百亿文件、百 PB 容量规模的文件存储能力,能够弹性扩展。
-
性能与成本,满足 AI 高并发训练等场景的性能需求,服务稳定可靠同时兼顾存储成本。
-
混合云场景,支持多种存储后端,支持云上云下不同应用环境。
-
开发迭代,我们有一个明确的目标,即借助开源项目,不重复造轮子。易于开发扩展与维护, 能够持续迭代。
存储选型:CephFS vs JuiceFS
我们对比了 JuiceFS、CephFS 以及其他一些业界文件系统的性能和功能。JuiceFS 社区文档也提供了一些的对比信息,如果您感兴趣,可以查阅 JuiceFS 社区文档。
首先,CephFS 在我们的需求中有一些无法满足的部分,例如,我们希望在公有云上部署,而 CephFS 可能更适合在 IDC 环境中使用。其次,CephFS 在集群规模达到一定程度时(例如 PB 级别),在平衡和元数据服务器性能方面可能会遇到一些瓶颈。

在 2021 年初,JuiceFS 项目刚刚开源,我们就开始关注了。与 CephFS 等其他开源文件存储系统相比,JuiceFS 采用了插件化的设计思想,为我们提供了更大的灵活性,使我们能够根据自身需求进行定制化开发。JuiceFS 还提供了丰富的产品功能,能够满足我们的特定场景需求。
同时,考虑到 Ceph 作为底层存储服务在小米内部已经大规模应用了多年,我们可以将 Ceph RADOS 作为 JuiceFS 的数据存储池,在 IDC 机房内提供高性能和低延迟的文件存储服务。这是我们在选型时的基本思考,以下这些优势是我们选择了 JuiceFS 作为整体存储服务的基础。
JuiceFS 优势

JuiceFS 采用了数据和元数据分离存储的架构,同时具备完全可插拔的设计,我个人认为这个构想非常出色。在进行基于 JuiceFS 的二次开发时,我们能够轻松地适应内部企业需求,充分利用已有的成熟组件,以满足不同应用场景下的数据管理需求。
JuiceFS 功能十分丰富,它兼容了 POSIX、HDFS、S3 等多种访问协议,支持数据的加密、压缩、文件锁等多项功能,并提供了 CSI 组件的支持,同时还具备相对复杂的扩展功能,这些满足了我们对存储服务的基本需求。
性能方面 JuiceFS 表现卓越,借助其独特的数据切分管理和客户端缓存加速能力,为客户端提供了出色的吞吐性能。
JuiceFS 社区生态非常活跃,根据我所接触到的一些项目,我认为 JuiceFS 社区的运作是最出色的。值得一提的是,在开源之前,JuiceFS 首先在商业领域积累了经验并应用于实际场景中,这为我们提供了许多有价值的借鉴。
通过以上考虑,我们当时决定基于 JuiceFS 构建一个面向云原生设计的、高性能且具有弹性可扩展性的共享文件系统。
02 小米存储平台架构及能力
作为一个文件存储平台,我们的服务是处于底层位置的,旨在满足小米企业内多样的需求场景。这些场景不仅包括自驾等基础应用,还涵盖了容器共享存储、大数据等多种场景。我们的目标是将产品化功能提供给业务部门,增强服务的易用性,使业务方能够更轻松地使用我们的服务。
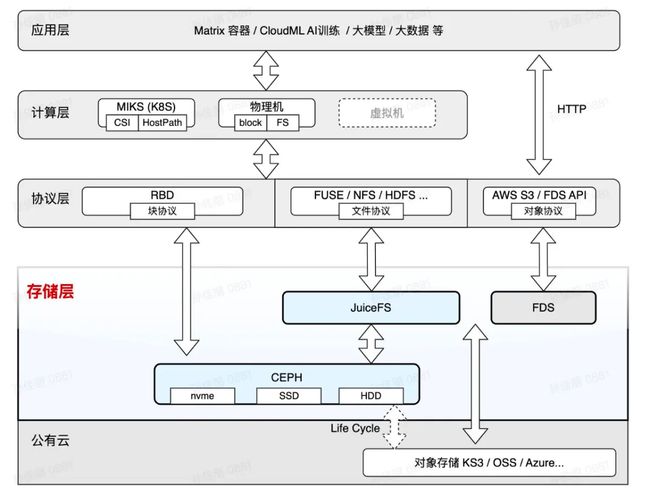
在上述架构图中,作为存储平台,我们不仅提供了 JuiceFS 文件存储服务,还提供了基于 Ceph RBD 的块存储服务。同时,Ceph 为 JuiceFS 提供了底层对象存储支持。我们还拥有内部的 FDS 对象存储服务,可以适应 IDC 以及各种公有云对象存储,为业务提供无缝的跨多云的服务。我们向上层提供了不同的协议支持,包括块协议、文件协议和对象协议。在更高层次,我们为 PaaS 平台和计算层提供支持,最顶层则是应用层。
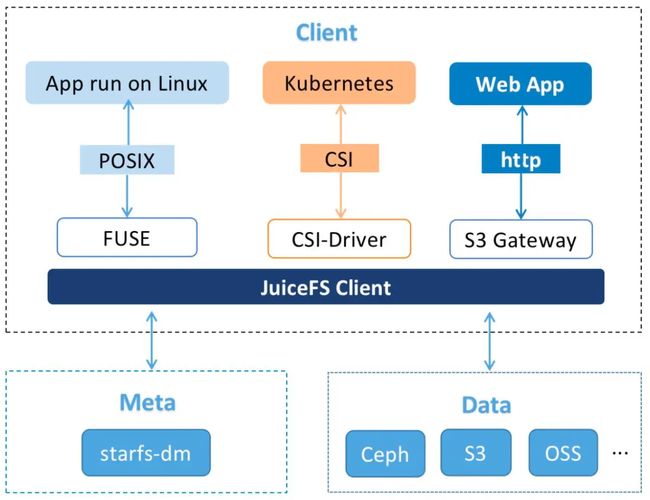
小米的 JuiceFS 架构与社区版 JuiceFS 基本相同。在 JuiceFS 客户端方面,我们提供上层协议支持,并与我们的 meta 服务和 data 服务进行底层对接。
我们的项目启动较早,当初在 JuiceFS 开源时,meta 服务的选择仅限于使用 Redis。然而,我们的首个业务需求可能涉及到数亿级别的文件规模,而 Redis 实际上难以有效支持这一规模。
与此同时,我们的产品是一个平台化项目,因此我们决定自行开发一个分布式的 meta 服务,用于统一管理集群,包括之前提到的复杂功能,具备这样的中心化能力实际上会更容易实现我们的目标。为存储元数据信息,我们选择了分布式 meta,基于另外一款开源存储项目 CubeFS 的 meta 模块实现。
优化1:统一集群管理
根据我们的场景需求,我们对 JuiceFS 做了一些优化。“集群统一管理” 这是我们与 JuiceFS 社区版的架构最大的区别,也是我们很多平台功能实现的基础。

在 JuiceFS 社区版中,文件系统之间缺乏统一的管理,用户需要自行设置他们自己的 meta 服务、bucket 等。例如,当业务部门创建一个新的卷时,他们需要自己申请 Redis、bucket、网关等,并设置后台任务,这使得整个过程繁琐且依赖于客户端。如果业务部门需要创建另一个卷,他们必须重复之前的工作,因为所有工作都是在客户端完成的。
小米的主要不同之处在于我们将卷的管理进行了集中,将通用功能下沉,使得业务使用更加便捷。

首先,我们可以看到在这个层次上,最顶层是 meta 服务,分为 master 和 metanode。我们通过 meta master 进行了统一管理,将跨客户端的工作功能集成到了统一的管理层次。这包括基本的管理功能,如卷的创建和删除,以及存储池与 bucket 的管理,还包括一些会话管理机制。一些异步任务由中心统一维护,包括 compaction、数据清理等流程。
由于我们有一个 master 层,因此我们能够提供一些产品功能,包括权限接入,建立了统一的网关,并提供账单服务,以及对应内部控制台的功能接入。
优化2:S3 网关
社区版的 S3 网关可以与一个卷相对应,通常需要进行 Minio 的 AK/SK 配置。我们首先在卷内进行了统一的管理,这使得它能够支持集群内所有卷的访问,并提供了一个统一的 S3 接入域名。
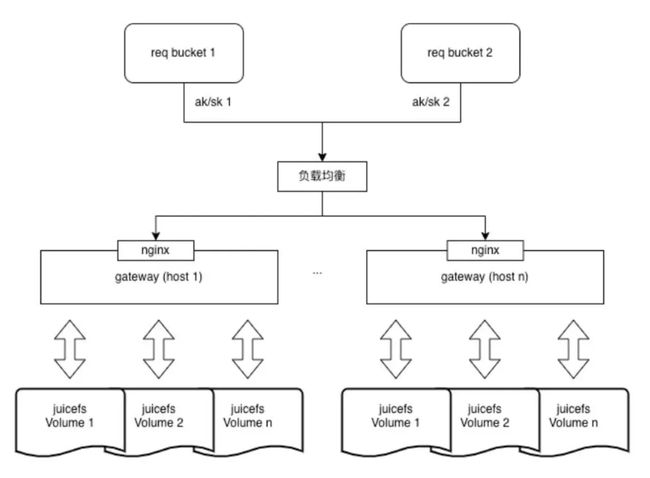
因此,我们在这一层上实现了文件系统的动态加载,使得多个卷可以通过同一个网关服务访问数据。同时,在这一层次上,我们也实现了小米内部 IAM 权限系统的适配,支持多租户的 AK/SK。
在公共参数方面,例如缓冲缓存(--buffer-cache)、缓存大小(--cache-size),这些参数可以在多个卷之间全局共享,还有与 meta 相关的连接池实现了共享,支持多个卷的网关管理。
此外,我们在网关服务上提供了一个完备的监控系统,用于监控请求吞吐量、延迟、SLA 等性能指标。
优化3:存储类型及多池管理

在进行了统一管理之后,我们进行了存储类型的封装。对于业务方来说,他们不需要关心数据存储在后端的存储介质或服务提供商。用户只需要选择适合其需求的服务类型。这个系统提供了三种基本类型,包括性能型、容量型和成本型。性能型对应后端的 Ceph SSD 存储,容量型对应机械硬盘,而成本型则对接对象存储。每种类型适用于不同的使用场景,因此提供了不同的吞吐量和延迟水平。
在存储类型方面,我们引入了一层多池管理机制,对底层存储服务进行了统一管理和封装。相对于社区版中卷(bucket)与存储池的一对一关系,我们支持了多池管理功能,主要实现了以下能力:
首先,与业务相关的配置。存储池的配置以及 Ceph 的配置都由元数据系统进行统一管理,无需用户额外配置 Ceph 的环境变量或配置文件。
第二点,我们允许卷设置存储类型,存储类型与存储池关联,并且在数据的切片级别进行记录。存储类型与其绑定的存储池是可以切换的,这样可以满足超大容量卷(百 PB 级别)的存储需求。

我们的多池管理设计主要来源于对 Ceph 的思考。当 Ceph 集群规模达到一定程度时,性能问题可能会显现出来,我们不希望维护特别大规模的 Ceph 集群,而是会建立新的集群,相当于将大容量划分为多个小集群来进行管理。这有利于减少性能开销,减少 OSD 存储故障的概率。同时也降低了管理节点的数量。我们的操作就相当于将存储类型绑定的存储池切换到新的存储池上,旧数据仍然存储在旧存储池中,而新的数据将被存储在新的存储池上,不会产生数据均衡挪动。
此外,我们还有更多操作的空间,可以按切片级别将数据迁移到不同的存储池。基于这一能力,我们可以实现更复杂的功能,如根据文件访问情况的冷热分层、基于 ec 纠删码+ 3 副本的大小 IO 分流优化等。
产品能力
我们为集团内部提供了丰富的产品功能,这些功能在企业内部是非常必要的功能:
-
权限系统:我们接入了 IAM(身份与访问管理)资源权限管理系统,适配通用的鉴权功能,以确保只有经过授权的用户可以访问资源。同时能够根据卷的归属找到相关项目部门及负责人,从而将存储资源精准地定位到实际负责的实体,有助于企业更好地进行管理。
-
控制台:接入小米融合云控制台,我们提供了管理卷和文件的功能,方便业务使用
-
监控:我们为 JuiceFS 集群和客户端提供了监控看板,帮助企业实时了解系统的性能和状态。
-
审计:对文件操作和数据读写进行审计,记录审计日志。这对一些敏感数据的业务非常重要,因为它可以告诉您哪些客户端正在访问文件,以及文件是否曾被篡改或删除。
-
回收站:我们支持回收站功能,可以帮助企业规避因误删数据而带来的风险,让数据更加安全可控。
-
账单:我们提供按不同存储类型和存储容量计费的功能,帮助企业了解和管理存储资源的费用。
大部分业务人员对于存储产品并不十分了解,因此在选择合适的存储类型时常常感到困难。为了帮助内部用户更好地做出选择,我们提供了一些通用场景建议。在控制台的卷文件管理方面,我们采用了类似于 Minio 平台的 S3 网关,用于多卷的文件内容管理,用户能够方便的进行文件管理和分享下载。
基于这些产品能力及云原生 CSI Driver 的功能,我们已经对接了小米容器平台及机器学习 PaaS 平台,业务根据需要选择不同的集群与存储类型使用我们的 JuiceFS 文件存储服务。在容器内使用 JuiceFS 时,我们更倾向于优先采用静态卷的方式来进行接入。首先,静态卷接入的优势在于它们是明确定义和创建的,对其名称和用途都有明确的规定。相比之下,动态卷的使用往往涉及到更复杂的权限管理。另外,对于更底层的 Kubernetes 平台,我们也为该服务提供了静态卷和动态卷两种接入方式。目前,我们的大部分服务都是以原生方式提供的。
分布式 meta
我们的元数据部分则是基于 CubeFS 进行开发的。最早,CubeFS 是由京东开源,是中国第一个开源分布式文件系统,涵盖了元数据(meta)、数据(data)以及最近的纠删码(EC)模块。
然而,当初我们并没有直接采用 CubeFS 的全部,主要有两个原因。首先,我们更希望能够充分利用公有云的资源,而当时的 CubeFS 仅支持自建存储。其次,我们对 Ceph 有更深入的了解,希望能够在底层的数据部分进行灵活替换。因此,当初我们只采用了 CubeFS 的元数据部分。
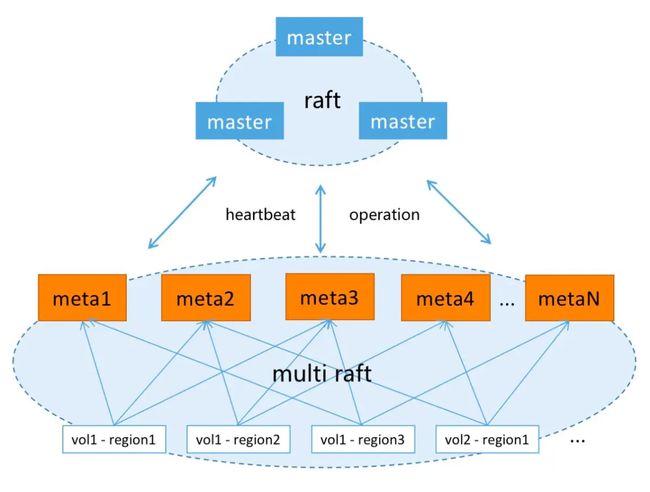
元数据是基于 Multi Raft 进行全内存实现的,架构分为两个模块:Master 和 Meta。
-
Master 是一个集群管理节点,负责管理存储卷和集群的基本配置信息,以及管理和调度 meta region,并向外部提供 HTTP 接口。
-
meta 作为元信息节点。它通过 Multi Raft 管理 region,并向外部提供 TCP 和 HTTP 接口,支持横向扩展。
数据被划分为不同的 region。每个文件系统都有多个数据分片,按照 inode 区间进行划分。随着数据量的增长,分片的数量也会增加。每个分片都会被均匀地分布在不同的元数据节点上。在一定条件下,会进行分裂操作,以便更好地实现水平扩展。目前,我们的生产环境中最大的一个集群已经拥有了 30 多亿个文件,预计可以扩展到百亿级别。

上图是 meta region 分裂的示意图,如果前两个 region 被写满,它就会变成只读状态。当最后一个 region 的文件数量达一定规模或节点内存用量超过了阈值,那么最后一个分片就会分裂成两个,实现了 region 的横向扩展。
03 应用场景
JuiceFS 的应用场景主要包括 4 个场景:机器学习、文件持久化存储、共享数据访问和大数据分析。目前,机器学习是我们最大的业务领域,大数据及大模型方面我们正在积极探索中。

上图展示了我们整体业务发展的情况。我们的单一集群已经达到了数十亿文件和 PB 级别的数据量,吞吐量达到数百 Gbps 的级别。
在过去的两年中,我们正式地将 JuiceFS 接入到了我们的学习平台。目前,它主要用于提供自动驾驶训练、部分手机训练和新一代语音训练的支持。
去年,我们还支持了容器平台,发布了公共集群,并提供了容器平台的接口,以满足不同应用的需求。接着,我们接入了小爱语音的训练业务。他们以前的部署方式是使用物理机上的 SSD 来运行 NFS 服务。然而,随着数据量的不断增长以及团队规模的扩大,他们很难进行扩容。此外,他们在数据管理方面也面临挑战。因此,去年他们决定采用我们的服务。
今年,我们进行了一些新业务领域的尝试,其中包括将大数据 Iceberg 迁移到云端进行性能验证和比较。此外,在大型模型的存储方面,我们已经支持了完整的存储,包括原始语料的接入、算法训练和基本模型文件的存储。
大数据上云场景探索
在将大数据 Iceberg 迁移到云端的性能验证与同类产品相比,JuiceFS 在多种规格的 IO 读写场景下均表现出色,某些场景性能略优。

如上图所示,时间越短越好,可以看到 JuiceFS 在某些场景的速度更快,某些场景略慢,整体性能可以和公有云产品媲美。同时值得一提的是,我也了解到一些其他的存储产品,在数据组织管理和加速设计方面或多或少受到了 JuiceFS 的启发。
语音场景业务收益
我们目前已经有许多业务迁移并使用了 JuiceFS 文件存储服务,下面是以语音训练业务为例,介绍一下迁移到 JuiceFS 后,给业务方带来的收益:
-
容量收益:语音组数据之前主要存放在 NFS 上,经常遇到某台存储机器被写满,导致该机器上同学无法继续写入的问题。随着训练规模的增加,容量扩展和容量管理都不方便。云平台-云存储组提供的 JuiceFS 理论上可以更好的满足我们的需求。
-
成本收益:JuiceFS 单位容量的成本低于 NFS,目前语音组数据已由(NFS+FDS)迁移至 JuiceFS,根据机器成本计算,每 T 容量每月的成本更低。
-
安全性:语音 NFS 采用 RAID10 与 RAIDO 混部的方式,而目前采用3副本模式存储,JuiceFS 上的数据安全性更有保障。
-
并发性:NFS 在使用时,用户的 IO 经常会集中在某一个存储节点上,某一台存储节点上的某个用户运行重 IO 任务后,同存储节点下的其他用户会受影响。而 JuiceFS 将数据分散到多个节点上,多用户多机并发访问时,用户相互影响小,IO 上限更高。
04 未来规划
更低成本
-
冷热分层:我们鼓励更多地使用公有云对象存储,以降低数据存储成本。
-
IDC 优化:我们引入了高密度机型以减少成本,并对存储方式进行了优化,采用了 EC 纠删码存储方式,并实现了大小 IO 的分离。
-
元数据管理:我们的元数据目前采用了全内存模式,对于大量小文件的应用场景,元数据在内存中的占用可能会相当大,成本很高。为了降低处理成本,我们需要支持 DB 模式,即不再使用全内存存储,而是采用本地的 rocksdb + ssd 方式存储。
提升性能
-
提高全闪存储性能,支持 RDMA、SPDK,降低延时
-
GDS (GPU Direct Storage) 面向 AI 大模型场景,提供高速存储 能力
-
优化 Meta 传输 proto 协议,减少 marshal 开销及数据传输量
丰富功能
-
适配社区版本最新功能,如目录配额功能。
-
希望能实现 JuiceFS 商业版的部分能力,如支持分布式缓存功能,快照功能
-
lifecycle 生命周期管理
-
QoS 限速能力
05 JuiceFS 使用经验分享
-
客户端升级优化:在早期,我们面临了客户端升级的一些挑战。具体来说,Mount Pod 客户端升级要求迁移 Mount Pod 上的所有业务,重新构建 Mount Pod,然后 Mount Pod 才能更新。这一过程非常繁琐,给业务方带来了很多困扰。
为了解决这个问题,我们实现了热重启功能,无需卸载即可升级客户端。通过 Unix Domain Socket 传递
/dev/fuse文件描述符,并重新构建文件句柄,从而实现了新进程对挂载点的重建。这一改进使得 CSI Driver 升级时则无需重新调度 Mount Pod,大大降低了升级的难度。 -
本地磁盘缓存优化:在容器场景中,客户端磁盘通常是机械硬盘。当需要读取的数据集较大时,如果本地缓存空间有限,会导致缓存命中率非常低。尤其是当将 Ceph 作为存储池时,一般不建议在业务中启用缓存。
-
预读优化:针对偏向于随机读取的场景,预读可能导致带宽大幅增加(高达数十倍)。为了解决这个问题,我们引入了预读放大带宽的监控机制。当预读放大过多时,我们建议业务关闭预读配置。需要指出的是,这种情况相对较为极端,在大多数数据场景中,启用预读仍然可以显著提升性能。
-
客户端开销优化:由于我们是通过 Fuse 用户态进程挂载文件系统,会引入额外的开销。如果宿主机挂载了大量卷,可能会导致内存资源的大量占用。因此,我们建议在使用卷的时候提前规划好,可以考虑使用子目录方式代替多卷挂载,以减少内存资源开销。