Python函数式编程之高阶函数(二)
D.常用的高阶函数:map、filter、reduce、sorted
这几个函数均为高阶函数,其也为Python内置的函数。接下来我们看一下这几个函数的用法以及其内部原理是怎样的:
D1.Map函数
map函数接收的是两个参数,一个函数,一个序列,其功能是将序列中的值处理再依次返回至列表内。其返回值为一个迭代器对象--》例如:
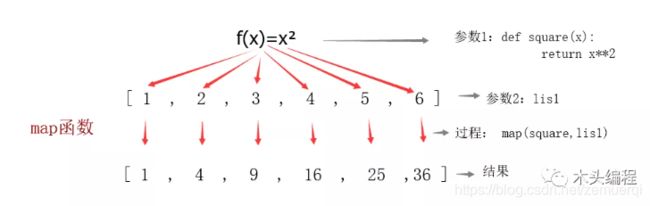
Round1:当seq(序列)只有一个时,将函数func作用于这个seq的每个元素上,并得到一个新的seq。
例如:
>>def number(x):... return x*x...>>map(number,[1,2,3,4,5,6])[1,4,9,16,25,36]#会发现结果就是上图#其次回发现map第一个参数传入的是number函数对象,而不是调用number函数#有小伙伴们会说,这个简单呀,可以直接使用列表推导式或者循环解决不就行了>>[number(i) for i in [1,2,3,4,5]][1,4,9,16,25,36]#的确可以,当然用循环的话还需要声明空列表,然后追加,会显得更加复杂而不好理解;:
Round2:当seq多于一个时,map可以并行(注意是并行)地对每个seq执行如下图所示的过程:
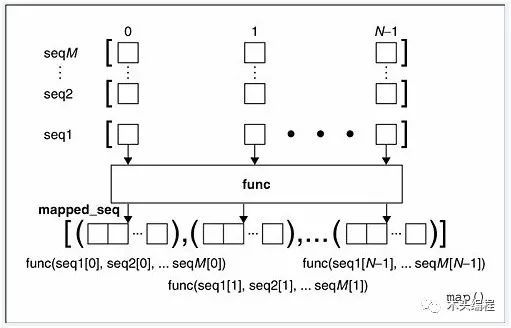
从图可以看出,每个seq的同一位置的元素同时传入一个多元的func函数之后,得到一个返回值,并将这个返回值存放在一个列表中。下面我们看一个有多个seq的例子
>>print map(lambda x , y : x ** y, [2,4,6],[3,2,1])[8, 16, 6]#大家可以思考:如果需要获取两个列表的每个元素的和以及每个元素的差进行构成一个元组,如果实现?
注意:map无法处理seq长度不一致、对应位置操作数类型不一致的情况,这两种情况都会报类型错误
Round3:使用map()函数可以实现将其他类型的数转换成list,但是这种转换也是有类型限制的,具体什么类型限制,在以后的学习中慢慢摸索吧。这里给出几个能转换的例子:
***将元组转换成list***>>> map(int, (1,2,3))[1, 2, 3]***将字符串转换成list***>>> map(int, '1234')[1, 2, 3, 4]***提取字典的key,并将结果存放在一个list中***>>> map(int, {1:2,2:3,3:4})[1, 2, 3]***字符串转换成元组,并将结果以列表的形式返回***>>> map(tuple, 'agdf')[('a',), ('g',), ('d',), ('f',)]#将小写转成大写def u_to_l (s):return s.upper()print map(u_to_l,'asdfd')
D2.Filter函数
filter函数也是接收一个函数和一个序列的高阶函数,其主要功能是过滤。其返回值也是迭代器对象,例如:
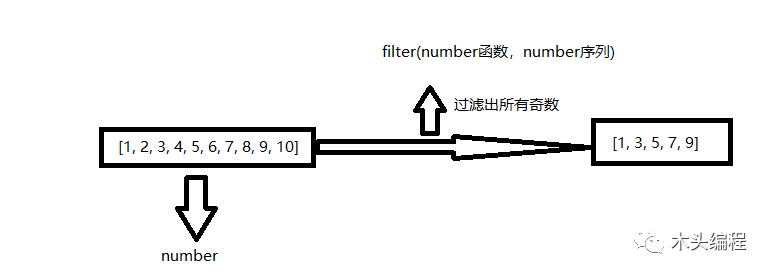
语法:
filter(function, iterable)
实例:
# 过滤列表中所有奇数def number(n):return n % 2 == 1newlist = list(filter(number, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))print(newlist)#结果输出:[1, 3, 5, 7, 9]
思考:过滤出1~100中平方根是整数的数;
D3.reduce函数
reduce函数也是一个参数为函数,一个为可迭代对象的高阶函数,其返回值为一个值而不是迭代器对象,故其常用与叠加、叠乘等,图示例如下:

例如:
#reduce函数不是内置函数,而是在模块functools中的函数,故需要导入from functools import reducenums=[1,2,3,4,5,6]#reduce函数的机制def reduce_test(func,array,ini=None): #ini作为基数if ini == None:ret =array.pop(0)else:ret=inifor i in array:ret=func(ret,i)return ret#reduce_test函数,叠乘print(reduce_test(lambda x,y:x*y,nums,100))#reduce函数,叠乘print(reduce(lambda x,y:x*y,nums,100))
D4.sorted函数
Python内置函数,主要可以实现排序操作;说到排序,大家肯定会联想到列表中的sort方法;
列表有自己的sort方法,其对列表进行原址排序,既然是原址排序,那显然元组不可能拥有这种方法,因为元组是不可修改的。
而sorted函数则会返回副本;
注:默认sort和sorted方法由小到大进行排序排序,reverse=True时,由小到大进行排序
sort方法还有两个可选参数:key和reverse
1、key在使用时必须提供一个排序过程总调用的函数:
x = ['mmm', 'mm', 'mm', 'm' ]x.sort(key = len)print (x) # ['m', 'mm', 'mm', 'mmm']
2、reverse实现降序排序,需要提供一个布尔值:
y = [3, 2, 8 ,0 , 1]y.sort(reverse = True)print (y) #[8, 3, 2, 1, 0]
True为倒序排列,False为正序排列
具体两者区别实例:
>>>a = [5,2,1,9,6]
>>> sorted(a) #将a从小到大排序,不影响a本身结构
[1, 2, 5, 6, 9]
>>> sorted(a,reverse = True) #将a从大到小排序,不影响a本身结构
[9, 6, 5, 2, 1]
>>> a.sort() #将a从小到大排序,影响a本身结构
>>> a
[1, 2, 5, 6, 9]
>>> a.sort(reverse = True) #将a从大到小排序,影响a本身结构
>>> a
[9, 6, 5, 2, 1]
# 注意,a.sort() 已改变其结构,b = a.sort() 是错误的写法!
>>> b = ['aa','BB','bb','zz','CC']
>>> sorted(b)
['BB', 'CC', 'aa', 'bb', 'zz'] #按列表中元素每个字母的ascii码从小到大排序,如果要从大到小,请用sorted(b,reverse=True)下同
>>> c =['CCC', 'bb', 'ffff', 'z']
>>> sorted(c,key=len) #按列表的元素的长度排序
['z', 'bb', 'CCC', 'ffff']
>>> d =['CCC', 'bb', 'ffff', 'z']
>>> sorted(d,key = str.lower ) #将列表中的每个元素变为小写,再按每个元素中的每个字母的ascii码从小到大排序
['bb', 'CCC', 'ffff', 'z']
>>> def lastchar(s):
return s[-1]
>>> e = ['abc','b','AAz','ef']
>>> sorted(e,key = lastchar) #自定义函数排序,lastchar为函数名,这个函数返回列表e中每个元素的最后一个字母
['b', 'abc', 'ef', 'AAz'] #sorted(e,key=lastchar)作用就是 按列表e中每个元素的最后一个字母的ascii码从小到大排序
>>> f = [{'name':'abc','age':20},{'name':'def','age':30},{'name':'ghi','age':25}] #列表中的元素为字典
>>> def age(s):
return s['age']
>>> ff = sorted(f,key = age) #自定义函数按列表f中字典的age从小到大排序
[{'age': 20, 'name': 'abc'}, {'age': 25, 'name': 'ghi'}, {'age': 30, 'name': 'def'}]
>>> f2 = sorted(f,key = lambda x:x['age']) #如果觉得上面定义一个函数代码不美观,可以用lambda的形式来定义函数,效果同上
需要了解更多可关注以下公众号,每日更新一篇测试文章
