C++ 并发编程实战 第五章 C++内存模型和原子操作
目录
5.1 内存模型基础
5.1.1 对象和内存区域
5.1.2 对象、内存区域和并发
5.1.3 改动序列
5.2 C++中的原子操作及其类别
5.2.1 标准原子类型
5.2.2 操作std::atomic_flag
5.2.3 操作std::atomic
5.2.4 操作std::atomic*>
5.2.5 操作标准整数原子类型
5.2.6 泛化的std::atomic<>类模板
5.2.7 原子操作的非成员函数
5.3 同步操作和强制次序
5.3.1 同步关系
5.3.2 先行关系
5.3.3 原子操作的内存次序
1. 先后一致次序
2. 非先后一致次序
3. 宽松次序
5. 获取-释放次序
6. 通过获取-释放次序
7.获取-释放序和memory_order_consume的数据相关性
5.3.4 释放序列和同步关系
5.3.5 栅栏
5.3.6 凭借原子操作令非原子操作服从内存次序
5.3.7 强制非原子操作服从内存次序
5.4 小结
参考:https://github.com/xiaoweiChen/CPP-Concurrency-In-Action-2ed-2019/blob/master/content/chapter5/5.0-chinese.md
5.1 内存模型基础
内存模型牵涉两个方面:基本结构和并发
5.1.1 对象和内存区域
无论是怎么样的类型,都会存储在一个或多个内存位置上。每个内存位置不是标量类型的对象,就是标量类型的子对象,比如:unsigned short、my_class*或序列中的相邻位域。当使用位域时就需要注意:虽然相邻位域中是不同的对象,但仍视其为相同的内存位置。如图5.1所示,将一个struct分解为多个对象,并且展示了每个对象的内存位置。
5.1.2 对象、内存区域和并发
如果不规定对同一内存地址访问的顺序,那么访问就不是原子的。当两个线程都是“写入者”时,就会产生数据竞争和未定义行为。
另一个重点是:当程序对同一内存地址中的数据访问存在竞争,可以使用原子操作来避免未定义行为。当然,这不会影响竞争的产生——原子操作并没有指定访问顺序——而原子操作会把程序拉回到定义行为的区域内。
5.1.3 改动序列
C++程序中的对象都有(由程序中的所有线程对象)在初始化开始阶段确定好修改顺序的。大多数情况下,这个顺序不同于执行中的顺序,但在给定的程序中,所有线程都需要遵守这个顺序。如果对象不是原子类型(将在5.2节详述),必须确保有足够的同步操作,确定线程都遵守了修改顺序。当不同线程在不同序列中访问同一个值时,可能就会遇到数据竞争或未定义行为(详见5.1.2节)。如果使用原子操作,编译器就有责任去做同步。
5.2 C++中的原子操作及其类别
原子操作是个不可分割的操作。系统的所有线程中,不可能观察到原子操作完成了一半。如果读取对象的加载操作是原子的,那么这个对象的所有修改操作也是原子的,所以加载操作得到的值要么是对象的初始值,要么是某次修改操作存入的值。
另一方面,非原子操作可能会被另一个线程观察到只完成一半。如果这个操作是一个存储操作,那么其他线程看到的值,可能既不是存储前的值,也不是存储的值。如果非原子操作是一个读取操作,可能先取到对象的一部分,然后值被另一个线程修改,然后它再取到剩余的部分,所以它取到的既不是第一个值,也不是第二个值。这就构成了数据竞争(见5.1节),出现未定义行为。
5.2.1 标准原子类型
通常,标准原子类型不能进行拷贝和赋值,它们没有拷贝构造函数和拷贝赋值操作符。但是,可以隐式转化成对应的内置类型,所以这些类型依旧支持赋值,可以使用load()和store()、exchange()、compare_exchange_weak()和compare_exchange_strong()。它们都支持复合赋值符:+=, -=, *=, |= 等等。并且使用整型和指针的特化类型还支持++和--操作。当然,这些操作也有功能相同的成员函数所对应:fetch_add(), fetch_or()等等。赋值操作和成员函数的返回值,要么是存储值(赋值操作),要么是操作值(命名函数),这就能避免赋值操作符返回引用。
赋值操作符的返回值是存入的值,而具名成员函数的返回值则是操作前的值。
std::atomic<>类模板不仅仅是一套可特化的类型,作为原发模板也可以使用自定义类型创建对应的原子变量。因为是通用类模板,操作限制为load(),store()(赋值和转换为用户类型),exchange(),compare_exchange_weak()和compare_exchange_strong()。
每种函数类型的操作都有一个内存序参数,这个参数可以用来指定存储的顺序。5.3节中,会对存储顺序选项进行详述。现在,只需要知道操作分为三类:
- Store操作,可选如下内存序:
memory_order_relaxed,memory_order_release,memory_order_seq_cst。 - Load操作,可选如下内存序:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_seq_cst。 - Read-modify-write(读-改-写)操作,可选如下内存序:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst。
5.2.2 操作std::atomic_flag
std::atomic_flag类型的对象必须被ATOMIC_FLAG_INIT初始化。初始化标志位是“清除”状态(置零状态)。这里没得选择,这个标志总是初始化为“清除”:
std::atomic_flag f = ATOMIC_FLAG_INIT;这适用于任何对象的声明,是唯一需要以如此特殊的方式初始化的原子类型,但也是唯一保证无锁的类型。首次使用时,需要初始化。如果std::atomic_flag是静态存储的,那么就的保证其是静态初始化的,也就意味着没有初始化顺序问题。
不能拷贝构造std::atomic_flag对象,不能将一个对象赋予另一个std::atomic_flag对象。这不是std::atomic_flag特有的属性,而是所有原子类型共有的属性。原子类型的所有操作都是原子的,而赋值和拷贝调用了两个对象,这就就破坏了操作的原子性。这样的话,拷贝构造和拷贝赋值都会将第一个对象的值进行读取,然后再写入另外一个。对于两个独立的对象,这里就有两个独立的操作了,合并这两个操作必定是不原子的。因此,操作就不被允许。
由于std::atomic_flag的局限性太强,没有非修改查询操作,甚至不能像普通的布尔标志那样使用。所以,实际操作中最好使用std::atomic,接下来让我们看看应该如何使用它。
5.2.3 操作std::atomic
最基本的原子整型类型就是std::atomic,它有着比std::atomic_flag更加齐全的布尔标志特性。虽然不能拷贝构造和拷贝赋值,但可以使用非原子的bool类型进行构造,所以可以初始化为true或false,并且可以从非原子bool变量赋值给std::atomic:
std::atomic b(true);
b=false; 另外,非原子bool类型的赋值操作不同于通常的操作(转换成对应类型的引用,再赋给对应的对象):它返回一个bool值来代替指定对象。原子类型中的另一种模式:通过返回值(返回相关的非原子类型)完成赋值。如果原子变量的引用返回了,任何依赖与这个赋值结果的代码都需要显式加载。问题是,结果可能会被其他线程修改。通过返回非原子值进行赋值的方式,可以避免多余的加载过程,并得到实际存储的值。
5.2.4 操作std::atomic
原子指针类型,可以使用内置类型或自定义类型T,通过特化std::atomic进行定义,操作是针对于相关类型的指针。虽然既不能拷贝构造,也不能拷贝赋值,但是可以通过合适的类型指针进行构造和赋值。std::atomic也有load(), store(), exchange(), compare_exchange_weak()和compare_exchage_strong()成员函数,获取与返回的类型都是T*。
- fetch_add() 和 fetch_sub() 返回原来的地址。
- 由于 fetch_add() 和 fetch_sub() 都是“读-改-写”操作,因此可以为其选取任何内存次序,它们还能参与释放次序。
5.2.5 操作标准整数原子类型
5.2.6 泛化的std::atomic<>类模板
模板允许用户使用自定义类型创建一个原子变量(除了标准原子类型之外),需要满足一定的标准才可以使用std::atomic<>。为了使用std::atomic(UDT是用户定义类型),这个类型必须有拷贝赋值运算符。这就意味着这个类型不能有任何虚函数或虚基类,以及必须使用编译器创建的拷贝赋值操作。不仅仅是这些,自定义类型中所有的基类和非静态数据成员也都需要支持拷贝赋值操作。这(基本上)就允许编译器使用memcpy()或赋值操作的等价操作,因为实现中没有用户代码。
5.2.7 原子操作的非成员函数
直到现在,还没有去描述成员函数对原子类型操作的形式,不同的原子类型中也有等价的非成员函数存在。大多数非成员函数的命名与对应成员函数有关,需要atomic_作为前缀(比如,std::atomic_load())。这些函数都会重载不同的原子类型,指定内存序时会分成两种:一种没有标签,另一种以_explicit为后缀,并且需要额外的参数,或将内存序作为标签,亦或只有标签(例如,std::atomic_store(&atomic_var,new_value)与std::atomic_store_explicit(&atomic_var,new_value,std::memory_order_release)。不过,成员函数隐式引用原子对象,所有非成员函数都持有一个指向原子对象的指针(作为第一个参数)。
C++标准库也对原子类型中的std::shared_ptr<>智能指针类型提供非成员函数,这打破了“只有原子类型,才能提供原子操作”的原则。std::shared_ptr<>不是原子类型,但是C++标准委员会认为这很重要。可使用的原子操作有:load, store, exchange和compare/exchange,这些操作重载了标准原子类型的操作,并且可获取std::shared_ptr<>*作为第一个参数:
std::shared_ptr p;
void process_global_data()
{
std::shared_ptr local=std::atomic_load(&p);
process_data(local);
}
void update_global_data()
{
std::shared_ptr local(new my_data);
std::atomic_store(&p,local);
} 并行技术规范扩展提供了一种原子类型 std::experimental::atomic_shared_ptr,该类型声明在std::atomic一样,也有load,store,exchange,compare-exchange这些操作。这个类型支持无锁实现,所以可以作为独立类型提供,并不会给普通的std::shared_ptr实例增加开销。不过和std::atomic模板一样,可以使用成员函数is_lock_free,可以确定在对应的硬件平台上检查是否无锁。当实现不是无锁结构时,推荐使用std::experimental::atomic_shared_ptr原子函数,因为该类型会让代码更加清晰,确保所有的访问都是原子的,并且能避免由于忘记使用原子函数导致的数据竞争。与原子类型和操作一样,如想用原子操作对应用进行加速,就需要对其性能进行分析,并且与其他同步机制进行对比。
如之前的描述,标准原子类型不仅仅是为了避免数据竞争所造成的未定义行为,还允许用户对不同线程上的操作进行强制排序。这种强制排序是数据保护和同步操作的基础,例如:std::mutex和std::future。
5.3 同步操作和强制次序
假设两个线程,一个向数据结构中填充数据,另一个读取数据结构中的数据。为了避免恶性条件竞争,第一个线程设置一个标志,用来表明数据已经准备就绪,从而第二个线程在这个标志设置前不能读取数据。
代码5.2 不同线程对数据的读写
#include
#include
#include
std::vector data;
std::atomic data_ready(false);
void reader_thread()
{
while(!data_ready.load()) // 1
{
std::this_thread::sleep(std::milliseconds(1));
}
std::cout<<"The answer="< 访问顺序通过对std::atomic类型的data_ready变量进行操作完成,这些操作通过*先行(happens-before)和同发*(synchronizes-with)确定顺序。写入数据③在写入data_ready④前发生,读取①发生在读取数据②之前。当data_ready①为true,写操作就会与读操作同步,建立一个“先行”的关系。因为“先行”关系是可传递的,所以写入③先行于写入④,这两个行为又先行于读取操作①,之前的操作都先行于读取数据②,这样就强制了顺序:写入数据先行于读取数据。
5.3.1 同步关系
同步关系的基本思想是:对变量 x 执行原子写操作 W 和原子读操作 R,且两者都有适当的标记。只要满足下面其中一点,它们即彼此同步。
R 读取了 W 直接存入的值。
W 所属线程随后还执行了另一原子写操作,R 读取了后面存入的值。
任意线程执行一连串“读-改-写”操作(如 fetch_add() 或 compare_exchange_weak()),而其中第一个操作读取的值由 W 写出。
5.3.2 先行关系
先行关系和严格先行关系是在程序中确立操作次序的基本要素;它们的用途是清楚界定哪些操作能看见哪些操作产生的结果
5.3.3 原子操作的内存次序
这里有六个内存序列选项可应用于对原子类型的操作:
- memory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_seq_cst
除非为特定的操作指定一个序列选项,要不内存序列默认都是memory_order_seq_cst。
虽然有六个选项,但仅代表三种内存模型:顺序一致性(sequentially consistent),获取-释放序(memory_order_consume, memory_order_acquire, memory_order_release和memory_order_acq_rel)和自由序(memory_order_relaxed)。
1. 先后一致次序
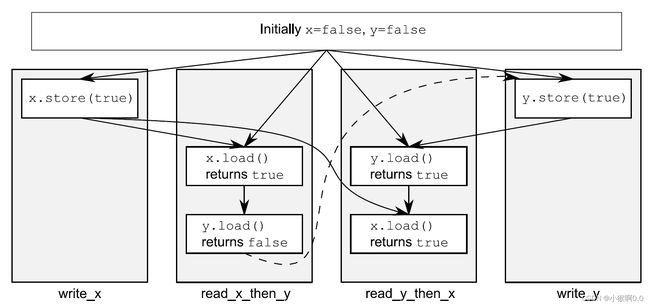
默认序命名为顺序一致性,因为程序中的行为从任意角度去看,序列都保持一定顺序。如果原子实例的所有操作都是序列一致的,那么多线程就会如单线程那样以某种特殊的排序执行。目前来看,该内存序是最容易理解的,这也是将其设置为默认的原因:不同的操作也要遵守相同的顺序。因为行为简单,可以使用原子变量进行编写。通过不同的线程,可以写出所有可能的操作消除那些不一致,以及确认代码的行为是否与预期相符。所以,操作都不能重排;如果代码在一个线程中,将一个操作放在另一个操作前面,那其他线程也需要了解这个顺序。
代码5.4 保持先后一致次序会形成一个全局总操作序列
#include
#include
#include
std::atomic x,y;
std::atomic z;
void write_x()
{
x.store(true,std::memory_order_seq_cst); // 1
}
void write_y()
{
y.store(true,std::memory_order_seq_cst); // 2
}
void read_x_then_y()
{
while(!x.load(std::memory_order_seq_cst));
if(y.load(std::memory_order_seq_cst)) // 3
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_seq_cst));
if(x.load(std::memory_order_seq_cst)) // 4
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0); // 5
} 
2. 非先后一致次序
线程之间不必就事件发生次序达成一致
它仅仅要求一点:全部线程在每个独立变量上都达成一致的修改序列。不同变量上的操作构成其特有的序列,假设各种操作都受施加的内存次序约束,若线程都能看到变量的值相应地保持一致
3. 宽松次序
原子类型上的操作以自由序执行。同一线程中对于同一变量的操作还是遵从先行关系,但不同线程不需要规定顺序。唯一的要求是在访问同一线程中的单个原子变量不能重排序,当给定线程看到原子变量的值时,随后线程的读操作就不会去检索较早的那个值。当使用memory_order_relaxed时,不需要任何额外的同步,对于每个变量的修改顺序只存在于线程间共享。
5. 获取-释放次序
6. 通过获取-释放次序
代码5.9 运用获取释放次序传递同步
std::atomic data[5];
std::atomic sync1(false),sync2(false);
void thread_1()
{
data[0].store(42,std::memory_order_relaxed);
data[1].store(97,std::memory_order_relaxed);
data[2].store(17,std::memory_order_relaxed);
data[3].store(-141,std::memory_order_relaxed);
data[4].store(2003,std::memory_order_relaxed);
sync1.store(true,std::memory_order_release); // 1.设置sync1
}
void thread_2()
{
while(!sync1.load(std::memory_order_acquire)); // 2.直到sync1设置后,循环结束
sync2.store(true,std::memory_order_release); // 3.设置sync2
}
void thread_3()
{
while(!sync2.load(std::memory_order_acquire)); // 4.直到sync1设置后,循环结束
assert(data[0].load(std::memory_order_relaxed)==42);
assert(data[1].load(std::memory_order_relaxed)==97);
assert(data[2].load(std::memory_order_relaxed)==17);
assert(data[3].load(std::memory_order_relaxed)==-141);
assert(data[4].load(std::memory_order_relaxed)==2003);
} 如果将获取-释放和序列一致进行混合,“序列一致”的加载动作就如使用了获取语义的加载操作,序列一致的存储操作就如使用了释放语义的存储,“序列一致”的读-改-写操作行为就如使用了获取和释放的操作。“自由操作”依旧那么自由,但其会和额外的同步进行绑定(也就是使用“获取-释放”的语义)。
7.获取-释放序和memory_order_consume的数据相关性
数据依赖的概念相对简单:第二个操作依赖于第一个操作的结果,这样两个操作之间就有了数据依赖。这里有两种新关系用来处理数据依赖:前序依赖(dependency-ordered-before)和携带依赖(carries-a-dependency-to)。携带依赖对于数据依赖的操作,严格应用于一个独立线程和其基本模型。如果A操作结果要使用操作B的操作数,则A将携带依赖于B。如果A操作的结果是一个标量(比如int),而后的携带依赖关系仍然适用于,当A的结果存储在一个变量中,并且这个变量需要被其他操作使用。这个操作可以传递,所以当A携带依赖B,并且B携带依赖C,就可以得出A携带依赖C的关系。
当不影响线程间的先行关系时,对于同步来说没有任何好处:当A前序依赖B,那么A线程间也前序依赖B。
5.3.4 释放序列和同步关系
通过线程在存储和加载操作之间有(有序的)多个“读-改-写”操作(所有操作都已经做了适当的标记),所以可以获取原子变量存储与加载的同步关系。存储操作标记为memory_order_release,memory_order_acq_rel或memory_order_seq_cst,加载标记为memory_order_consum,memory_order_acquire或memory_order_sqy_cst,并且操作链上的每一加载操作都会读取之前操作写入的值,因此链上的操作构成了一个释放序列(release sequence),并且初始化存储同步(对应memory_order_acquire或memory_order_seq_cst)或是前序依赖(对应memory_order_consume)的最终加载,操作链上的任何原子“读-改-写”操作可以拥有任意个内存序(甚至是memory_order_relaxed)。
代码5.11 使用原子操作从队列中读取数据
#include
#include
std::vector queue_data;
std::atomic count;
void populate_queue()
{
unsigned const number_of_items=20;
queue_data.clear();
for(unsigned i=0;i 
5.3.5 栅栏
栅栏操作会对内存序列进行约束,使其无法对任何数据进行修改,典型的做法是与使用memory_order_relaxed约束序的原子操作一起使用。栅栏属于全局操作,执行栅栏操作可以影响到在线程中的其他原子操作。因为这类操作就像画了一条任何代码都无法跨越的线一样,所以栅栏操作通常也被称为内存栅栏(memory barriers)。回忆一下5.3.3节,自由操作可以使用编译器或者硬件的方式,在独立的变量上自由的重新排序。不过,栅栏操作就会限制这种自由。
代码5.12 栅栏可以让自由操作变的有序
#include
#include
#include
std::atomic x,y;
std::atomic z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
std::atomic_thread_fence(std::memory_order_release); // 2
y.store(true,std::memory_order_relaxed); // 3
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 4
std::atomic_thread_fence(std::memory_order_acquire); // 5
if(x.load(std::memory_order_relaxed)) // 6
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 7
} 例子中,如果存储y的操作③标记为memory_order_release,而非memory_order_relaxed,释放栅栏②也会对这个操作产生影响。同样,当加载y的操作④标记为memory_order_acquire时,获取栅栏⑤也会对之产生影响。使用栅栏的想法是:当获取操作能看到释放栅栏操作后的存储结果,那么这个栅栏就与获取操作同步。并且,当加载操作在获取栅栏操作前,看到一个释放操作的结果,那么这个释放操作同步于获取栅栏。当然,也可以使用双边栅栏操作。举一个简单的例子:当一个加载操作在获取栅栏前,看到一个值有存储操作写入,且这个存储操作发生在释放栅栏后,那么释放栅栏与获取栅栏同步。
void write_x_then_y()
{
std::atomic_thread_fence(std::memory_order_release);
x.store(true,std::memory_order_relaxed);
y.store(true,std::memory_order_relaxed);
}栅栏不会分开这里的两个操作,并且也不再有序。只有当栅栏出现在存储x和存储y操作之间时,顺序才是硬性的。当然,栅栏是否存在不会影响任何拥有先行关系的执行序列。
5.3.6 凭借原子操作令非原子操作服从内存次序
代码5.13 使用非原子操作执行序列
#include
#include
#include
bool x=false; // x现在是一个非原子变量
std::atomic y;
std::atomic z;
void write_x_then_y()
{
x=true; // 1 在栅栏前存储x
std::atomic_thread_fence(std::memory_order_release);
y.store(true,std::memory_order_relaxed); // 2 在栅栏后存储y
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 3 在#2写入前,持续等待
std::atomic_thread_fence(std::memory_order_acquire);
if(x) // 4 这里读取到的值,是#1中写入
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // 5 断言将不会触发
} 5.3.7 强制非原子操作服从内存次序
5.4 小结
本章中对C++内存模型的底层知识进行介绍,了解了原子操作能在线程间提供同步。包含基本的原子类型由std::atomic<>类模板和std::experimental::atomic_shared_ptr<>模板特化后提供的接口,以及对于这些类型的操作,还要有对内存序列选项的各种复杂细节,都由std::atomic<>类模板提供。
也了解了栅栏如何在执行序中对原子类型的操作成对同步。
最后,回顾了本章开始的例子,了解了原子操作也可以在非原子操作间使用,并进行有序执行,并了解了一些高级工具所提供的同步能力。