太实用了! 20分钟彻底理解【Pointpillars论文】,妥妥的!
PointPillars: Fast Encoders for Object Detection from Point Clouds
PointPillars:快就对了
摘要(可跳过):
这帮人提出了PointPillars,一种新颖的编码器,它利用PointNets来学习以垂直列组织的点云(柱体点云)的表示。PointPillars在速度和准确性方面都明显优于先前的编码器。尽管仅使用激光雷达,他们的完整检测流程在3D和鸟瞰视图的KITTI基准测试中明显优于现有技术,甚至在融合方法中也是如此。这种检测性能在每秒运行62次的情况下实现:该方法的更快版本在每秒105次的情况下达到了现有技术的水平。这些基准测试结果表明,PointPillars是适用于点云物体检测的适当编码方法。
简介(可跳过):
在城市环境中部署自动驾驶车辆构成了一个困难的技术挑战。自动驾驶车辆依赖于多个传感器,其中激光雷达可以说是最重要的。激光雷达使用激光扫描仪来测量到环境的距离,从而生成了一个稀疏的点云表示。
1)点云是一种稀疏表示,而图像是密集的;
2)点云是3D的,而图像是2D的。
因此,从点云进行目标检测并不直接适用于标准的图像卷积流程。
在这项工作中,我们提出了PointPillars:一种用于3D目标检测的方法,只使用2D卷积层进行端到端学习。
PointPillars使用一种新编码器,学习点云的柱(垂直列)上的特征,以预测车辆的3D定向框。
优点:
1)通过学习特征而不是依赖固定的编码器,PointPillars可以利用点云所表示的全部信息。
2)通过在柱上操作而不是体素上,无需手动调整垂直方向的分割。
3)柱体非常高效,因为所有关键操作都可以表述为在GPU上计算非常高效的2D卷积。
学习特征的额外好处是PointPillars不需要手动调整以适应不同的点云配置。例如,它可以轻松地合并多个激光雷达扫描,甚至是雷达点云。
PointPillars 网络
PointPillars接受点云作为输入,并估计车辆、行人和骑自行车者的定向3D包围框。它由三个主要阶段组成
- 特征编码网络:将点云PointCloud转换为稀疏伪图像Pillars的网络。这个阶段的任务是将点云数据编码成适合进一步处理的形式。
- 2D卷积骨干网络:将伪图像处理成高级表示的2D卷积网络。这个阶段通过卷积操作将伪图像转化为更高层次的特征表示。
- 检测器头部:用于检测和回归3D包围框的部分。这个阶段负责识别目标物体并估计其3D包围框的位置和方向。
这三个阶段协同工作,使PointPillars能够从点云中准确地检测和定位车辆、行人和骑自行车的人。
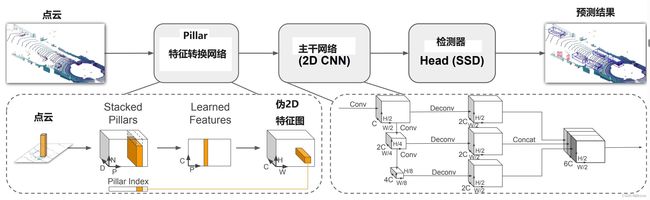
点云转伪图像
为了应用2D卷积,我们首先将点云转换为伪图像。我们用 I c I_c Ic表示点云中的一个点,其具有坐标x、y、z和反射率r。首先,将点云在x-y平面中均匀离散化,就是平均切分点云,于是创建了一堆柱状体 P c P_c Pc,这个切分操作需要用超参数控制,需要注意的是,在z维度上,由于不进行切分,所以不需要用来控制的超参数。
然后,将每个柱状体中的点用 x c x_c xc、 y c y_c yc、 z c z_c zc、 x p x_p xp、 y p y_p yp进行扩充,其中下标 c c c表示该点与柱状体中所有点云的虚拟中心 I v i r t u a l I_{virtual} Ivirtual的平均距离,注意这个 c c c意味着是个三维数据,而下标 p p p表示该点与柱状体在2D平面x-y上的中心 P v i r t u a l P_{virtual} Pvirtual的偏移,这个 p p p意味是个二维数据。这样,扩充后的每个激光点云 I c I_c Ic就具有9个维度=( x x x, y y y, z z z, x c x_c xc, y c y_c yc, z c z_c zc, x p x_p xp, y p y_p yp),注:激光点云的9个维度的值都是小数。
由于点云的稀疏性,柱状体集合将主要为空,通常只有少量点位于非空的柱状体中。例如,在0.162平方米的箱子中,来自HDL-64E Velodyne激光雷达的点云在通常用于KITTI数据集的范围内有6,000-9,000个非空的柱状体,稀疏度约为97%。通过对每个样本(P)和每个柱状体(N)中非空柱状体的数量施加限制,利用了这种稀疏性,以创建尺寸为(D,P,N)的密集张量,这里的张量是经过筛选后的非空点云集合。置换不变性:点的排序不影响物体的性质
其中,D表示每个点云的维度,D=9;P表示提取到的Pillar数量,P=30000,P的选取是根据激光雷达的硬件来选的是个超参数,N表示每个Pillar存储的最大点云数量,如果一个Pillar包含的点云数量太大,那么将被随机采样。相反,如果数据太少,将应用零填充。
因此,产生的伪2D张量:(30000 x 20 x 9) =(D,P,N)



对KITTI数据集的结果进行定性分析。我们展示了激光雷达点云的鸟瞰视图(顶部),以及为了更清晰的可视化而投影到图像中的3D包围盒。请注意,我们的方法仅使用了激光雷达数据。我们展示了汽车(橙色)、骑自行车者(红色)和行人(蓝色)的预测包围盒。地面真值包围盒以灰色显示。包围盒的方向由连接底部中心和前部的线表示。
接下来,我们使用了PointNet的简化版本( M L P s i m p l e = L i n e a r + B a t c h N o r m + R e L U MLP_{simple}=Linear+BatchNorm+ReLU MLPsimple=Linear+BatchNorm+ReLU ),对于每个点使用 M L P s i m p l e MLP_{simple} MLPsimple,以生成一个尺寸为(C,P,N)的张量。也就是,伪2D张量(D,P,N),通过 M L P s i m p l e MLP_{simple} MLPsimple,转变为了可以用来分类的张量(C,P,N),这里C也是个超参数,C=64。简单来说,就是D=9所包含的维度少,很容易被后续的卷积卷没了,所以要做个维度上升:
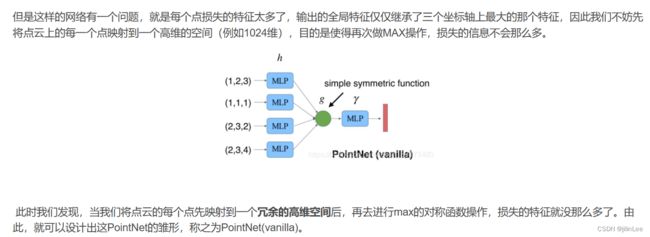
有关PointNet的理解,点击这里
(D,P,N)-> M L P s i m p l e MLP_{simple} MLPsimple->(C,P,N)
(9 x 30000 x 20)->(64 x 30000 x 20)
然后,在N这个维度,对30000个pillar中的每个pillar中的20个激光点,进行Max pool操作,该操作来自Pointnet论文,通过对称函数用于选定的所有点,提取这个pillar中点云的surface信息,并聚合到一个特征值,范围在[0,1]。注意,Linear可以用1x1卷积代替,从而产生非常有效的计算。一旦编码完成,特征将被散回原始的柱状体位置,以创建一个尺寸为(C,H,W)的伪图像,其中H和W表示画布的高度和宽度。
主干网络
我们使用了类似于Voxelnet的骨干网络结构,其结构如图2所示。这个骨干网络包括两个子网络:

- 一个自上而下的网络,以逐渐减小空间分辨率的方式生成特征。
- 一个拼接网络,负责进行上采样和连接自上而下的特征。
自上而下的网络可以用一系列块卷积块Block(S, L, F)来描述,每个Block是2D卷积层构成,每个卷积层输出F个通道,然后接着BatchNorm和ReLU激活函数。
拼接网络,通过Deconv来放大分辨率,然后Concat。
检测头
在本文中,我们使用单击检测器(SSD)[18]设置来执行3D目标检测。与SSD类似,我们使用2D联合交叉(IoU)[4]将先验框与真值相匹配。边界框高度和标高未用于匹配;而不是给定2D匹配,高度和高程成为额外的回归目标。
损失
我们使用SECOND[28]中介绍的相同损失函数。真值框和锚由( x , y , z , w , l , h , θ ) (x,y,z,w,l,h,θ)(x,y,z,w,l,h,θ)定义。真值和锚之间的定位回归残差定义如下: