论文笔记(整理):轨迹相似度顶会论文中使用的数据集
0 汇总
| 数据类型 | 数据名称 | 数据处理 |
| 出租车数据 | 波尔图 | 原始数据:2013年7月到2014年6月,170万条数据 |
| ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过滤包含少于20个点或超过200个点的轨迹 |
||
| CIKM 2022 Efficient Trajectory Similarity Computation with Contrastive Learning 为两个数据集设置相同的采样率,即15秒 |
||
| CIKM 2022 Aries: Accurate Metric-based Representation Learning for Fast Top-k Trajectory Similarity Query 根据位置和时间戳,在三个月内选择了一个相对集中的轨迹集,数量为100 |
||
| KDD2022 TrajGAT: A Graph-based Long-term Dependency Modeling Approach for Trajectory Similarity Computation 2019 ICDE Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Approach 选择城市中心区域的轨迹,并移除少于10条记录的轨迹 ——>超过60W条轨迹 |
||
| CIKM 2023 Can Adversarial Training benefit Trajectory Representation? An Investigation on Robustness for Trajectory Similarity ICDE 2018 Deep Representation Learning for Trajectory Similarity Computation
|
||
| ICDE 2022 TMN: Trajectory Matching Networks for Predicting Similarity ICDE 2021 T3S: Effective Representation Learning for Trajectory Similarity Computation 没有多少处理 |
||
| 哈尔滨 | ICDE 2018 Deep Representation Learning for Trajectory Similarity Computation 8个月内13000辆出租车的轨迹。 选择了长度至少为30,且连续采样点之间的时间间隔少于20秒的轨迹。 这产生了150万条轨迹 |
|
| 西安 | 2018年10月的前两周 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 过滤位于城市(或国家)区域之外的轨迹 过滤包含少于20个点或超过200个点的轨迹 |
| 数据类型 | 数据名称 | 数据处理 |
| 出租车数据 | 德国 |
ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention 2006年到2013年间 过滤位于城市(或国家)区域之外的轨迹 过滤包含少于20个点或超过200个点的轨迹 |
| 罗马 | KDD 2022 Spatio-Temporal Trajectory Similarity Learning in Road Networks 移除了少于10个采样点的轨迹 45157条轨迹 |
|
| 北京(T-drive) | AAAI 2023 GRLSTM: Trajectory Similarity Computation with Graph-Based Residual LSTM 从10,357辆出租车中收集的 使用空间相似函数通过GPS坐标在北京道路网络上创建基准真值 |
|
| KDD 2022 Spatio-Temporal Trajectory Similarity Learning in Road Networks 移除了少于10个采样点的轨迹 |
||
| KDD 2021 A Graph-based Approach for Trajectory Similarity Computation in Spatial Networks 按小时分割这些轨迹,然后我们总共可以得到5,621,428条轨迹。 通过过滤异常值,这些轨迹的平均长度为25。 |
||
| 新加坡 | 15,054辆出租车的轨迹 对于每辆出租车,GPS信息在整整一个月内以半分钟到三分钟的采样率持续收集 |
|
| 人流mobility数据 | 北京( Geolife) |
2007年4月到2012年8月收集的17621条轨迹 |
| Sigspatial 2022 TSNE: trajectory similarity network embedding 选择了城市中心区域的轨迹,并将该区域离散化为200m×200m的网格单元。 移除了所有点太稀疏(少于10个点的轨迹),并在Geolife中获得了10,504条轨迹 |
||
| CIKM 2023 Can Adversarial Training benefit Trajectory Representation? An Investigation on Robustness for Trajectory Similarity
|
||
| 2019 ICDE Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Approach 过滤掉位于稀疏区域的轨迹,保留城市中心区域的轨迹 移除了少于10条记录的轨迹 大约8,000条轨迹 |
1 2023
1.1 ICDE 2023 Contrastive Trajectory Similarity Learning with Dual-Feature Attention
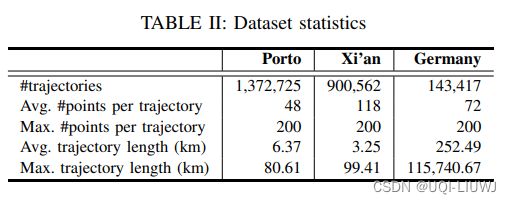
使用了三个真实世界的轨迹数据集:
(1)Porto ——2013年7月到2014年6月间,葡萄牙波尔图的170万条出租车轨迹;
(2)西安——2018年10月的前两周内,中国西安的210万条网约车轨迹(滴滴)
(3)德国 ——2006年到2013年间,170.7千条用户提交的轨迹。(openStreetMap)
- 过滤位于城市(或国家)区域之外的轨迹,
- 过滤包含少于20个点或超过200个点的轨迹
预处理后的数据集在表II中进行了总结。
1.2 AAAI 2023 GRLSTM: Trajectory Similarity Computation with Graph-Based Residual LSTM

- 北京的轨迹来自T-drive项目的出租车轨迹。
- 这些出租车轨迹是在几天内通过出租车id,GPS坐标和时间戳从10,357辆出租车中收集的
- 按小时划分这些轨迹,并丢弃短长度的轨迹
- 使用空间相似函数(Shang et al. 2017b)通过GPS坐标在北京道路网络上创建基准真值
- T-Drive trajectory data sample - Microsoft Research
- 纽约的轨迹从NYC Open Data - (cityofnewyork.us)获取
- 使用相同的预处理方法来处理这些轨迹并获得基准真值
- 对于这两个数据集,我们将这些数据随机分为训练集,验证集和测试集,比例为[0.2,0.1,0.7]
2 2022
2.1 CIKM 2022 Efficient Trajectory Similarity Computation with Contrastive Learning
为两个数据集设置相同的采样率,即15秒。
根据轨迹的开始时间戳将每个数据集划分为训练集和测试集,其中前100万条轨迹用于训练,其余的用于测试
2.2 CIKM 2022 Aries: Accurate Metric-based Representation Learning for Fast Top-k Trajectory Similarity Query
波尔图数据集:从2013年到2014年,有超过四百辆出租车的170万辆车轨迹。
我们根据它们的位置和时间戳,在三个月内选择了一个相对集中的轨迹集,数量为100。
然后我们删除少于50个点的记录,并将整个区域划分为1500×1500大小的网格。
经过预处理,我们在波尔图获得了79,362条轨迹。
2.3 CIKM 2023 Can Adversarial Training benefit Trajectory Representation? An Investigation on Robustness for Trajectory Similarity

- 波尔图的数据集——从2013年7月到2014年6月的12个月期间的170万条出租车轨迹
- 删除了长度少于30的轨迹
- 最终剩下120万条轨迹
- 北京数据集(Geolife)
- 2007年4月到2012年8月收集的17621条轨迹
- 也选择了那些至少满足长度为30的轨迹,并且在连续采样点之间的时间间隔小于20秒
- 这样的操作产生了8214条轨迹
- 对于波尔图数据集,训练数据由800,000条轨迹组成,其余的用于测试数据。
- 对于Geolife数据集,前4928条轨迹用于训练数据,其余的用于测试数据。
2.4 Sigspatial 2022 TSNE: trajectory similarity network embedding
Geolife ——由182个用户从2007年到2012年在中国北京收集的17,621条轨迹组成。
选择了城市中心区域的轨迹,并将该区域离散化为200m×200m的网格单元。
移除了所有点太稀疏(少于10个点的轨迹),并在Geolife中获得了10,504条轨迹。
2.5 KDD 2022 Spatio-Temporal Trajectory Similarity Learning in Road Networks
- 北京包含了从2008年2月2日到2008年2月8日在中国北京收集的1500万个出租车轨迹点。
- 罗马包含了367,052条来自意大利罗马的出租车轨迹,覆盖了30多天。
- 首先将所有轨迹映射匹配到来自OpenStreetMap的相应道路网络。
- 这样,原始GPS轨迹数据就转换成了按时间顺序排列的顶点序列。
- 进一步,获取了来自城市地区的轨迹,并移除了少于10个采样点的轨迹。
- 这个预处理得到了在北京的348,210条轨迹和在罗马的45,157条轨迹。
2.6 KDD2022 TrajGAT: A Graph-based Long-term Dependency Modeling Approach for Trajectory Similarity Computation
- 西安的出租车轨迹
- 从2007年到2010年的17,621条人类移动轨迹
- 波尔图
- 从2013年到2014年的超过170万条出租车轨迹
- 预处理:选择城市中心区域的轨迹,并移除少于10条记录的轨迹
- 处理后,我们获得了西安数据集的7641条轨迹和波尔图数据集的超过600,000条轨迹
2.7 ICDE 2022 TraSS: Efficient Trajectory Similarity Search Based on Key-Value Data Stores
(1)TDrive ,包含了两周内北京的321,387条出租车轨迹(752MB)
(2)Lorry,包含了广州的4,394,397条JD物流卡车轨迹(136GB)
(3)合成,为了验证TraSS的可扩展性,我们使用了由Lorry数据集复制7次生成的五个合成数据集
2.8 ICDE 2022 TMN: Trajectory Matching Networks for Predicting Similarity
• Geolife 由中国北京的182名用户收集,它包含了广泛的人类户外运动,这些运动是用户的GPS位置。总共,Geolife中有17,612条轨迹。
• Porto 包含了超过170万辆车的路线轨迹,主要由葡萄牙波尔图的442辆出租车收集。
遵循之前的工作,过滤掉位于稀疏区域的轨迹,保留城市中心区域的轨迹用于训练和测试。
也移除了少于10条记录的轨迹。
- 这是因为计算较长序列的相似性更为困难和耗时。
- 此外,轨迹数据集通常以许多GPS错误和其他问题为特征,如果受到影响,短轨迹会严重受到这些错误的影响
经过预处理后,Geolife数据集中有大约8,000条轨迹,Porto数据集中有600,000条轨迹
2.9 ICDE 2022 Continuous Trajectory Similarity Search for Online Outlier Detection
1)北京(Geolife)
该数据集保留了182名用户在三年多的时间里的所有旅行记录,包括多种交通方式(步行、驾驶和乘坐公共交通)。
轨迹每1-5秒采样一次,两个相邻点之间的平均速度为5.73 m/s。
北京的道路网络有65,129个节点和85,322条边。
2)新加坡。
该数据集追踪了新加坡的15,054辆出租车的轨迹。
对于每辆出租车,GPS信息在整整一个月内以半分钟到三分钟的采样率持续收集。
它在两个相邻点之间的平均距离远高于GeoLife。
新加坡的道路网络包含20,801个节点和42,309条边。
这是一个私有数据


3)波尔图。
该数据集包含了442辆出租车在波尔图市,葡萄牙一整年(从2013年7月1日到2014年6月30日)的轨迹。
其道路网络具有最细的粒度,有100,484个节点和129,303条边。
3 2021
3.1 ICDE 2021 REPOSE: Distributed Top-k Trajectory Similarity Search with Local Reference Point Tries
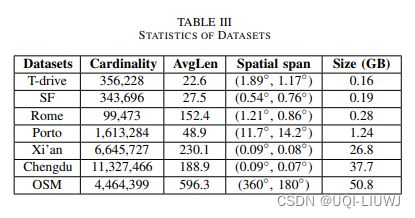
我们在3种类型的数据集上进行实验。
1)小规模和小空间跨度:旧金山(SF),波尔图(Porto),罗马(Rome),T-drive [33]。
2)大规模和小空间跨度:成都和西安。
3)大规模和大空间跨度:OSM。
数据集统计信息显示在表III中。
在预处理阶段,我们删除长度小于10的轨迹,并将长度大于1000的轨迹分割成多条轨迹。我们均匀且随机地选择100条轨迹作为查询集。
1http://sigspatial2017.sigspatial.org/giscup2017/home 2https://www.kaggle.com/c/pkdd-15-predict-taxiservice-trajectory-i 3http://crawdad.org/roma/taxi/20140717 4https://gaia.didichuxing.com 5https://www.openstreetmap.org
3.2 ICDE 2021 T3S: Effective Representation Learning for Trajectory Similarity Computation
我们的实验使用了以下两个数据集:
• Geolife [17] 是一个基于GPS的轨迹数据集,由2007年4月至2012年8月在中国北京的182名用户收集。该数据集包含17,621条轨迹,并记录了广泛的人类户外活动。
• Porto [18] 是一个包含超过170万辆车路线轨迹的数据集,由葡萄牙波尔图的442辆出租车收集。该数据集用作评估交通监测模型的基准。
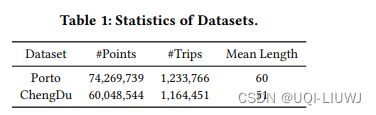
3.3 KDD 2021 A Graph-based Approach for Trajectory Similarity Computation in Spatial Networks
使用来自不同城市的两个空间网络。一个是来自北京市的,即北京道路网络(BRN)。另一个是来自纽约市的,即纽约道路网络(NRN)。
在BRN数据集中,有28,342个兴趣点和27,690条边;在NRN数据集中,有95,581个兴趣点和260,855条边。
对于BRN中的轨迹,我们使用来自T-drive项目的出租车行驶数据。BRN中的出租车轨迹是按出租车id收集的,一条轨迹的时间范围可能持续几天。因此,我们按小时分割这些轨迹,然后我们总共可以得到5,621,428条轨迹。通过过滤异常值,这些轨迹的平均长度为25。
对于NRN中的轨迹,我们使用来自纽约的出租车行驶数据。在原始数据集中,有697,622,444次行程,我们随机抽样其中的一部分来生成轨迹数据集。经过预处理后,我们的实验中有10,541,288条轨迹,它们的平均长度为38。详细信息总结在表1中。
对于这两个轨迹数据集,我们都以20%、10%和70%的比例随机分割它们为训练集、评估集和测试集。

4 2020
4.1 IJCAI 2020 Trajectory Similarity Learning with Auxiliary Supervision and Optimal Matching

ECML/PKDD 15: Taxi Trajectory Prediction (I) | Kaggle
4.2 2020 ICDE Parallel Semantic Trajectory Similarity Join
- 纽约轨迹数据(NTD)和北京轨迹数据(BTD)。
- NTD包含一张道路网络和1000万辆出租车行程。每个出租车行程都是一个起点-终点对。
- 将从源到目的地的最短路径视为一次行程的轨迹。
- 此外,使用了一个真实的POI数据集,其中包含了纽约市的19,969个POI。
- 每个POI都有一个带有纬度和经度的空间坐标和一个文本描述。
- 因为POI可能不匹配轨迹点,我们将每个POI映射到道路网络中最近的节点,并将POI视为语义轨迹中的一个对象。
- 在BTD中——T-drive
- BTD中的原始轨迹非常长,因为每条轨迹都包含了特定时间段内的所有行程,这可能是几天。
- 我们将这些轨迹划分为半小时的子轨迹。目的是创建具有现实长度和持续时间的行程。
- 为了用文本描述增强每个轨迹点,我们从包含200万条推文的真实推文集合中随机选择一条推文,并将推文的文本描述与轨迹点关联起来。
https://publish.illinois.edu/dbwork/open-data/
5 更早
5.1 ICDE 2018 Deep Representation Learning for Trajectory Similarity Computation

第一个数据集在葡萄牙的波尔图市收集,持续19个月,包含170万条轨迹。每辆出租车每15秒报告一次其位置。我们移除了长度少于30的轨迹,得到了120万条轨迹。
第二个数据集包含了在中国哈尔滨市收集的8个月内13000辆出租车的轨迹。我们选择了长度至少为30,且连续采样点之间的时间间隔少于20秒的轨迹。这产生了150万条轨迹。
我们根据轨迹的开始时间戳将两个集合划分为训练数据和测试数据。对于这两个集合,前80万条轨迹用于训练,其余的轨迹用于测试。
5.2 2019 ICDE Computing Trajectory Similarity in Linear Time: A Generic Seed-Guided Neural Metric Learning Approach
第一个数据集[33],被称为Geolife,包含了从2007年到2010年的17,621条人类移动轨迹。
第二个数据集[23]包含了从2013年到2014年的超过170万条出租车轨迹。
为了减小M的维度,我们选择了城市中心区域的轨迹,并将该区域离散化为50m × 50m的网格单元。
然后,我们删除了记录少于10条的轨迹。经过这样的预处理,我们在Geolife中获得了8203条轨迹,在波尔图中获得了601,071条轨迹。