C++ | C++11新特性(上)
目录
前言
一、列表初始化
二、声明
1、auto
2、decltype
3、nullptr
三、STL容器的变化
四、右值引用与移动语义
1、左值与左值引用
2、右值与右值引用
3、右值引用与左值引用的比较
4、右值引用的场景及意义
(1)做参数
(2)返回值
5、完美转发
(1)万能引用
(2)完美转发
五、类的新功能
1、默认成员的改变
2、default与delete关键字
3、final与override
前言
本章主要讲解一些关于C++11常用语法;不会将每个语法都介绍一边,将主要语法进行讲解;如果想要了解全部有关C++11语法可以访问下方链接网站;
C++11
一、列表初始化
没错,就是列表初始化,并不是初始化列表,一定要搞清楚了。这里说的是列表初始化,并不是构造函数中的初始化列表;其实列表初始化在C语言中也有体现,如下代码;
// 列表初始化
struct point
{
int _x;
int _y;
};
void test1()
{
// C++98 C语言版的列表初始化
int arr1[] = { 1,2,3,4,5 };
int arr2[5] = { 0 };
struct point p = { 1,2 };
}
在C语言中,我们可以通过花括号的方式对数组和结构体进行初始化;C++11中,我们同样提供了这种初始化方式;万物皆可花括号初始化;其中等号一般可省略;
// C++11 万物皆可花括号(= 可省略)
int x1 = 3;
int x2{ 3 };
int* pa = new int[2]{ 3 };
其实,不仅是我们内置成员可以这么初始化,连我们自定义类型也可以这样初始化,如下述代码所示;
string str1 = { "hhhh" };
string str2{ "hhhh" };
vector v1 = { 1,2,3,4,5,6 };
vector v2 { 1,2,3,4,5,6 };
list l1 = { 1,2,3,4,5,6 };
list l2 { 1,2,3,4,5,6 };
Date d1 = { 2022, 8, 5 };
Date d2 { 2022, 8, 5 }; 这是因为我们的C++11中,为我们提供了一种新的类型,这个类型叫initializer_list;而我们的STL容器都提供了一个这个版本的构造;我们可以通过下述代码证明initializer_list的存在;
void test2()
{
// initializer_list 头文件
auto li1 = { 1,2,3,4,5,6 };
initializer_list li2 = { 1,2,3,4,5,6 };
cout << typeid(li1).name() << endl;
cout << typeid(li2).name() << endl;
} 
一个是通过auto自动识别类型,一个是显示声明;可输出的结果都相同;
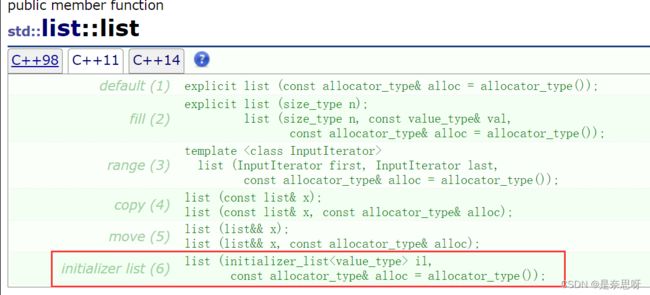

自C++11后,许多容器都提供了这种初始化的方式;
二、声明
1、auto
auto其实在C++98时就存在了,但由于在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。而在C++11中,废除了以前的用法,实现了自动类型推断,在很多场景下都变得好用了许多;
void test4()
{
map m1;
map::iterator it1 = m1.begin();
auto it2 = m1.begin();
} 2、decltype
auto用于类型自动识别,而我们的则是可以推导我们的表达式类型,并用该类型进行初始化;具体用法如下;
void test3()
{
// decltype
int a = 1;
int b = 2;
decltype(a + b) c = 10;
cout << typeid(c).name() << endl;
// 应用
vector v1;
cout << typeid(v1).name() << endl;
} 3、nullptr
没错,我们平常使用的nullptr也是C++11后推出的,那为什么不用NULL呢?实际上NULL的定义存在BUG;具体细节可以移步下方链接最后一个知识点;
C++初阶
三、STL容器的变化
在我们C++11后,我们的容器也有了很大的变化;如下图所示;

其中,array对标的是我们C语言的数组,可实际上,我们有非常好用的vector了,因此array使用并不怎么需要了;但C++11中unordered系类的容器有非常显著的效果,确实挺好用,比起map与set,虽然unordered系类并不排序,但是效率明显会比map与set高很多,其增删查改的时间复杂度都接近O(1);同时C++11的容器中提供了const迭代器版本cbegin。cend,但实际上用的也不多;
四、右值引用与移动语义
C++11增加的右值相关语法进一步提高了我们代码的效率;是一个非常有用的知识点;下面我们首先了解什么叫左值,什么又叫右值;
1、左值与左值引用
左值是一个表示数据的表达式;我们可以对他进行取地址以及赋值;左值既可以出现在=的左边,也可以出现在=的右边;左值引用就是左值的引用,左值的别名;
void test5()
{
// a/b/p都是左值
int a = 1;
const int b = 4;
int* p = new int(10);
// ra/rb/rp都是左值引用
int& ra = a;
const int& rb = b;
int*& rp = p;
}2、右值与右值引用
右值也是一个表示数据的表达式,但是不同的是右值通常是字面量、表达式返回值、函数返回值等;右值只能出现在=的右边,不能出现在=的左边;且右值无法取地址;这是二者最本质的区别;右值引用就是右值的引用,右值的别名;
void test6()
{
int a = 1;
int b = 4;
// 以下均为右值
a + b;
123;
func();
// 以下均为右值引用
int&& r1 = a + b;
int&& r2 = 123;
int&& r3 = func();
}注意:关于上述,我们区分左值和右值的可通过是否可以取地址来进行判断,若可取地址,则必定是左值,若不可则是右值,这里还有一个小小的补充,右值引用在引用右值后,保存进了一个变量,该变量是左值,可以进行取地址;
void test7()
{
int a = 3;
int b = 6;
// a + b是右值,ra是右值引用,ra变量是左值
int&& ra1 = a + b;
const int&& ra2 = a + b;
cout << &ra1 << endl; // 可以取地址
// cout << &(a + b) << endl; // err 右值不能取地址
ra1 = 20; // 正确
// ra2 = 20; // err const修饰的右值引用不可修改
}3、右值引用与左值引用的比较
左值引用:
1、可以引用左值
2、const修饰后既可引用左值,也可引用右值
右值引用:
1、可以引用右值
2、可以引用move后的左值
void test8()
{
int a = 2;
int b = 5;
// 左值引用可以引用左值
// const佐治引用可以引用右值
int& ra1 = a;
//int& ra2 = (a + b); // err 不能引用右值
const int& ra3 = (a + b); // const修饰的左值引用可以引用右值
// 右值引用可以引用右值
// 右值引用可以引用move后的左值
int&& ra4 = (a + b);
// int&& ra5 = a; // err 不可引用左值
int&& ra6 = move(a); // 可引用move后的左值
}4、右值引用的场景及意义
关于右值引用的场景与意义,我们使用我们之前封装的简略版string进行展示;
namespace MySpace
{
class string
{
public:
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
cout << "string(char* str)" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
string operator+(char ch)
{
string tmp(*this);
tmp.push_back(ch);
return tmp;
}
~string()
{
delete[] _str;
_str = nullptr;
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
//string operator+=(char ch)
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
private:
char* _str;
size_t _size;
size_t _capacity; // 不包含最后做标识的\0
};
}(1)做参数
我们给上述的string类添加一个移动构造版本; 形参是右值时才会调用这个版本;一般右值都是一些声明周期快要介绍的值;可能即将会被销毁;我们可以直接偷走右值的资源来减少深拷贝的次数;代码如下所示;
// 移动构造(拷贝构造特殊版本)
string(string&& s):_str(nullptr), _size(0), _capacity(0)
{
cout << "string(string&& s) -- 移动语义" << endl;
swap(s);
}我们再对上述情况进行分析;当我们传入一个右值时,我们调用移动构造,直接转移其资源,而不进行深拷贝;

(2)返回值
我们的左值引用解决了当我们传回非局部对象时的拷贝问题;但是对于局部对象,我们还是需要进行深拷贝;下面以to_string函数作为举例;


但是在我们C++11后,引入了右值引用的概念;我们同样使用这段代码;


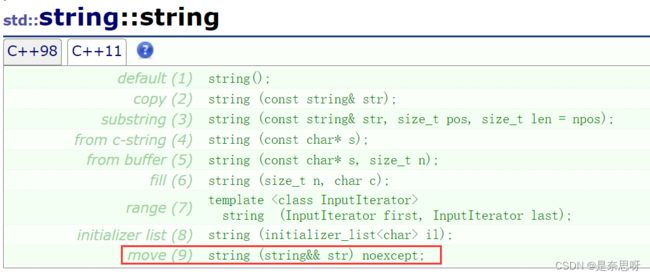
同样,不仅有移动构造,还有移动赋值,原理是一样的,通过识别形参是左值还是右值选择不同的接口, 如果是左值就采用深拷贝的方式进行;如果是右值,则采用移动资源的方式来进行;同样库里的STL容器也更新了许多关于移动语义的接口;

5、完美转发
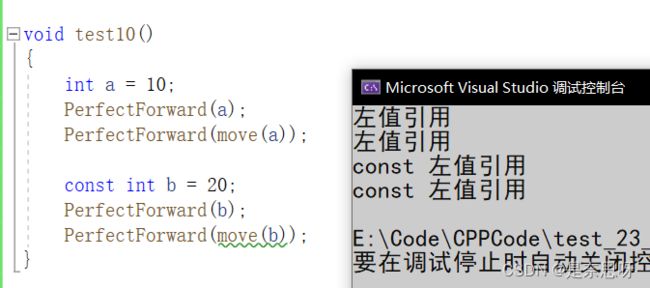
有如下程序,猜测如下程序的输出结果是什么?
void Fun(int& x)
{
cout << "左值引用" << endl;
}
void Fun(const int& x)
{
cout << "const 左值引用" << endl;
}
void Fun(int&& x)
{
cout << "右值引用" << endl;
}
void Fun(const int&& x)
{
cout << "const 右值引用" << endl;
}
template
void PerfectForward(T&& t)
{
Fun(t);
}
void test10()
{
int a = 10;
PerfectForward(a);
PerfectForward(move(a));
const int b = 20;
PerfectForward(b);
PerfectForward(move(b));
} 结果都是我们的左值引用,这个结果你猜到了吗?
(1)万能引用
在上述代码中,我们将模板中的&&成为万能引用;也叫折叠引用;

(2)完美转发
完美转发的情况就诞生在上述情况中,当我们用右值引用接收右值时,我们的右值引用对象接收右值,并找个位置储存起来;此时我们的引用对象实际上是左值;当我们想往下一层调用传达右值就无法做到了;如上述我们PerfectForward接收后,用右值引用对象 t 保存了下来,此时 t 实际上已经是左值了,所以我们传给下一层时,传的时左值引用的接口;我们可以称这种现象为丢失了右值的属性;此时我们可以用我们的 forward 保持其原有的右值属性,这种方式我们称之为完美转发;如下述代码;
void Fun(int& x)
{
cout << "左值引用" << endl;
}
void Fun(const int& x)
{
cout << "const 左值引用" << endl;
}
void Fun(int&& x)
{
cout << "右值引用" << endl;
}
void Fun(const int&& x)
{
cout << "const 右值引用" << endl;
}
template
void PerfectForward(T&& t)
{
Fun(forward(t));
}
void test10()
{
int a = 10;
PerfectForward(a);
PerfectForward(move(a));
const int b = 20;
PerfectForward(b);
PerfectForward(move(b));
}

五、类的新功能
1、默认成员的改变
之前类与对象中我们提过,类有六大默认成员,分别为默认构造、拷贝构造、赋值重载。析构函数、取地址重载以及const取地址重载;C++11后,又新增了两个默认的成员函数,分别为移动构造函数和移动赋值重载函数;
移动构造函数与移动赋值重载函数具有以下特性:
1、若自己未显式声明且没有实现析构函数、拷贝构造、赋值重载中任意一个,则生成默认的
2、默认生成的移动构造/移动赋值对内置成员会逐字节拷贝,对于自定义成员则调用他们的移动构造/移动赋值,若该自定义成员没有移动构造/移动赋值,则调用他们的拷贝构造/赋值;
class Person
{
public:
Person(int age = 18, MySpace::string name = "Jack")
:_age(age)
,_name(name)
{}
private:
int _age;
MySpace::string _name;
};此时我们的Person类满足上述自动生成默认移动构造与移动赋值的条件;并且我们发现对于自定义成员sting也调用了其移动构造与移动赋值;

2、default与delete关键字
default关键字可以让编译器帮我们生成默认的成员函数函数,delete关键字可以不让编译器生成默认的成员函数,即使已经满足自动生成条件;如下所示;
class A
{
public:
// 生成默认的构造
A() = default;
A(int a)
:_a(a)
{}
// 不允许生成拷贝构造
A(const A& a) = delete;
private:
int _a;
};
void test12()
{
A a1;
A a2 = a1; // err 拷贝构造函数被禁止生成了
}3、final与override
final作用有二,其一是修饰类,使得该类不允许被继承下去了;其二是修饰虚函数,使得该虚函数不能被继续重写了;
override的作用则是修饰虚函数,检查子类虚函数是否重写;
class Base
{
public:
virtual void func1() final // 该虚函数无法被重写
{
cout << "virtual void func1() final" << endl;
}
virtual void func2()
{
cout << "virtual void func2()" << endl;
}
private:
int _b;
};
class Deriver : public Base
{
public:
/*void func1()
{
cout << "void func1()" << endl;
}*/
void func2() override // 检查是否重写父类虚函数
{
cout << "class Deriver : public Base" << endl;
}
private:
int _d;
};