【MySQL锁篇】MySQL是怎样加锁的
本文为博主参考《小林coding》网站的学习笔记。具体文章,请参考转载记录。
目录
一、哪一些SQL语句会加锁
①普通select语句,不会加锁;
②两类不同select加锁语句
③update和delete操作都会加锁
二、MySQL是怎样加行级锁的
①唯一索引等值查询(select...where [index]=...)
存在唯一索引的情况:
不存在唯一索引的情况:
②唯一索引范围查询
针对大于等于的情况
针对小于或者小于等于的情况
③非唯一索引等值查询
当查询记录不存在的时候:锁住这个二级索引最近的范围(使用间隙锁)
当查询记录存在的时候:先锁住二级索引(next-key lock),然后锁住主键索引(Record-lock),最后锁住二级索引的下一行(间隙锁)
④非唯一索引范围查询
⑤没有加索引的查询
一、哪一些SQL语句会加锁
InnoDB存储引擎是支持行级锁的,而MyISM存储引擎不支持行级锁,所以后面的内容都是基于
InnoDB存储引擎设计的。
①普通select语句,不会加锁;
它是使用一个叫做Read View的东西来控制的,本质上就是一个快照。
关于什么是Read View以及MVCC,已经在这一篇文章当中提到了。
(1条消息) MySQL事物以及事物的四大特性,隔离级别的简单介绍_mysql中指定事物的特征的语句是_革凡成圣211的博客-CSDN博客 https://blog.csdn.net/weixin_56738054/article/details/127857770?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_56738054/article/details/127857770?spm=1001.2014.3001.5501
②两类不同select加锁语句
//对读取的记录加共享锁(S型锁)
select ... lock in share mode;
//对读取的记录加独占锁(X型锁)
select ... for update; 这两个不同的加锁方式,已经在上一篇文章当中提到了。
【MySQL锁篇】一、MySQL当中有哪些锁_革凡成圣211的博客-CSDN博客https://blog.csdn.net/weixin_56738054/article/details/128790366?spm=1001.2014.3001.5501
其实S型锁可以理解为读锁,X型锁可以理解为写锁。
对于X型锁:读读冲突、读写冲突、写写冲突;
对于S型锁:读读不冲突、读写冲突、写写冲突
③update和delete操作都会加锁
//对操作的记录加独占锁(X型锁)
update table .... where id = 1;
//对操作的记录加独占锁(X型锁)
delete from table where id = 1;但是对于insert语句,也会加锁(Auto-INC锁),也在上一篇文章当中提到了。
二、MySQL是怎样加行级锁的
首先需要知道的是:
加锁的对象是索引, 而不是一整行的数据。
加锁的基本单位为next-key lock;
在前面一篇文章当中,也提到了,next-key lock本质上就是一个拥
有左开右闭区间的锁,既可以保证其他事物无法在(左,右)区间内插入数据,又可以保证其他事物无法修改右边区间的只
下面,需要了解一下四种不同的加锁方式
下面的唯一索引,都是基于"主键索引"来实现的
①唯一索引等值查询(select...where [index]=...)
存在唯一索引的情况:
当查询的记录是存在的,那么该索引当中的next-key lock会退化为记录锁。也就是针对一行数据加的锁。
唯一索引等值查询并且查询记录存在的场景下,仅靠记录锁也能避免幻读的问题。

update加的是X型记录锁。
不存在唯一索引的情况:
在索引树当中找到第一条大于该查询记录的记录之后,将该记录当中的next-key lock退化为间隙锁。
找到第一条大于该查询的记录的时候,变为间隙锁。
例如,在下表当中:
| id | name |
| 3 | "小明" |
| 5 | "小华" |
此时,如果一条sql语句执行select*from user where id=4 for update
这个时候,id为4的这一行记录,因为不存在于表当中,因此会锁住最近的索引范围。
因此会加上一个id为(3,5)范围的间隙锁。这个时候,如果有其他的事物想插入id为4的数据,那么就会被阻塞。
唯一索引等值查询并且查询记录不存在的场景下,仅靠间隙锁就能避免幻读的问题。
| 情况 | 哪种类型的锁 |
| 找到了 | 记录锁,锁住索引(主键索引) |
| 没找到 | 间隙锁,锁住查询记录两边的范围,都是开区间 |
②唯一索引范围查询
有下面这一张表
| id(主键索引) | (age | name) | sex |
| 1 | 19 | abc | 男 |
| 5 | 21 | def | 女 |
| 10 | 22 | ghi | 男 |
| 15 | 20 | lmn | 女 |
| 20 | 39 | opq | 男 |
针对「大于等于」的范围查询,因为存在等值查询的条件,那么如果等值查询的记录是
存在于表中,那么该记录的索引中的 next-key 锁会退化成记录锁。
- 情况二:针对「小于或者小于等于」的范围查询,要看条件值的记录是否存在于表中:
- 当条件值的记录不在表中,那么不管是「小于」还是「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
- 当条件值的记录在表中,如果是「小于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁;如果「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引 next-key 锁不会退化成间隙锁。其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
③非唯一索引等值查询
非唯一索引,一般都指的是联合索引。
例如:在下面这张表当中,id为主键索引,name和age为联合索引。
| id | (age | name) | sex |
| 1 | 15 | abc | 男 |
| 2 | 20 | def | 女 |
| 3 | 25 | ghi | 男 |
| 4 | 29 | lmn | 女 |
| 5 | 35 | opq | 男 |
当查询记录不存在的时候:锁住这个二级索引最近的范围(使用间隙锁)
例如:
select*from table where age=16 for update;这个时候,age这一列对应查询的值16不在表当中。
因此,加锁的过程就是这样的:首先根据age,name构成的这两列构成的索引列进行扫描,扫描到的第一条不符合条件的二级索引记录就会退化为间隙锁.
也就是间隙锁的范围是(15,20),锁住的对象是age这一列的索引,不会对主键索引加锁。
当查询记录存在的时候:先锁住二级索引(next-key lock),然后锁住主键索引(Record-lock),最后锁住二级索引的下一行(间隙锁)
例如:执行
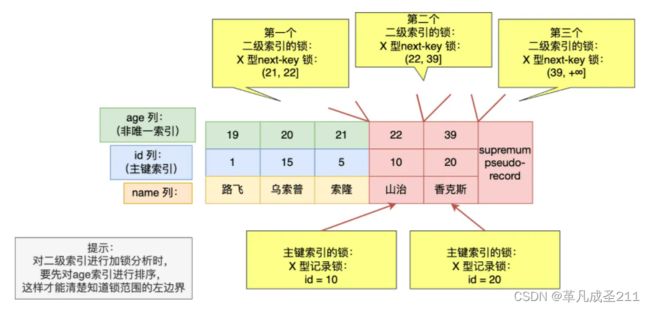
select*from table where age=22 for update;这个时候,age=22在这一个组合索引当中。
| id(主键) | (age | name) | sex |
| 1 | 19 | abc | 男 |
| 2 | 20 | def | 女 |
| 4 | 22 | lmn | 女 |
| 5 | 39 | opq | 男 |
因此,加锁的过程分为3个步骤:
| 步骤 | 对于二级索引 | 对于主键索引 |
| 1 | 对于age=22往下的范围,加锁。 范围是(20,22]的X型的next-key lock |
|
| 2 | age=22对应的主键索引为id=4; 于是对id=4的主键索引加上 X型的记录锁(record-lock) |
|
| 3 | 对于(22,39)的二级索引范围加上 X型间隙锁。 |
图解:

④非唯一索引范围查询
例如查询的sql语句为:
首先,开启一个事物:
然后执行下面的查询语句
select*from table where age>=25 for update| id | (age | name) | sex |
| 1 | 15 | abc | 男 |
| 2 | 20 | def | 女 |
| 3 | 25 | ghi | 男 |
| 4 | 30 | opq | 男 |
一共涉及5次加锁
| 步骤 | 说明 |
| 第一步 | 由于涉及等值查询,因此对于二级索引age加上next-key lock,锁住的范围为(20,25]. |
| 第二步 | 对于age=25这一行数据的主键索引加锁,主键索引为3。 |
| 第三步 | 因为涉及范围查询,因此需要扫描已经存在的,最近的一行二级索引的记录, 对于id=4这一行的主键索引加记录锁(record_lock) |
| 第四步 | 对于(25,30]的范围的二级索引加上间隙锁(next-key lock) |
| 第五步 | 对于(30,+∞)的二级索引加上间隙锁 |
⑤没有加索引的查询
| id | (age | name) | sex |
| 1 | 15 | abc | 男 |
| 2 | 20 | def | 女 |
例如,在上表当中,对于sex这一列,没有设计索引,那么查询:
select*from table where sex='男' for update这样的语句的时候,就会导致全表扫描。因此,就会对于每一条记录的主键索引加上next-key lock,这样其他事物都没有办法对于这张表进行任何增删改以及携带update的查询操作。
因此,在线上在执行 update、delete、select ... for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。