装入与链接;写时拷贝技术;内存管理的范畴;内存分配算法;基本分页存储管理;逻辑地址与物理地址转换;快表;二级页表;段页式存储管理;虚拟内存;请求分页存储管理;缺页中断;页面置换算法;CLOCK算法
一、内存的基础知识

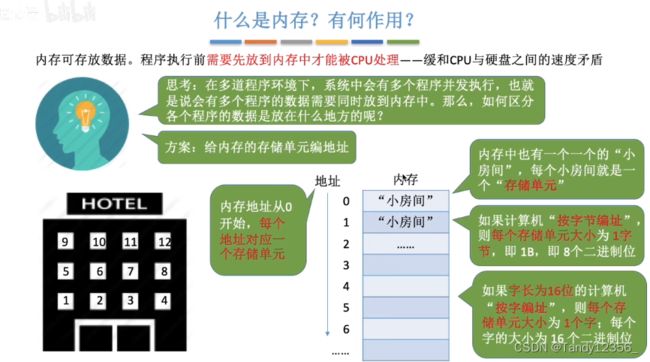



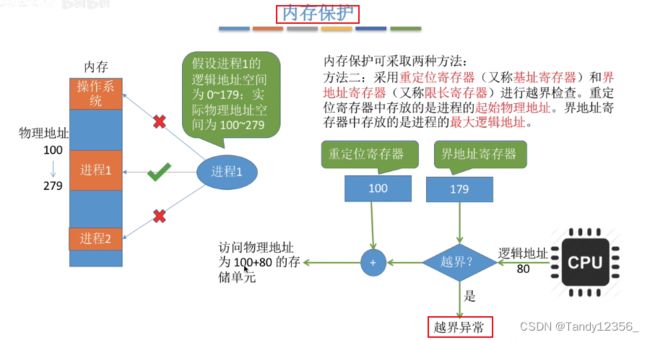
重定位寄存器存放了进程的起始地址:

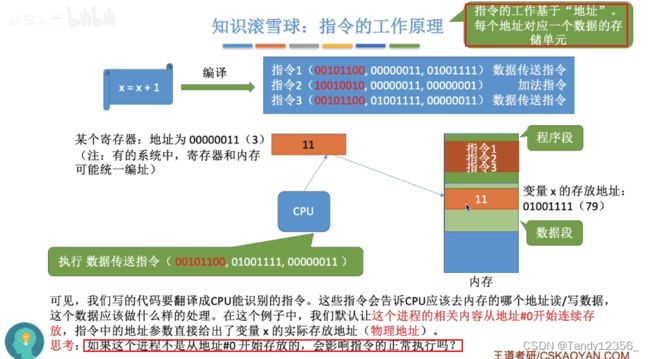
C语言的库函数,比如你使用printf函数,编译器会检查你包含的头文件当中,比如stdio.h文件当中有没有printf函数的声明,如果有就不会报错,并且当年编译的时候,你用到什么函数,编译器就会把对应的函数实现的代码从stdio.c文件当中抠出来,一起编译到可执行文件当中:


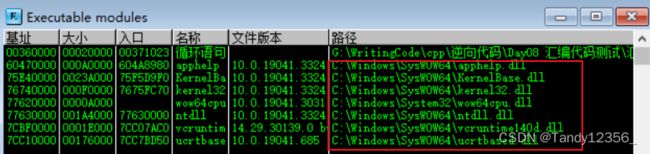
A.exe需要用到什么模块都在他的导入表里面,但是不是立即就会被加载到内存当中,而是等应用进程需要dll的功能了,才把dll贴到A的进程空间当中
像控制台程序由于不包含gdi32.dll,所以你ctrl+g搜索不到MessageBox
系统dll在内存当中通常只保留一份,多个应用进程共享一份系统dll:
如果你想修改dll的内容,Windows采用的是写时拷贝技术:

一页是4K,1M就有256页,所以还是相对比较轻量的,复制一页的代价不是很大
伪代码实现:
写操作代码(hProcess,"hello world"){
查找给hProcess写时拷贝分配的内存页;
在指定内存页进行相关操作;
}而C++的写拷贝只是复制了数据,而不是内存页:


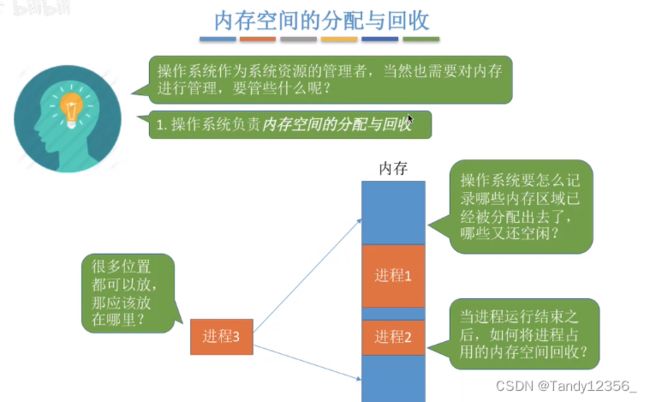
二、内存管理应该做一些什么事情?


其实就是base和limit:

内存空间的扩充:


让不可能被同时访问的程序段共享一个覆盖区:

交换技术:把进程换出内存,PCB保留在内存并挂载到OS的挂起队列当中,PCB当中同样存储着进程被换出到磁盘的什么位置:



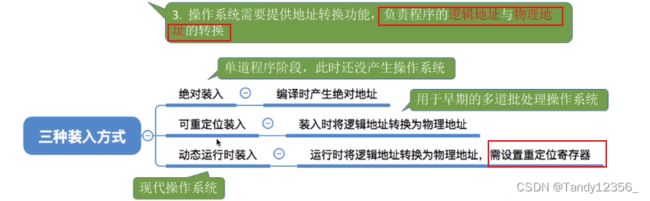
三、内存分配的方式
用于早期的单道程序,比如DOS系统:


使用结构体数组来建立分区说明表:
10MB的作业会产生2MB大小的内部碎片

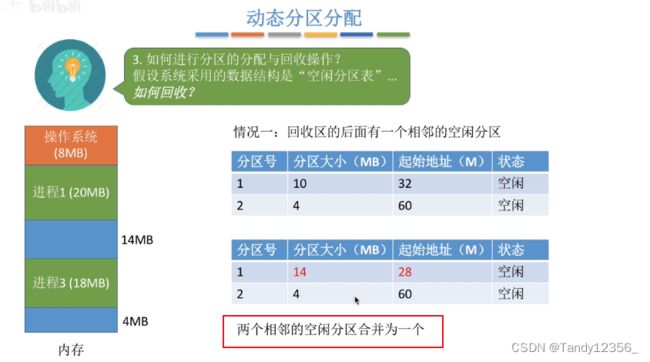
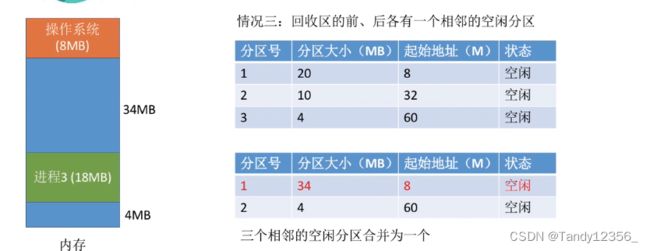
进行分区的分配和回收:回收之后的内存是否应该和上下内存合并?

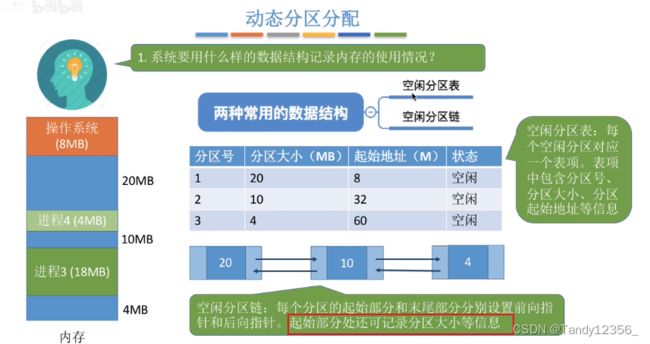

2种情况:删除一个表项/仅仅修改可用分区的大小&起始地址


回收:
相邻的内存区域需要合并:合并到前面/后面/前后汇成一体/新建一个表项
一言以蔽之:有相邻的内存分区就把他们合并



四、内存分配算法





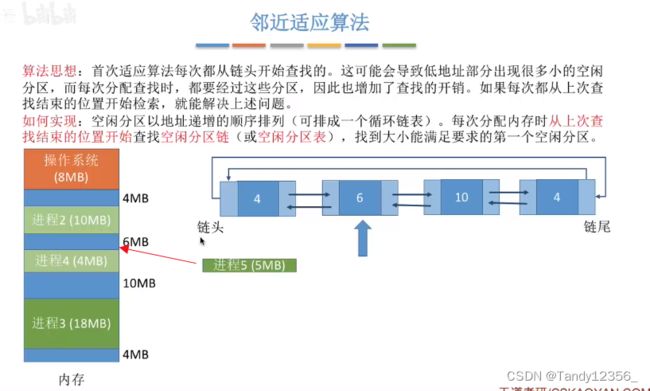
不需要重新排列

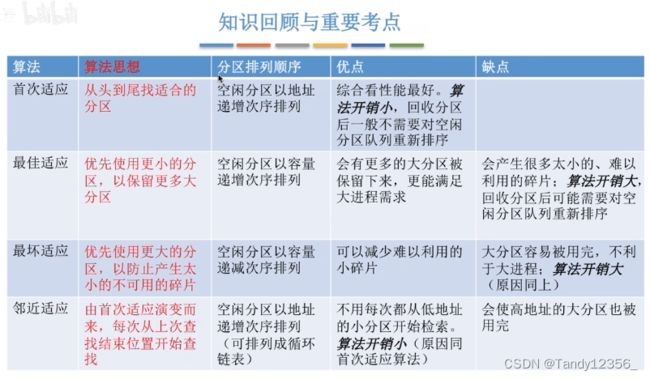
五、非连续分配的存储管理方式——基本分页存储

进程的各个页会被放到内存的各个页框当中:
既然内存分页了,那么装入程序也要把整个exe按页划分、按页装入

物理内存和进程的逻辑地址空间都要相同划分

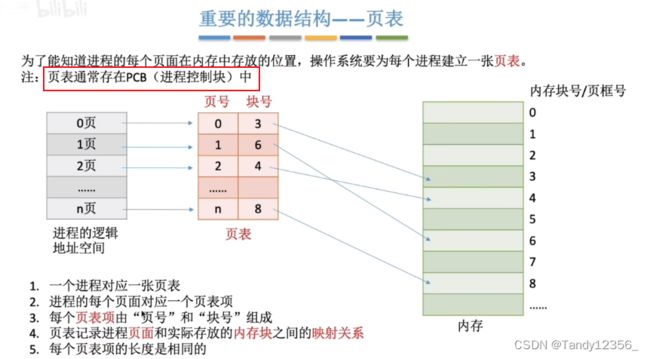
页表存储在PCB当中,一个进程一张页表,记录页面和页框的映射关系
页表只有两项组成,即页号和块号,不包含起始地址


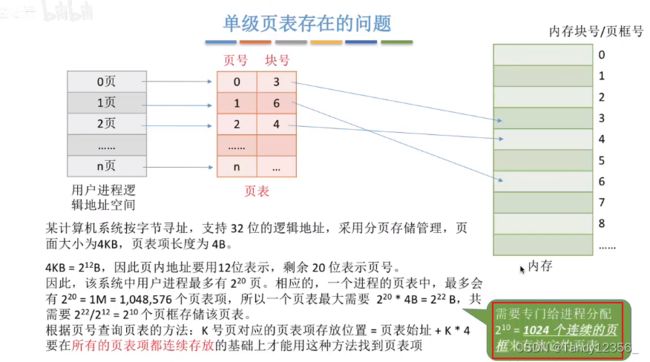
想要表示所有块号,需要20bit,至少用3B来表示每个块号
每个页表项占3B,而且都是连续存放
由于页表当中的页号是隐含的,因此,页号和数组的下标一样不用占存储空间,只需要存储块号
页表是每个进程独有的,用于查找进程被分割的每页被映射到物理内存的什么位置

补充:
页表记录的是内存块号而不是内存块的起始地址,因此还需要额外计算内存块的起始地址,才能找到真正的物理地址

分页之前的逻辑地址》物理地址:

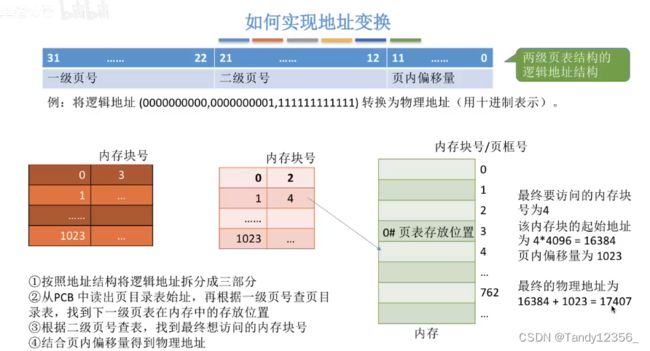
分页之后如何实现逻辑地址》物理地址?
访问逻辑地址A的时候,首先要获取逻辑地址A对应的页号,然后查页表,确定物理页框在内存的起始地址,再获取逻辑地址当中的页内偏移量,拼接成一个完整的物理地址

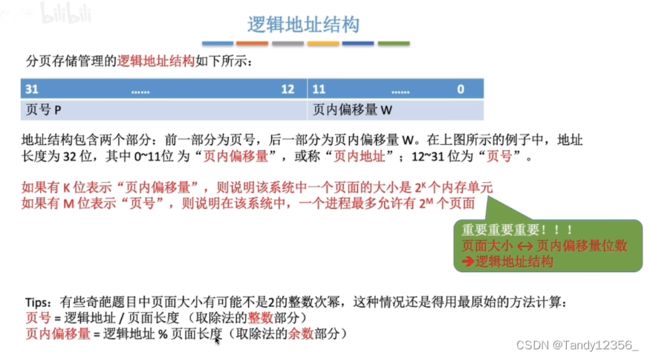
如何获取一个逻辑地址所对应的页号和页内偏移?

页面大小为2的整数幂的好处1:

这样计算机硬件就不需要做复杂的除法&取余操作,拿到一个逻辑地址之后,页号和页内偏移就已经有了,这样可以让计算机的硬件更快地把逻辑地址拆解成页号和偏移两部分!
页面大小为2的整数幂的好处2:
查页表得到物理内存块号,直接和逻辑地址后面的页内偏移拼接在一起就是物理地址了,而不用再用乘法加法运算得到,提高了硬件的执行速度

小结:页面大小为2的整数幂的2个好处


六、基本地址变换机构

当进程A上处理机运行的时候,OS要把进程A的页表的起始地址和长度放到页表寄存器当中
根据页表的起始地址+第几个页号就可以找到所有页面映射的物理地址了

页表始止(base),页表长度(limit,页号的最大值)
页号超过进程当中总的页面数量就会报越界中断:
一旦CPU把逻辑地址放到页表寄存器当中,后续工作就会自动进行,单级页表一次地址转换需要访存两次,一次是查页表,一次是访问数据所在的物理内存

逻辑地址转物理地址只需要告诉逻辑地址即可,不需要其他任何额外的信息:


为了方便查询,就用4B的空间存储每个页表项,这样通过X+4*M就可以轻松找到M号页对应的块号了

七、具有快表的地址变换机构

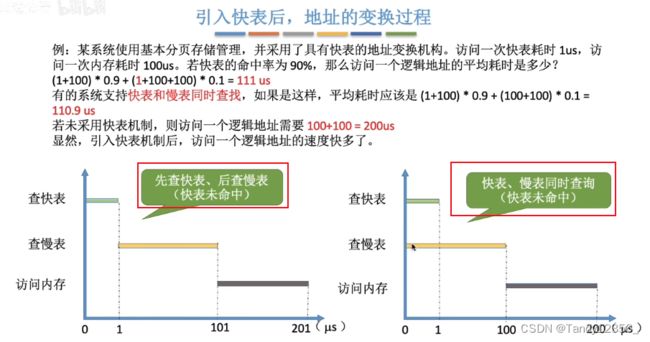
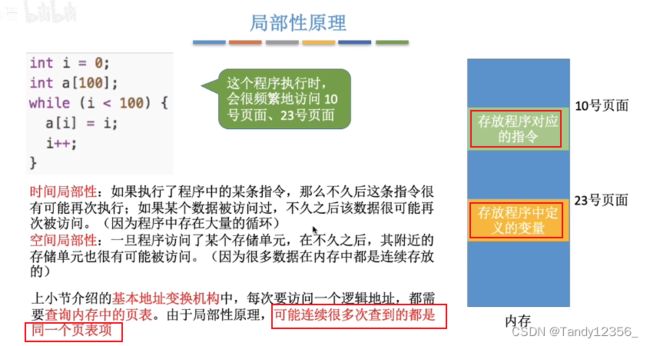
内存当中最近有可能被频繁访问的内容存储到高速缓存里面

当一个进程上处理机运行(进程切换)的时候,OS会清空快表的内容
访问页表项的同时也会复制一份到TLB当中

快表之所以快是因为,CPU每访问一次内存都需要100us,而访问快表每次只需要1us
快表中存放的是慢表中的一部分副本
数据cache,指令cache


八、二级页表
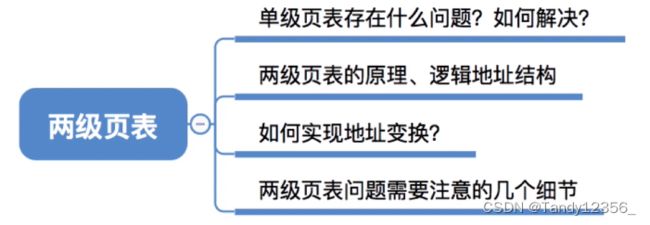
光是页表项最多就需要1024个连续的页框来存储,代价太大了
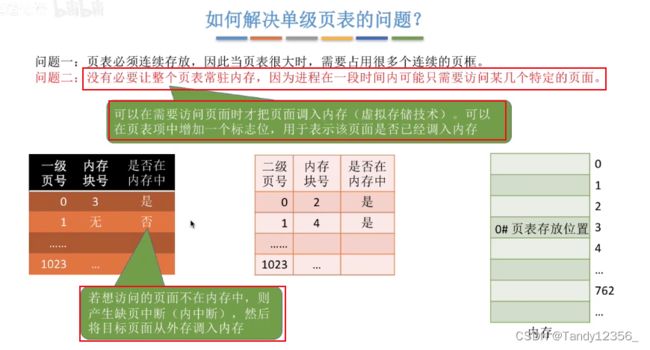
进程在一个时间段内通常只需要访问某几个特定的页面就可以正常运行了,因此,没必要让进程的整个页表都驻留在内存当中,只要让进程此时需要用到的页面对应的页表项在内存中保存就可以了

块号一样都是762,但是页号重新编排了:
每个页面可以存放1K(1024)个页表项,2^20个页号需要1K个页框来存储


从3号内存块读出对应的二级页表:



九、基本分段存储管理

CPU执行指令的时候是根据段号来区分各个段的
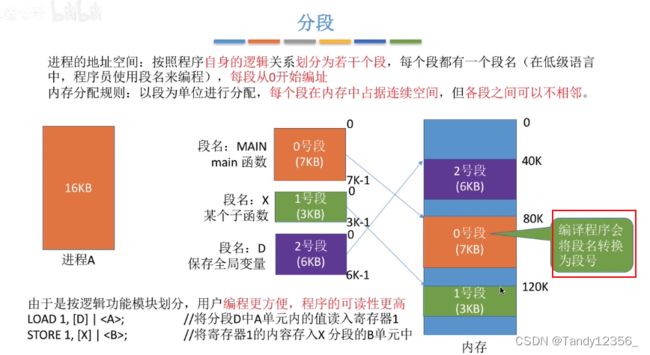



检查越界:

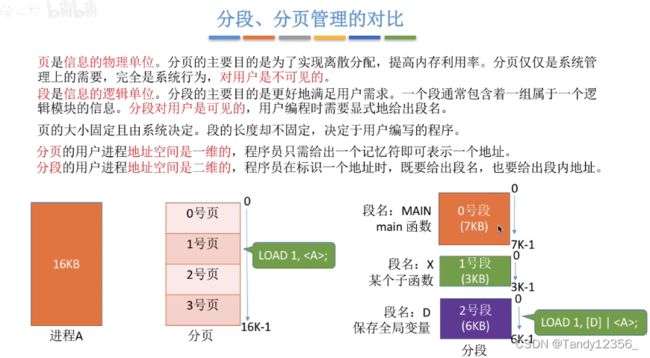




十、段页式管理方式



一个进程一个段表,但有可能对应多个页表

每一个段表项相当于一个页表寄存器


十一、虚拟内存
虚拟存储技术比传统的换入换出要先进:

如果此时在游戏的A场景,那么B场景的内容此时就不需要加载进内存
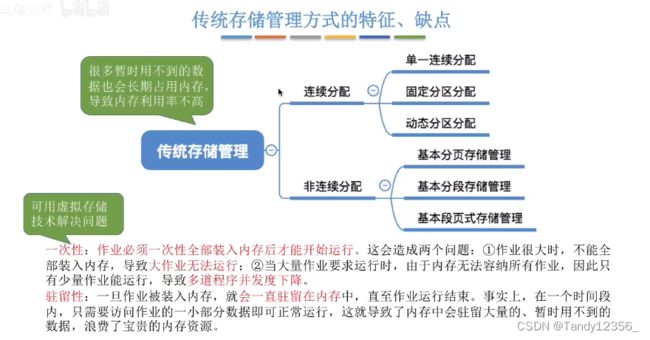


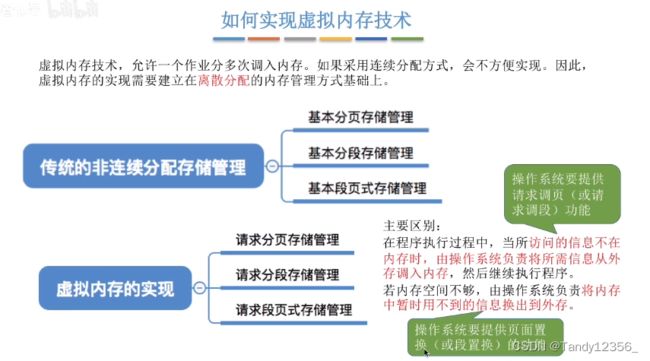

十二、请求分页存储管理



引入缺页中断机制之后才能实现请求调页功能:
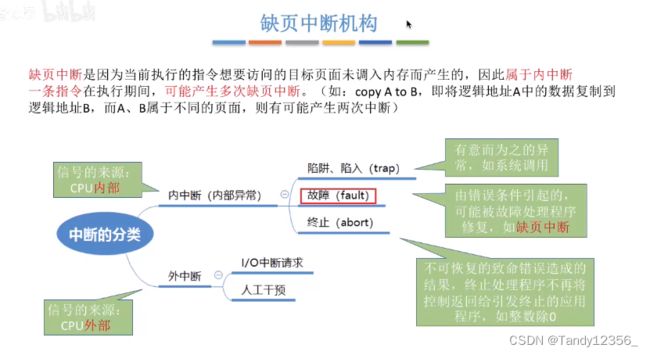





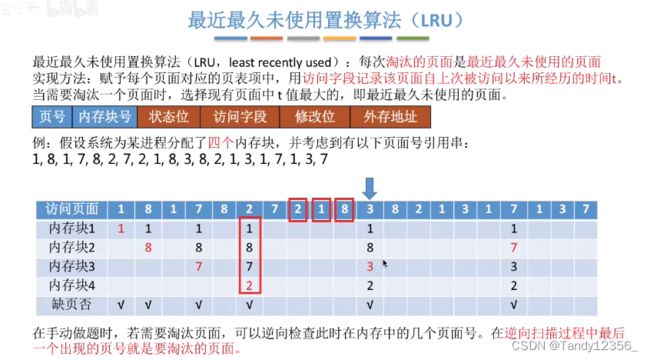
十三、请求分页存储管理的页面置换算法



一共缺页9次:
使用一个队列辅助观察

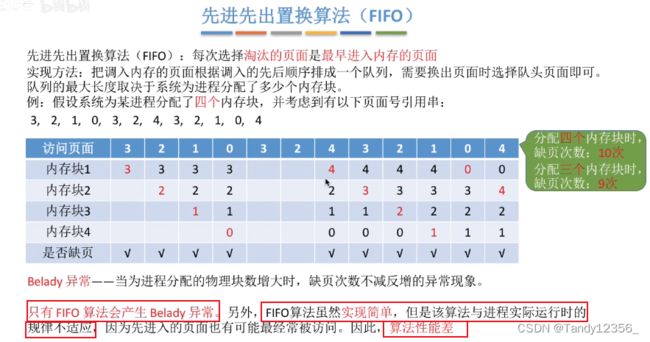
逆向往前检查:
该算法的实现需要专门的硬件支持,虽然性能最接近最佳置换算法,但是实现困难,开销大
1 3 4 2 5这几个页面会通过链接指针的方式链接成一个循环队列:

到6的时候,在第二轮检查的过程中发现1号页面访问位为0,所以淘汰1号页面,换入6号页面,并把6号页面的访问位置1,同时clock指针指向下一个页面的位置
访问4号页面的时候,只是把访问位置1,但是clock指针不会移动,只有缺页的时候,clock指针才会移动

如果页面没有被修改过的话,就不用换出内存,直接覆盖就可以了,所以优先淘汰这种页面,否则还需要把修改后的内存页先交换到磁盘上去,再把新的页面换入
只有第二轮扫描会修改第一个访问位
没访问>没修改(0,1)第一个优先级更高
 四轮扫描的例子:
四轮扫描的例子:

十四、页面分配策略

为了解决抖动现象,引出了工作集的概念


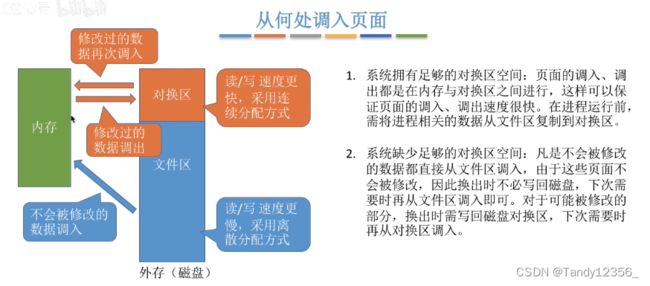 也有的OS第一次是从磁盘直接装载到内存,之后交换的时候是放在交换区
也有的OS第一次是从磁盘直接装载到内存,之后交换的时候是放在交换区


窗口大小:设置为4,工作集:在某段时间内实际访问页面的集合(元素互异性)
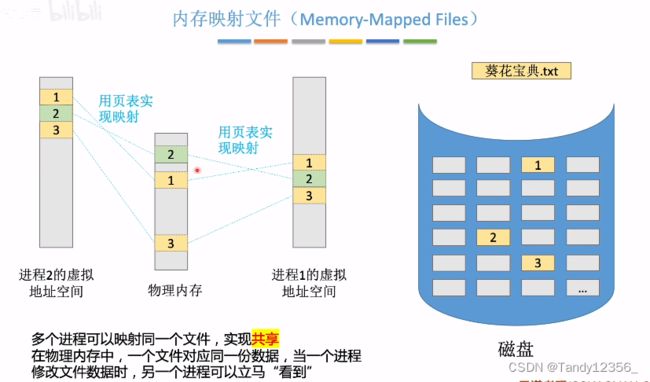
十五、内存映射文件