【深度学习_TensorFlow】卷积神经网络(CNN)
写在前面
这篇文章的行文思路如下:
-
先根据视频了解卷积和卷积神经网络的整体框架
-
接着了解卷积神经网络构建过程中的一些重要操作,包括内积、填充、池化。
-
然后介绍卷积层如何实现。
-
最后用卷积神经网络的开山之作(LeNet-5)来进行上手练习。
一、初识卷积
最近学习信号与系统的时候,了解了卷积的相关概念,联想起此前学习opencv的时候也有卷积操作,到现在学到深度学习的时候又碰到了卷积神经网络,但是也一直搞不懂为什么要那样做,有什么意义,于是查阅相关博客视频,发现视频比博客直观的多,于是多分享几个制作精良的视频,帮你从数学定义、信号处理、图像处理、现实应用多维度了解卷积!
| 卷积在声乐中体现(了解即可) | 卷积究竟卷了啥?——17分钟了解什么是卷积 |
|---|---|
| 卷积在图像中应用 | 【卷积神经网络】为什么卷积哪儿都能用? |
| 卷积物理意义、卷积在矩阵运算 | 【卷积】直观形象的实例,10分钟彻底搞懂 |
| 卷积神经网络解释 | 【卷积神经网络】8分钟搞懂CNN,动画讲解喜闻乐见 |
| 卷积神经网络解释 | 什么是卷积神经网络CNN?【知多少】 |
| 卷积神经网络 | 【数之道 08】走进"卷积神经网络",了解图像识别背后的原理 |
| 神经网络可视化网站 | https://poloclub.github.io/cnn-explainer/ |
虽然这些视频讲解不尽相同,但是里面有大量的共同点,我们就只讨论卷积在神经网络中应用,有几点可以串联补充
1. 卷积优势
全连接的劣势就是卷积的优势。全连接层的参数量极大,具体可以体现在:假设一张图像输入的像素量为 28×28=784,我们将权值 w 和偏置 b 视为参数(每两个节点之间的参数w和b不一定相同),对于输入节点为 784,输出节点为 256 的第一层网络来说,总参数量就为784×256 + 256 = 200960(后面的256是b),这仅仅只是28×28的图像在第一层的参数量,更大的图像,更多的层数,就意味着更加恐怖的参数量!更难的特征提取!
|
|
|
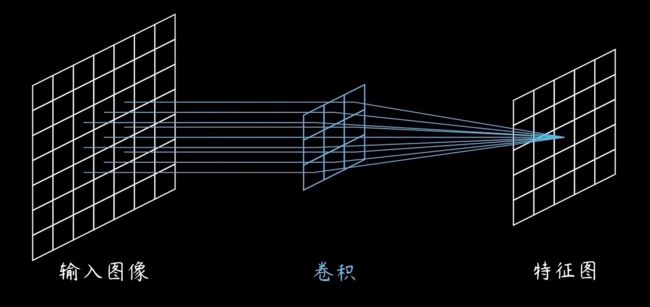
2. 局部相关
为解决全连接层的缺陷,我们引入局部相关的概念,其实也挺容易理解的,对于一张图像,并非所有像素点都是重要的,就如手写数字识别中,手写数字才是关键,其他的背景部分都是次要的。因此关注的中心可以进一步缩小。将全连接层替换为卷积层来简化特征提取。具体的卷积操作如下图所示
局部相关操作是指使用卷积层中的卷积核,在输入图像上进行滑动,对每个位置进行卷积运算(卷积核与感受野内的图像矩阵进行内积运算,不了解可以搜索内积相关文章)。和信号的卷积运算先反褶、时移、叠加还是稍有些不同的。
3. 填充与池化
先讲讲为什么要进行填充,很明显上面的卷积计算后原来5×5 的图像矩阵,转换为3×3的特征矩阵,这样可能会丢失一些提取出来的特征,例如第一幅图像‘7’未进行填充,经过两个不同的卷积核后,‘7’ 的竖直特征被提取出,但是水平特征却丢失了,解决的办法就是,将原图像矩阵周围填充(如右图),这样水平特征和竖直特征都被提取出来了。(后文实现卷积网络层的方法无需进行手动填充,tensorflow自动帮你实现)

|

|
池化通常在卷积层之后,我们针对卷积过后的特征图中的小矩阵求最大值,就是最大池化;小矩阵中的数求平均值就是平均池化,从而减少模型参数,提高模型的计算效率和泛化能力,还可以在一定程度上防止过拟合,提高模型的鲁棒性
二、卷积神经网络
接下来,我们以一个经典的卷积模型 LeNet-5 来学习卷积神经网络。这个卷积模型是Yann LeCun 等人在1998年提出的,非常适合初学者学习,我们稍微修改这个模型,尝试使用 Tensorflow 复现出修改后的模型来,部分操作可能和下图模型不一致,但效果相差不大。

为了方便,我们仍然使用之前的 mnist 数据集来作为输入数据,图像的尺寸为 28×28,初始张量为[b, 28, 28, 1]:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 6) 60
max_pooling2d (MaxPooling2D (None, 13, 13, 6) 0
)
conv2d_1 (Conv2D) (None, 11, 11, 16) 880
max_pooling2d_1 (MaxPooling (None, 5, 5, 16) 0
2D)
flatten (Flatten) (None, 400) 0
dense (Dense) (None, 120) 48120
dense_1 (Dense) (None, 84) 10164
dense_2 (Dense) (None, 10) 850
=================================================================
- 经过一个卷积层(convolution),得到[b, 26, 26, 6]形状的张量,由于代码没有填充,故张量尺寸会缩减,具体的计算公式如下:其中(b, h’, w’, c)的张量,卷积核的数量c,卷积核的大小k,步长s, p h p_h ph表示上下填充行数(只考虑两端相等), p w p_w pw表示左右填充列数(只考虑相等情况),在这里
h ′ = [ h + 2 ⋅ p h − k s ] + 1 h'=\left[\frac{h+2\cdot p_h-k}{s}\right]+1 h′=[sh+2⋅ph−k]+1
h ′ = [ h + 2 ⋅ p w − k s ] + 1 h'=\left[\frac{h+2\cdot p_w-k}{s}\right]+1 h′=[sh+2⋅pw−k]+1
在第一层卷积,就可以使用上面的公式来计算,括号里面向下取整:
h ′ = [ 28 + 2 ∗ 0 − 3 1 ] + 1 = ⌊ 25 ⌋ + 1 = 26 w ′ = [ 28 + 2 ∗ 0 − 3 1 ] + 1 = ⌊ 25 ⌋ + 1 = 26 \begin{aligned}h^{\prime} & =\left[\frac{28+2*0-3}{1}\right]+1=\lfloor25\rfloor+1=26\\ & \\ w^{\prime} & =\left[\frac{28+2*0-3}{1}\right]+1=\lfloor25\rfloor+1=26\end{aligned} h′w′=[128+2∗0−3]+1=⌊25⌋+1=26=[128+2∗0−3]+1=⌊25⌋+1=26
-
经过一个向下采样层,张量尺寸缩小为[b, 13, 13, 6],这里我们使用池化层来实现;
-
经过第二个卷积层,得到[b, 11, 11, 16]的张量;
-
经过第二个向下采样层,张量尺寸缩小为[b, 5, 5, 16],这里我们使用池化层实现;
-
将张量打平为[b, 400],之后进入三个节点为 120、84、10 的全连接层将结果矩阵输出
三、卷积实现
由于使用卷积神经网络进行手写数字识别和之前的使用全连接层实现的手写数字识别的代码极为相似,只需将网络层的地方修改即可,所以就不再介绍其它部分的代码,不了解的可以查阅**这篇文章 ,**在tensorflow中卷积的实现主要有下面两种方式,自定义方式函数的方式和卷积层的方式
1. 自定义权值
tf.nn.conv2d(input, kernel, strides=1, padding=[[0, 0], [0, 0], [0, 0], [0, 0]])
input:输入数据图像,例如[100, 28, 28, 3]表示 100 张 28×28的三通道图像。
kernel:卷积核,例如[3, 3, 3, 4] 表示4个 3×3 的三通道的卷积核
strides:表示步长
padding:表示填充,填充的具体数量由tensorflow自动计算并完成
input = tf.random.normal([100, 28, 28, 3])
w = tf.random.normal([3, 3, 4, 3])
out = tf.nn.conv2d(x, w, strides=1, padding=[[0, 0], [0, 0], [0, 0], [0, 0]])
2. 卷积层的实现
还有更为常见的层方式实现:
# strides=1, padding='same',可得到输入输出同大小的卷积层,具体填充操作自动完成
layers = layers.Conv2D(4, kernel_size=3, strides=1, padding='SAME')
四、leNet-5实战
这套代码和之前使用全连接层实现mnist手写数字识别的代码框架是一致的,只是修改了网络层的部分。不了解的可以查看往期专栏文章。
# import tensorflow as tf
# from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics, regularizers
# from tensorflow.keras.callbacks import EarlyStopping
# # 处理每一张图像
# def preprocess(x, y):
#
# x = tf.cast(x, dtype=tf.float32) / 255.
# y = tf.one_hot(y, depth=10)
#
# return x, y
#
# # 数据集读取
# (x, y), (x_test, y_test) = datasets.mnist.load_data()
#
# # 交叉验证切分,防止过拟合的有效手段
# idx = tf.range(60000) # 按顺序生成索引0~59999
# idx = tf.random.shuffle(idx) # 将索引打乱
# x_train, y_train = tf.gather(x, idx[:50000]), tf.gather(y, idx[:50000])
# x_val, y_val = tf.gather(x, idx[-10000:]), tf.gather(y, idx[-10000:])
#
# # 训练集
# train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# train_db = train_db.map(preprocess).shuffle(10000).batch(128).repeat(5) # 这里粗暴的重复数据增加数据集,repeat改小训练时间缩短
#
# # 验证集
# val_db = tf.data.Dataset.from_tensor_slices((x_val, y_val))
# val_db = val_db.map(preprocess).shuffle(10000).batch(128)
#
# # 测试集
# test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
# test_db = test_db.map(preprocess).shuffle(10000).batch(128)
#
# # 定义早停法回调函数
# early_stopping = EarlyStopping(monitor='val_loss', # 监视验证集loss
# patience=3, # 当验证集loss在2个epoch内都没有改善则停止训练
# mode='min', # 监测loss时一般设置为min,监测准确值时一般设置为max
# verbose=1, # 检测值改善时打印一条信息
# restore_best_weights=True # 将权重恢复到最好的一个epoch
# )
#
# # 网络构建
# # 正则化:在模型损失函数中加入权重参数的L2范数作为惩罚项,力度由0.001控制。
# network = Sequential([
# layers.Reshape(target_shape=(28, 28, 1), input_shape=(28, 28)), # 这里指定了层,就不需要在process里进行reshape了,也不需要built构建参数了
# layers.Conv2D(6, kernel_size=3, strides=1), # 6个3×3的卷积核,步长设置为1
# layers.MaxPooling2D(pool_size=(2, 2), strides=2), # 高宽减半的池化层
# layers.Conv2D(16, kernel_size=3, strides=1), # 第二个卷积层,16个3×3的卷积核
# layers.MaxPooling2D(pool_size=(2, 2), strides=2), # 高宽减半的池化层
# layers.Flatten(), # 打平,方便连接全连接层
# layers.Dense(120, kernel_regularizer=regularizers.l2(0.001), activation='relu'),
# layers.Dense(84, kernel_regularizer=regularizers.l2(0.001), activation='relu'),
# layers.Dense(10)
# ])
#
# # 参数构建
# # network.build(input_shape=(None, 28, 28, 1)) # 由于第一层已经指定好大小了,所以这里不构建也可以
# # 模型展示
# network.summary()
# # 模型装配
# network.compile(optimizer=optimizers.Adam(learning_rate=0.01),
# loss=tf.losses.CategoricalCrossentropy(from_logits=True),
# metrics=['accuracy'])
# # 模型训练,这里控制训练次数
# network.fit(train_db, epochs=50,
# validation_data=val_db, validation_steps=10,
# callbacks=[early_stopping])
# # 模型评估
# print('模型评估:')
# network.evaluate(test_db)
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# 这两段代码框架一致,只是在不同位置进行了数据处理,注意辨别
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, regularizers
from tensorflow.keras.callbacks import EarlyStopping
# 处理每一张图像
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [28, 28, 1])
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
# 数据集读取
(x, y), (x_test, y_test) = datasets.mnist.load_data()
# 交叉验证切分,防止过拟合的有效手段
idx = tf.range(60000) # 按顺序生成索引0~59999
idx = tf.random.shuffle(idx) # 将索引打乱
x_train, y_train = tf.gather(x, idx[:50000]), tf.gather(y, idx[:50000])
x_val, y_val = tf.gather(x, idx[-10000:]), tf.gather(y, idx[-10000:])
# 训练集
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.map(preprocess).shuffle(10000).batch(128).repeat(10)
# 验证集
val_db = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_db = val_db.map(preprocess).shuffle(10000).batch(128)
# 测试集
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).shuffle(10000).batch(128)
# 定义早停法回调函数
early_stopping = EarlyStopping(monitor='val_loss', # 监视验证集loss
patience=3, # 当验证集loss在2个epoch内都没有改善则停止训练
mode='min', # 监测loss时一般设置为min,监测准确值时一般设置为max
verbose=1, # 检测值改善时打印一条信息
restore_best_weights=True # 将权重恢复到最好的一个epoch
)
network = Sequential([
layers.Conv2D(6, kernel_size=3, strides=1), # 6个3×3的卷积核,步长设置为1
layers.MaxPooling2D(pool_size=(2, 2), strides=2), # 高宽减半的池化层
layers.Conv2D(16, kernel_size=3, strides=1), # 第二个卷积层,16个3×3的卷积核
layers.MaxPooling2D(pool_size=(2, 2), strides=2), # 高宽减半的池化层
layers.Flatten(), # 打平,方便连接全连接层
layers.Dense(120, kernel_regularizer=regularizers.l2(0.001), activation='relu'),
layers.Dense(84, kernel_regularizer=regularizers.l2(0.001), activation='relu'),
layers.Dense(10)
])
# 参数构建
network.build(input_shape=(None, 28, 28, 1))
# 模型展示
network.summary()
# 模型装配
network.compile(optimizer=optimizers.Adam(learning_rate=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 模型训练,这里控制训练次数
network.fit(train_db, epochs=50,
validation_data=val_db, validation_steps=10,
callbacks=[early_stopping])
# 模型评估
print('模型评估:')
network.evaluate(test_db)
写在最后
点赞,你的认可是我创作的动力!
⭐收藏,你的青睐是我努力的方向!
✏️评论,你的意见是我进步的财富!