GO-面试考点总结
1:go同步锁有什么特点,作用是什么?
当一个goroutine获得同步锁时,其他的只能等待。如果该gouroutine释放了读,其他可以读不可以写,但是在写占用时,其他不可读和写。作用是保证资源在使用时的独有性,不会因为并发而导致数据错乱,保证系统的稳定性。
2:go语言中channel有什么特点,需要注意什么,数据结构怎样?
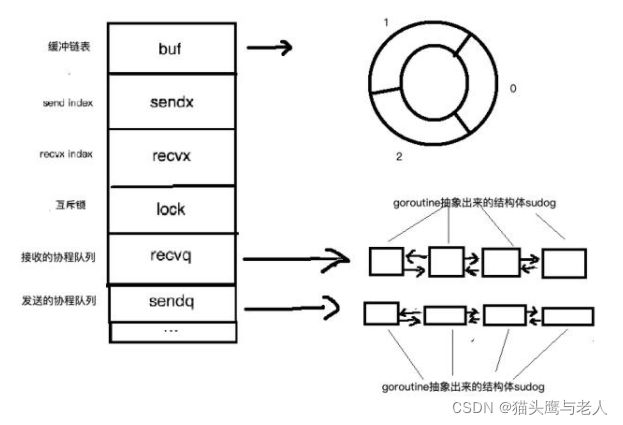
先进先出,分为有缓存和无缓冲
给nil发或者从nil的channel接收都会永久阻塞。给已经关闭的channel发会Panic,从关闭的channel取,如果缓冲区中为空则会返回零值
无缓冲的channel是同步的,有缓存的是非同步的
参考于:百度安全验证https://baijiahao.baidu.com/s?id=1637513659872023994&wfr=spider&for=pc
lock:互斥锁,加锁-》把数据cpoy到队列(获取取出),修改sendx或者recvx的值对应buf的位置-》释放锁
sendq和recvq是双向链表:原因:在send和recv过程中获取当我位置比较方便,一直循环就行。依靠链表自身特性也符合先进先出。
buf:有缓存的才有,环形链表
sendx和recvx:记录buf中发送或者接收的可写的index
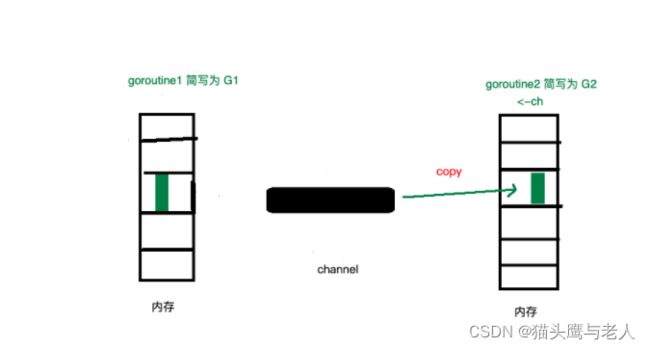
缓存满了存或者没有取就会阻塞goroutine,G1满了会主动调用GO的调度器,让出M给其他G使用,G1会被抽象成含有G1指针和send元素sudog结构体,保存到hchan的sendq中等待被唤醒。这是G2recv数据,channel会将等待队列中的G1推出,将G1send的数据推到缓存中,然后调用GO的schedule唤醒G1,把G1放到可以允许的gouroutine队列中。如果是取的过程阻塞,就是当G1推数据时,不会有锁操作,G1直接copy到G2栈中,减少了内存copy。
3:go的new和make有什么区别?
new : 分配空间,传递给new函数的是一个类型而不是值,返回的是新分配的地址的指针
make:为slice, map 或者chan初始化,返回引用。make函数目的和new不同,用于创建上面三类,返回的是类的实例
4:打印函数?
printf:标准化输出到屏幕,sprintf:格式化输出到字符串中,fsprintf:格式化字符串到文件中
5:数组和切片的区别?
数组的长度是数组类型的一部分,通过值传递
切片:指针,长度,容量三部分组成,地址传递通过数组或者make初始化,存在扩容
6:defer?
程序结束执行,return,panic都会执行,多个最后的先执行。
用于:打开释放锁,打开关闭连接
7:slice的底层实现?

基于数组实现,是底层数组的抽象,底层内存是连续分配的,效率很高,通过索引获取数据,可以迭代和垃圾回收优化。通过指针引用底层数组,切片本身非常小,只有三个字段:指向底层数组的指针,切片长度,切片容量。
切片的扩容策略:
1:新申请的大于2倍的旧容量,选择这个;旧的容量小于1024就是2倍,大于等于1024循环增加4分之1,如果最终容量计算值溢出,最终就是申请的容量
扩容前后的slice是否相同?
如果扩容后底层引用的数组还有空间,就还是指向之前的数组,切片操作会影响其他指向的slice。如果已经达到最大值,会重新开辟空间,进行拷贝,不影响之前的,最好使用copy复制
8:php数据的实现,怎么保证有序?
连续的内存空间,Bucket 即储存元素的数组,arData 指向数组的起始位置,使用映射函数对 key 值进行映射后可以得到偏移值,通过内存起始位置 + 偏移值即可在散列表中进行寻址操作。
time32

散列函数计算的值是-1 到2的幂次方,比如一个key是算得-1,那value存的位置就在bucket的1的位置,hash冲突的解决办法:
1. 将散列值放到相邻的最近地址里
2. 换个散列函数重新计算散列值
3. 将冲突的散列值统一放到另一个地方
4. 在冲突位置构造一个单向链表,将散列值相同的元素放到相同槽位对应的链表中。这个方法叫链地址法,PHP 数组就是采用这个方法解决散列冲突的问题。
当我们访问 $arr ['key'] 的过程中,假设首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向 arData 数组下标为 1 的元素。此时我们将该元素的 key 和要访问的键名相比较,发现两者并不相等,则该元素并非我们所想访问的元素,而元素的 zval.u2.next 保存的值正是另一个具有相同散列值的元素对应 arData 数组的下标,所以我们可以不断通过 zval.u2.next 的值遍历直到找到键名相同的元素。
扩容?
如果已删除元素所占比例达到阈值,则会移除已被逻辑删除的 Bucket,然后将后面的 Bucket 向前补上空缺的 Bucket,因为 Bucket 的下标发生了变动,所以还需要更改每个元素在中间映射表中储存的实际下标值。
如果未达到阈值,PHP 则会申请一个大小是原数组两倍的新数组,并将旧数组中的数据复制到新数组中,因为数组长度发生了改变,所以 key-value 的映射关系需要重新计算,这个步骤为重建索引。
在删除某一个数组元素时,会先使用标志位对该元素进行逻辑删除,即在删除 value 时只是将 value 的 type 设置为 IS_UNDEF,而不会立即删除该元素所在的 Bucket,因为如果每次删除元素立刻删除 Bucket 的话,每次都需要进行排列操作,会造成不必要的性能开销。
9:go的map底层实现?
学习于:Golang map的底层实现 - maji233 - 博客园
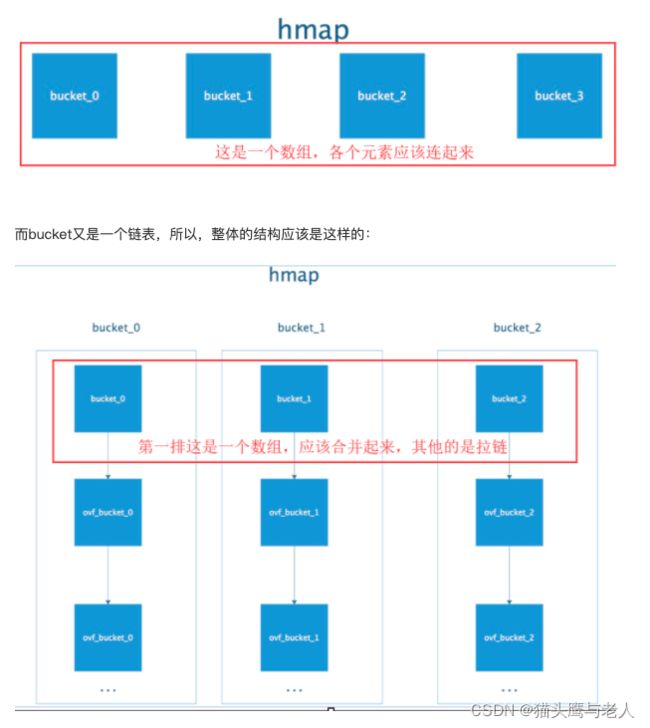
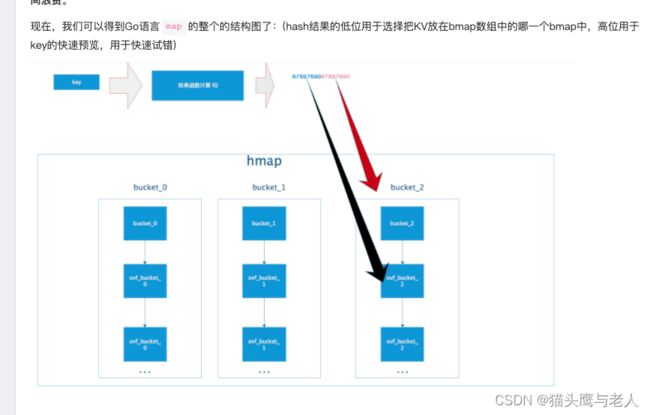
map是用数组+链表实现hashTable。
为什么遍历是无序的?
map是有删除的,那个空的bucket会被新的数据填充,这样会导致遍历结果不一致,再一个就是map扩容时位置也会bucket内的数据也会有迁移。所以官方直接在map遍历里面引入随机开头点的遍历机制,防止别人在依赖于map的遍历顺序来写业务,会出乱子的!

Go map在hash冲突过多时,会发生扩容操作,为了不全量搬迁数据,使用了增量搬迁,[0]表示当前使用的溢出桶集合,[1]是在发生扩容时,保存了旧的溢出桶集合;overflow存在的意义在于防止溢出桶被gc。
map查找:通过hash获取到key,然后利用B计算出所在的bucket,当前的bucket没有找到,就去对应的overfolw bucket查找,再去对比完整数据,如果存在hash冲突,就利用链表找到需要的value。

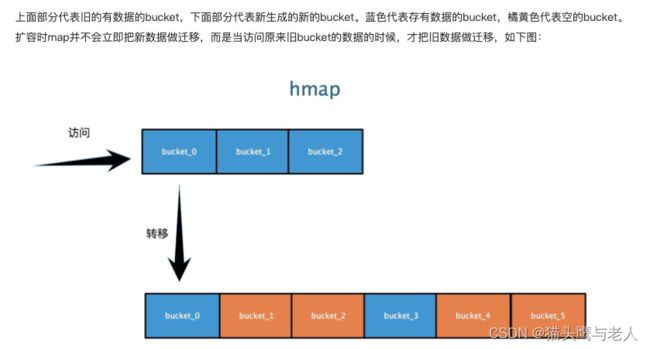 10:go GMP调度原理?
10:go GMP调度原理?
参考于:https://segmentfault.com/a/1190000018775901
golang GMP调度模型_m0_47167062的博客-CSDN博客
- G的创建和分配。
- P的本地队列和全局队列的负载均衡。
- M如何寻找G。
- M如何从G1切换到G2。
- work stealing,M如何去偷G。
- 为何需要自旋线程。
- G进行系统调用,如何保证P的其他G'可以被执行,而不是饿死。
- Go调度器的抢占。
Go调度本质是把大量的goroutine分配到少量线程上去执行,并利用多核并行,实现更强大的并发。
几个概念:
M0:m0是Go runtime所创建的第一个系统线程,一个Go进程只有一个M0,也叫主线程,负责初始化和操作第一个G,启动之后就和其他m一样了。
G0:比如当前g1运行完后就是g0,负责调度时协成的切换。
全局队列:接收了别的本地传过来的g,g会被打乱顺序,供其他自旋的M获取p,拉一部分部署全部,实现负载均衡
本地队列:M1-P1维护了一个自己的本地队列存放G,p1本地满了,就要把前一半和新创建的g放到全局队列(256)
抢占:go调度器抢占比较温和,满足:G进行系统调度超过20us,或者G运行超过10ms就会给goroutine发一个抢占请求,何时停下来不管,解决G饥饿
自旋:创建g的时候允许的g会尝试唤醒其他空闲的p和m,如果唤醒了M2,m2绑定了p2,并且运行p0,本地队列没有g,此时m2为自旋线程。m2尝试从全局队列(GQ)取一批g放到p2的本地队列,从全局队列取1个g,但每次不要从全局队列移动太多的g到p本地队列,给其他p留点。这是从全局队列到P本地队列的负载均衡。全局没有了,M2就要从其他有G的p偷一般g过来。
当有多个m自旋时,并不会销毁,因为创建销毁都会浪费CPU,我们希望当有g创建时能立马被m执行,所以最多有一个数量的自旋,其他休眠。
假如:m2-p2的g2进行了阻塞调用,又创建了g3,p2会执行以下判断:p2本地有g、全局队列有g、或者有空闲的m,p2会立马唤醒一个m和他绑定,否则p2会加入到空闲的队列中,等待m来获取可用的p,

上面例子,若是进行了非阻塞系统调用,m2会和p2解绑,并记住p2.当m2退出系统调用状态,会尝试获取p2,无法获取,就获取空闲的p,依然没有,g2就会放到全局队列。
11:Mutex正常模式和饥饿模式?
非公平锁:等待锁的goroutine按顺序等待,但是新唤醒的不会立马获得锁,而是要和新请求锁的goroutine竞争,新请求的正在CPU执行可能很有优势,这种会导致新唤醒的一直获取不到锁。
饥饿模式:直接分配给第一个唤醒的,新进来的不会去抢直接排在队列末尾。
当一个G等待超过1ms或者只剩下一个g会切换到饥饿模式。
12:waitGroup实现原理?
维护了2个计数器,一个请求计数器一个等待计数器。wq.Add(1)请求计数器加1,wq.Done()请求计数器-1
12:三色标记原理?
参考于:Golang三色标记+混合写屏障GC模式全分析 - 知乎
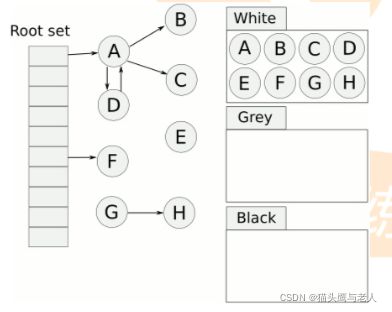
把变量放到白色盒子里,从根节点开始遍历对象,遍历到白色的变量,就放入到灰色盒子中,同时把灰色的放到黑色的盒子中。循环上一步,直到灰色中没有对象,这是白色盒子的就是不能到达黑色的不可达对象,就要被清理。
13:zookeeper在kafka中的作用,怎么保证消费顺序?
broker,topic注册,服务发现与治理,负载均衡。
使用一个partition或者指定写入到指定的一个partition。
14:kafka怎么保证消息不丢失?
生产者丢失:使用get方法获取调用结果,没有就重新发送,这样会转换成同步操作
消费者丢失:关闭自动提交offset,重复消费就要做到幂等,加锁。
15:分布式怎么设置幂等?
唯一标识:订单id
标识是否被处理:订单状态
是否处理过的逻辑:通过订单唯一索引
分布式通过MQ实现顺序处理
16:zookeeper使用场景?
1:分布式协调:比如a发送请求到MQ,B收到请求后处理。A怎么直到B处理了,用zk,A发送消息后对某个节点的值注册个监听器,一但B系统处理完了,就修改zk那个节点的值,A立马收到通知。
2:分布式锁:A执行请求先获取zk上的锁,就是可以创建一个znode(临时节点),另一个机器尝试创建znode发现已经存在,就不会执行
redis和zk的区别:redis存在读写分离,会有主从延迟,或者主从切换丢失情况,强一致性要求高的业务建议ZK,但是qps redis高于zk。
3:配置信息管理:注册中心
4:高可用:主进程挂了立马通过ZK感知切换到备份进程。
17:分布式事务?
2阶段提交,3阶段提交,本地消息,MQ,最终一致性
重试,幂等,MQ,脚本检测,超时
18:单例模式设计要点?
确保一个类只有一个实例,保存类的唯一一个静态变量静态能被所有实例共享,私有的构造函数和克隆函数。提供访问实例的公共静态方法
authload加载机制:当new一个book时,会检查是否包含这个类,不存在就调用,并把classname传过去,存在文件就自动加载,类和文件名必须一致,一个文件只有一个类。
php变量底层是一个结构体,分表记录值,引用计数,类型,和是否是引用。字符串的值是一个记录了长度和内容的结构体。
go关键字:func,break,select,case,chan,const,continue,defer,import,var,return
内置函数:make,new,append,print
19:go锁的设计和注意事项?
var m sync.Mutex
m.Lock() m.Unlock()
锁中尽量不要用I/O操作
善用defer确保释放锁
锁的两种模式
defer执行顺序,后进先出,最后输出panic
copy结构体,如果有锁需要重新初始化对象,u2.Mutex = sync.Mutex{}
defer链表不在for中使用
20:Mysql两阶段提交?
先写日志再写磁盘
先写入到redo log,更新内存
一个update语句:连接器-》分析器-》优化器-》操作引擎-》写入redo log-》prepare->写binlog->redo log 改为commit
事务异常:
commit:不用操作
binlog写完没有commit:commit
binlog没有写完:回滚
21:php读取大文件:
$handle = fopen("test.txt", "r");
if($handle){
while(($line = fgets($handle)) !== false){
//业务逻辑
}
}
22:es设计中遇到的问题?
es默认1s才会落盘,所以更新立马查询会有问题,如果需要实时,需要setRefersh(true),实时刷新
聚合后数据量大分页有问题。
max_result_window:默认10000页,超过会有问题,可以设置更大的值或者使用scroll
23:延迟队列?
zset:zrangeByscore key -inf +inf limit 0 1 withscores, hash多个key处理大key
rabbitMq:死信队列,超时的会到死信监控机,通过设置ttl和监听死信监控没机实现
TimeWheel:时间轮算法,多重时间轮,时分秒,每一个时间点都对应一个双向链表。比如现在是3s如果5s后执行,我们只要吧数据放到8s时间轮对应的链表中。
zset:zincrby key num member
zrange key start stop withscores
zcard:个数
zrangebyscore key min max withscores limit 0 10
zrank key member 返回索引
zscore key member 返回分值
24:秒杀系统实现:
两个方向:1:将请求拦截在上游,不要让锁冲突落到数据库;2:读多写少充分利用缓存;
Redis集群可以承受10万+qps
架构:客户端-》代理层-》内网服务-》数据层
1:客户端:按钮点击置灰。限制1S只能请求一次,这样可以最大限度减少重复请求
2:代理层:根据用户做限制,比如一个uid限制1s请求一次,可以通过redis的锁实现,得到锁才能继续请求。可以设置几s内的请求都返回同样的缓存界面,提升用户体验。
3:内网服务层:可以使用队列,kafka,或者拿到redis的库存再进行下一步操作,保证只有库存数量的请求到达数据层。或者业务上分段秒杀,适当缓冲
4:数据层:数据量只有库存大小完全可以抗住,可以使用读写分离,分库分表,等进行优化。
思考:
如果真有1000W+,代理层可以通过扩充机器,如果机器不够就抛弃一部分请求,限制峰值,保证大部分是成功的,不能影响后续的服务
如果大家请求相同,也可以公用缓存,比如A搜索手机,B也同样搜索,可以考虑返回B,A生成的缓存
队列失败直接返回无库存,这时之前应该也有库存的数量得到了处理,多余的请求是无意义的,不要让用户感觉到异常。
可以在nginx做7层负载均衡,保证同一个uid打到同一台机器上
队列的话可以统一使用一个队列,或者库存/节点。每个节点一个队列,使用同样数量的库存
支付等待一定时间,未支付成功重新加回库存
缓存存在数据不一致,只能通过上面讨论的一致性,最大程度保证一致,但是最终数据库层面数据是准确的,这样业务也是可以接受的。
失败提示重试,原则是fail fast
用户层面同步,服务层面可以异步
25:分表问题?
26:go超时重试?
func main() {
ctx, cancel := context.WithTimeout(context.Background(), time.Duration(time.Second*8))
//不释放会一直等到8s才释放context,这样可以保证提前处理完就释放
defer cancel()
go func(ctx context.Context) {
fmt.Println(111)
}(ctx)
select {
case <-ctx.Done():
fmt.Println("successful")
return
case <-time.After(time.Duration(time.Second*9)):
fmt.Println("timeout")
return
}
}
func Retry(tryTimes int, sleep time.Duration, callback func() (map[string]interface{}, error)) map[string]interface{} {
for i := 1; i <= tryTimes; i++ {
ret, err := callback()
if err == nil {
return ret
}
if i == tryTimes {
panic(fmt.Sprintf("error info: %s", err.Error()))
return nil
}
time.Sleep(sleep)
}
return nil
}