疫情可视化--1.爬虫--腾讯疫情数据(各省市各个时间段)----附完整代码
疫情可视化–1.爬虫–腾讯疫情数据(各省市各个时间段)
目录
- 疫情可视化--1.爬虫--腾讯疫情数据(各省市各个时间段)
-
- 1. 分析网站
- 2. 爬虫部分(代码)
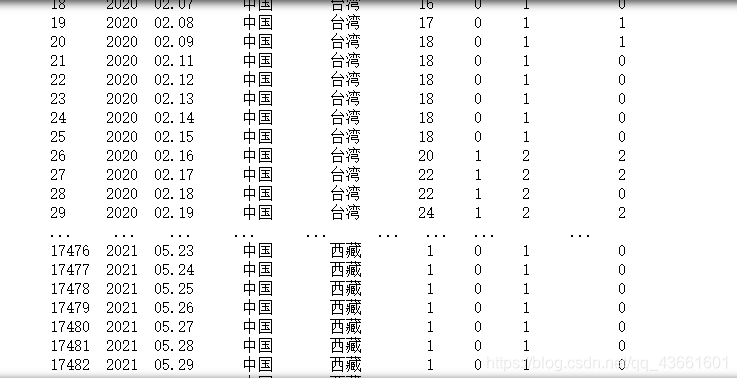
先看下结果

1. 分析网站
https://news.qq.com/zt2020/page/feiyan.htm#/

按F12进入开发界面,以广东省为例,进入广东省疫情页面后,https://news.qq.com/zt2020/page/feiyan.htm#/area?pool=gd,可以看到有这么一个文件
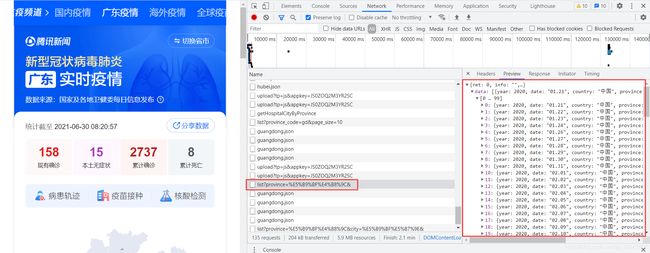
双击打开这个链接
https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=广东

发现数据是我我们想要的数据,2020.1.21至今的数据,于是可以分析出,各省的历史数据接口:
https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=各省名称
同理可以分析出各省各市的历史数据接口:
https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=省名称&city=市名称
2. 爬虫部分(代码)
目标为爬取到每个省每个市的历史疫情数据。
大致思路为,首先需要知道有多少省,分别有多少市,再分别进入网页爬取数据。
(用的是Jupyter Notebook,一边运行一边看结果)
import time
import json
import requests
from datetime import datetime
import pandas as pd
import numpy as np
def get_data():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
response = requests.get(url).json()
data = json.loads(response['data'])
return data
data = get_data()
print(data)
province = []
children =[]
index=0 # children的序号
for i in data['areaTree'][0]['children']:
# print(i['name'])
province.append(i['name'])
children.append([])
for j in i['children']:
if j['name']=='境外输入':
continue
# print(j['name'])
children[index].append(j['name'])
index+=1
# print('***************************')
# 注意建立二维列表
print(province)
print(children)
print(index)
import xlwt
# 爬取各省疫情数据
header = {
'Cookie':'RK=KzwZgVEeXg; ptcz=157737b47be19a589c1f11e7d5ea356f466d6f619b5db6525e3e4e9ea568b156; pgv_pvid=8404792176; o_cookie=1332806659; pac_uid=1_1332806659; luin=o1332806659; lskey=00010000f347903107135dfbd497aa640c9344fe129f3f881877cca68a1e46b4821572bebdf89eb35565f4e6; _qpsvr_localtk=0.24584627136079518; uin=o1332806659; skey=@twSZvHSZD; qzone_check=1332806659_1624245080',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
all_data={}
for i in province:
url = 'https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province={0}'.format(i)
# print(url)
response = requests.post(url,headers=header)
data = json.loads(response.text)['data']
all_data[i]=data
lists = []
flag=0
for pro in province:
for i in all_data[pro]:
if flag==0:
name = list(i.keys())
flag+=1
lists.append(list(i.values()))
import pandas as pd
test=pd.DataFrame(columns=name,data=lists)
print(test)
test.to_csv('./数据可视化/课设/data/province_history_data.csv',encoding='utf-8')
# 爬取各省市数据
header = {
'Cookie':'RK=KzwZgVEeXg; ptcz=157737b47be19a589c1f11e7d5ea356f466d6f619b5db6525e3e4e9ea568b156; pgv_pvid=8404792176; o_cookie=1332806659; pac_uid=1_1332806659; luin=o1332806659; lskey=00010000f347903107135dfbd497aa640c9344fe129f3f881877cca68a1e46b4821572bebdf89eb35565f4e6; _qpsvr_localtk=0.24584627136079518; uin=o1332806659; skey=@twSZvHSZD; qzone_check=1332806659_1624245080',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
all_data={}
every_province = province[1]
for i in children[1]:
url = 'https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province={0}&city={1}'.format(every_province,i)
# print(url)
response = requests.post(url,headers=header)
data = json.loads(response.text)['data']
all_data[i]=data
lists = []
flag=0
for child in children[1]:
for i in all_data[child]:
if flag==0:
name = list(i.keys())
flag+=1
lists.append(list(i.values()))
test=pd.DataFrame(columns=name,data=lists)
print(test)
# test.to_csv('./数据可视化/课设/data/' + every_province + 'province_history_data.csv',encoding='utf-8')
test = test.sort_values(['city','y','date']).reset_index(drop=True)
print(test)
# test.to_csv('D:/学习资料/数据可视化/课设/data/' + every_province + 'province_history_data11111.csv',encoding='utf-8')
# 爬取各省市数据
header = {
'Cookie':'RK=KzwZgVEeXg; ptcz=157737b47be19a589c1f11e7d5ea356f466d6f619b5db6525e3e4e9ea568b156; pgv_pvid=8404792176; o_cookie=1332806659; pac_uid=1_1332806659; luin=o1332806659; lskey=00010000f347903107135dfbd497aa640c9344fe129f3f881877cca68a1e46b4821572bebdf89eb35565f4e6; _qpsvr_localtk=0.24584627136079518; uin=o1332806659; skey=@twSZvHSZD; qzone_check=1332806659_1624245080',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
index = 0 # 控制爬取哪个省
for every_province in province:
all_data={}
for i in children[index]:
url = 'https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province={0}&city={1}'.format(every_province,i)
print(url)
response = requests.post(url,headers=header)
data = json.loads(response.text)['data']
all_data[i]=data
lists = []
flag=0
for child in children[index]:
if child == '地区待确认':
continue
print(child)
if all_data[child] is None:
continue
for i in all_data[child]:
if flag==0:
name = list(i.keys())
flag+=1
lists.append(list(i.values()))
index+=1
test=pd.DataFrame(columns=name,data=lists)
print(test.keys())
test = test.sort_values(['city','y','date'])
test = test.reset_index(drop=True)
print(test)
test.to_csv('./数据可视化/课设/data/' + every_province + 'province_history_data.csv',encoding='utf-8')