基于LiDAR的自动驾驶的位置识别:综述
文章:LiDAR-Based Place Recognition For Autonomous Driving: A Survey
作者:Yongjun Zhang, Pengcheng Shi, Jiayuan Li
编辑:点云PCL
主页:https://github.com/ShiPC-AI/LPR-Survey.git
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系[email protected]。侵权或转载请联系微信cloudpoint9527。
摘要
基于LiDAR的位置识别(LPR)在自动驾驶中扮演着关键角色,它协助同时定位与地图构建(SLAM)系统能够减少累积误差,实现可靠的定位。然而,现有的综述主要集中在视觉位置识别(VPR)方法上。尽管近年来在LPR领域取得了显著进展,但据我们所知目前还没有专门的系统性综述文章。本文通过全面回顾利用LiDAR传感器的地点识别方法来填补这一空白,从而促进和鼓励进一步的研究。我们首先深入探讨了地点识别问题的形式化,探索了现有的挑战,并描述了与以前的综述之间的关系。随后,我们对相关研究进行了深入的综述,提供了详细的分类、优势和劣势以及架构。最后,我们总结了现有的数据集、常用的评估指标,以及不同方法在公开数据集上的全面评估结果。本文可以作为进入地点识别领域的新人的有价值的教程,也适用于对长期机器人定位感兴趣的研究人员。
主要贡献
本文呈现了对LPR研究的全面综述,并在图1中呈现了详细的方法分类。我们将方法分为人工特征和基于学习的类型并进一步细分,对开创性的作品进行了详细介绍。
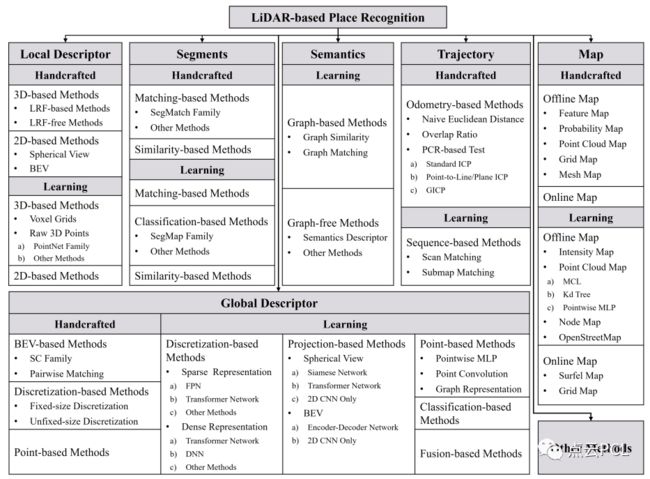
图1 位置识别方法分类
我们的主要贡献如下:
据我们所知,本文是第一篇专门关注基于3D LiDAR的位置识别的综述。我们深入探讨了问题的形式化、挑战以及与之前综述之间的关系。
我们提供了对LPR的深入概述,涵盖了传统的人工制作描述子和先进的深度学习技术。我们将现有方法分类为七个类别,并描述了它们的优势和局限性。
我们使用了大量的图表,以帮助读者了解这些方法的开源代码、骨干网络、特征类型、相似度度量、内存成本、训练策略、运行效率和定位能力。
我们总结了现有的数据集和评估指标,同时在几个公开数据集上全面比较了现有方法。此外,我们还提供了一个定期更新的github项目。
内容概述
lidar位置识别的挑战
随着图像处理技术的进步和可负担的设备的可用性,过去几十年中涌现了许多基于视觉的方法。然而,它们面临着光照变化、视点变化、恶劣天气条件和尺度模糊等挑战。相比之下,LiDAR传感器主动发射激光信号以捕获高分辨率的3D点,在低光条件下也能提供精确和详细的几何信息。此外,3D扫描技术的快速进步进一步加强了使用LiDAR传感器进行地点识别研究的兴趣。
许多最近的LPR方法已经探索了鸟瞰图(BEV),直方图,图像表示和图论等技术,以提高性能。它们通过蛮力搜索和频域分析实现旋转不变性。其他方法采用位姿邻近性,序列匹配和点云配准(PCR)技术来提高识别精度。然而,这些方法在动态和高度遮挡的环境中面临困难。传统方法依赖于低级特征(坐标,法线,强度,距离和密度),而基于学习的方法则逐渐通过神经网络,注意机制,语义和分类器显示出有希望的结果。此外,多样的地图表示,如点云,语义和网格,已成功应用于地图定位。
尽管这些方法声称取得了令人印象深刻的结果,但仍存在一些需要进一步关注的挑战:
运动失真:对于去畸变的扫描,常见的恒定速度运动假设在高速应用中不准确。
视点差异:当机器人从不同方向重新访问历史地点时,可能存在车道级水平偏差。虽然一些方法解决了旋转不变性问题,但它们仍然存在平移对位置识别的影响。
天气条件:在不同的天气条件下,激光信号会表现出不同的行为。它们在晴天减弱较少且传播更远,但在雨天和雾天会显著衰减。
感知混叠:在狭窄的走廊中,不同的地点可能会展现出类似的点云数据,从而引入了歧义的解释。
外观变化:长期导航应用通常涉及显著的环境变化,这可能导致潜在的失败。
传感器特性。机械式LiDAR以多条扫描线的格式生成点云,导致垂直稀疏。固态LiDAR提供有限的水平视场(FOV),在识别过程中需要特定的考虑。
基于局部描述子Lidar位置识别
局部描述子是对区域或点云的紧凑表示,捕捉了纹理、颜色、密度或形状等独特特征,基于局部描述子的方法通常提取关键点,并使用局部描述子来表征其周围的上下文。根据描述子的性质,它们通常分为基于3D或2D的类别。表1中包含了系统性的总结。图2描述了几种代表性的方法。
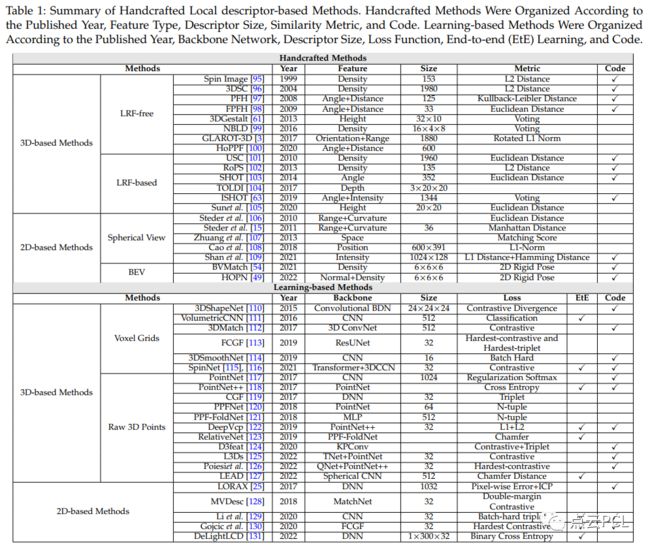
图2. 地图点的异常值剔除。(a)确定桌面平面。(b)根据点到平面的距离剔除异常值。(c)使用隔离森林算法剔除异常值。
尽管局部描述子在PCR和物体识别等任务中有广泛的应用,但它们并不是首选的地点识别方法。主要原因如下:
视点变化可能影响3D关键点的准确性,使它们不适合匹配。此外,它们可能无法有效处理数据噪声和物体遮挡。
使用3D局部描述子可能具有挑战性,因为它需要密集的点云,这在计算上是昂贵的,可能与像Velodyne VLP-16这样产生稀疏点云的传感器不太适用。
将点云转换为图像可以使用成熟的图像处理技术,但会导致几何信息的丢失,使其不适用于大规模场景。
基于全局描述子Lidar位置识别
全局描述子捕捉了场景的整体特征,提供了对数据的整体视图,而不是专注于特定区域或点,表2中包含了基于全局描述符的方法的系统总结。
人工制作的全局描述子通常使用单一描述子来描述整个点云,根据空间划分的类型,它们可以分为基于鸟瞰图(BEV)、基于离散化和基于点的方法。图3展示了三种典型的方法。

图3:人工制作的全局描述子示例。
BEV基于方法:BEV投影因其通过降维提高算法效率的能力,在机器人领域引起了极大关注,这使得它非常适用于实时应用。Scan Context(SC)家族和成对匹配是两种主流方法。
基于离散化的方法:离散化处理将点云转化为3D离散表示,分为基于固定大小和基于非固定大小的方法。
基于点的方法 :一些方法将地点识别视为一个直方图匹配问题,编码角度和高度信息。
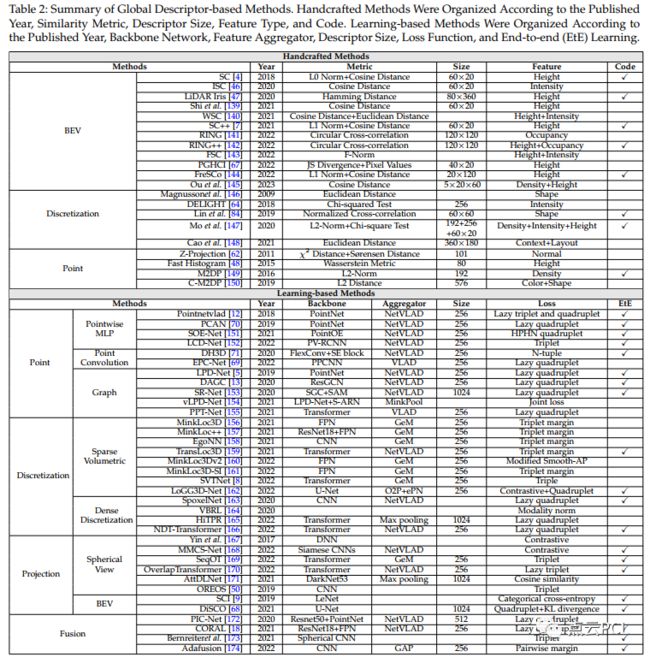
基于学习方法 :用于获取全局描述子的学习方法,根据网络架构和模型机制将其分为五组:基于点、基于离散化、基于分类、基于投影和基于融合的方法。
基于点的方法:一种普遍的方法是直接利用激光雷达点云处理中的固有3D空间信息,涉及点级MLP、点卷积和图表示,如图4所示。
图4:基于点的方法示意图
目前,全局描述子是最受欢迎的位置识别方法,能够提供关于整个场景的信息,不受局部变化的影响。在3D计算机视觉领域深度学习的进展为LPR中的数据驱动方法铺平了道路。以下是一些总结:
• BEV 在平坦结构环境中展现出卓越的性能,但存在三个主要限制:
(1)当LiDAR的z轴在全局坐标系中发生变化时,由于这些方法假设了局部平面车辆运动,可能会出现糟糕的结果。
(2)大的横向偏移可能会导致漏检环路或重新定位失败。
(3)旋转匹配只能计算偏航角,如果用作迭代最近点(ICP)的初始姿态,可能会导致潜在的局部最优问题。
• 基于离散化的方法 :可以使用强大的数学理论来描述局部表面,然而增加分辨率将会显著增加计算负担。
• 基于点的方法是最基本的全局描述子方法。然而,它们需要昂贵的邻居搜索来建立拓扑关系。此外,投影操作可能会导致信息丢失并引起潜在的误报。

图5:离散化方法示意图
• 基于学习的方法在效率和准确性方面表现出色,但严重依赖充足的训练样本和广泛的数据清理。现实世界的环境提供了额外的挑战,包括噪声、遮挡和LiDAR测量中的不确定性。因此,特定应用可能需要转移学习。
• 变换器在捕获长距离依赖关系和上下文关系方面表现出色,使其能够在杂乱环境中进行可靠的识别。然而,它们巨大的计算需求限制了用于度量学习的批大小。
• 稀疏卷积架构在生成信息丰富的局部特征方面表现出色,但在动态场景中很难区分特征大小。此外,仅仅堆叠卷积层可能会忽略长程上下文信息。
• 基于点的方法具有排列不变性,可以处理无序的点云,但缺乏对局部空间关系的明确捕捉。
基于分类的方法在训练过程中将更高的权重分配给信息丰富的特征,强调区分特征。然而,每个弱分类器对整体预测的具体贡献可能不太可解释。
• 基于投影的方法 具有较低的计算复杂性,并提供更可解释的结果,然而,它们可能会因为维度降低而导致信息丢失。

图6:投影方法示意图。
基于分割方法Lidar位置识别
分割是具有相似几何属性的有意义的区域划分。这些方法将点云分成段,图8展示了三种代表性的方法。人工方法是指这些方法通常提取用于地点识别的分割特征,可以分为基于匹配和基于相似性的方法。

图8:三种代表性的基于分段的方法示意图。
传统的点云描述子依赖于低层属性来编码点云,但是局部描述子缺乏描述能力,全局描述符在旋转和平移不变性方面存在困难。幸运的是,分段提供了两者之间的一个很好的折衷方案。以下是一些总结:
• 分割方法提供了一个潜在的解决方案,通过避免处理整个点云来减少特征计算。然而,一些方法依赖于点云聚合或地图构建,在处理大规模环境时效率低下。
• 基于分割的方法在增强准确性方面表现出潜力,它们融合了分段的几何、颜色和语义信息。然而,它们需要丰富的三维几何结构进行分割,这可能并不总是可用的,从而限制了它们的适用性。
• 基于分段的方法以其对环境变化的适应性而闻名,包括光照、天气和季节变化。然而,它们对底层三维结构的洞察力有限,因此在存在大量移动物体的长期定位场景中,分割性能不佳。
基于语义信息Lidar位置识别
语义指的是使用基于学习的分割技术将点云划分为不同实例的标签或类别,从而促进语义级别的地点识别,因此,基于语义的位置识别属于基于学习的方法范畴。根据用于语义关联的方法,它们可以分为两种类型:基于图的和无图的。
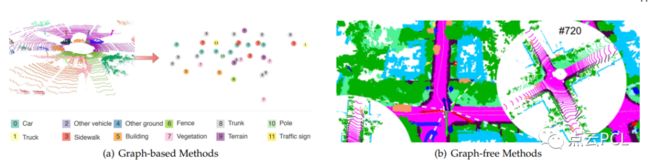
图9:基于语义的方法示意图。
受到人类感知的启发,基于语义的方法利用预定义的知识数据库来对对象进行分类,并识别它们的拓扑关系。然而,这些方法仍然相对较新且不够成熟,因为它们需要先进的语义分割技术。以下是一些关键观察总结:
• 基于图的方法提供了简化的点云理解,但存在三个限制:
(1)可能丢失特定特征,如对象大小。
(2)无法区分同一类别的不同部分,导致信息丢失。
(3)在两个图之间计算指标仍然是NP完全问题,在合理的时间范围内无法进行精确的距离计算。
• 语义标签在性能上优于仅使用几何特征,提供了更具解释性和直观性的结果。它们在遮挡和视角变化方面表现更为鲁棒,尤其是在反向激光雷达图中。然而,在测试数据集中预定义的语义标签有限,无法涵盖真实场景中的各种类别。
• 在动态或杂乱的环境中,利用对象及其拓扑信息可以提高识别准确性。这些方法在很大程度上依赖于语义分割的结果,这可能导致在各种场景中性能不佳。尽管存在这些挑战,但它们在传统方法表现不佳的应用中具有潜力。
基于轨迹信息的Lidar位置识别
轨迹信息能够将当前和最近的历史扫描进行关联,用于地点识别。里程计和序列(学习)是历史数据的两种显著使用方法。

图10:基于里程计的方法示意图。
传统的帧间比较方法可以产生直观的相似性分数,但在封闭、对称和动态环境中容易退化。基于轨迹的方法结合了空间和时间信息来解决这个限制。以下是两点观察:
LiDAR SLAM采用基于位姿相似性的简单LCD方法,然后进行PCR以计算相对变换。尽管结果令人满意,但仍存在两个限制:
(1)累积误差影响了大规模场景中里程计位姿的可靠性。
(2)PCR的局部优化阻碍了将回环约束集成到全局优化中。
基于序列的方法具有多功能性,因为它们有效地整合了各种地点识别技术,如局部和全局描述子,语义和分割。尽管视觉序列方法已经得到广泛研究,但LiDAR为基础的方法仍处于早期阶段。此外,匹配和特征融合所需的昂贵计算限制了它们的实际应用。
基于地图辅助的Lidar位置识别
地图辅助方法提供全局度量定位以实现地点识别,它们通常根据地图构建的时机分为两组:离线地图和在线地图。图12展示了一些代表性的地图。

图12:四种地图类型的示意图。其中(a)-(d)、(f)和(h)是离线地图,而(e)和(g)是在线地图。
地图在机器人定位和路径规划中被广泛使用,因为它们提供了精确且详细的环境表示。值得注意的是,基于地图的方法在识别拓扑相似的定位、提供姿态信息以及有效地恢复被劫持的机器人方面表现出色。以下是几点总结:
• 地图表示增强了全局一致性并减少了定位误差。然而,它们巨大的内存需求导致了耗时的加载、通信和处理。
• 基于地图的方法可以克服噪声和局部遮挡,确保在具有挑战性的场景中实现稳健的识别。然而,显著的密度差异导致了在线扫描到地图的注册困难。
• 健壮的先前地图有助于在一致的环境中进行长期机器人定位。然而,显著的环境变化可能导致现有地图过时,从而产生定位和识别误差。
数据集
已经收集了大量的数据集用于评估LPR方法的性能。表3提供了这些数据集的摘要。

评估结果
为了帮助研究人员了解每种方法的性能,我们广泛收集了公共数据集上的实验评估。如表4所总结的,我们收集了发布年份、方法类型、代码、结果来源、最大F1分数、EP以及在KITTI Odometry 上的运行时间。

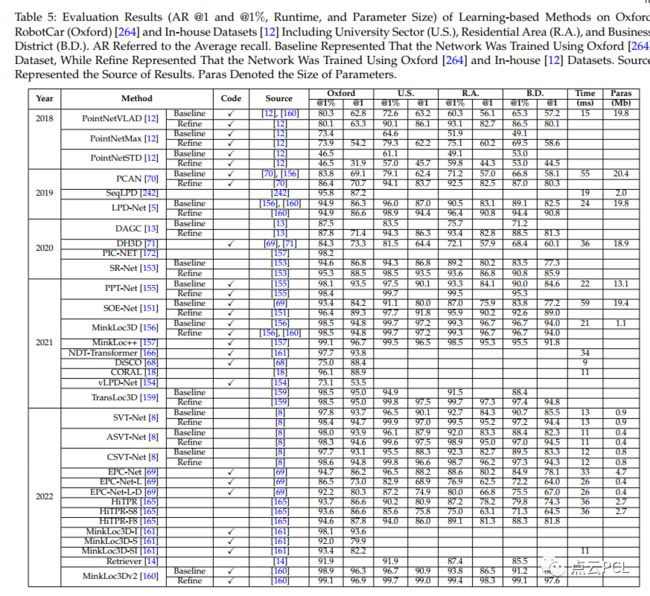
表5主要总结了发布年份、代码、结果来源、平均召回率(AR)、运行时间以及牛津和内部数据集上学习方法的参数大小。
总结
据我们所知,这篇论文是专门致力于LPR研究的第一篇全面综述。它在背景介绍部分进行了广泛的讨论,突显了当前研究中的主要关切。我们进行了全面的方法分类和性能比较,阐述了它们的架构、优势和劣势。此外,我们还总结了常用的数据集、评估指标以及有前景的未来研究方向。
资源
自动驾驶及定位相关分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
自动驾驶中基于光流的运动物体检测
基于语义分割的相机外参标定
综述:用于自动驾驶的全景鱼眼相机的理论模型和感知介绍
高速场景下自动驾驶车辆定位方法综述
Patchwork++:基于点云的快速、稳健的地面分割方法
PaGO-LOAM:基于地面优化的激光雷达里程计
多模态路沿检测与滤波方法
多个激光雷达同时校准、定位和建图的框架
动态的城市环境中杆状物的提取建图与长期定位
非重复型扫描激光雷达的运动畸变矫正
快速紧耦合的稀疏直接雷达-惯性-视觉里程计
基于相机和低分辨率激光雷达的三维车辆检测
用于三维点云语义分割的标注工具和城市数据集
ROS2入门之基本介绍
固态激光雷达和相机系统的自动标定
激光雷达+GPS+IMU+轮速计的传感器融合定位方案
基于稀疏语义视觉特征的道路场景的建图与定位
自动驾驶中基于激光雷达的车辆道路和人行道实时检测(代码开源)
用于三维点云语义分割的标注工具和城市数据集
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
TOF相机原理介绍
TOF飞行时间深度相机介绍
结构化PLP-SLAM:单目、RGB-D和双目相机使用点线面的高效稀疏建图与定位方案
开源又优化的F-LOAM方案:基于优化的SC-F-LOAM
【开源方案共享】ORB-SLAM3开源啦!
【论文速读】AVP-SLAM:自动泊车系统中的语义SLAM
【点云论文速读】StructSLAM:结构化线特征SLAM
SLAM和AR综述
常用的3D深度相机
AR设备单目视觉惯导SLAM算法综述与评价
SLAM综述(4)激光与视觉融合SLAM
Kimera实时重建的语义SLAM系统
SLAM综述(3)-视觉与惯导,视觉与深度学习SLAM
易扩展的SLAM框架-OpenVSLAM
高翔:非结构化道路激光SLAM中的挑战
基于鱼眼相机的SLAM方法介绍
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除

扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作方式:微信“cloudpoint9527”(备注:姓名+学校/公司+研究方向) 联系邮箱:[email protected]。
为分享的伙伴们点赞吧!
