python 时间处理datetime
python datetime 时间处理
数据分析过程中经常会处理一些时间序列,需要进行一些时间格式的转换,或者提取一些时间信息
pandas 处理 datetime
csv数据中某一列为日期
使用 parse_dates 参数
在读取的过程中,直接将存储时间的列读取为 datetime 格式,并将其设置为行index
import pandas as pd
from datetime import datetime
# 读取数据,在csv数据中,第四列为日期
ndvi_data = pd.read_csv('数据.csv',index_col = 3,parse_dates =True)
ndvi_data.head()
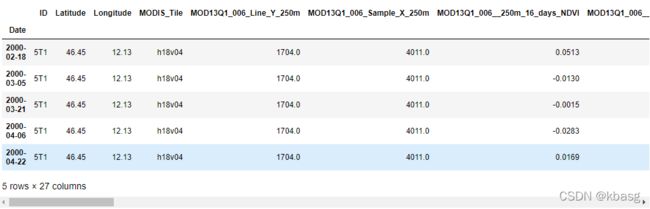
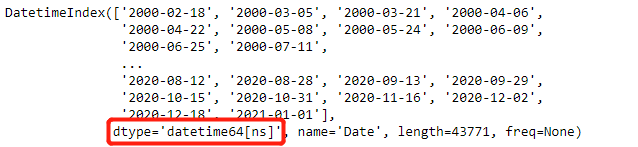
ndvi_data.index
使用 to_datetime() 函数
直接读取数据,然后再转换格式
ndvi_data = pd.read_csv('数据.csv')
ndvi_data.head()

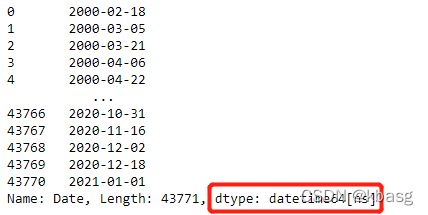
ndvi_data.Date

此时Date列的格式并不是 datetime
ndvi_data.loc[:,'Date'] = pd.to_datetime(ndvi_data.Date)
使用to_datetime 函数将其转换为 datetime格式
根据日期对数据进行处理
进行 resample()
将日期作为索引后,可以使用resample对数据进行计算处理,如求均值,求和等
首先,在使用 to_datetime() 函数 将日期列转为 datetime格式后,可以使用 set_index 方法将该列设置为 index
ndvi_data = ndvi_data.set_index('Date')

之后,可以按照不同的时间频率进行resample操作
## 按月对数据求均值
ndvi_data.resample('M').mean()
pandas 提供了多种多样的时间频率,具体见 link
分组操作:groupby()
还可以按找某些时间参数 对数据进行分组,并完成一些计算和统计
为了直观一些,可以首先从日期时间中提取 年,月,日等信息,并写成新的列
- 当datetime 作为index时
## 新增一列 年份
ndvi_data['year'] = ndvi_data.index.year
ndvi_data

- 当 datetime 为一列时,可以使用 lambda
ndvi['year'] = ndvi['date'].apply(lambda x:x.year)
- 出了常见的年月日外,有时需要从 datetime中提取 doy (day of year), 可以使用 datetime中的 timetuple() 方法
## tm_yday 为 doy
ndvi['doy'] = ndvi['date'].apply(lambda x:x.timetuple().tm_yday)
timetuple() 方法可以得到 datetime 中的各种 时间成分

在得到这些时间信息的列之后,可以使用groupby 进行一些统计和计算
例如,计算每个样点每一年,每一列数据的均值
ndvi_data.groupby(['ID','year']).mean()

分组-处理-组合 split-apply-combine 是使用pandas分析数据时最常用的操作组合,更多内容见 pandas link