轻量自高斯注意力(LSGA)机制
light(轻量)Self-Gaussian-Attention vision transformer(高斯自注意力视觉transformer) for hyperspectral image classification(高光谱图像分类)
论文:Light Self-Gaussian-Attention Vision Transformer for Hyperspectral Image Classification
代码:GitHub - machao132/LSGA-VIT
一、摘要
研究现状:近年来,卷积神经网络(convolutional neural networks,CNNs)由于其在局部特征提取方面的优异性能,在高光谱图像分类中得到了广泛的应用。然而,由于卷积核的局部连接和权值共享特性,cnn在长距离关系建模(远程依赖关系)方面存在局限性,而更深层次的网络往往会增加计算成本。
主要工作:针对这些问题,本文提出了一种基于轻量自高斯注意(light self-gauss-attention, LSGA)机制的视觉转换器(vision Transformer, VIT),提取全局深度语义特征。
1. 首先,空间-光谱混合标记器模块提取浅层空间-光谱特征,扩展图像小块生成标记。
2. 其次,轻自注意使用Q(查询)、X(原点输入),而不是Q、K(键)和V(值)来减少计算量和参数。
3. 此外,为了避免位置信息的缺乏导致中心特征和邻域特征混叠,我们设计了高斯绝对位置偏差来模拟HSI数据分布,使关注权值更接近中心查询块。
研究成果:多个实验验证了该方法的有效性,在4个数据集上的性能优于目前最先进的方法。具体来说,我们观察到A2S2K的准确率提高了0.62%,SSFTT 的准确率提高了 0.11%。综上所述,LSGA-VIT方法在HSI 分类中具有良好的应用前景,在解决位置感知远程建模和计算成本等问题上具有一定的潜力。
二、创新点
1) 作者使用混合空间-频谱标记器来代替patch嵌入,以保持输入图像patch的完整关系,并获得局部特征关系,使后续的VIT块,以实现全局特征提取。
2) LSGA-VIT模块被设计为联合收割机高斯位置信息和轻SA(LSA)机制,模拟场的中心位置和局部位置之间的关系。通过提高中心位置的谱特征权重,有效地减少了计算量和参数个数。
3) 该方法融合了全局和局部特征表达,有效地提高了HSI分类的准确率。烧蚀实验和对比实验均验证了该方法的有效性和优越性。
三、Method
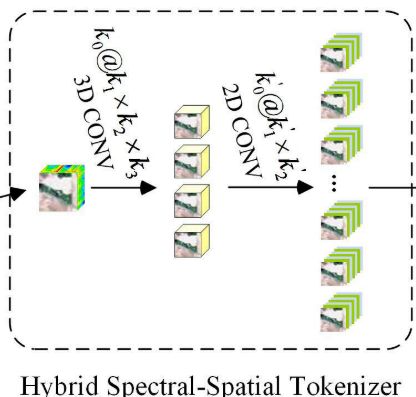
LSGA-VIT框架,主要由混合谱-空间标记器、LSGA模块(轻量自高斯注意力模块)构成,如下图。

A. Hybrid Spectral–Spatial Tokenizer(混合谱-空间标记器)
输入:高光谱图像![]() 经过PCA(主成分分析法)降维后得到的
经过PCA(主成分分析法)降维后得到的![]() ,s代表图像的bands(图像的bands也叫通道)。
,s代表图像的bands(图像的bands也叫通道)。
输入样本:再输入之前还要把图像裁剪为n个大小为h×w的样本![]() 。
。
过程:混合空间-频谱标记化模块,首先,将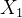 重塑为
重塑为![]() 作为卷积层的输入。再利用3-D卷积层来提取空间-频谱特征。
作为卷积层的输入。再利用3-D卷积层来提取空间-频谱特征。
第一层,3-D卷积层,从卷积到激活的定义如下:![]() 表示为在第m个卷积层的第n个特征图的像素位置
表示为在第m个卷积层的第n个特征图的像素位置![]() 的激活值。
的激活值。
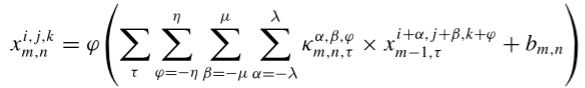
其中, 表示激活函数,
表示激活函数,![]() 是偏置参数,
是偏置参数,![]() 、
、![]() 和
和![]() 分别代表卷积核的通道数、高度和宽度,κ表示卷积核。
分别代表卷积核的通道数、高度和宽度,κ表示卷积核。![]() 为输入的3-D数据块数量,这里我们设
为输入的3-D数据块数量,这里我们设![]() = 1。 通过3-D卷积层后,合并前两个维度后,输出大小为
= 1。 通过3-D卷积层后,合并前两个维度后,输出大小为![]() ,再输入到2-D卷积层中。
,再输入到2-D卷积层中。
第二层,2-D卷积层,从卷积到激活的定义如下:
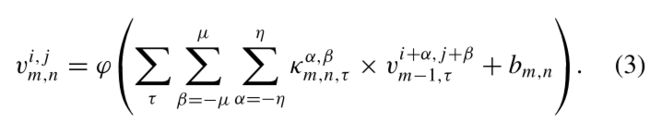
通过2-D卷积层后,输出空间的大小还原为原大小,输出大小为![]() 。其中,其中 c′ 为线性投影输出通道数和patch嵌入维数。
。其中,其中 c′ 为线性投影输出通道数和patch嵌入维数。
最后,将后两个维度展平并转置,获得![]() ,其中
,其中 ![]() (
( 由t个token向量组成)。将向量长度为 c' 的 t 个token输入到LSGA Transformer模块。
由t个token向量组成)。将向量长度为 c' 的 t 个token输入到LSGA Transformer模块。
Q:线性投影输出通道数?
接下来的LSGA模块中,包含线性的残差连接,也就是说输入、输出通道数是一致的,所以c′ 也可以说是接下来线性投影输出通道数。
Q:patch嵌入维数是什么?
transformer的patch embedding(嵌入)是指在模型中将图像分成固定大小的patchs,并通过线性变换得到每个patch的embedding(经过嵌入层的维度),嵌入维数也就是这个embedding的维度。
Q:token的作用?
将每个像素的直接展开作为token可以保持图像上每个点的空间相关性。
B. Light Self-Attention Mechanism(轻量的自注意机制)
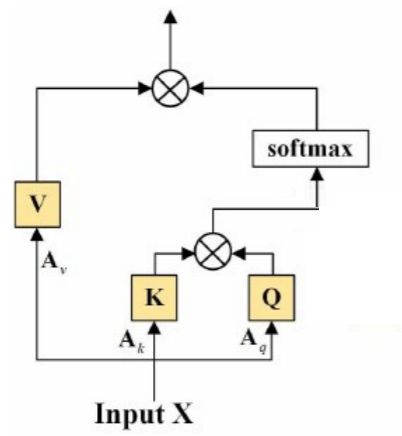
传统自注意力机制:
![]()
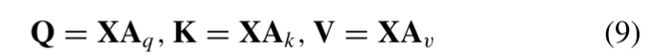
![]()
其中,![]() 是权重矩阵(没错,就是权重矩阵,
是权重矩阵(没错,就是权重矩阵,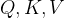 也可以通过线性层获得)。
也可以通过线性层获得)。
简化推导:
令![]() ,A是一个权重矩阵。公式10简化为:
,A是一个权重矩阵。公式10简化为:
![]()
令![]() ,则
,则

由于 和
和![]() 都是由X变换得到的,因此我们直接把
都是由X变换得到的,因此我们直接把![]() 看作,则
看作,则
![]()
-------------------------------------------(简化掉了权重矩阵
,分支头
只输入一个X,不再进行
再令 ,则
,则
![]()
根据公式9,可得
![]()
作者在注意力框架末尾多增加了一个线性层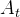 ,
,

令![]() ,则
,则
![]()
令![]() ,也就是说末尾的线性操作和分支头
,也就是说末尾的线性操作和分支头 的线性操作
的线性操作![]() 可进行合并,作者使用线性操作代替
可进行合并,作者使用线性操作代替![]() ,换句话说,线性层
,换句话说,线性层![]() 移到了框架末尾(框架末尾不属于计算式之内),因此分支头不再进行
移到了框架末尾(框架末尾不属于计算式之内),因此分支头不再进行![]() 操作,最终得到下面的定义。
操作,最终得到下面的定义。
-------------------------------------(将线性层
转移到了框架末尾,分支头
最终,将线性层![]() 移到了框架末尾,轻量的自注意机制定义如下:
移到了框架末尾,轻量的自注意机制定义如下:
![]()
总结:经过公式推导简化,简化掉了
C. Gaussian Absolute Position Bias(高斯绝对位置偏差)

目的:由于Transform模型无法捕获标记(token)的位置信息,因此有必要添加表示相对或绝对位置的模块。
方法:在多头自注意力机制中,对每个头引入相对位置偏差参数。表示如下:

其中,d是多头注意机制中每个头的维度,![]() 是相对位置偏差参数。
是相对位置偏差参数。
因为,在本文中,不是从图像patch生成token,而是每个像素作为一个token,可以保留图像的空间关系。为了计算每一个像素的空间关系,采用2-D高斯函数来表示图像的空间关系,以高斯绝对位置代替相对位置偏差,定义如下:
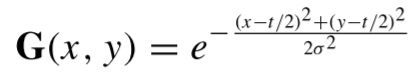

其中,σ是标准偏差,(x,y)表示空间位置坐标,G是高斯位置矩阵。
D. LSGA transformer模块总述
LSGA transformer模块,如下图所示:
在LSGA Transformer模块中,对输入特征图进行层归一化,然后对LSGA得到的![]() 进行残差连接。将上述结果归一化并通过FC,最后执行剩余连接。LSGA块的末端顺序地执行层归一化、MLP和残差连接。在执行两次LSGA块之后,通过线性层使特征图变平以用于最终分类。
进行残差连接。将上述结果归一化并通过FC,最后执行剩余连接。LSGA块的末端顺序地执行层归一化、MLP和残差连接。在执行两次LSGA块之后,通过线性层使特征图变平以用于最终分类。

四、实验
数据集:IP,Salinsa Scene(SA),Pavia University(PU)和Houston 2013(Houston)。
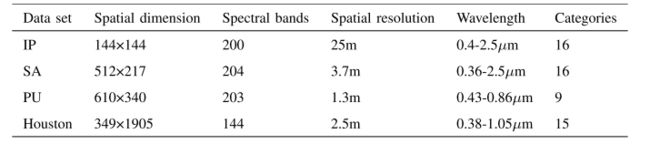
评价标准:总体准确率(OA)、平均准确率(AA)和Kappa系数(K)作为量化指标来验证LSGA-VIT的实验性能。
实验配置:所有实验都在配备有Intel Core I7- 10700 K CPU、RTX 2070 GPU和32-GB RAM的计算机上进行。本文中的所有实验训练集都设置为数据集的10%。
1. 消融实验
对比SA(自注意力)、LSA(轻量自注意力)、自高斯注意(self-Gaussian attention, SGA)和LSGA(轻量自高斯注意力)
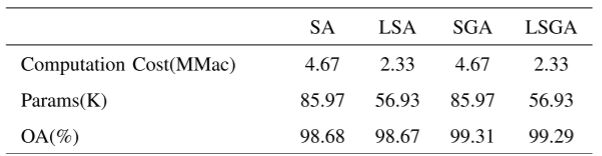
可以看到LSGA减少了 50%的计算量,减少了 30%的参数,仅损失了 0.02%的OA。
2. 对比实验

实验数据表明,该算法在4个数据集上均取得了较好的分类精度,尤其是在3个数据集上取得了最优的OA。
五、总结
1. 通过混合谱-空间标记器获得X(t个token向量),以保持图像上每个点的空间相关性,再传入LSGA模块融合注意力。
2. LSGA模块(轻量自高斯注意力模块)首先经过公式推导去除了分支头K,V中的线性操作![]() 、
、![]() 。(没错这里是线性,作者采用线性变换而不是卷积来降低参数)
。(没错这里是线性,作者采用线性变换而不是卷积来降低参数)
3. 采用2-D高斯函数获取高斯绝对位置来提取像素间的空间关系。