【教学类-38-02】20230724京剧脸谱2.0——竖版(小彩图 大面具)(Python 彩图彩照转素描线描稿)
结果展示

背景需求:
前文体运用Python颜色提取功能,将“京剧脸谱”彩色图片转化为线描图案。
【教学类-38】20230724京剧脸谱1.0——横版“彩图线图等大”(Python 彩图彩照转素描线描稿)_reasonsummer的博客-CSDN博客
存在问题:
一、彩色面积大,效用低
1、彩打了一份,看着作品第一感觉就是:好浪费彩色硒鼓啊,如果35份面具都是这样打印,会损耗很多颜色,打印速度也慢。
2、左侧面具用来提示颜色,右侧线描面具供幼儿涂色。
思考:是否可以缩小彩色面具的大小,做一个小图片,给孩子一个色彩提示(把图片缩小放在竖版的左上角,线描涂色部分放大

二、面具使用,有点小
我在大7班随机抽了几个孩子,测试剪下来的线描面具。


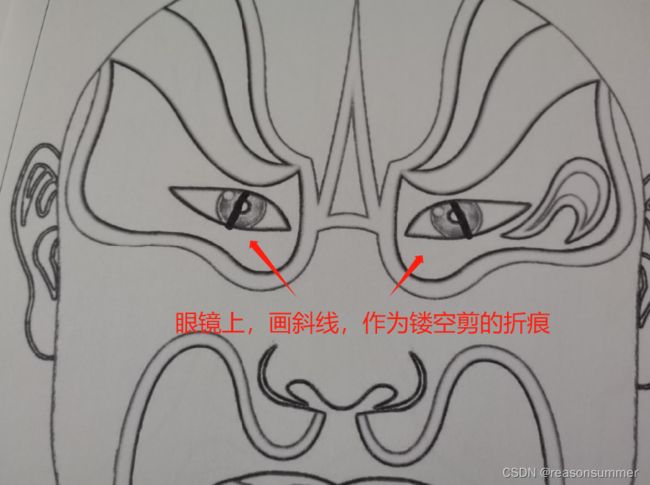
面具只比幼儿脸小一点点,但是挖空的眼睛部分,不能确保幼儿双眼都在这个镂空位置(有遮挡,看不清)
考虑到如果面具太小,幼儿涂色太快的问题(拉平集体活动中的速度差异),所以我决定换个WORD,把1:1等大的彩图和线描图,改成小彩图和大线描图。让幼儿多画一会儿,并且镂空的眼睛部分能适合幼儿的眼距。
原来:A4横版1:1图(彩图与线描图一样大)

修改:a4竖版1:20图(彩图小,线描图很大)



脸谱面具又比整个脑袋还要大,但镂空的眼镜部分非常适合大班幼儿的眼距,就打印这样的脸谱面具吧。
“小彩图大面具”的制作过程
一、素材准备

1.小彩图(含文字)

2.线描图(含文字)
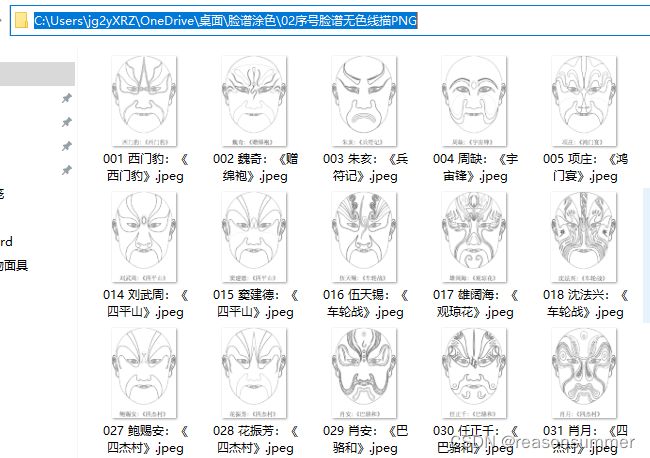
3.线描图 (切掉文字)
新建一个存放“无文字脸谱线描图片”的文件夹



4、WORD模板

重点说明:线描图是去掉下面文字的纯脸谱团(有文字,面具会压扁变形,所以去掉了文字,只保留线描脸谱)

二、代码展示
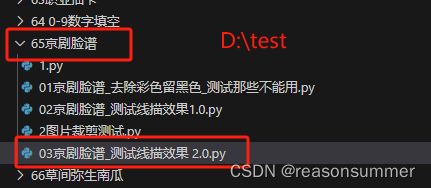
# -*- coding: utf-8 -*-
'''
目的:
1、京剧脸谱彩色和黑白对应,制作涂色学具 一共468张,
2、作者:阿夏
时间:2023年7月24日)
'''
import os
import os.path
import shutil
from PIL import Image
# num=int(input('生成多少份(28人)\n'))
# Number=4
print('----------第1步:提取所有的京剧脸谱的路径------------')
# 文件名
path0=[]
p0=r"C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\02序号脸谱无色线描PNG"
# 过滤:只保留png结尾的图片
imgs0=os.listdir(p0)
for img0 in imgs0:
if img0.endswith(".jpeg"):
path0.append(img0[4:-5])
# 所有图片的路径
# print(path1)
print(path0)
# 有颜色的 彩色脸谱
path1=[]
p1=r"C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\01序号脸谱有色彩PNG"
# 过滤:只保留png结尾的图片
imgs1=os.listdir(p1)
for img1 in imgs1:
if img1.endswith(".jpeg"):
path1.append(p1+'\\'+img1)
# 所有图片的路径
print(path1)
print(imgs1)
# 线描大图(截取线描图上半部分)
lu=r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\03序号脸谱无色线描(脸谱部分)'
if os.path.exists(lu):
print("目录已存在")
else:
print("目录不存在,创建成功")
os.mkdir(lu)
z=[]
pr=r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\02序号脸谱无色线描PNG'
# 过滤:只保留jpeg结尾的图片
z1=[0,0,1000,1250]
imgs=os.listdir(pr)
for img in imgs:
if img.endswith(".jpeg"):
path=pr+'//'+img
img1 = Image.open(path)
region = img1.crop((0,0,1000,1250))## 0,0表示要裁剪的位置的左上角坐标,50,50表示右下角。
region.save(lu+'\\'+img)## 将裁剪下来的图片保存到 举例.pn
# 没有有颜色的 黑白脸谱
path2=[]
# 有颜色的
imgs2=os.listdir(lu)
for img2 in imgs2:
if img2.endswith(".jpeg"):
path2.append(lu+'\\'+img2)
# 所有图片的路径
print(path2)
print(imgs2)
# print('----------第2步:新建一个临时文件夹------------')
# # 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,len(path2)):
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\脸谱涂色小大测试.docx')
# # 制作列表
# for z in range(2): # 5行组合循环2次 每页两张表
# # # 23个图形随机抽取12个
# # figure=random.sample(path,Number) # 12个图片随机写入4个
# # print(figure)
# # 路径 ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_2.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\06士兵2_1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\20医生_1.png']
# # 提取名称
# title=[]
# for t in figure:
# tt=t[44:-6]
# title.append(tt)
# # 路径 ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\08特警_2.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\06士兵2_1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\脸谱涂色\\脸谱涂色png\\20医生_1.png']
# print(title)
table = doc.tables[0] # 只有一个表格
# 帖图片的单元格
# bg1=['00','01']
# for t1 in range(len(bg1)): # 02
# pp1=int(bg1[t1][0:1])
# qq1=int(bg1[t1][1:2])
# # print(p)
# k1=figure[t1]
# print(pp1,qq1,k1)#
# 写入彩色图片
run=doc.tables[0].cell(0,0).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(path1[nn]),width=Cm(4.26),height=Cm(6)) # 1.5的图片最多6个
table.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# 写入黑白图片
run=doc.tables[0].cell(1,0).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
run.add_picture('{}'.format(path2[nn]),width=Cm(19.27),height=Cm(22)) # 1.5的图片最多6个
table.cell(1,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# 写入序号和生肖名称
run=table.cell(0,1).paragraphs[0].add_run(path0[nn]) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(40) #输入字体大小默认30号 一行里(可以一页两份)
run.font.bold= True #是否加粗
run.font.color.rgb = RGBColor(0,0,0) #数字小,颜色深0-255
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(0,1).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\脸谱涂色\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/(打印合集)脸谱涂色线描稿竖版2.0(共{}份).pdf".format(len(path2)))
file_merger.close()
# doc.Close()
# # # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/脸谱涂色/零时Word') #递归删除文件夹,即:删除非空文件夹
三、终端运行
不用参数,直接运行,468张要运行很长时间
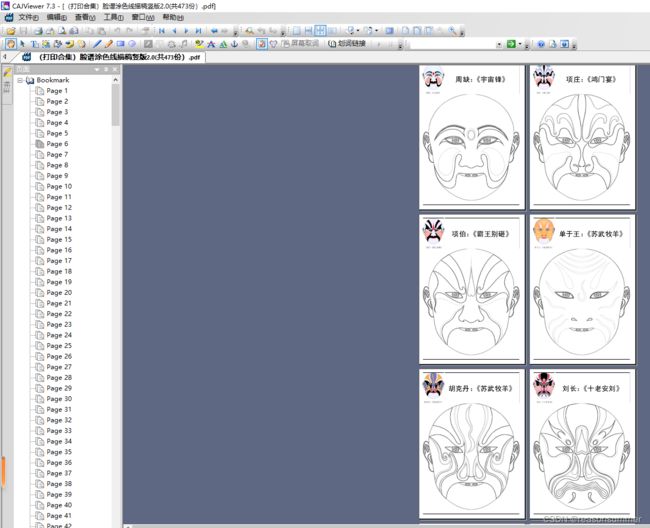

四、材料打印





目测选择一些涂色面积大的脸谱,一些细节琐碎的脸谱不能打印绘画——因为蜡笔涂色效果不如水彩笔,但幼儿园里只有人手一套的12色蜡笔。

教学过程:
时间:2023年9月20日 9:13-10:15
班级:大4
人数:28人
要求:不是随便涂色,要和左上角的彩图颜色一样。也是对称涂色

























































绘画过程中,有一组的孩子对面具人物感兴趣了,纷纷询问:
“老师,我的面具是谁?”
“那我这个是什么?”
“哈哈,我拿到齐天大圣孙悟空,我运气真好”
“我这个是龙王!”
……很多脸谱人物,我也不清楚背景,除了报一个名字和京剧名称,就鼓励孩子们
“把小彩图和文字剪下来,贴在面具反面,回去问问家长,这是谁的脸谱,是哪个故事里”。
感悟:
1、不同的造型,激发幼儿探究兴趣。
2、部分面具需要大块面涂色,幼儿涂色时间很长。所以速度不均。
3、纸条黏贴的面具依旧不牢,无法反复佩戴脱下。
END
中午一起来玩纸条吧

