spark sql操作数据
文章目录
-
-
-
- 1、创建Dataset
- 2、实现反射机制推断schema
- 3、编程方式定义Schema
- 4、spark操作mysql数据库
-
- 在windows操作
- 5、spark操作Hive数据
-
- 出现bug1无法访问/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/lib/spark-assembly-*.jar: 没有那个文件或目录
- bug2hive启动时没有反映,一直卡着
-
-
1、创建Dataset
[root@hadoop01 bin]# ./spark-shell --master local[2] --jars /export/servers/apache-hive-1.2.1-bin/lib/mysql-connector-java-5.1.46.jar

Dataset和DataFrame的互相转换
scala> spark.read.text("/spark/person.txt").as[String]
res0: org.apache.spark.sql.Dataset[String] = [value: string]
scala> spark.read.text("/spark/person.txt").as[String].toDF()
res1: org.apache.spark.sql.DataFrame = [value: string]
2、实现反射机制推断schema

创建一个maven工程,其结构如下:

pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sparkSchema</groupId>
<artifactId>sparkSchemaspace</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
2.11.8
2.7.4
2.3.2
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.spark
spark-sql_2.11
2.3.2
mysql
mysql-connector-java
5.1.46
CaseClassSchema.scala
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
//定义样例类
case class Person(id: Int, name: String, age: Int)
object CaseClassSchema {
def main(args: Array[String]): Unit = {
//1.构建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("CaseClassSchema ")
.master("local[2]")
.getOrCreate()
//2.获取SparkContext
val sc: SparkContext = spark.sparkContext
//设置日志打印级别
sc.setLogLevel("WARN")
//3.读取文件
val data: RDD[Array[String]] =
sc.textFile("/export/data/person.txt").map(x => x.split(" "))
//4.将RDD与样例类关联
val personRdd: RDD[Person] =
data.map(x => Person(x(0).toInt, x(1), x(2).toInt))
//5.获取DataFrame
//手动导入隐式转换
import spark.implicits._
val personDF: DataFrame = personRdd.toDF
//------------DSL风格操作开始-------------
//1.显示DataFrame的数据,默认显示20行
personDF.show()
//2.显示DataFrame的schema信息
personDF.printSchema()
//3.统计DataFrame中年龄大于30的人数
println(personDF.filter($"age" > 30).count())
//-----------DSL风格操作结束-------------
//-----------SQL风格操作开始-------------
//将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where name='zhangsan'").show()
//-----------SQL风格操作结束-------------
//关闭资源操作
sc.stop()
spark.stop()
}
}


3、编程方式定义Schema
SparkSqlSchema.scala
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.
{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object SparkSqlSchema {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
//2.获取sparkContext对象
val sc: SparkContext = spark.sparkContext
//设置日志打印级别
sc.setLogLevel("WARN")
//3.加载数据
val dataRDD: RDD[String] = sc.textFile("/export/data/person.txt")
//4.切分每一行
val dataArrayRDD: RDD[Array[String]] = dataRDD.map(_.split(" "))
//5.加载数据到Row对象中
val personRDD: RDD[Row] =
dataArrayRDD.map(x => Row(x(0).toInt, x(1), x(2).toInt))
//6.创建Schema
val schema: StructType = StructType(Seq(
StructField("id", IntegerType, false),
StructField("name", StringType, false),
StructField("age", IntegerType, false)
))
//7.利用personRDD与Schema创建DataFrame
val personDF: DataFrame = spark.createDataFrame(personRDD, schema)
//8.DSL操作显示DataFrame的数据结果
personDF.show()
//9.将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
//10.sql语句操作
spark.sql("select * from t_person").show()
//11.关闭资源
sc.stop()
spark.stop()
}
}

4、spark操作mysql数据库
[root@hadoop01 ~]# mysql -u root -p

表的创建、插入等操作
mysql> create database spark;
Query OK, 1 row affected (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| azkaban |
| hive |
| mysql |
| performance_schema |
| spark |
| sys |
| userdb |
+--------------------+
8 rows in set (0.00 sec)
mysql> use spark;
Database changed
mysql> create table person (id int(4),name char(20),age int(4));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into person value(1,'zhangsan',18);
Query OK, 1 row affected (0.01 sec)
mysql> insert into person value(2,'lisi',20);
Query OK, 1 row affected (0.00 sec)
mysql> select * from person;
+------+----------+------+
| id | name | age |
+------+----------+------+
| 1 | zhangsan | 18 |
| 2 | lisi | 20 |
+------+----------+------+
2 rows in set (0.01 sec)
读取mysql数据
添加mysql的驱动包,和hive所用的要一致,如果没装hive,可以任意版本。
[root@hadoop01 apache-hive-1.2.1-bin]# cd lib/
[root@hadoop01 lib]# ls

[root@hadoop01 lib]# cp mysql-connector-java-5.1.46.jar /export/servers/spark/jars/
DataFromMysql.scala
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object DataFromMysql {
def main(args: Array[String]): Unit = {
//1、创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("DataFromMysql")
.master("local[2]")
.getOrCreate()
//2、创建Properties对象,设置连接mysql的用户名和密码
val properties: Properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "Dn@123456")
//3、读取mysql中的数据
val mysqlDF: DataFrame = spark.read.jdbc("jdbc:mysql://192.168.121.134:3306/spark", "person", properties)
//4、显示mysql中表的数据
mysqlDF.show()
spark.stop()
}
}

在windows操作
首先需要可视化数据库的工具,并连接你的主机IP

其次代码在连接时注意
//3、读取mysql中的数据
val mysqlDF: DataFrame = spark.read.jdbc("jdbc:mysql://192.168.121.134:3306/spark?useUnicode=true&characterEncoding=utf8&useSSL=false", "person", properties)
需要添加所示内容,不然会运行失败

写入数据
SparkSqlToMysql.scala
import java.util.Properties
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
//创建样例类Person
case class Person(id: Int, name: String, age: Int)
object SparkSqlToMysql {
def main(args: Array[String]): Unit = {
//1.创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlToMysql")
.master("local[2]")
.getOrCreate()
//2.创建数据
val data = spark.sparkContext
.parallelize(Array("3,wangwu,22", "4,zhaoliu,26"))
//3.按MySQL列名切分数据
val arrRDD: RDD[Array[String]] = data.map(_.split(","))
//4.RDD关联Person样例类
val personRDD: RDD[Person] =
arrRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
//导入隐式转换
import spark.implicits._
//5.将RDD转换成DataFrame
val personDF: DataFrame = personRDD.toDF()
//6.设置JDBC配置参数
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "Dn@123456")
prop.setProperty("driver", "com.mysql.jdbc.Driver")
//7.写入数据
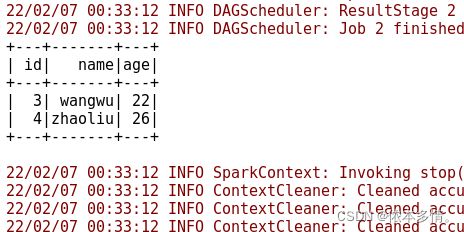
personDF.write.mode("append").jdbc(
"jdbc:mysql://192.168.121.134:3306/spark", "spark.person", prop)
personDF.show()
}
}
5、spark操作Hive数据
环境准备
先需要把mysql的驱动包复制到spark的jars目录下
[root@hadoop01 sbin]# cp /export/servers/apache-hive-1.2.1-bin/lib/mysql-connector-java-5.1.46.jar /export/servers/spark/jars/
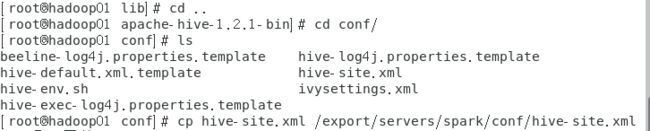
然后再把hive-site.xml复制到spark的conf目录下
[root@hadoop01 conf]# cp hive-site.xml /export/servers/spark/conf/
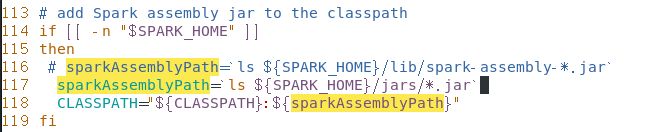
出现bug1无法访问/export/servers/spark-2.2.0-bin-2.6.0-cdh6.14.0/lib/spark-assembly-*.jar: 没有那个文件或目录

解决:

将hive内容注释116行,改其内容为117行:
bug2hive启动时没有反映,一直卡着
内容不会出来,可能是集群没有开启,需要开启Hadoop和zookeeper。

 在hive中插入数据
在hive中插入数据
hive> create database sparksqltest;
OK
Time taken: 0.797 seconds
hive> create table if not exists sparksqltest.person(id int,name string,age int);
OK
Time taken: 0.273 seconds
hive> use sparksqltest;
OK
Time taken: 0.019 seconds
hive> insert into person values(1,"tom",29);

hive> insert into person values(2,"jerry",20);

开启spark集群,进行spark-shell操作

spark sql操作hive
scala> spark.sql("use sparksqltest")
2022-02-06 23:40:29 WARN ObjectStore:568 - Failed to get database global_temp, returning NoSuchObjectException
res0: org.apache.spark.sql.DataFrame = []
scala> spark.sql("show tables").show;
+------------+---------+-----------+
| database|tableName|isTemporary|
+------------+---------+-----------+
|sparksqltest| person| false|
+------------+---------+-----------+
scala> spark.sql("use sparksqltest");
res2: org.apache.spark.sql.DataFrame = []
scala> spark.sql("show tables").show;
+------------+---------+-----------+
| database|tableName|isTemporary|
+------------+---------+-----------+
|sparksqltest| person| false|
+------------+---------+-----------+
scala> spark.sql("select * from person").show;
+---+-----+---+
| id| name|age|
+---+-----+---+
| 1| tom| 29|
| 2|jerry| 20|
+---+-----+---+
1、创建表
2、设置personRDD的Schema
3、创建Row对象,每一个Row对象都是rowRDD的一行
4、建立rowRDD与Schema对应关系,创建DataFrame
5、注册临时表
6、将数据插入Hive表
7、查询表数据
scala> import java.util.Properties
import java.util.Properties
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val personRDD = spark.sparkContext.parallelize(Array("3 zhangsan 22","4 lisi 29")).map(_.split(" "))
personRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[8] at map at <console>:28
scala> val schema =
| StructType(List(
| StructField("id",IntegerType,true),
| StructField("name",StringType,true),
| StructField("age",IntegerType,true)))
schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,IntegerType,true), StructField(name,StringType,true), StructField(age,IntegerType,true))
scala> val rowRDD = personRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).toInt))
rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[9] at map at <console>:30
scala> val personDF = spark.createDataFrame(rowRDD,schema)
personDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> personDF.registerTempTable("t_person")
warning: there was one deprecation warning; re-run with -deprecation for details
scala> spark.sql("insert into person select * from t_person")
2022-02-06 23:46:53 ERROR KeyProviderCache:87 - Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!
res6: org.apache.spark.sql.DataFrame = []
scala> spark.sql("select * from person").show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1| tom| 29|
| 2| jerry| 20|
| 3|zhangsan| 22|
| 4| lisi| 29|
+---+--------+---+