目标检测-学习笔记-目标检测的基本概念,非极大值抑制,评价指标
文章目录
- 计算机视觉主要任务
- 目标检测
-
- 目标检测-数据集
- 目标检测--概述
- 目标检测基础概念
-
- 边界框(bounding box)
- IoU
- 非极大值抑制
- 目标检测中常见指标
计算机视觉主要任务
- 图像分类(Image Classification)
用于识别图像中物体的类别,为图像赋予一个或多个语义标签,解决 what 问题。 - 目标检测(Object Detection)
引入矩形框,找到图像中多个物体的类别及所在位置,解决 what & where 问题。

- 语义分割
用于标出图像中每个像素点所属的类别,语义分割不区分实例,只考虑像素类别,属于同一类别的像素点用一个颜色标识。
确定图像中物体的类别并精确勾勒出其所在位置,解决 what & where 问题。
目标检测是标出物体的矩形框就可以了,但图像语义分割是在像素级进行识别。标出物体每个像素是属于物体还是背景等,类似于抠图。
做分割要提供像素级的标注,而做检测只要提供矩形框标注即可。当然,有像素级标注,既可以做检测也可以做分割。
- 实例分割(Instance Segmentation)
实例分割任务和语义分割类似,但如果多个同类物体存在时,要将它们一一区分出来,解决 what & where 问题。
语义分割不区分实例,只考虑像素类别。实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。
实例分割(Instance Segmentation)

目标检测
目标检测-数据集
PASCAL VOC(The PASCAL Visual Object Classification):
PASCAL VOC数据集包含20个类别,被看成目标检测问题的一个基准数据集
- VOC2007中包含 9,963 张图片,共 24,640 个物体
- VOC2012中包含 11,540 张图片,共 27,450 个物体
MS COCO( Microsoft Common Objects in Context ):
COCO数据集是Microsoft制作收集用于Detection + Segmentation + Localization + Captioning的数据集。COCO数据集共有12个大类,80个小类。
- MSCOCO2014数据集:训练集: 82783张, 验证集:40504张,共计123287张
- MSCOCO2017数据集:训练集:118287张,验证集: 5000张,共计123287张
Object365(密集标注):
2019年,旷视科技发布了通用物体检测数据集Objects365,包含63万张图像,覆盖365个类别数量,边界框高达 1000 万个。Objects365的图片数量是COCO的5倍,标注框超过COCO的11倍。
目标检测–概述
目标检测包括目标分类和目标定位 2 个任务。目标定位一般是用一个矩形的边界框来框出物体所在的位置。
目标检测难点:物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方;物体还可以是多个类别。
基于深度学习的目标检测发展历程:
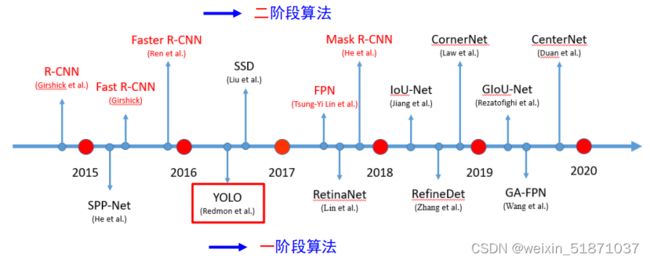
二阶段算法:
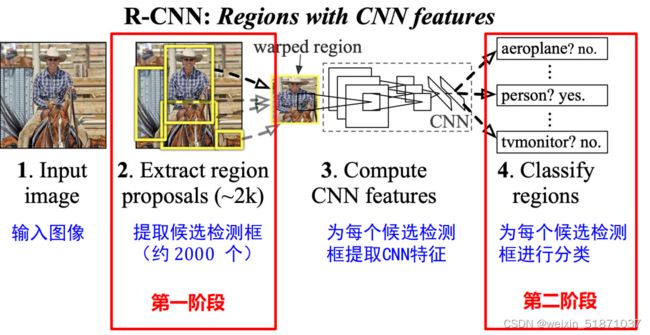
先从图像中提取若干候选框(矩形框),再逐一对候选框进行分类、甄别和调整候选框坐标。如R-CNN:
一阶段算法:
一阶段目标检测算法是不提取候选框,直接把全图输入到模型里,直接输出目标检测结果。属于end-to-end(端到端,输入原始数据,输出最后结果)系统,一步到位。直接在网络中提取特征来预测物体分类和位置。
两类目标检测算法各有利弊。二阶段算法因为先提取和筛选候选框,所以精度较高,但效率低;而一阶段算法实时性强,但精度可能不如二阶段算法。
目标检测基础概念
边界框(bounding box)
检测任务需要同时预测物体的类别和位置,因此需要引入一些跟位置相关的概念
边界框:正好能包含住物体的矩形框( ),简称
边界框的表示方法:
-
格式, [ x 1 , y 1 , x 2 , y 2 ] [x_1, y_1, x_2, y_2] [x1,y1,x2,y2],矩形框左上角 [ x 1 , y 1 ] [x_1, y_1] [x1,y1] ,右下角 [ x 2 , y 2 ] [x_2, y_2] [x2,y2]
-
ℎ 格式, [ x , y , w , h ] [x, y, w, h] [x,y,w,h],矩形框中心点 [ x , y ] [x, y] [x,y] ,矩形框宽度 , 高度 ℎ
IoU
交并比(Intersection over Union,IoU)作为衡量两个框(真实框和预测框)重合程度的指标。
计算相较比分面积:

I o U = i n t e r s e c t i o n u n i o n IoU = \frac{intersection}{union} IoU=unionintersection, i n t e r s e c t i o n intersection intersection是相交的橙色部分, u n i o n union union是两个矩形框面积之和减去相交部分,即两个矩形框的"交集"。
'''输入两个边界框的中心点和长宽,输出它们之间的IoU'''
def iou(box1, box2):
"""
计算两个边界框之间的IoU
:param box1: 边界框1,格式为 (cx1, cy1, w1, h1)
:param box2: 边界框2,格式为 (cx2, cy2, w2, h2)
:return: 两个边界框之间的IoU
"""
x1, y1, w1, h1 = box1
x2, y2, w2, h2 = box2
# 计算两个边界框的左上角和右下角坐标
x1_tl, y1_tl = x1 - w1 / 2, y1 - h1 / 2
x1_br, y1_br = x1 + w1 / 2, y1 + h1 / 2
x2_tl, y2_tl = x2 - w2 / 2, y2 - h2 / 2
x2_br, y2_br = x2 + w2 / 2, y2 + h2 / 2
# 计算两个边界框的交集面积
x_overlap = max(0, min(x1_br, x2_br) - max(x1_tl, x2_tl))
y_overlap = max(0, min(y1_br, y2_br) - max(y1_tl, y2_tl))
intersection = x_overlap * y_overlap
# 计算两个边界框的并集面积
area1, area2 = w1 * h1, w2 * h2
union = area1 + area2 - intersection
# 计算IoU
iou = intersection / union
return iou
'''输入两个边界框四个角的顶点,输出它们之间的IoU'''
def iou(box1, box2):
"""
计算两个边界框之间的IoU
:param box1: 边界框1,格式为 (x1, y1, x2, y2)
:param box2: 边界框2,格式为 (x1, y1, x2, y2)
:return: 两个边界框之间的IoU
"""
# 计算两个边界框的左上角和右下角坐标
x1_tl, y1_tl, x1_br, y1_br = box1
x2_tl, y2_tl, x2_br, y2_br = box2
# 计算两个边界框的交集面积
x_overlap = max(0, min(x1_br, x2_br) - max(x1_tl, x2_tl))
y_overlap = max(0, min(y1_br, y2_br) - max(y1_tl, y2_tl))
intersection = x_overlap * y_overlap
# 计算两个边界框的并集面积
area1, area2 = (x1_br - x1_tl) * (y1_br - y1_tl), (x2_br - x2_tl) * (y2_br - y2_tl)
union = area1 + area2 - intersection
# 计算IoU
iou = intersection / union
return iou
非极大值抑制
目标检测的过程中在同一目标的位置上会产生一些预测框,这些预测框相互之间可能会有重叠,如何消除冗余的预测框为了简化输出,可以使用非极大值抑制(non-maximum suppression,)合并属于同一目标的类似的预测边界框
非极大值抑制的工作原理
对于一个预测边界框 B ,目标检测模型会计算每个类别的预测概率(置信度)。假设最大的预测概率为 p ,则该概率所对应的类别 c1 即为预测的类别。
p称为预测边界框 预测为类别c1的概率。在同一张图像中,所有预测的非背景边界框都按对类别c1预测的概率降序排序,以生成列表 L1 。然后通过以下步骤操作排序列表L1:
- 从 L1 中选取概率最高的预测边界框 B1 作为基准,然后将所有的与 B1 的IoU 超过预定阈值θ 的非基准预测边界框从 L1 中移除(我们认为当两个边界框的IoU值超过了阈值即为重复识别了同一个物体)
- 从 L1 中选取置信度第二高的预测边界框 B2 作(不包括已经被移除的边界框)为又一个基准,然后将所有与 B2 的 IoU 大于 θ 的非基准预测边界框从 L1 中移除
- 重复上述过程,直到 L1 中的所有预测边界框都曾被用作基准。此时,没有一对边界框过于相似
- 输出列表 L1 中的所有预测边界框
- 同理对类别c2-cn的列表L2(Ln)
def nms(detections, scores, threshold):
"""
使用非极大值抑制去除重叠的检测框并保留置信度最高的框
:param detections: 检测框列表,每个检测框的格式为 (x1, y1, x2, y2)
:param scores: 对应的置信度分数列表
:param threshold: 阈值,用于控制重叠度的判定
:return: 保留的框的坐标和置信度分数
"""
# 对置信度分数进行降序排序
sorted_indices = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
# 初始化保留的框列表
keep = []
# 遍历所有检测框
while sorted_indices:
# 选出置信度最高的检测框,加入保留的框列表
max_index = sorted_indices[0]
sorted_indices = sorted_indices[1:]
keep.append(max_index)
# 计算该检测框和其余所有检测框的IoU
overlaps = []
for i in range(len(sorted_indices)):
overlap = iou(detections[max_index], detections[sorted_indices[i]])
overlaps.append(overlap)
# 根据IoU和阈值,去除与置信度最高的检测框重叠度较高的框
indices_to_remove = [i for i in range(len(overlaps)) if overlaps[i] > threshold]
sorted_indices = [i for j, i in enumerate(sorted_indices) if j not in indices_to_remove]
# 返回保留的框的坐标和置信度分数
return [detections[i] for i in keep], [scores[i] for i in keep]
detections = [(50, 50, 150, 150),(75, 75, 175, 175), (50, 50, 175, 175), (75, 75, 150, 150), (75, 75, 200, 200)]
scores = [0.9, 0.8, 0.7,0.6,0.5]
threshold = 0.5
keep_detections, keep_scores = nms(detections, scores, threshold)
for i in range(len(keep_detections)):
print("Detection", i+1, ":", keep_detections[i], "Score:", keep_scores[i])
Detection 1 : (50, 50, 150, 150) Score: 0.9
Detection 2 : (75, 75, 175, 175) Score: 0.8
值设置大好还是小好?
值设置大,可以把和基准框高重合的框去掉; 值设置小,可以把和基准框低重合的框去掉,说明 强大,有可能降低检测精度。
目标检测中常见指标
的含义
目标检测不仅需要输出目标的类别,还要定位出目标所在的位置。那么评估分类分类问题中的精确率、召回率、准确率这些简单的指标已经不能反映出目标检测中结果的准确度。
( ) 就是用来衡量目标检测算法的常用指标对于目标检测任务来说,每一个类别都可以计算出 和 ,于是每个类都可以画出一条 − 曲线,而曲线下的面积就是 的值。
(Average Precision) 的值和 − 曲线下的面积是成正比的,如果一个类别下的 越大,那么也就说明 − 曲线下的面积越大,也可以认为该类别在 、 上表现得更加好。
查准率( )和 查全率( )二者绘制的曲线称为 − 曲线

( ) :计算出所有类别的 ,再求它们的平均值(一个类别对应一个 ,目标检测往往有多个类别,所以有多个 )