BERT(Transformer Encoder)详解和TensorFlow实现(附源码)
文章目录
- 一、BERT简介
-
- 1. 模型
- 2. 训练
-
- 2.1 Masked Language Model
- 2.2 Next Sentence Prediction
- 2.3 BERT的输出
- 3. 微调
- 二、源码
-
- 1. 加载BERT模型
- 2. 加载预处理模型
- 3. 加载BERT
- 4. 构建BERT微调模型
- 5. 训练
- 6. 推理
一、BERT简介
1. 模型
BERT的全称为Bidirectional Encoder Representation from Transformers,从名字中可以看出,BERT来源于Transformer的Encoder,见如下Transformer网络结构图,其中红框部分即BERT:
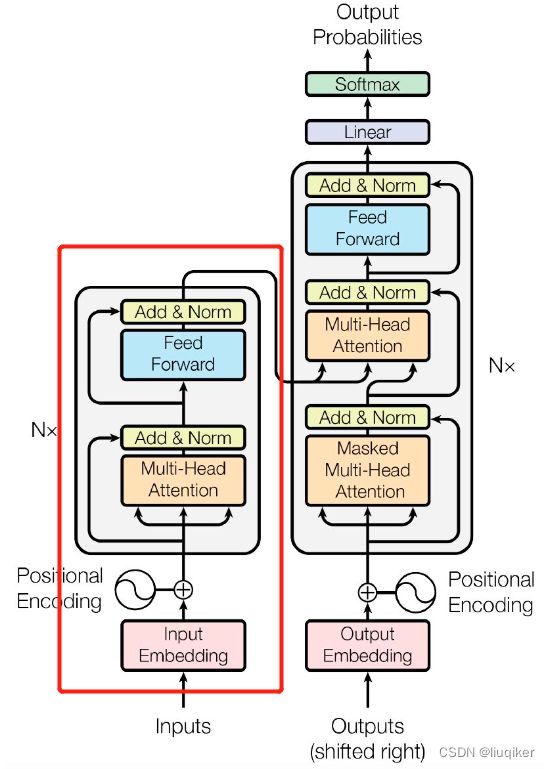
图中Encoder(BERT)和Decoder(GPT)结构相似,核心的区别在于其Attention Model的不同。BERT采用了双向注意力模型,而GPT采用的是单向注意力模型(即某个token只与该句子中位于其前方的token计算Attention),如下图:
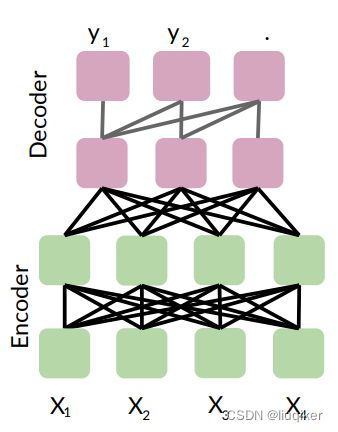
单向语言模型会限制模型的表征能力,使其只能获取单方向的上下文信息,而BERT利用双向注意力来构建整个神经网络,因此最终生成能融合左右上下文信息的深层双向语言表征,即真正意义上的Bi-Directional Context信息。这使得该模型在“完型填空”、“问答”、“情感分析”、“目标式搜索”、和“辅助性导航”等需要完整理解左右上下文信息的场景上,有着非常优秀的表现。
2. 训练
BERT使用两种预训练方法:Masked Language Model和Next Sentence Prediction,分别捕捉词语和句子级别的特征。
2.1 Masked Language Model
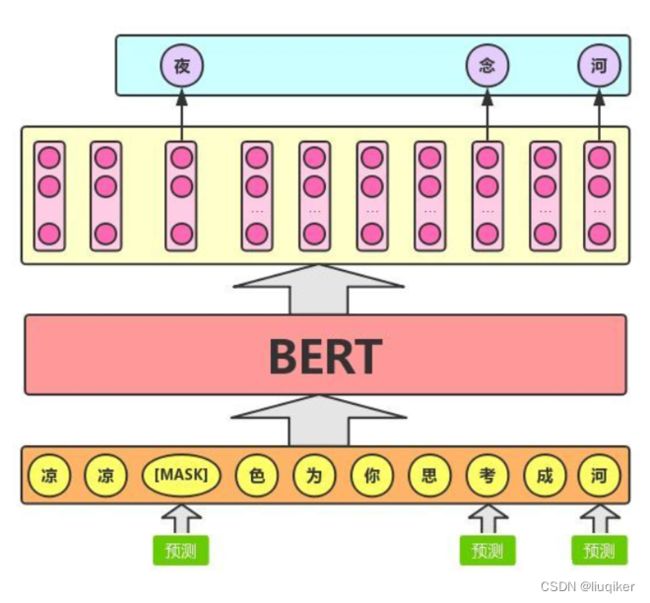
Masked Language Model称作遮蔽语言模型(简称 MLM)。MLM可以理解为完形填空,我们会随机屏蔽(mask)每一个句子中15%的词,用其上下文来预测原本的词语。
例如:my dog is hairy → my dog is [MASK],此处将hairy进行了mask处理,然后预测mask位置的词是什么。
训练过程中,我们要做如下处理:
80%的情况下采用[MASK],my dog is hairy → my dog is [MASK]
10%的情况下随机取一个词来代替[MASK]的词,my dog is hairy -> my dog is apple
10%的情况下保持不变,my dog is hairy -> my dog is hairy
这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,且预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力,训练过程如下图:
2.2 Next Sentence Prediction
Next Sentence Prediction称作下一句预测(简称 NSP),即给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示:
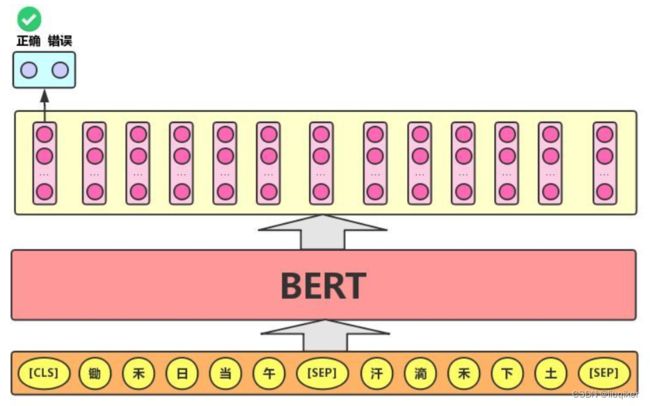
在实际的训练中,通常另训练集中的50%符合IsNext关系,另外50%的第二句话随机从语料中提取,它们的关系是NotNext,并将这个关系保存在[CLS]中。
2.3 BERT的输出
众所周知,BERT(以及GPT、Transformer)的模型特点是有多少个输入就有多少个对应的输出,如下图:
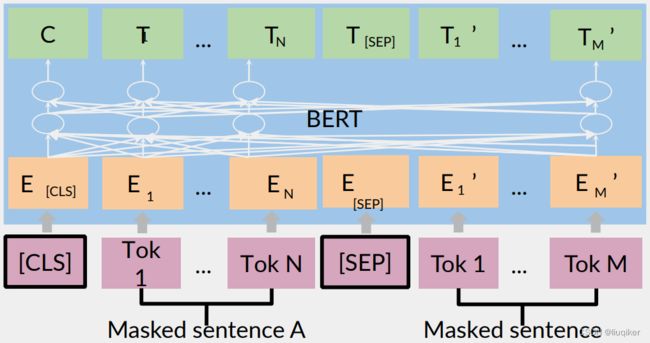
故,理解其输出具有重要的意义。图中“C”为分类token “[CLS]”对应的输出,而“T_i”
则代表其他token “Tok_i”对应的输出。
对于一些token级别的任务(如完型填空或问答任务),就把“T_i” 输入到额外的输出层中进行预测;对于一些句子级别的任务(如情感分类任务),就把“C”输入到额外的输出层中。
注:图中的“[CLS]”代表了输入句子的分类;“[SEP]”代表输入的分隔符,其前后代表两个不同的句子。
3. 微调
在海量语料训练完BERT之后,便可以将其应用到NLP的各个任务中。
对应于NSP任务来说,其条件概率表示为:

其中C是BERT输出中的[CLS]符号,W是可学习的权值矩阵。
对于其他任务来说,我们也可以根据BERT的输出信息做出相应的预测。
下图展示了BERT在11种各不同任务中的模型,它们只需要在BERT的基础上再添加一个输出层便可以完成对特定任务的微调。
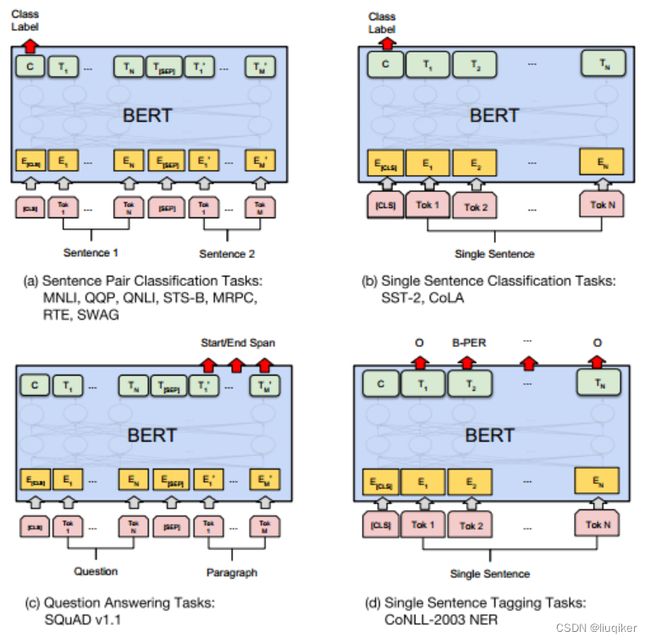
记录一篇很好的文章:https://blog.csdn.net/KK_1657654189/article/details/122204640
二、源码
下面以语义分析为例,展示BERT的模型构建、预训练参数的加载、和微调的过程。
1. 加载BERT模型
注:BERT的模型有很多个版本,其中Small BERT的参数量较小,微调耗时较小,适合新手学习使用;如果想要更高的准确率,且模型规模较小,可以选择ALBERT;如果要更高的准确率,而不关心模型规模,则可以选择classic BERT等版本。
此处以Small BERT为例:
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
}
map_model_to_preprocess = {
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
2. 加载预处理模型
用于对输入的句子进行预处理,转换成BERT能识别的格式。
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess) # 加载为Keras Model
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
3. 加载BERT
bert_model = hub.KerasLayer(tfhub_handle_encoder)
4. 构建BERT微调模型
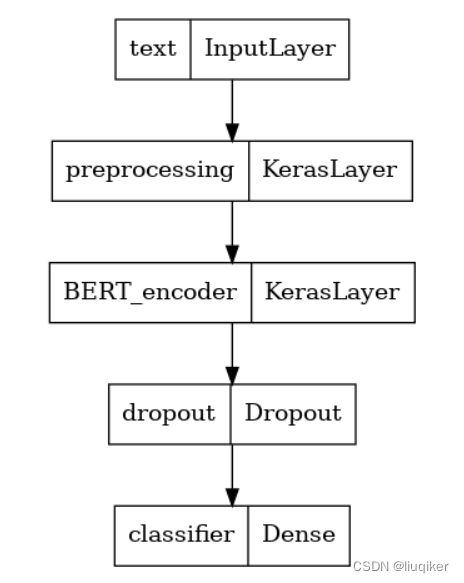
由于本例是做语义分析,如前边内容所述,需要将BERT输出内容中的[CLS]输入到Dense层中做分类处理,如下:
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net) # 此处unit个数是1,因此是二分类
return tf.keras.Model(text_input, net)
# 构建微调模型
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
构建后的微调模型如下:
5. 训练
# 定义损失函数和度量函数
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
# 定义optimizer
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
# 训练
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
6. 推理
loss, accuracy = classifier_model.evaluate(test_ds)
至此BERT训练微调的主要过程已完成。