【CVPR 2023】DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
文章目录
- 开场白
-
-
- 效果
- 意图
-
- 重点
-
-
- VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
- X-Axis DSVT Layer
- Y-Axis DSVT Layer
- Dynamic Sparse Window Attention
-
- Dynamic set partition
- Rotated set attention for intra-window feature propagation.
- Hybrid window partition for inter-window feature propagation.
- Attention-style 3D Pooling
-
- 非重点
开场白
-
先说一下为什么我会看到这篇文章,其实最开始我并没有太关注这篇,因为他算是一种架构上的设计了(类似于convnext这样)。我最开始看到到文章其实是UniTR:A Unified and Efficient Multi-Modal Transformer for Bird’s-Eye-View Representation这篇,因为当时一心说搞一搞bev的检测,看文章的时候发现有些东西看不懂往回找才看到。
-
这两篇工作其实出自一群人(当然可能略有不同,人有聚散离合么,总会有人要先走),哈哈哈好,言归正传,就是北大的作者搞了个这个东西用来处理3D voxel然后拿了CVPR 2023,然后呢他们又用这个东西去做bev 检测然后有中了 ICCV 2023,这个工作还是挺有延续性的(大家可以注意一下这个配置,在他们iccv那篇paper里面也会出现,有好装备是真不错)。
效果
*先看效果如下,速度其实还可以(27Hz)用tensor rt部署以后当然肯定还是没有pointpillars快,pointpillars在工业界用的还是比较多的,但他的精度确实高不少。

意图
我们看到效果了,然后再看一下这篇文章作者主打的是什么。
在本文中,作者试图扩大Transformer的适用性,使其能够像在2D视觉中一样,成为户外3D感知的强大backbone。这个backbone是高效的且便于部署,无需任何定制的CUDA操作。为了实现这一目标,他们提出了两个主要模块,一个是动态稀疏窗口注意力,以支持具有不同稀疏性的局部窗口的高效并行计算,另一个是一种新颖的可学习的3D池化操作,以对特征图进行下采样并更好地编码几何信息。
然后我们就知道了,主打一个高效和部署方便(从tensor rt的结果可以看出来),然后有两个模块,下面我们重点看的就是这两个模块。
重点
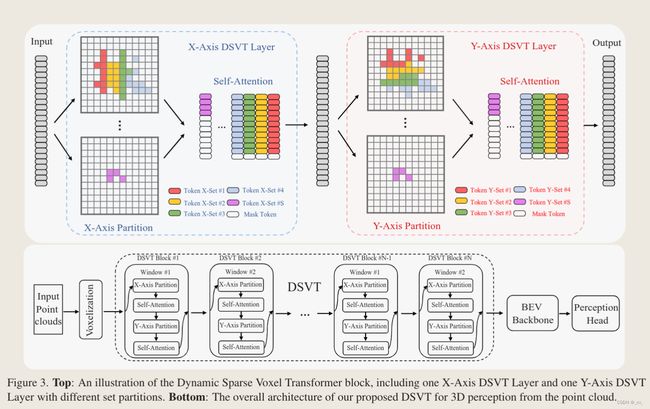
老样子先看图,如果把图看懂了就知道文章做了些什么了。
我们可以看到点云进去之后经过体素化成为稀疏体素(文章里面说用的voxel feature encoding (VFE) module,这个其实是voxelnet的做法,很简单可以去网上找,或者我先说一下也行。)
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
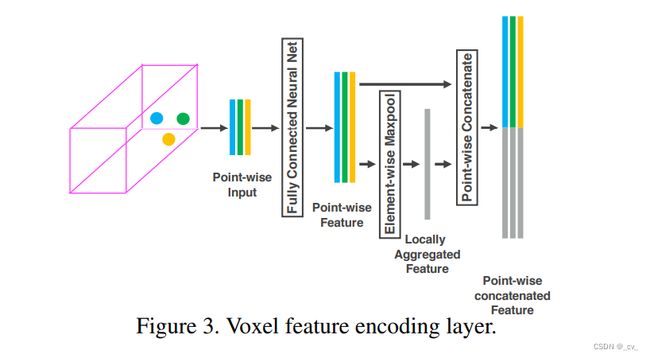
所谓voxel feature encoding (VFE) module就长上面这个样子。
- 先对每一个体素的xyz求个均值,然后把每个点从4维的xyzr变成xyzr再加上xyz对各自均值的偏移,这7维度就是point-wise input
- 然后过fc把特征拉长到一个固定的维度得到point-wise feature
- 然后把拉长的特征过maxpool拿到一个局部聚合的特征(locally aggregated feature)
- 然后把point-wise feature和locally aggregated feature直接concat到一起就得到了point-wise concatenated feature.
**好的然后我们接着上面的图来说,过了所谓VFE之后,每个点就变成了稀疏的voxel,对于这些voxel我们可以把他们视为一个一个的Token,然后这些稀疏体素会过X-Axis DSVT Layer,Self-Attention,Y-Axis DSVT Layer,Self-Attention,堆叠几个block后过bev backbone ,用预测头出结果。**整体流程就是这样
X-Axis DSVT Layer
我们再来看一下这一层做了些什么,在 X-Axis DSVT 层,稀疏体素将被分成 X-Axis 主顺序的一系列窗口有界和大小等效子集,并在每个集合中计算自注意力。在下一层,将集合分区切换到 Y-Axis,提供先前集合之间的连接。

我们可以看到稀疏体素沿着X方向,每固定数目个为一个set被分成了S个,然后送去做self-attenetion,但是我们知道自注意力操作的输入数量和维度都是固定的,数量不够的用mask token做填充。然后就该Y-Axis DSVT Layer了。
Y-Axis DSVT Layer
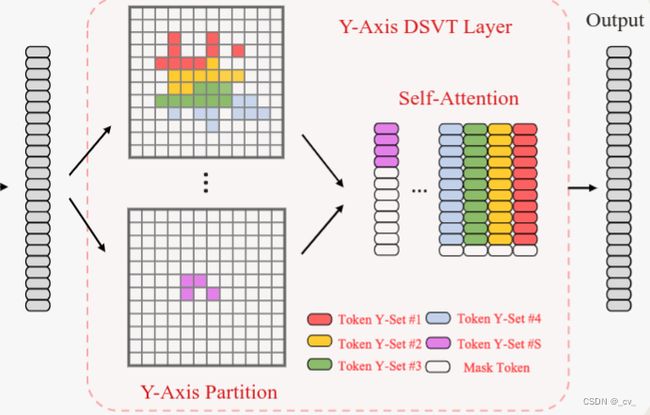
我们可以看到一样的操作,只是排序的方向换了一下,改成按Y轴进行排序了。要注意的是在流程图上,是一个一个窗口来的,在窗口内部对体素进行的划分。
其实到这里已经可以了,不过我们也可以再更加详细的按公式来看一看每个步骤具体是怎么做的。
Dynamic Sparse Window Attention
Dynamic set partition
为了在每个窗口内的给定稀疏体素之间执行标准注意,我们将其重新表述为在一系列窗口有界(window-bounded)和大小等效(size-equivalent)子集中的并行计算自我注意。具体来说,在将点转换为 3D 体素后,它们被进一步划分为大小为 L × W × H 的非重叠 3D 窗口列表。。对于特定的窗口,它有 N 个非空体素。
先上公式:
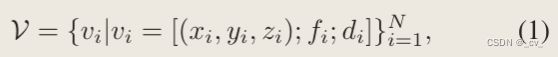
从里面看(x,y,z)是稀疏体素的坐标,,f是稀疏体素的特征(维度是c),d是inner-window voxel ID,这个id是根据排序策略生成的。
为了生成非重叠和大小相等的局部集,我们首先计算该窗口中所需的子集数量,如下所示:

where ⌊·⌋ is the floor function (向下取整操作),and I[·] is the indicator function(指示函数是定义在集合上的函数, 用来表示其中有哪些元素属于它的子集 ,就是符合后面这个操作的集和).τ是一个超参数,表示分配给每个集合的非空体素的最大数量。这个S呢就是我们一个窗口中子集的数量,是一个数字。
通过这种方式,我们可以用最少的子集覆盖该窗口中的所有体素。值得注意的是,S 随窗口的稀疏性动态变化。非空体素越多,将分配更多的集合和计算资源来处理这个窗口,这是动态稀疏窗口注意的关键设计。
然后要怎么做呢?

我们知道了分配的集和 S 的数量后将 N 个非空体素均匀分布到 S 个集合中。具体来说,对于属于第 j 个集合的体素索引,我们计算其第 k 个索引按上面来。该操作可以为每个集和生成特定数量的体。
在获得第j个集合的分区Qj之后,我们基于体素内窗id D={di}N i=1得到相应的体素特征和坐标,如下所示,

其中 INDEX(·voxels, ·partition, ·ID) 是索引操作,Fj ∈ Rτ ×C 和 Oj ∈ Rτ ×3 是该集合的相应体素特征和空间坐标 (x, y, z)。
这里可能需要给大家整理一下INDEX() 这个函数里面的V,是从公式一中来的;Qj是从公式三(和公式二)中来的,最后的D,是从公式一中的ID部分来,这下应该清楚了。
![]()
通过这种方式,我们获得了一些具有相同数量稀疏体素的非重叠和窗口有界子集。值得注意的是,我们的动态集合划分高度依赖于内窗体素ID,因此我们可以通过不同排序策略的体素ID重新排序来轻松控制每个集合的覆盖局部区域。
Rotated set attention for intra-window feature propagation.

这部分就是上面block部分的公式化表述了,也没什么好说的大家都能看懂应该。
Hybrid window partition for inter-window feature propagation.
用来swin-transformer,使用两个连续DSVT块之间的窗口移位技术来重新划分稀疏窗口,但它们的窗口大小不同。通过这种设计,可以在不牺牲性能的情况下有效地节省计算成本。也没什么好说的。
Attention-style 3D Pooling
这个操作也比较简单。给一个局部的区域,首先会对稀疏体素进行填充操作把他变成稠密的,然后沿体素的维度做标准最大池化

然后就是,最大池化过的用来做Q,没经过最大池化的稠密体素做kv.
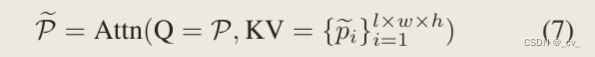
他自己说效果更好“With this attention-style 3D pooling operation, our 3D backbone holds the characteristic of fully attention and achieves better performance than our pillar variant.”
剩下的部分和实验就不是很精华了,大家可以自己看
非重点

最后呢吹一下水就是这样。“在本文中,我们提出了DSVT,这是一种部署友好但功能强大的仅用于3D感知的变压器主干。为了有效地处理稀疏点云,我们引入了动态稀疏窗口注意力,这是一种新的注意力策略,它将所有稀疏体素划分为一系列大小等效和窗口有界的子集,这些子集可以并行处理,而无需任何定制的CUDA操作。因此,我们提出的DSVT可以通过优化良好的NVIDIA TensorRT来加速,它在各种3D感知基准上以实时运行速度实现了最先进的性能。我们希望我们的DVST不仅可以成为现实世界应用中3D感知的可靠点云处理器,还可以为在其他任务中有效处理稀疏数据提供潜在的解决方案。”