文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- 文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- 1. 文章简介
- 2. 方法介绍
- 1. 整体方法说明
- 3. 实验结果
- 1. RLHF vs RLAIF
- 2. Prompt的影响
- 3. Self-Consistency
- 4. Labeler Size的影响
- 5. 标注数据的影响
- 4. 总结 & 思考
- 文章链接:https://arxiv.org/abs/2309.00267
1. 文章简介
这篇文章是Google在今年9月发表的一篇文章,顾名思义,其核心的idea就是将RLHF当中的human部分直接替换为AI,直接用LLM的Feedback来finetune模型,考察其得到的模型效果。
结论而言其得到的模型效果有了不输RLHF后的模型效果,证明了上述策略的可行性。
怎么说呢,这个结论多少有些情理之中又有些意料之外……
情理之中是在于说已经有多个实验证明了LLM在标注任务上的效果不弱于人类,甚至比人类有着更稳定的标注效果,因此用LLM来替代人类的标注有其一定的道理。
另一方面,意料之外则是因为LLM毕竟还是模型,用模型自己来finetune模型总觉得会引入bias,在其本身的训练feature没有获得增加的情况下,对于模型效果的最终提升来说总觉得有些不可靠……
不过,anyway,还是让我们言归正传,来看看文中到底是做了怎么样的实验以及得出了怎么样的结论吧。
2. 方法介绍
1. 整体方法说明
首先,我们给出RLHF与RLAIF的完整pipeline示意图如下:
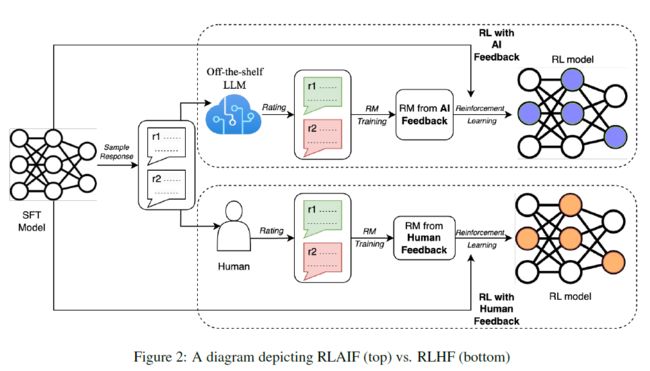
可以看到,整体来说,RLHF和RLAIF唯一的区别就是将RM模型所需的标注从人工换成了另一个LLM的自动标注结果。
下面,我们来看一下其中具体的细节实现。
对于一个标准的RLHF过程,可以拆解为以下三部分的内容:
-
Supervised finetuned Model (SFT)
-
RM model
使用人工标注结果训练一个二分类模型:
L = − E ( x , y w , y l ) ∼ D [ l o g σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ] L = -\mathop{E}\limits_{(x, y_w, y_l) \sim D} [\mathop{log}\sigma(r_{\phi}(x, y_w) - r_{\phi}(x, y_l))] L=−(x,yw,yl)∼DE[logσ(rϕ(x,yw)−rϕ(x,yl))]
-
Reinforce Learning
m a x θ E [ r ϕ ( y ∣ x ) − β D K L ( π θ R L ( y ∣ x ) ∣ ∣ π S F T ( y ∣ x ) ) ] \mathop{max}\limits{\theta} \mathop{E}[ r_{\phi} (y|x) - \beta \mathop{D}_{KL} (\pi_{\theta}^{RL}(y|x) || \pi^{SFT} (y|x))] maxθE[rϕ(y∣x)−βDKL(πθRL(y∣x)∣∣πSFT(y∣x))]
而RLAIF就是将2中的标注结果替换为人工标注的结果,其用于query大模型的prompt示例如下:

可以看到,文中使用的prompt主要包含四部分的内容:
- Preamble
- 对任务的整体介绍
- Few-Shot example
- optional,一些具体的case样例
- query
- 具体的query,在文中就是summary任务
- ending
- 回答的提示词
但是,实际在实验过程当中,文中发现LLM的回答对于summary的位置信息还是挺敏感的,也就是说当LLM对summary出现的位置具有一定的倾向性,比如说比较倾向于选择先给出的summary这样。
而另一方面,在请求模型时,为了优化模型调用的效果,文中还使用了类似CoT之类的prompt调优的方法。
下图是文中实际使用的LLM进行标注的流程示意图:
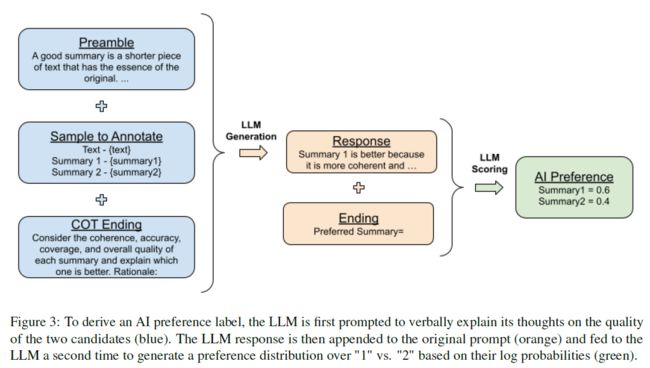
可以看到,这里主要是加入了如下一些变化:
- 引入COT方法
- 对于输出的结果,分别用两个概率来表示其preference。
- 对于每一组summary都query两次,消除其出现位置对模型输出的影响,然后将两次结果进行平均作为最终的输出;
3. 实验结果
下面,我们来看一下文中实际的实验效果。
1. RLHF vs RLAIF
首先,文中给出了人对于RLHF与RLAIF的结果的喜好程度比例如下:

可以看到:
- RLHF与RLAIF都超越了SFT模型的生成效果,但是两者相互之间却没有显著的效果差异。
下面是一个具体的生成case展示:

2. Prompt的影响
下面,我们来考察一下prompt对RLAIF效果的影响。
文中主要研究了三方面的prompt tuning的效果影响:
- preamble的准确性
- In-Context Learning
- CoT
给出文中的实验结果表格如下:
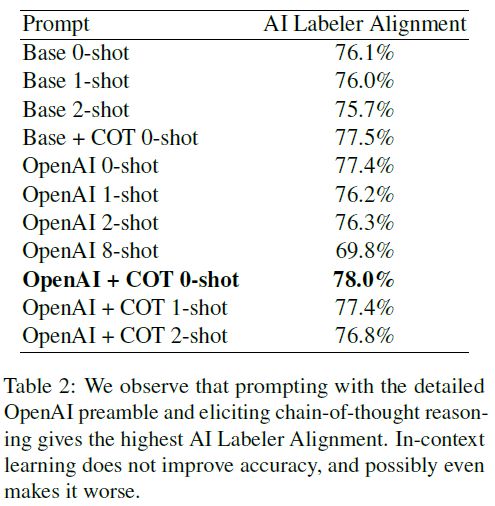
其中,AI Labeler Aligned表示标注结果与人工标注结果的一致性。
可以看到:
- Preamble对模型效果的影响最大;
- CoT同样可以给模型带来一定的效果增益;
- few-shot (in-context learning)对模型效果并没有什么增益,甚至可能会带来伤害;
3. Self-Consistency
文中还考察一了一下生成结果的self-consistency,具体来说,就是通过调整生成的随机性,然后多次生成进行average作为RM模型的训练数据,实验得到的结果如下:

可以看到:
- self-consistency的实验结果并不很好,多次sample取均值之后发现其结果反而有所下降。
文中给出一种猜测可能是由于设置随机性较高之后使得生成质量受到了影响。
4. Labeler Size的影响
文中同样考察了一下Label模型的size对标注结果的影响:

可以看到:
- 模型size越大,模型的标注效果越好。
这也是符合直觉的,毕竟模型的size越大,模型的效果越好,对应的标注效果也应该越好。
5. 标注数据的影响
最后,文中还考察了一下随着标注数据的增加,RLHF与RLAIF效果的变化。
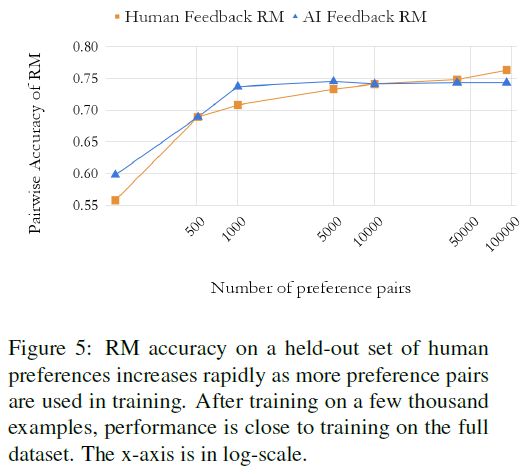
可以看到:
- RLAIF可以更快速地达到一个较好的水平上,但是随着标注数据的增加,模型效果的提升很快达到了一个瓶颈,不会随着标注数据的增加而持续提升;
- 而另一方面,RLHF的效果随着标注数据的增加提升的相对较慢,但是会有一个持续的提升趋势。
这个结果也是make sense的,毕竟RLAIF并没有额外的信息输入,只能说是更有效地利用现有训练数据对模型进行训练,因此其效果的提升总是会有一个极限的,而相对的,RLHF则是持续地给模型增加额外的输入特征,因此模型总是可以持续地进行优化的。
但是另一方面,正如文章所说,考虑到所需的数据量和标注成本,RLAIF作为一个替代方案已经足够有效和划算了。
4. 总结 & 思考
综上,我们可以看到,由于当前LLM本身拥有的强大理解能力和效果,用LLM来替换RLHF当中的人工标注部分获得的RLAIF可以获得和人工标注相类似的效果,这个和目前大量的使用LLM来进行标注的工作中的结论是一致的。
然后,同样的,由于LLM本身不会有额外的信息传入,因此虽然RLAIF能够获得超过SFT,并获得和RLHF相当的效果,其效果的上限较之RLHF依然存在一定的差距,只不过要看到相对明显的差距需要大量的标注数据,这个成本是非常可观的,因此整体上来说RLAIF是一个相当好用的RLHF的替代品。
最后,文中还考察了一下标注过程的prompt调优,发现随即因子的引入会伤害模型的表达,另外CoT和好的preamble非常的关键,但是in-context learning则不是那么重要,这个和我们平时的prompt调优的感觉也是相似的。
但尽管如此,prompt工程这方面的结论的可靠性和一致性我个人实在是觉得有点过低了,仿佛炼丹,充满了玄学色彩,感觉还是不太好控制,不知道是不是只有我一个人这么觉得……