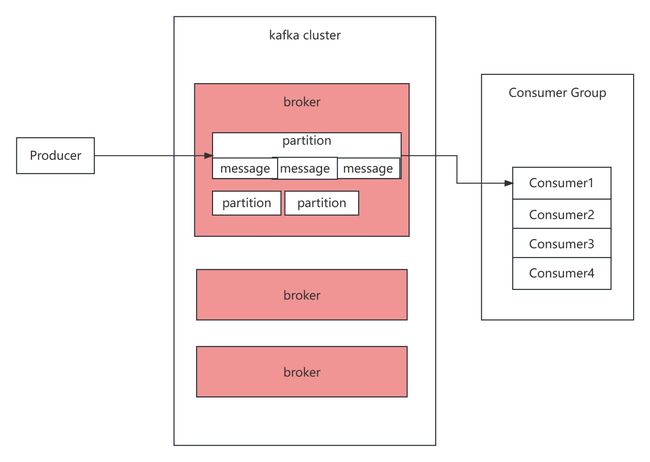
kafka客户端应用参数详解
一、基本客户端收发消息
Kafka提供了非常简单的客户端API。只需要引入一个Maven依赖即可:
org.apache.kafka
kafka_2.13
3.4.0
1、消息发送者主流程
然后可以使用Kafka提供的Producer类,快速发送消息。
public class MyProducer {
private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";
private static final String TOPIC = "disTopic";
public static void main(String[] args) throws ExecutionException, InterruptedException {
//PART1:设置发送者相关属性
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 配置key的序列化类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// 配置value的序列化类
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
CountDownLatch latch = new CountDownLatch(5);
for(int i = 0; i < 5; i++) {
//Part2:构建消息
ProducerRecord record = new ProducerRecord<>(TOPIC, Integer.toString(i), "MyProducer" + i);
//Part3:发送消息
//单向发送:不关心服务端的应答。
producer.send(record);
System.out.println("message "+i+" sended");
//同步发送:获取服务端应答消息前,会阻塞当前线程。
RecordMetadata recordMetadata = producer.send(record).get();
String topic = recordMetadata.topic();
int partition = recordMetadata.partition();
long offset = recordMetadata.offset();
String message = recordMetadata.toString();
System.out.println("message:["+ message+"] sended with topic:"+topic+"; partition:"+partition+ ";offset:"+offset);
//异步发送:消息发送后不阻塞,服务端有应答后会触发回调函数
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(null != e){
System.out.println("消息发送失败,"+e.getMessage());
e.printStackTrace();
}else{
String topic = recordMetadata.topic();
long offset = recordMetadata.offset();
String message = recordMetadata.toString();
System.out.println("message:["+ message+"] sended with topic:"+topic+";offset:"+offset);
}
latch.countDown();
}
});
}
//消息处理完才停止发送者。
latch.await();
producer.close();
}
}
整体来说,构建Producer分为三个步骤:
- 设置Producer核心属性 :Producer可选的属性都可以由ProducerConfig类管理。比如ProducerConfig.BOOTSTRAP_SERVERS_CONFIG属性,显然就是指发送者要将消息发到哪个Kafka集群上。这是每个Producer必选的属性。在ProducerConfig中,对于大部分比较重要的属性,都配置了对应的DOC属性进行描述。
- 构建消息:Kafka的消息是一个Key-Value结构的消息。其中,key和value都可以是任意对象类型。其中,key主要是用来进行Partition分区的,业务上更关心的是value。
- 使用Producer发送消息。:通常用到的就是单向发送、同步发送和异步发送者三种发送方式。
2、消息消费者主流程
接下来可以使用Kafka提供的Consumer类,快速消费消息。
public class MyConsumer {
private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";
private static final String TOPIC = "disTopic";
public static void main(String[] args) {
//PART1:设置发送者相关属性
Properties props = new Properties();
//kafka地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
//每个消费者要指定一个group
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
//key序列化类
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
//value序列化类
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
Consumer consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(TOPIC));
while (true) {
//PART2:拉取消息
// 100毫秒超时时间
ConsumerRecords records = consumer.poll(Duration.ofNanos(100));
//PART3:处理消息
for (ConsumerRecord record : records) {
System.out.println("offset = " + record.offset() + ";key = " + record.key() + "; value= " + record.value());
}
//提交offset,消息就不会重复推送。
consumer.commitSync(); //同步提交,表示必须等到offset提交完毕,再去消费下一批数据。
// consumer.commitAsync(); //异步提交,表示发送完提交offset请求后,就开始消费下一批数据了。不用等到Broker的确认。
}
}
}
整体来说,Consumer同样是分为三个步骤:
- 设置Consumer核心属性 :可选的属性都可以由ConsumerConfig类管理。在这个类中,同样对于大部分比较重要的属性,都配置了对应的DOC属性进行描述。同样BOOTSTRAP_SERVERS_CONFIG是必须设置的属性。
- 拉取消息:Kafka采用Consumer主动拉取消息的Pull模式。consumer主动从Broker上拉取一批感兴趣的消息。
- 处理消息,提交位点:消费者将消息拉取完成后,就可以交由业务自行处理对应的这一批消息了。只是消费者需要向Broker提交偏移量offset。如果不提交Offset,Broker会认为消费者端消息处理失败了,还会重复进行推送。
Kafka的客户端基本就是固定的按照这三个大的步骤运行。在具体使用过程中,最大的变数基本上就是给生产者和消费者的设定合适的属性。这些属性极大的影响了客户端程序的执行方式。
kafka官方配置:Apache Kafka
二、客户端属性详解
1、消费者分组消费机制
在Consumer中,都需要指定一个GROUP_ID_CONFIG属性,这表示当前Consumer所属的消费者组。他的描述是这样的:
public static final String GROUP_ID_CONFIG = "group.id";
// 大概意思是给消费者组指定一个唯一的string,如果消费者使用subscribe(topic)或基于kafka的偏移量管理策略来使用组管理功能,则需要此属性。
public static final String GROUP_ID_DOC = "A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either the group management functionality by using subscribe(topic) or the Kafka-based offset management strategy.";既然有基于kafka管理的offset,也有消费者端缓存的offset
查看消费者组offset消费者进度
./kafka-consumer-groups.sh --bootstrap-server worker1:9092 --describe --group test ![]()
2、生产者拦截器机制
生产者拦截机制允许客户端在生产者在消息发送到Kafka集群之前,对消息进行拦截,甚至可以修改消息内容。
这涉及到Producer中指定的一个参数:INTERCEPTOR_CLASSES_CONFIG
public static final String INTERCEPTOR_CLASSES_CONFIG = "interceptor.classes";
public static final String INTERCEPTOR_CLASSES_DOC = "A list of classes to use as interceptors. "
+ "Implementing the org.apache.kafka.clients.producer.ProducerInterceptor interface allows you to intercept (and possibly mutate) the records "
+ "received by the producer before they are published to the Kafka cluster. By default, there are no interceptors.";
于是,按照他的说明,我们可以定义一个自己的拦截器实现类:
public class MyInterceptor implements ProducerInterceptor {
//发送消息时触发
@Override
public ProducerRecord onSend(ProducerRecord producerRecord) {
System.out.println("prudocerRecord : " + producerRecord.toString());
return producerRecord;
}
//收到服务端响应时触发
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
System.out.println("acknowledgement recordMetadata:"+recordMetadata.toString());
}
//连接关闭时触发
@Override
public void close() {
System.out.println("producer closed");
}
//整理配置项
@Override
public void configure(Map map) {
System.out.println("=====config start======");
for (Map.Entry entry : map.entrySet()) {
System.out.println("entry.key:"+entry.getKey()+" === entry.value: "+entry.getValue());
}
System.out.println("=====config end======");
}
}
然后在生产者中指定拦截器类(多个拦截器类,用逗号隔开)
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,"com.roy.kfk.basic.MyInterceptor");
拦截器机制一般用得比较少,主要用在一些统一添加时间等类似的业务场景。比如,用Kafka传递一些POJO,就可以用拦截器统一添加时间属性。但是我们平常用Kafka传递的都是String类型的消息,POJO类型的消息,Kafka可以传吗?这就要用到下面的消息序列化机制。
3、消息序列化机制
在之前的简单示例中,Producer指定了两个属性KEY_SERIALIZER_CLASS_CONFIG和VALUE_SERIALIZER_CLASS_CONFIG,对于这两个属性,在ProducerConfig中都有配套的说明属性。
public static final String KEY_SERIALIZER_CLASS_CONFIG = "key.serializer";
public static final String KEY_SERIALIZER_CLASS_DOC = "Serializer class for key that implements the org.apache.kafka.common.serialization.Serializer interface.";
public static final String VALUE_SERIALIZER_CLASS_CONFIG = "value.serializer";
public static final String VALUE_SERIALIZER_CLASS_DOC = "Serializer class for value that implements the org.apache.kafka.common.serialization.Serializer interface.";
通过这两个参数,可以指定消息生产者如何将消息的key和value序列化成二进制数据。在Kafka的消息定义中,key和value的作用是不同的。
- key是用来进行分区的可选项。Kafka通过key来判断消息要分发到哪个Partition。
如果没有填写key,那么Kafka会使Round-robin轮询的方式,自动选择Partition。
如果填写了key,那么会通过声明的Serializer序列化接口,将key转换成一个byte[]数组,然后对key进行hash,选择Partition。这样可以保证key相同的消息会分配到相同的Partition中。
- Value是业务上比较关心的消息。Kafka同样需要将Value对象通过Serializer序列化接口,将Key转换成byte[]数组,这样才能比较好的在网络上传输Value信息,以及将Value信息落盘到操作系统的文件当中。
生产者要对消息进行序列化,那么消费者拉取消息时,自然需要进行反序列化。所以,在Consumer中,也有反序列化的两个配置
public static final String KEY_DESERIALIZER_CLASS_CONFIG = "key.deserializer";
public static final String KEY_DESERIALIZER_CLASS_DOC = "Deserializer class for key that implements the org.apache.kafka.common.serialization.Deserializer interface.";
public static final String VALUE_DESERIALIZER_CLASS_CONFIG = "value.deserializer";
public static final String VALUE_DESERIALIZER_CLASS_DOC = "Deserializer class for value that implements the org.apache.kafka.common.serialization.Deserializer interface.";
在Kafka中,对于常用的一些基础数据类型,都已经提供了对应的实现类。但是,如果需要使用一些自定义的消息格式,比如自己定制的POJO,就需要定制具体的实现类了。
4、消息分区路由机制
了解前面两个机制后,你自然会想到一个问题。就是消息如何进行路由?也即是两个相关联的问题。
- Producer会根据消息的key选择Partition,具体如何通过key找Partition呢?
- 一个消费者组会共同消费一个Topic下的多个Partition中的同一套消息副本,那Consumer节点是不是可以决定自己消费哪些Partition的消息呢?
这两个问题其实都不难,你只要在几个Config类中稍微找一找就能找到答案。
首先,在Producer中,可以指定一个Partitioner来对消息进行分配。
public static final String PARTITIONER_CLASS_CONFIG = "partitioner.class";
private static final String PARTITIONER_CLASS_DOC = "A class to use to determine which partition to be send to when produce the records. Available options are:" +
"" +
"- If not set, the default partitioning logic is used. " +
"This strategy will try sticking to a partition until at least " + BATCH_SIZE_CONFIG + " bytes is produced to the partition. It works with the strategy:" +
"
" +
"- If no partition is specified but a key is present, choose a partition based on a hash of the key
" +
"- If no partition or key is present, choose the sticky partition that changes when at least " + BATCH_SIZE_CONFIG + " bytes are produced to the partition.
" +
"
" +
" " +
"org.apache.kafka.clients.producer.RoundRobinPartitioner: This partitioning strategy is that " +
"each record in a series of consecutive records will be sent to a different partition(no matter if the 'key' is provided or not), " +
"until we run out of partitions and start over again. Note: There's a known issue that will cause uneven distribution when new batch is created. " +
"Please check KAFKA-9965 for more detail." +
"
" +
"Implementing the org.apache.kafka.clients.producer.Partitioner interface allows you to plug in a custom partitioner.";
这里就说明了Kafka是通过一个Partitioner接口的具体实现来决定一个消息如何根据Key分配到对应的Partition上的。你甚至可以很简单的实现一个自己的分配策略。
5、生产者消息缓存机制
Kafka生产者为了避免高并发请求对服务端造成过大压力,每次发消息时并不是一条一条发往服务端,而是增加了一个高速缓存,将消息集中到缓存后,批量进行发送。这种缓存机制也是高并发处理时非常常用的一种机制。
Kafka的消息缓存机制涉及到KafkaProducer中的两个关键组件: accumulator 和 sender
//1.记录累加器
int batchSize = Math.max(1, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG));
this.accumulator = new RecordAccumulator(logContext,batchSize,this.compressionType,lingerMs(config),retryBackoffMs,deliveryTimeoutMs, partitionerConfig,metrics,PRODUCER_METRIC_GROUP_NAME,time,apiVersions,transactionManager,new BufferPool(this.totalMemorySize, batchSize, metrics, time, PRODUCER_METRIC_GROUP_NAME));
//2. 数据发送线程
this.sender = newSender(logContext, kafkaClient, this.metadata);
其中RecordAccumulator,就是Kafka生产者的消息累加器。KafkaProducer要发送的消息都会在ReocrdAccumulator中缓存起来,然后再分批发送给kafka broker。
在RecordAccumulator中,会针对每一个Partition,维护一个Deque双端队列,这些Dequeue队列基本上是和Kafka服务端的Topic下的Partition对应的。每个Dequeue里会放入若干个ProducerBatch数据。KafkaProducer每次发送的消息,都会根据key分配到对应的Deque队列中。然后每个消息都会保存在这些队列中的某一个ProducerBatch中。而消息分发的规则,就是由上面的Partitioner组件完成的。

这里主要涉及到两个参数
//RecordAccumulator缓冲区大小
public static final String BUFFER_MEMORY_CONFIG = "buffer.memory";
private static final String BUFFER_MEMORY_DOC = "The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are "
+ "sent faster than they can be delivered to the server the producer will block for " + MAX_BLOCK_MS_CONFIG + " after which it will throw an exception."
+ ""
+ "This setting should correspond roughly to the total memory the producer will use, but is not a hard bound since "
+ "not all memory the producer uses is used for buffering. Some additional memory will be used for compression (if "
+ "compression is enabled) as well as for maintaining in-flight requests.";
//缓冲区每一个batch的大小
public static final String BATCH_SIZE_CONFIG = "batch.size";
private static final String BATCH_SIZE_DOC = "The producer will attempt to batch records together into fewer requests whenever multiple records are being sent"
+ " to the same partition. This helps performance on both the client and the server. This configuration controls the "
+ "default batch size in bytes. "
+ "
"
+ "No attempt will be made to batch records larger than this size. "
+ "
"
+ "Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent. "
+ "
"
+ "A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable "
+ "batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a "
+ "buffer of the specified batch size in anticipation of additional records."
+ "
"
+ "Note: This setting gives the upper bound of the batch size to be sent. If we have fewer than this many bytes accumulated "
+ "for this partition, we will 'linger' for the linger.ms time waiting for more records to show up. "
+ "This linger.ms setting defaults to 0, which means we'll immediately send out a record even the accumulated "
+ "batch size is under this batch.size setting.";
这里面也提到了几个其他的参数,比如 MAX_BLOCK_MS_CONFIG ,默认60秒
接下来,sender就是KafkaProducer中用来发送消息的一个单独的线程。从这里可以看到,每个KafkaProducer对象都对应一个sender线程。他会负责将RecordAccumulator中的消息发送给Kafka。

Sender也并不是一次就把RecordAccumulator中缓存的所有消息都发送出去,而是每次只拿一部分消息。他只获取RecordAccumulator中缓存内容达到BATCH_SIZE_CONFIG大小的ProducerBatch消息。当然,如果消息比较少,ProducerBatch中的消息大小长期达不到BATCH_SIZE_CONFIG的话,Sender也不会一直等待。最多等待LINGER_MS_CONFIG时长。然后就会将ProducerBatch中的消息读取出来。LINGER_MS_CONFIG默认值是0。
然后,Sender对读取出来的消息,会以Broker为key,缓存到一个对应的队列当中。这些队列当中的消息就称为InflightRequest。接下来这些Inflight就会一一发往Kafka对应的Broker中,直到收到Broker的响应,才会从队列中移除。这些队列也并不会无限缓存,最多缓存MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION(默认值为5)个请求。
生产者缓存机制的主要目的是将消息打包,减少网络IO频率。所以,在Sender的InflightRequest队列中,消息也不是一条一条发送给Broker的,而是一批消息一起往Broker发送。而这就意味着这一批消息是没有固定的先后顺序的。
其中涉及到的几个主要参数如下:
public static final String LINGER_MS_CONFIG = "linger.ms";
private static final String LINGER_MS_DOC = "The producer groups together any records that arrive in between request transmissions into a single batched request. "
+ "Normally this occurs only under load when records arrive faster than they can be sent out. However in some circumstances the client may want to "
+ "reduce the number of requests even under moderate load. This setting accomplishes this by adding a small amount "
+ "of artificial delay—that is, rather than immediately sending out a record, the producer will wait for up to "
+ "the given delay to allow other records to be sent so that the sends can be batched together. This can be thought "
+ "of as analogous to Nagle's algorithm in TCP. This setting gives the upper bound on the delay for batching: once "
+ "we get " + BATCH_SIZE_CONFIG + " worth of records for a partition it will be sent immediately regardless of this "
+ "setting, however if we have fewer than this many bytes accumulated for this partition we will 'linger' for the "
+ "specified time waiting for more records to show up. This setting defaults to 0 (i.e. no delay). Setting " + LINGER_MS_CONFIG + "=5, "
+ "for example, would have the effect of reducing the number of requests sent but would add up to 5ms of latency to records sent in the absence of load.";
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
private static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC = "The maximum number of unacknowledged requests the client will send on a single connection before blocking."
+ " Note that if this configuration is set to be greater than 1 and enable.idempotence is set to false, there is a risk of"
+ " message reordering after a failed send due to retries (i.e., if retries are enabled); "
+ " if retries are disabled or if enable.idempotence is set to true, ordering will be preserved."
+ " Additionally, enabling idempotence requires the value of this configuration to be less than or equal to " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE + "."
+ " If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled. ";
最后,Sender会通过其中的一个Selector组件完成与Kafka的IO请求,并接收Kafka的响应。
//org.apache.kafka.clients.producer.KafkaProducer#doSend
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
this.sender.wakeup();
}
Kafka的生产者缓存机制是Kafka面对海量消息时非常重要的优化机制。合理优化这些参数,对于Kafka集群性能提升是非常重要的。比如如果你的消息体比较大,那么应该考虑加大batch.size,尽量提升batch的缓存效率。而如果Producer要发送的消息确实非常多,那么就需要考虑加大total.memory参数,尽量避免缓存不够造成的阻塞。如果发现生产者发送消息比较慢,那么可以考虑提升max.in.flight.requests.per.connection参数,这样能加大消息发送的吞吐量。
6、发送应答机制
在Producer将消息发送到Broker后,要怎么确定消息是不是成功发到Broker上了呢?
这是在开发过程中比较重要的一个机制,也是面试过程中最喜欢问的一个机制,被无数教程指导吹得神乎其神。所以这里也简单介绍一下。
其实这里涉及到的,就是在Producer端一个不太起眼的属性ACKS_CONFIG。
public static final String ACKS_CONFIG = "acks";
private static final String ACKS_DOC = "The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the "
+ " durability of records that are sent. The following settings are allowed: "
+ " "
+ " acks=0 If set to zero then the producer will not wait for any acknowledgment from the"
+ " server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be"
+ " made that the server has received the record in this case, and the retries configuration will not"
+ " take effect (as the client won't generally know of any failures). The offset given back for each record will"
+ " always be set to -1."
+ " acks=1 This will mean the leader will write the record to its local log but will respond"
+ " without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after"
+ " acknowledging the record but before the followers have replicated it then the record will be lost."
+ " acks=all This means the leader will wait for the full set of in-sync replicas to"
+ " acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica"
+ " remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting."
+ "
"
+ ""
+ "Note that enabling idempotence requires this config value to be 'all'."
+ " If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled.";
官方给出的这段解释,同样比任何外部的资料都要准确详细了。如果你理解了Topic的分区模型,这个属性就非常容易理解了。这个属性更大的作用在于保证消息的安全性,尤其在replica-factor备份因子比较大的Topic中,尤为重要。
- acks=0,生产者不关心Broker端有没有将消息写入到Partition,只发送消息就不管了。吞吐量是最高的,但是数据安全性是最低的。
- acks=all or -1,生产者需要等Broker端的所有Partiton(Leader Partition以及其对应的Follower Partition都写完了才能得到返回结果,这样数据是最安全的,但是每次发消息需要等待更长的时间,吞吐量是最低的。
- acks设置成1,则是一种相对中和的策略。Leader Partition在完成自己的消息写入后,就向生产者返回结果。
在示例代码中可以验证,acks=0的时候,消息发送者就拿不到partition,offset这一些数据。
在生产环境中,acks=0可靠性太差,很少使用。acks=1,一般用于传输日志等,允许个别数据丢失的场景。使用范围最广。acks=-1,一般用于传输敏感数据,比如与钱相关的数据。
如果ack设置为all或者-1 ,Kafka也并不是强制要求所有Partition都写入数据后才响应。在Kafka的Broker服务端会有一个配置参数min.insync.replicas,控制Leader Partition在完成多少个Partition的消息写入后,往Producer返回响应。这个参数可以在broker.conf文件中进行配置。
min.insync.replicas
When a producer sets acks to "all" (or "-1"), min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception (either NotEnoughReplicas or NotEnoughReplicasAfterAppend).
When used together, min.insync.replicas and acks allow you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of "all". This will ensure that the producer raises an exception if a majority of replicas do not receive a write.
Type: int
Default: 1
Valid Values: [1,...]
Importance: high
Update Mode: cluster-wide7、生产者消息幂等性
之前分析过,当Producer的acks设置成1或-1时,Producer每次发送消息都是需要获取Broker端返回的RecordMetadata的。这个过程中就需要两次跨网络请求。

如果要保证消息安全,那么对于每个消息,这两次网络请求就必须要求是幂等的。但是,网络是不靠谱的,在高并发场景下,往往没办法保证这两个请求是幂等的。Producer发送消息的过程中,如果第一步请求成功了, 但是第二步却没有返回。这时,Producer就会认为消息发送失败了。那么Producer必然会发起重试。重试次数由参数ProducerConfig.RETRIES_CONFIG,默认值是Integer.MAX。
这时问题就来了。Producer会重复发送多条消息到Broker中。Kafka如何保证无论Producer向Broker发送多少次重复的数据,Broker端都只保留一条消息,而不会重复保存多条消息呢?这就是Kafka消息生产者的幂等性问题。
先来看Kafka中对于幂等性属性的介绍
public static final String ENABLE_IDEMPOTENCE_CONFIG = "enable.idempotence";
public static final String ENABLE_IDEMPOTENCE_DOC = "When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer "
+ "retries due to broker failures, etc., may write duplicates of the retried message in the stream. "
+ "Note that enabling idempotence requires " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + " to be less than or equal to " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE
+ " (with message ordering preserved for any allowable value), " + RETRIES_CONFIG + " to be greater than 0, and "
+ ACKS_CONFIG + " must be 'all'. "
+ ""
+ "Idempotence is enabled by default if no conflicting configurations are set. "
+ "If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled. "
+ "If idempotence is explicitly enabled and conflicting configurations are set, a ConfigException is thrown.";
这段介绍中涉及到另外两个参数,也一并列出来
// max.in.flight.requests.per.connection should be less than or equal to 5 when idempotence producer enabled to ensure message ordering
private static final int MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE = 5;
/** max.in.flight.requests.per.connection */
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
private static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC = "The maximum number of unacknowledged requests the client will send on a single connection before blocking."
+ " Note that if this config is set to be greater than 1 and enable.idempotence is set to false, there is a risk of"
+ " message re-ordering after a failed send due to retries (i.e., if retries are enabled)."
+ " Additionally, enabling idempotence requires this config value to be less than or equal to " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE + "."
+ " If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled.";
可以看到,Kafka围绕生产者幂等性问题,其实是做了一整套设计的。只是在这些描述中并没有详细解释幂等性是如何实现的。
这里首先需要理解分布式数据传递过程中的三个数据语义:at-least-once:至少一次;at-most-once:最多一次;exactly-once:精确一次。
比如,你往银行存100块钱,这时银行往往需要将存钱动作转化成一个消息,发到MQ,然后通过MQ通知另外的系统去完成修改你的账户余额以及其他一些其他的业务动作。而这个MQ消息的安全性,往往是需要分层次来设计的。首先,你要保证存钱的消息能够一定发送到MQ。如果一次发送失败了,那就重试几次,只到成功为止。这就是at-least-once至少一次。如果保证不了这个语义,那么你肯定不会接受。然后,你往银行存100块,不管这个消息你发送了多少次,银行最多只能记录一次,也就是100块存款,可以少,但决不能多。这就是at-most-once最多一次。如果保证不了这个语义,那么银行肯定也不能接收。最后,这个业务动作要让双方都满意,就必须保证存钱这个消息正正好好被记录一次,不多也不少。这就是Exactly-once语义。
所以,通常意义上,at-least-once可以保证数据不丢失,但是不能保证数据不重复。而at-most-once保证数据不重复,但是又不能保证数据不丢失。这两种语义虽然都有缺陷,但是实现起来相对来说比较简单。但是对一些敏感的业务数据,往往要求数据即不重复也不丢失,这就需要支持Exactly-once语义。而要支持Exactly-once语义,需要有非常精密的设计。
回到Producer发消息给Broker这个场景,如果要保证at-most-once语义,可以将ack级别设置为0即可,此时,是不存在幂等性问题的。如果要保证at-least-once语义,就需要将ack级别设置为1或者-1,这样就能保证Leader Partition中的消息至少是写成功了一次的,但是不保证只写了一次。如果要支持Exactly-once语义怎么办呢?这就需要使用到idempotence幂等性属性了。
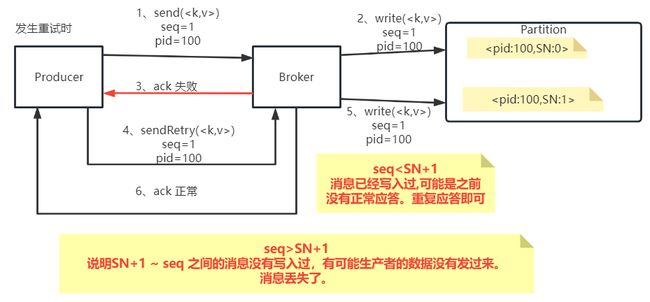
Kafka为了保证消息发送的Exactly-once语义,增加了几个概念:
- PID:每个新的Producer在初始化的过程中就会被分配一个唯一的PID。这个PID对用户是不可见的。
- Sequence Numer: 对于每个PID,这个Producer针对Partition会维护一个sequenceNumber。这是一个从0开始单调递增的数字。当Producer要往同一个Partition发送消息时,这个Sequence Number就会加1。然后会随着消息一起发往Broker。
- Broker端则会针对每个
这样,Kafka在打开idempotence幂等性控制后,在Broker端就会保证每条消息在一次发送过程中,Broker端最多只会刚刚好持久化一条。这样就能保证at-most-once语义。再加上之前分析的将生产者的acks参数设置成1或-1,保证at-least-once语义,这样就整体上保证了Exactaly-once语义。
8、生产者消息事务
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 提交事务
void commitTransaction() throws ProducerFencedException;
// 4 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;例:
public class TransactionErrorDemo {
private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";
private static final String TOPIC = "disTopic";
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 事务ID
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"111");
// 配置key的序列化类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// 配置value的序列化类
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
producer.initTransactions();
producer.beginTransaction();
for(int i = 0; i < 5; i++) {
ProducerRecord record = new ProducerRecord<>(TOPIC, Integer.toString(i), "MyProducer" + i);
//异步发送。
producer.send(record);
if(i == 3){
//第三条消息放弃事务之后,整个这一批消息都回退了。
System.out.println("error");
producer.abortTransaction();
}
}
System.out.println("message sended");
try {
Thread.sleep(10000);
} catch (Exception e) {
e.printStackTrace();
}
// producer.commitTransaction();
producer.close();
}
}